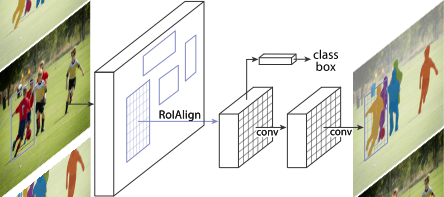
Instance Segmentation is one of many interesting computer vision tasks that combines object detection and semantic segmentation. It detects the object, and at the same time, generates a segmentation mask, which you can think as classifying each pixel - whether it belongs to an object or not.
Therefore, solving object detection and semantic segmentation together is a good approach to solve instance segmentation. In the summer school, we borrowed the framework of Mask R-CNN, to combine object detection and semantic segmentation in one pipeline, and produced some promising results.
Mask R-CNN is developed like this: R-CNN -> Fast R-CNN -> Faster R-CNN -> Mask RCNN. In each stage, researchers solved some bottleneck problems to get faster and better performance. R stands for the region based, so R-CNN a region based convolutional neural network. Mask R-CNN has two stages, the first stage is trying to produce valid bounding box, you can think it as "blobby" image regions because "blobby" regions are likely to contain objects. In the early stage, researchers feed these warped image regions into a convolutional network, and in the output, they put two head, one regression head to produce the bounding-box, another head like SVM to do classify. And peoples kept working on it and make the network more efficient using some tricks like switch the proposal layer and convolutional layer to avoid unnecessary computations.
There is a Github repo FastMaskRCNN, several machine learning enthusiasts are trying to reproduce this paper in Tensorflow. I already obtained >400k epoch weights, but haven't tested yet, I will keep working on it after summer school. This Mask R-CNN model a too big to finish within 2 weeks, especially since I am new to the TensorFlow framework. Here is the graph visualization from TensorBoard, which looks really complicated and I haven't figure out the pipeline yet.
Because building Mask R-CNN network in Mathematica side turned out to be too complicated to finish before the deadline. So in the last two days of summer school, I did something simpler, but it's inspired by Mask R-CNN's framework, which uses the bounding-box region and corresponding mask to train a network to produce a binary mask (pixel-to-pixel). And this process is like semantic segmentation. In order to get this "pixel-to-pixel" trianing dataset, I wrote a script to process 24k COCO train2014 dataset and to crop the bounding box region based on the annotation json file. Here is how information encoded for object instance annotations:
annotation{
"id" : int,
"image_id" : int,
"category_id" : int,
"segmentation" : RLE or [polygon],
"area" : float,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
The original annotation json data looks like this:
{"area" -> 54653.,
"segmentation" -> {{312.29, 562.89, 402.25, 511.49, 400.96, 425.38,
398.39, 372.69, 388.11, 332.85, 318.71, 325.14, 295.58, 305.86,
269.88, 314.86, 258.31, 337.99, 217.19, 321.29, 182.49, 343.13,
141.37, 348.27, 132.37, 358.55, 159.36, 377.83, 116.95, 421.53,
167.07, 499.92, 232.61, 560.32, 300.72, 571.89}}, "iscrowd" -> 0,
"bbox" -> {116.95, 305.86, 285.3, 266.03}, "image_id" -> 480023,
"category_id" -> 58, "id" -> 86}
The code is very simple, we just need to do the following things:
-
Use the bounding-box
{{x, y}, {dw, dh}to trim the image into bounding-box region image. -
Use the list of points (vertices of the polygon (encoding ground truth segmentation mask) ) and bounding-box image dimensions to produce the corresponding mask for the region image.
convertAnnotationBBoxIntoImageCoord[bbox_List, h_]:= Module[ {x1, y1, dw, dh}, {x1, y1, dw, dh} = bbox; Transpose[{0, h} + {1, -1} Transpose[Partition[{x1, y1, x1 + dw, y1 + dh}, 2]]] ] getMask[pts_List, w_, h_]:= Module[ {vtx}, vtx = convertAnnotationMask[pts, h]; Binarize @ Rasterize[Graphics[{White, Polygon@@vtx}, PlotRange->{{0, w}, {0, h}}, Background->Black],"Image", ImageSize->{w, h}] ] extractBBoxAndMask[img_, bbox_, segPts_List]:= Module[ {bboxLocal, w, h, boxRegion, maskRegion}, {w, h} = ImageDimensions[img]; bboxLocal = convertAnnotationBBoxIntoImageCoord[bbox, h]; boxRegion = ImageTrim[img, bboxLocal]; maskRegion = ImageTrim[getMask[segPts, w, h], bboxLocal]; {boxRegion, maskRegion} ] imgsAndMasks = extractBBox[imgs[[#]], bboxes[[#]], maskCoord[[#]]] & /@ Range[10]

For the network I used to train, I used ENet, which is a very fast and an efficient network. The Mask R-CNN paper used FCN, which is known as standard network to perform semantic segmentation. I also construct this network in Mathematica and I will try it later as well. The ENet architecture is as followings:

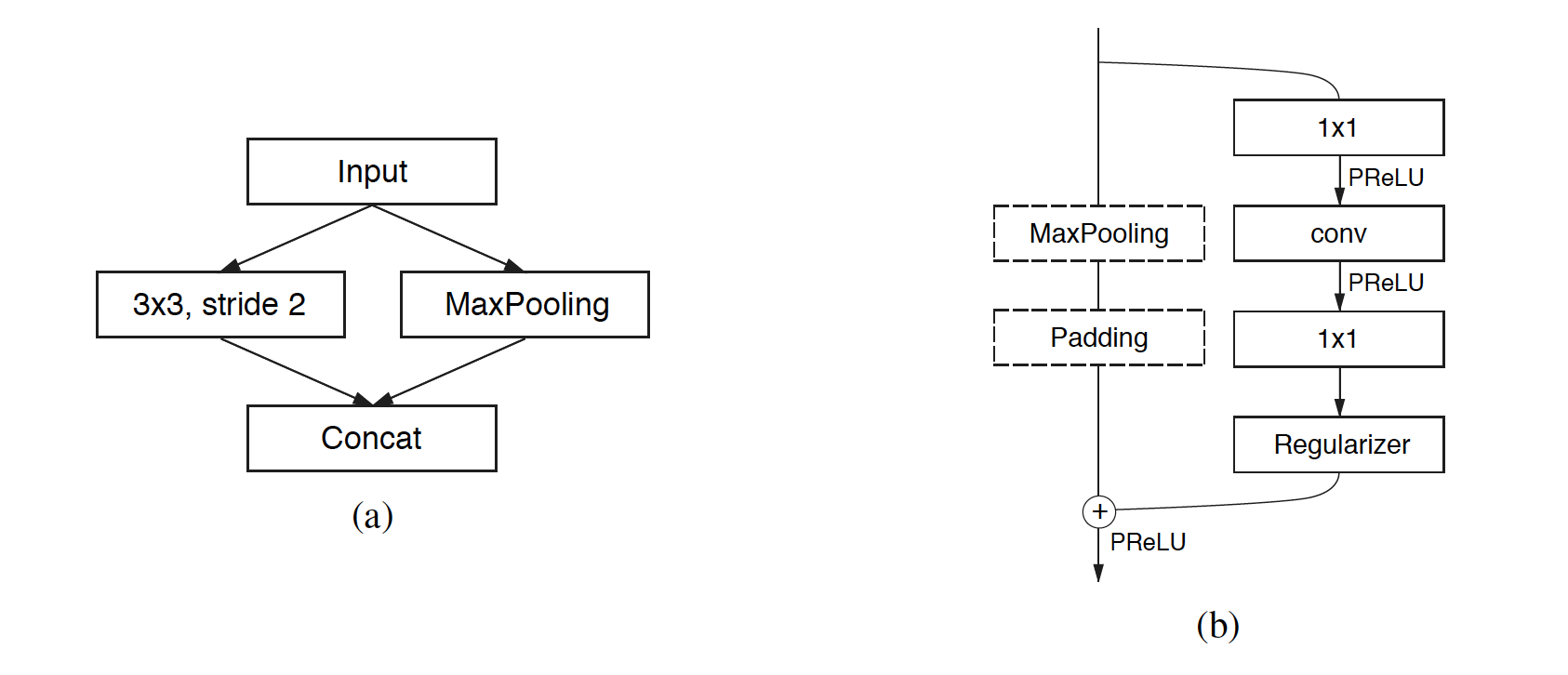
The output is a 256 * 256 * 2 tensor produced by a softmax layer, so it encoded the mask as the Pr[ this pixel belongs to object]. Therefore, I also need to convert the mask image from {0,1} binary into {1,2} as the class label and save it as .dat as training labels. Because I was running out of the time, I just trained with this simple input and output. A better way Etienne suggested is to extract the output from the final convolutional layer of yolo as an input feature to feed in near the output, which I will definitely try soon.
I trained my network only for 9 hours on a single Tesla K80 GPU, and already got very promising results.
The way my instanceSegmentation[image, net, detectionThreshold, overlapThreshold] work is as followings:
-
Use YOLO network as detector to produce labels, bounding-boxes, and probabilities
-
Use bounding-boxes to crop the image object region and feed it to our trained network
-
Take the output tensor, convert it to binaryImages, resize it back to bounding box dimensions by using
ImagePad.padRegionMask[trimmedMask_, bboxLocal_, w_, h_]:= Block[ {x1,y1,x2,y2}, {{x1,y1},{x2,y2}} = bboxLocal; ImagePad[trimmedMask, {{x1, w - x2}, {y1, h - y2}}] ] instanceSegmentation[img_, ennet_, detectionThreshold_, overlapThreshold_]:= Module[ {labels, bboxes, probs, masks, coloredMasks, yoloVis, yoloRes, rectangles, centers}, yoloRes = detection[img, detectionThreshold, overlapThreshold]; rectangles = Transpose[yoloRes][[2]]; {labels, bboxes, probs} = convertYoloResult[yoloRes]; centers = Mean/@ bboxes; masks = produceMask[ennet, img, bboxes]; coloredMasks = Flatten[{RandomColor[], Opacity[.45], #}&/@ masks]; yoloVis = Transpose @ MapThread[ { {Darker @ Green,Opacity[0],#2}, Style[ Inset[#1<>" \n("<>ToString@Round[#3, .01]<>")", #4, {Center, Center} ], FontSize -> Scaled[.03], FontColor -> White, GrayLevel[0,1], Background -> GrayLevel[1,0] ] }&, {labels, rectangles, probs, centers}]; HighlightImage[img, Join[{coloredMasks,yoloVis}], ImagePadding -> Scaled[.02]] ]
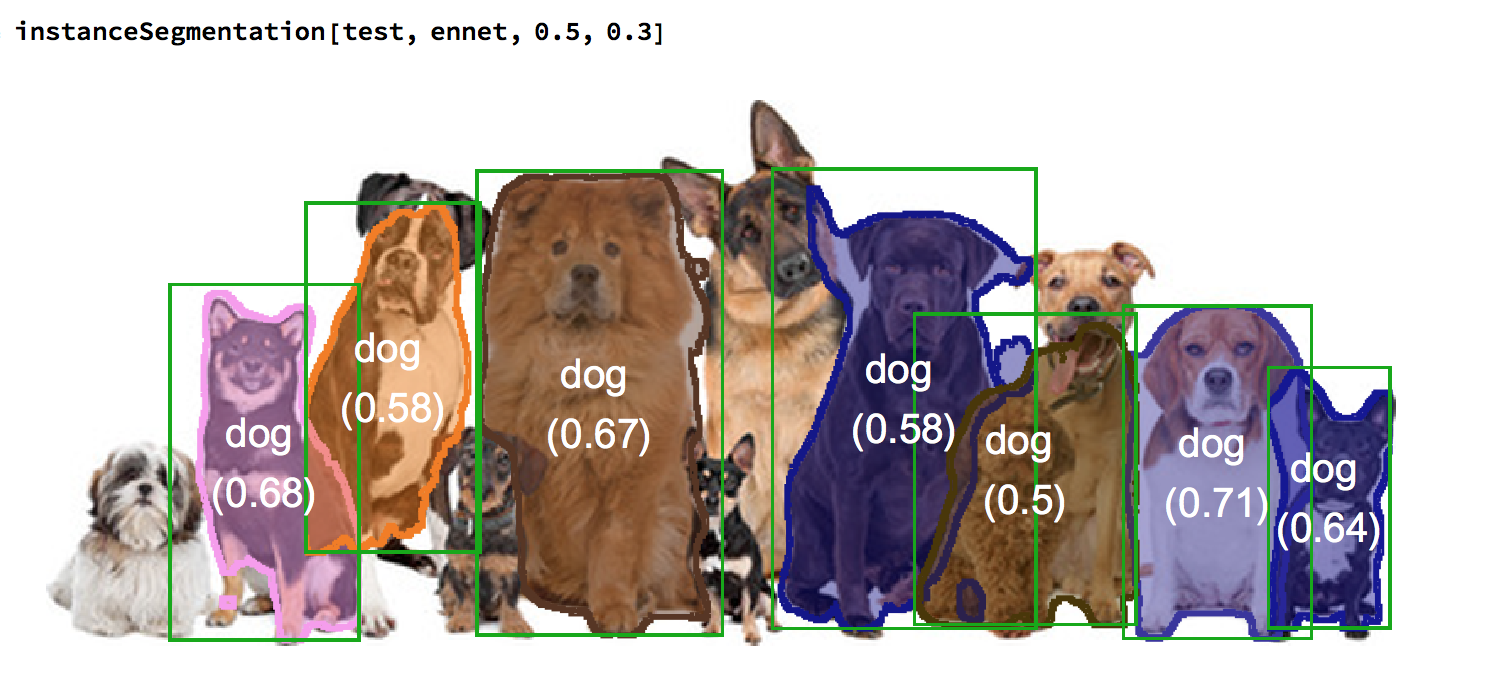
Ok, here are some results, I only started training today
Many cute dogs
Me and my mentor

Me and my phone

Me and my coffee

Me and my handbag

Me and my classmates and his phone

I enjoyed the summer school overall. I have been hoping to explore the Tensorflow framework and watch Stanford CS231n class for few months, but I was always very occupied with school's classes, other projects, lab's assignments, coding interviews, etc. I finally find some peaceful time to sit down and learn things I had always to learn. And in the process, I am also very amazed by the neural network framework Wolfram people developed. This is a very powerful and user-friendly framework that inherits Wolfram Language's elegant syntax and interactive property. I still have some questions about this framework and plan to learn more about it.
- Use FCN to do mask semantic segmentation
- After obtained Mask R-CNN trained network, deploy it on a server and build an interesting iOS application.
- Collaborate with Medical school people and apply Mask R-CNN to some medical imaging problems.
- Mask R-CNN
Paper: https://arxiv.org/abs/1703.06870
Code (under testing): https://github.com/CharlesShang/FastMaskRCNN - ENet: https://arxiv.org/abs/1606.02147
- YOLO2: https://pjreddie.com/darknet/yolo/
- Project repo: https://github.com/zhuwenzhen/InstanceSegmentation