Don't use this.
The lock consists of a sequence counter and a regular mutex.
Readers do a fenced read of the sequence before entering critical section, and a second fence read after exiting it. If the second sequence read is not equal to the first, or the sequence is odd, the reader retries.
Writers acquire the mutex and increment the sequence before entering critical section. When exiting critical section writers first increment the sequence again, and then release the mutex.
The sequence starts at 0. Hence, it will always be odd when a writer is in its critical section.
In the happy case, a reader thus only performs two fenced reads to verify it has successfully executed its critical section.
Readers acquire a "ticket to ride" stamp, and perform their critical work in a loop body. At the end of the loop body, they verify if they were successful:
var rw RWMutex
stamp := rw.RStamp()
for {
// Start critical section
// ..
// End critical section
if rw.Ok(stamp) {
break
}
}
Writers use the lock just like normal Go mutexes:
var rw RWMutex
rw.Lock()
// Start critical section
// ..
// End critical section
rw.Unlock()
The go race detector does not like this code, which is why you should not use it:
WARNING: DATA RACE
Read at 0x00c0000140b0 by goroutine 84:
seqmut.BenchmarkContendedRWMutex.func2()
/home/jake/Code/toy/seqmut/rwmutex_test.go:239 +0x5a
testing.(*B).RunParallel.func1()
/usr/local/go/src/testing/benchmark.go:665 +0x160
Previous write at 0x00c0000140b0 by goroutine 15:
seqmut.BenchmarkContendedRWMutex.func1()
/home/jake/Code/toy/seqmut/rwmutex_test.go:222 +0x8f
However, I think the code is safe. Putting this on github is part of an effort to confirm this and learn more about the Go memory model and the race detector.
I'm curious if there's a way I can
- Confirm this code is indeed safe
- Help the race detector see that it is safe
According to https://golang.org/ref/mem, the race detector is right that there are cases here where ordering of some operations is not well defined. Specifically, readers race with writers inside critical sections.
However, the memory model reference does not say behavior is undefined in the "the compiler may empty your bank account and print pictures of elephants" way. What it says is simply that you can't know if you get to see a write or not if you don't fulfil the second criteria in the "Happens Before" section.
The trick being that we can cheaply detect if a race occurred, and if so we retry.
In other words: The goal and hope is that there should be no case where a reader does not re-run its critical section if there was a race.
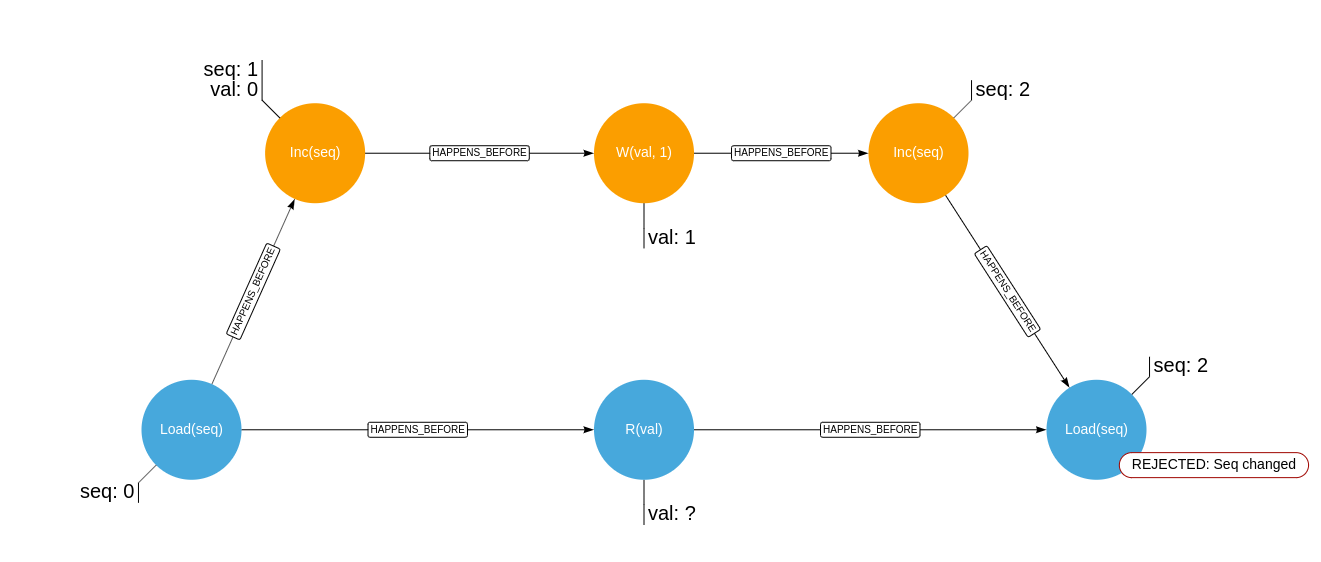
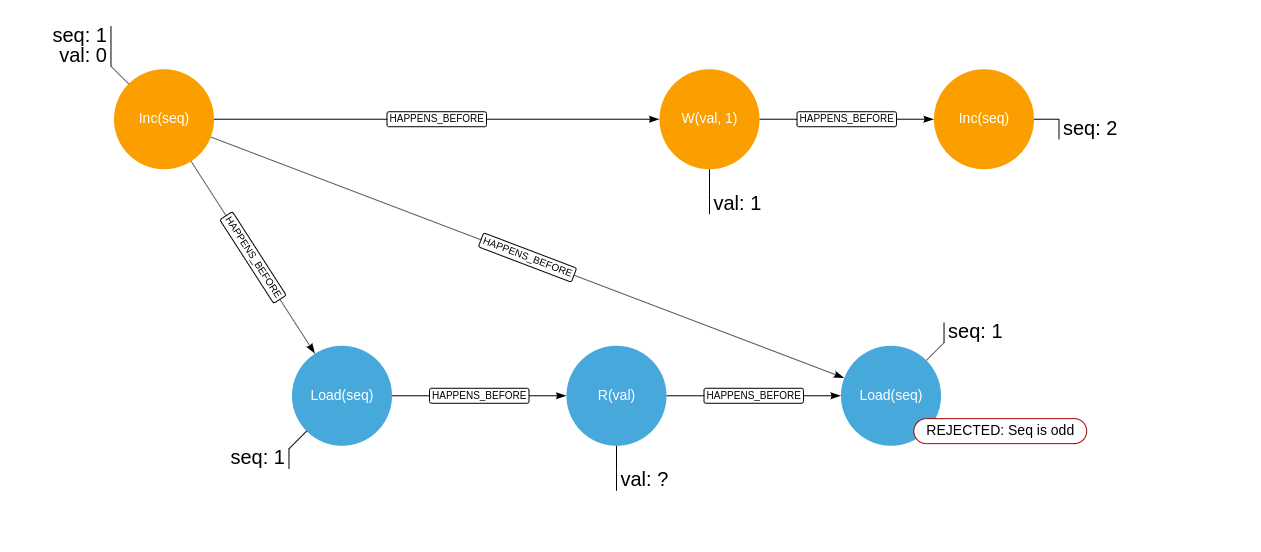
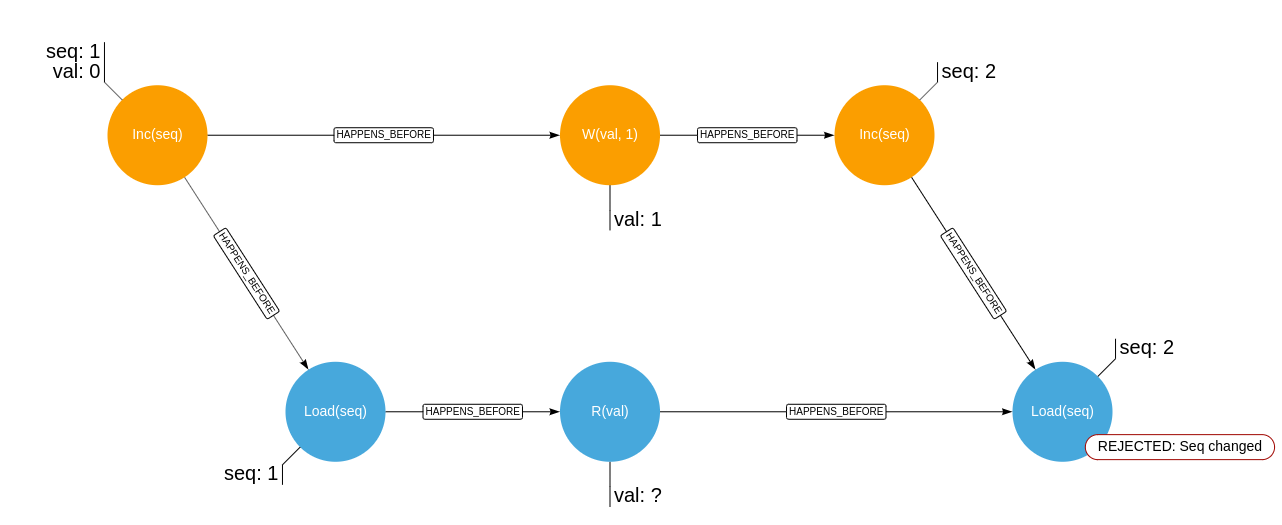
Given the two concurrent histories, orange signifying operations of a writer, blue operations of a reader:
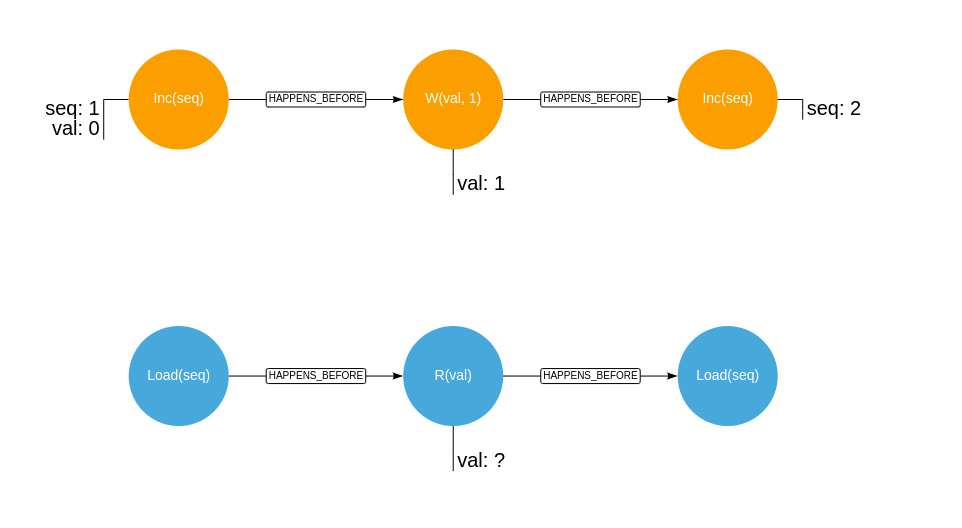
Where R(..) signifies an unfenced read, W(..) signifies an unfenced write, Load(..) signifies an atomic read and Inc(..)
signifies an atomic increment.
These are the two histories where the lock will consider the read to have taken place in a deterministic way:
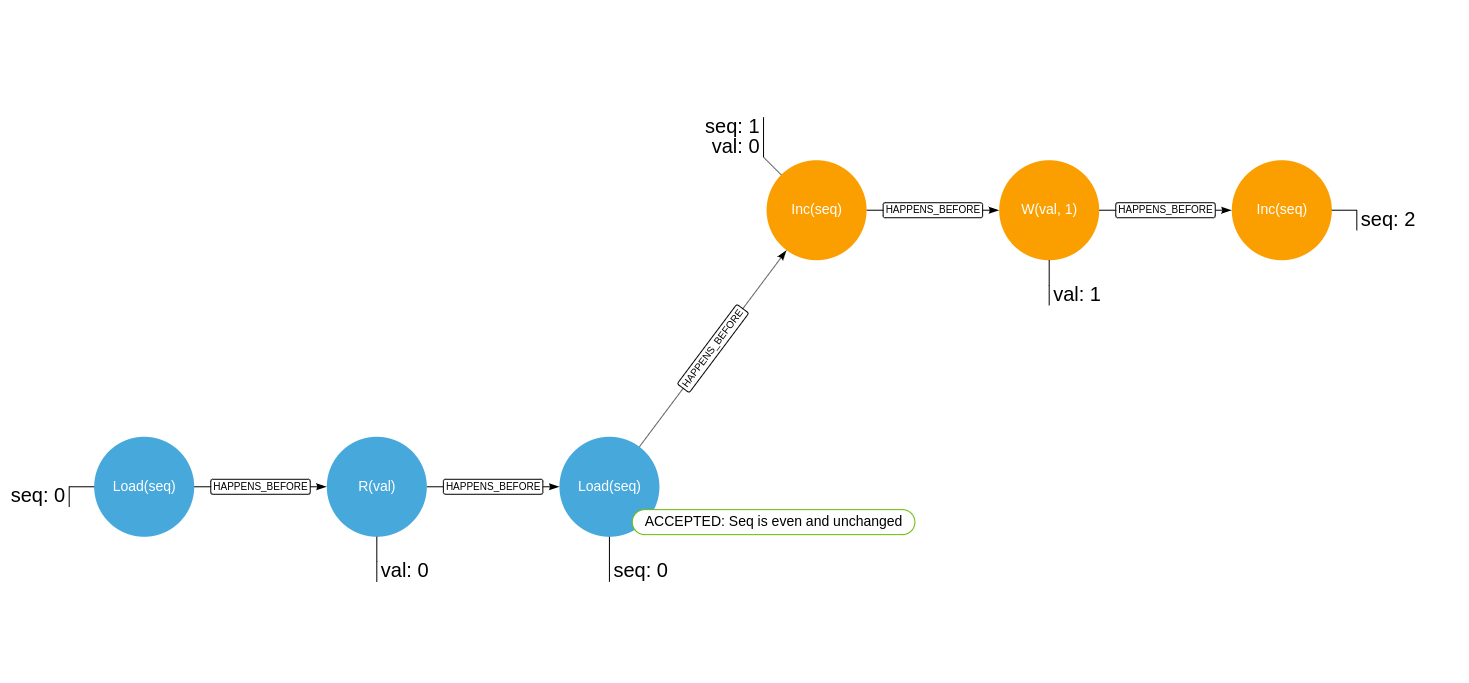
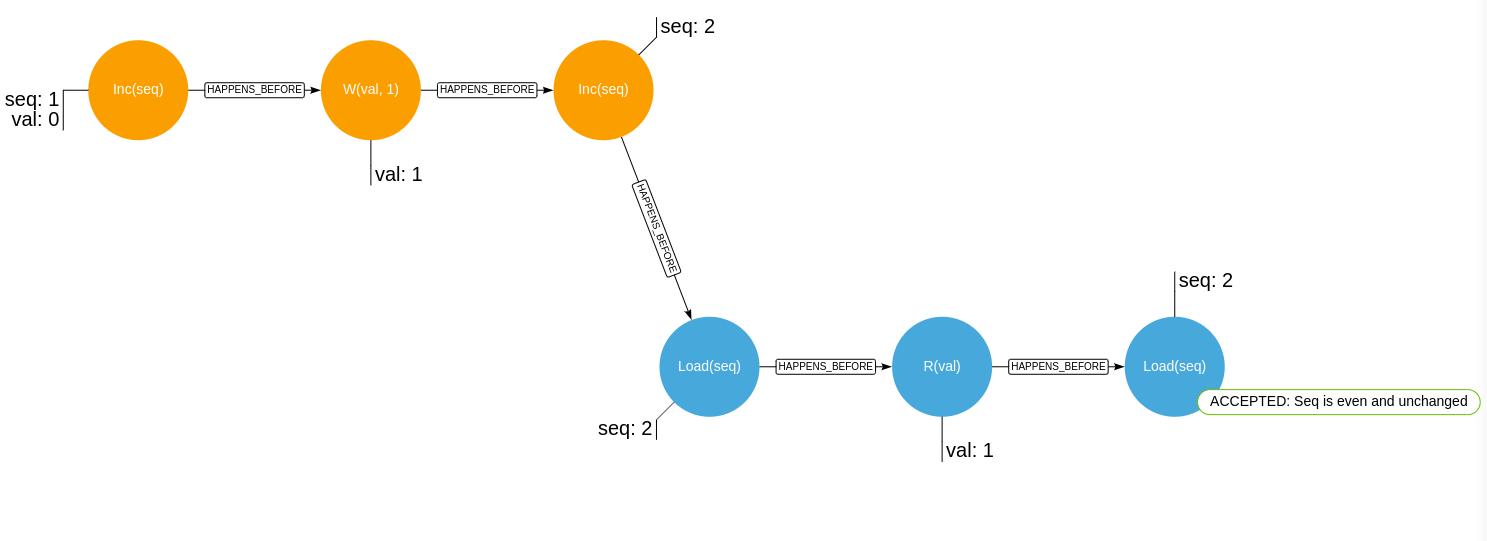
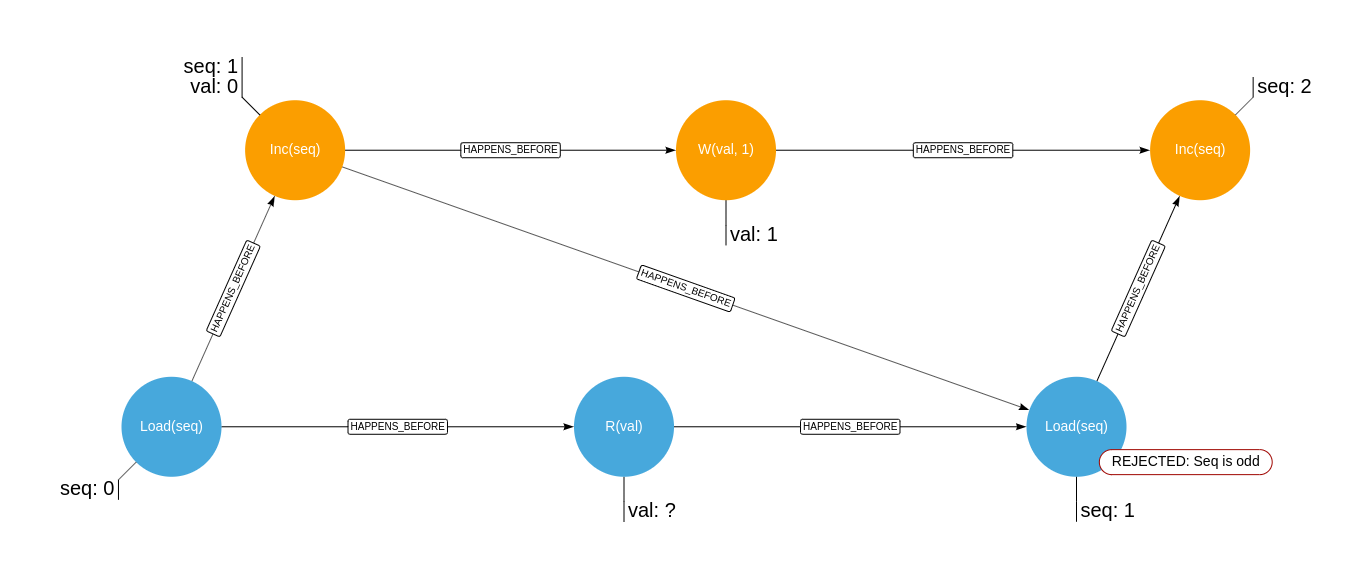
And the following are the histories where the read value is unknown, and where the lock would then require a retry:
In uncontended reads, the sequence lock performs two fenced reads. This is compared to the regular Go RWLock which performs two atomic writes.
Hence, the sequence lock is substantially faster:
$ uname -a
Linux randy 4.10.0-38-generic #42~16.04.1-Ubuntu SMP Tue Oct 10 16:32:20 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 142
Model name: Intel(R) Core(TM) i7-7600U CPU @ 2.80GHz
Stepping: 9
CPU MHz: 1899.938
CPU max MHz: 3900.0000
CPU min MHz: 400.0000
BogoMIPS: 5808.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 4096K
NUMA node0 CPU(s): 0-3
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb intel_pt tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp
$ go test -bench=.
goos: linux
goarch: amd64
pkg: seqmut
BenchmarkUncontendedRWMutex-4 2000000000 0.91 ns/op
BenchmarkContendedRWMutex-4 500000000 2.92 ns/op
BenchmarkUncontendedSyncRWMutex-4 50000000 27.5 ns/op
BenchmarkContendedSyncRWMutex-4 50000000 28.4 ns/op
For use cases like implementing disk page caches, the locks guarding pages become bottle necks if the working set fits in RAM. Each cache line read takes in the order of 1-100ns depending on where it is in caches, while the read lock takes in the order of 20ns.
Hence, in the "best" case, 100ns is main memory fetch, 20ns is mutex shenanigans.
Sequence locks have overheads closer to 1ns, which is significant here.