analyzing the most common chess blunders
writeup: https://javier.artiga.es/chess-blunders/
repo: https://github.com/jartigag/chess-blunders
Just:
make create_environment # and activate the environment:
source venv/bin/activate
make requirements
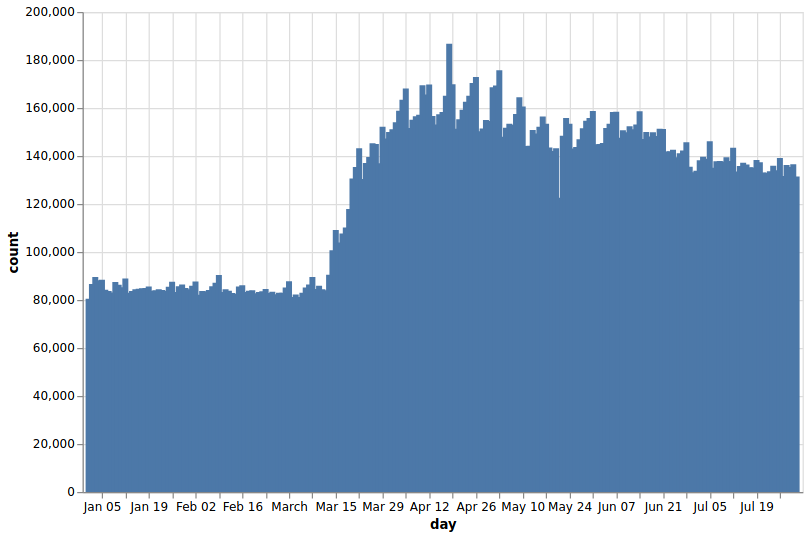
./src/data/wget_data.sh # or download only the months you want from https://database.lichess.org
make data
The make data step takes a long time, so I'd recommend to run it on a server or maybe run it in two steps (make data_interim and then make data_processed).
Unfold this to see screenshots and screencasts about the process

All data (only the first 4M evaluated games for each month in 2020 and 2021 has been processed, but that's enough):
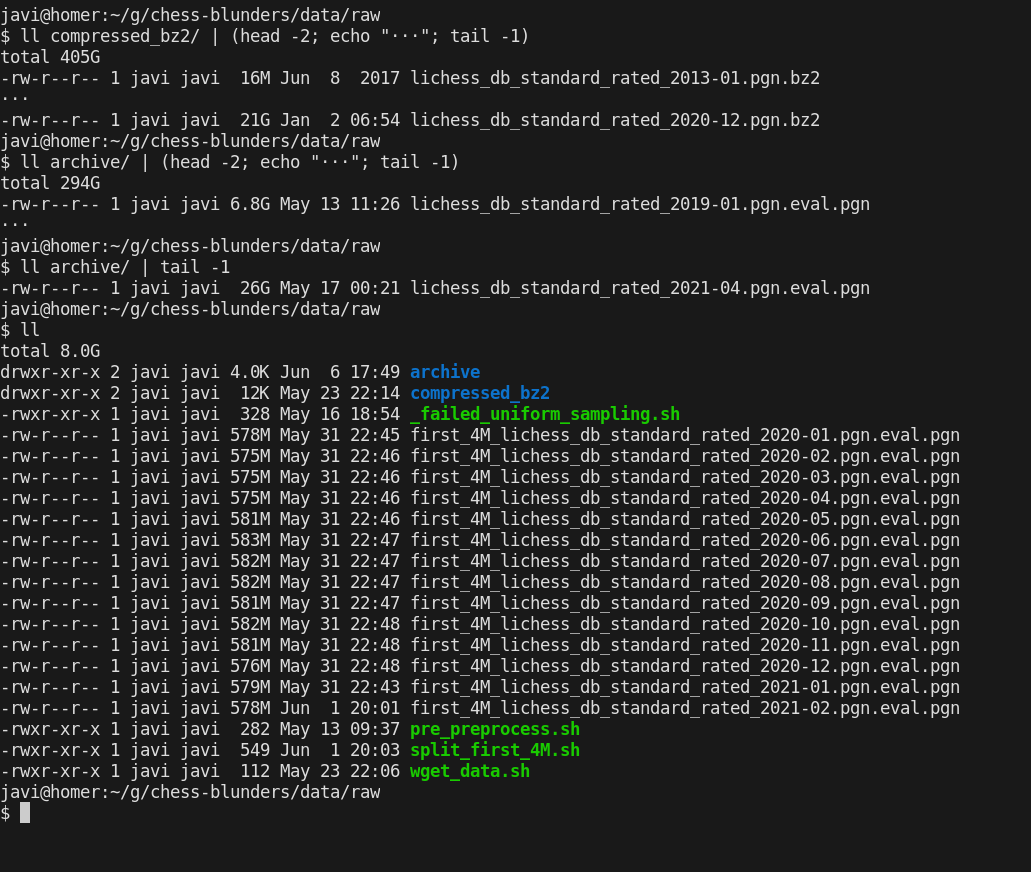
At now, this step requires manual intervention:
./src/data/split_first_4M.sh
# manually, fix the end and beginning of each file, so the pgn keeps a correct format

I should integrate this in src/visualization/, but until then:
cd notebooks
jupyter-notebook
and open the notebook, or just:
cd notebooks
python 1.0-jartigag-explore_interim_data/1.0-jartigag-explore_interim_data.py
but in that case matplotlib commands must be adapted in order to save the figures.
In 2020 (9,661,219 blunders extracted out of the first 15 turns of 2,371,589 evaluated games), these were the most frequent moves that were annotated as blunders:

On the board:
g6  |
Ng5  |
Bc4  |
|---|---|---|
Nd4  |
fxe5  |
fxe5  |
Nh3  |
Nxe5  |
Bf4  |
Here there are the blunders more often played during 2020 (in the first 15 turns), not taking into account the position:

Derived from the Cookiecutter Data Science project
├── Makefile <- Makefile with commands like `make data` or `make create_environment`
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── external <- Data from third party sources.
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── docs <- A default MkDocs project; see mkdocs.org for details
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description, e.g.
│ `1.0-jqp-initial-data-exploration`.
│
├── reports <- Generated analysis as HTML, PDF, LaTeX, etc.
│ └── figures <- Generated graphics and figures to be used in reporting
│
├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g.
│ generated with `pip freeze > requirements.txt`
│
├── setup.py <- Make this project pip installable with `pip install -e`
└── src <- Source code for use in this project.
├── data <- Scripts to download or generate data
│ ├── make_interim_data.py
│ ├── make_processed_data.py
│ ├── pre_preprocess.sh
│ ├── split_first_4M.sh
│ └── wget_data.sh
│
└── visualization <- Scripts to create exploratory and results oriented visualizations
├── visualize_interim_data.py
└── visualize_processed_data.py
Compiled on this thread