![]()
![]()

Fully differentiable reinforcement learning environments, written in Ivy.
What is Ivy Gym?
Ivy Gym opens the door for intersectional research between supervised learning (SL), reinforcement learning (RL), and trajectory optimization (TO), by implementing RL environments in a fully differentiable manner.
Specifically, Ivy gym provides differentiable implementations of the classic control tasks from OpenAI Gym, as well as a new Swimmer task, which illustrates the simplicity of creating new tasks using Ivy. The differentiable nature of the environments means that the cumulative reward can be directly optimized for in a supervised manner, without need for reinforcement learning, which is the de facto approach for optimizing cumulative rewards. Check out the docs for more info!
The library is built on top of the Ivy machine learning framework. This means all environments simultaneously support: Jax, Tensorflow, PyTorch, MXNet, and Numpy.
Ivy Libraries
There are a host of derived libraries written in Ivy, in the areas of mechanics, 3D vision, robotics, gym environments, neural memory, pre-trained models + implementations, and builder tools with trainers, data loaders and more. Click on the icons below to learn more!








Quick Start
Ivy gym can be installed like so: pip install ivy-gym
To quickly see the different environments provided, we suggest you check out the demos!
We suggest you start by running the script run_through.py,
and read the "Run Through" section below which explains this script.
For demos which optimize performance on the different tasks, we suggest you run either
optimize_trajectory.py or optimize_policy.py in the optimization demos folder.
The different environments can be visualized via a simple script,
which executes random motion for 250 steps in one of the environments.
The script is available in the demos folder, as file run_through.py.
First, we select a random backend framework to use for the examples, from the options
jax, tensorflow, torch, mxnet or numpy,
and use this to set the ivy backend framework.
import ivy
fw = ivy.choose_random_backend()
ivy.set_backend(fw)We then select an environment to use and execute 250 random actions, while rendering the environment after each step.
By default, the demos all use the CartPole environment, but this can be changed using the --env argument,
choosing from the options CartPole, Pendulum, MountainCar, Reacher or Swimmer.
env = getattr(ivy_gym, env_str)()
env.reset()
ac_dim = env.action_space.shape[0]
for _ in range(250):
ac = ivy.random_uniform(low=-1, high=1, shape=(ac_dim,))
env.step(ac)
env.render()Here, we briefly discuss each of the five environments, before showing example episodes from a learnt policy network. We use a learnt policy in these visualizations rather than random actions as used in the script, because we find this to be more descriptive for visually explaining each task. We also plot the instantaneous reward corresponding to each frame.
CartPole
For this task, a pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The system is controlled by applying a force to the cart. A reward is given based on the angle of the pendulum from being upright. Example trajectories are given below.

MountainCar
For this task, a car is on a one-dimensional track, positioned between two "mountains". The goal is to drive up the mountain on the right. However, the car's engine is not strong enough to scale the mountain in a single pass. Therefore, the only way to succeed is to drive back and forth to build up momentum. Here, the reward is greater if you spend less energy to reach the goal. Example trajectories are given below.
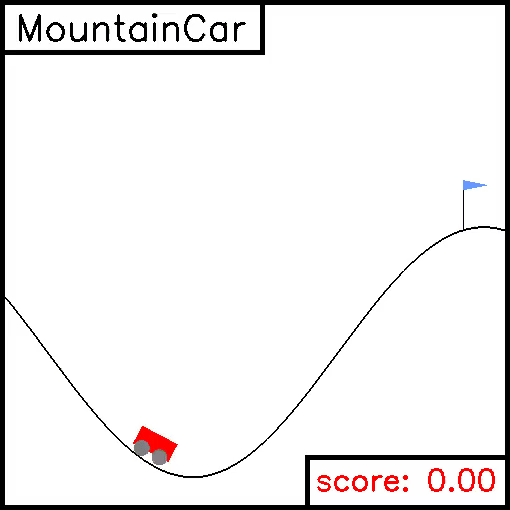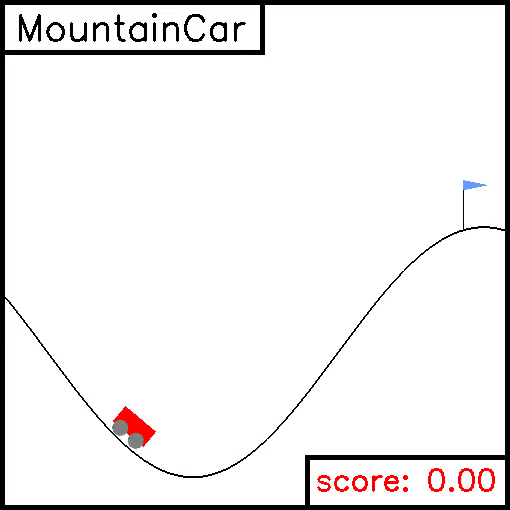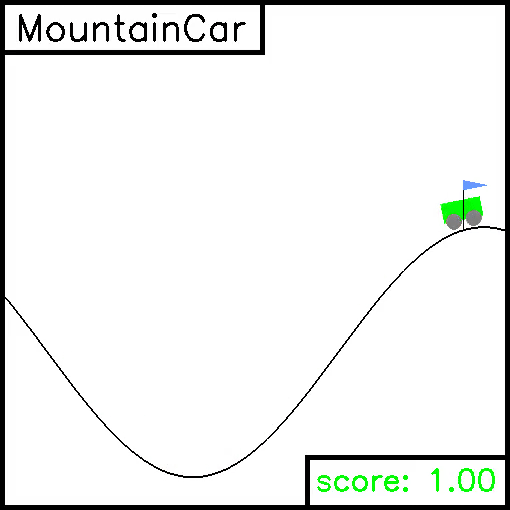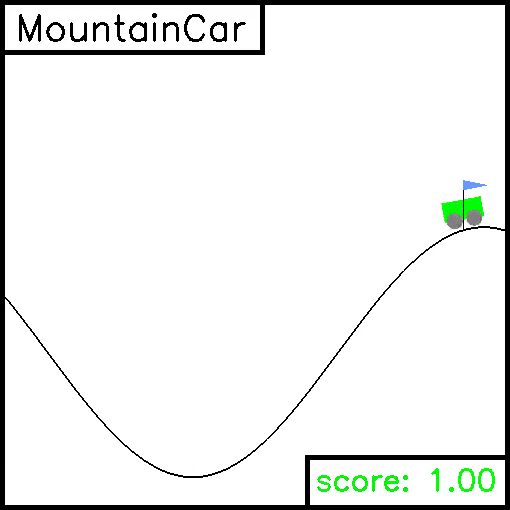
Pendulum
For this task, an inverted pendulum starts in a random position, and the goal is to swing it up so it stays upright. Again, a reward is given based on the angle of the pendulum from being upright. Example trajectories are given below.

Reacher
For this task, a 2-link robot arm must reach a target position. Reward is given based on the distance of the end effector to the target. Example trajectories are given below.

Swimmer
We implemented this task ourselves, in order to highlight the simplicity of creating new custom environments. For this task, a fish must swim to reach a target 2D positions whilst avoiding sharp obstacles. Reward is given for being close to the target, and negative reward is given for colliding with the sharp objects. Example trajectories are given below.
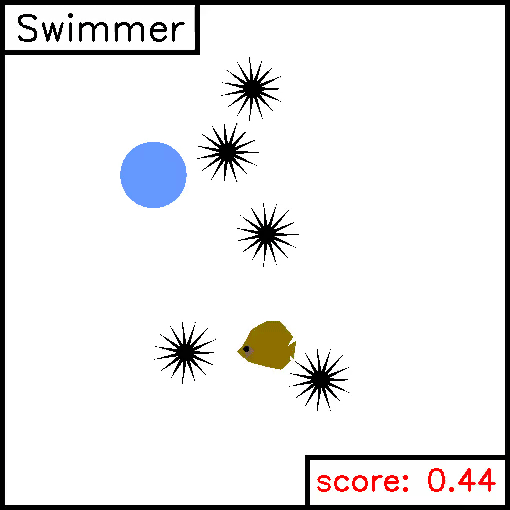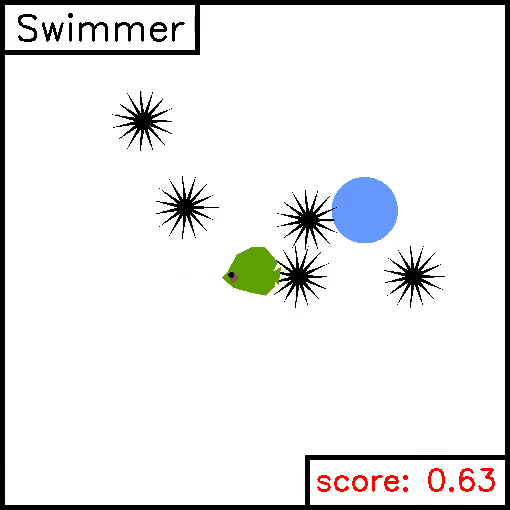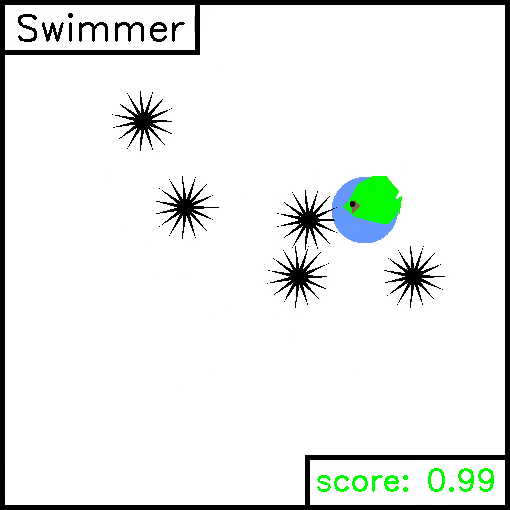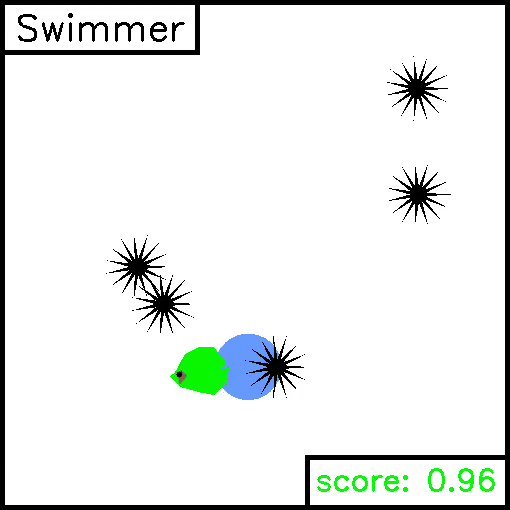
We provide two demo scripts which optimize performance on these tasks in a supervised manner, either via trajectory optimization or policy optimization.
In the case of trajectory optimization, we optimize for a specific starting state of the environment, whereas for policy optimization we train a policy network which is conditioned on the environment state, and the starting state is then randomized between training steps.
Rather than presenting the code here, we show visualizations of the demos. The scripts for these demos can be found in the optimization demos folder.
Trajectory Optimization
In this demo, we show trajectories on each of the five ivy gym environments during the course of trajectory optimization. The optimization iteration is shown in the bottom right, along with the step in the environment.
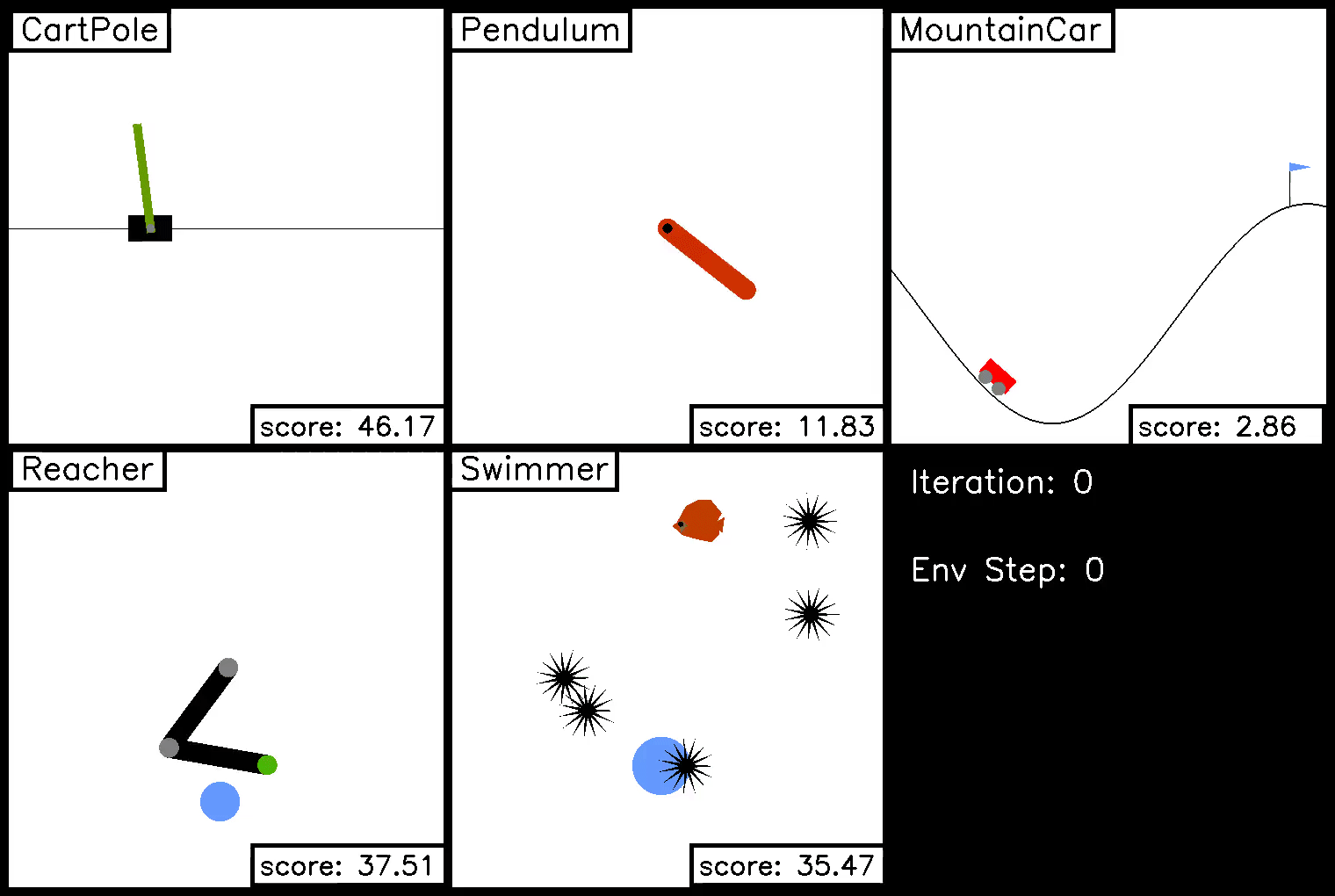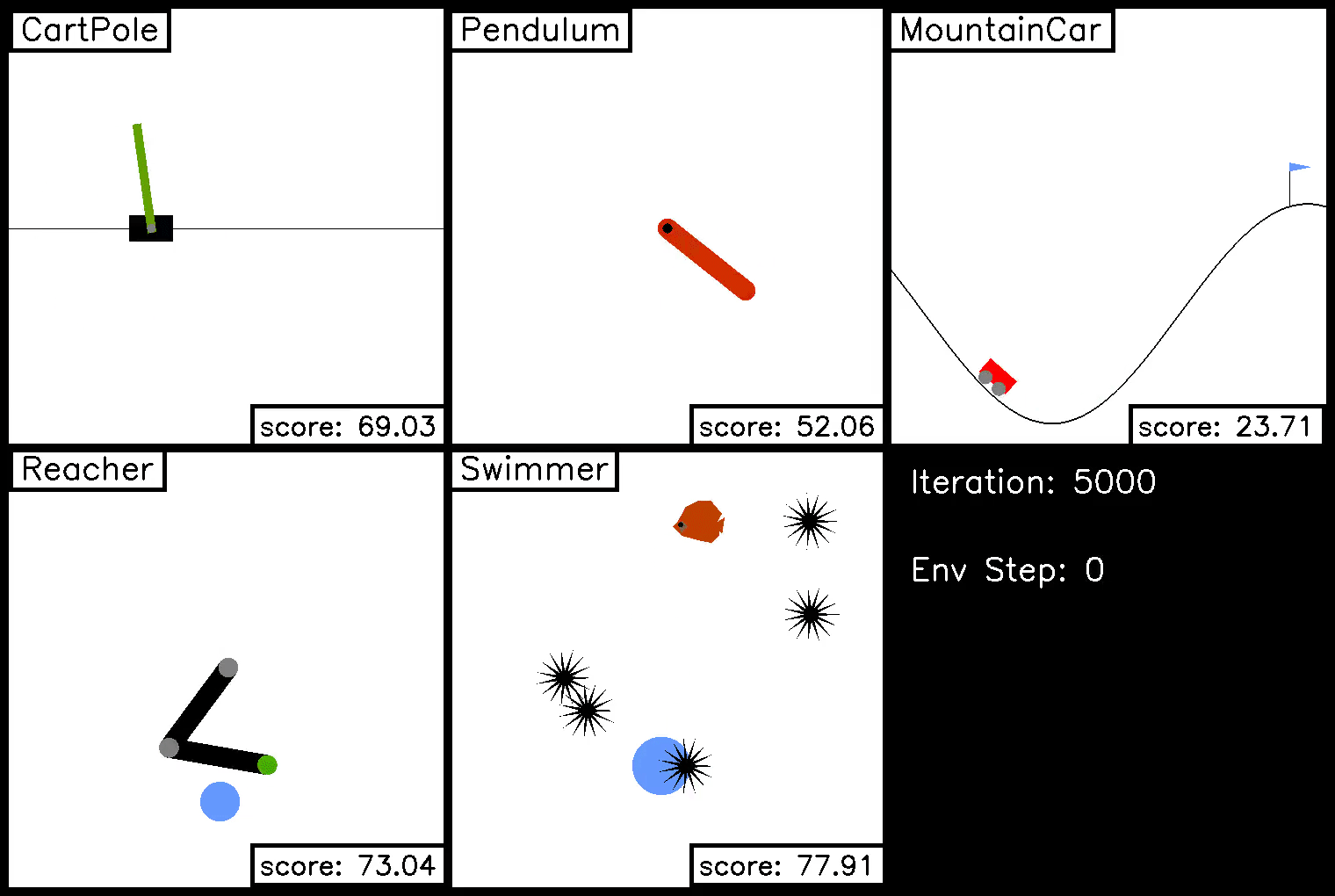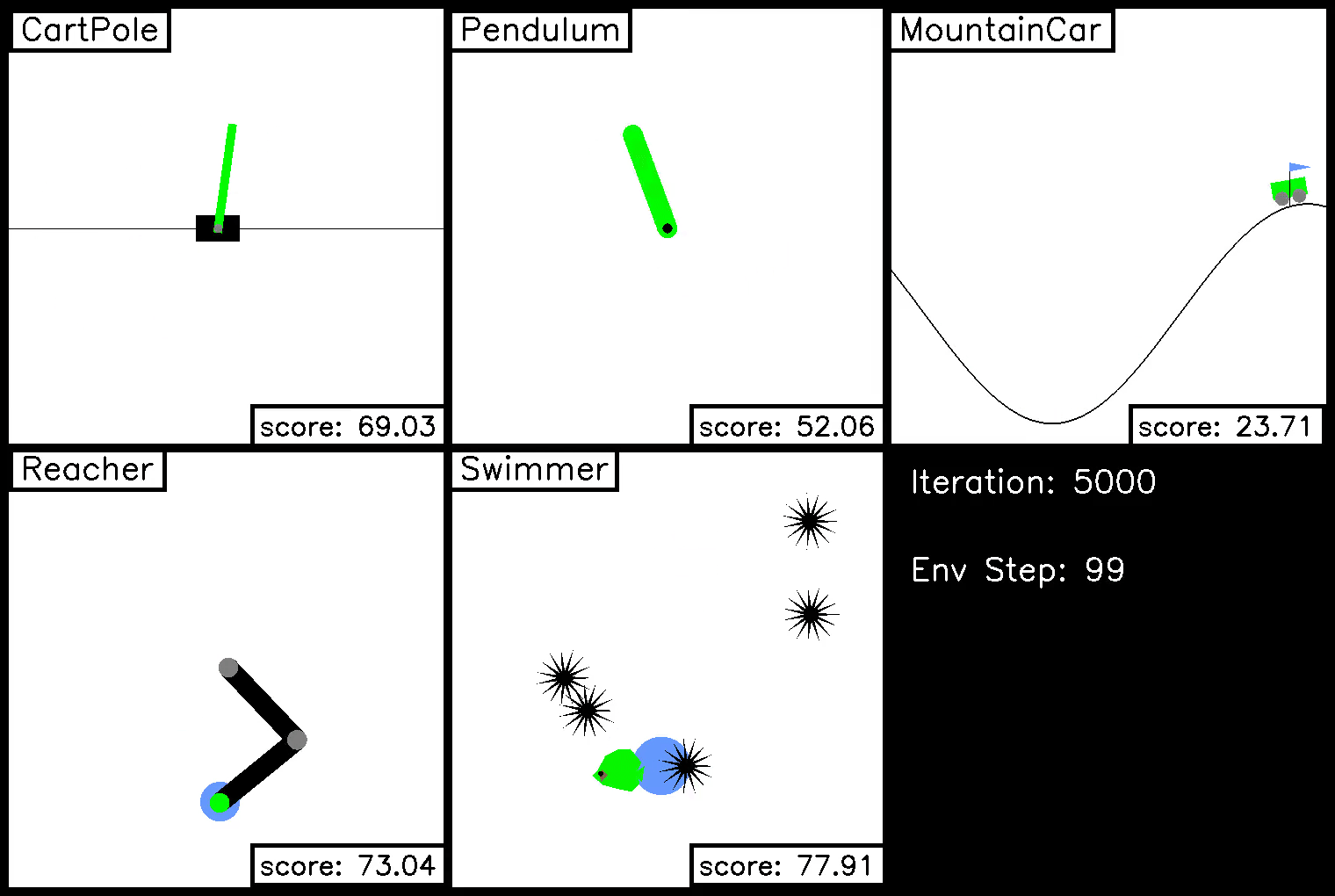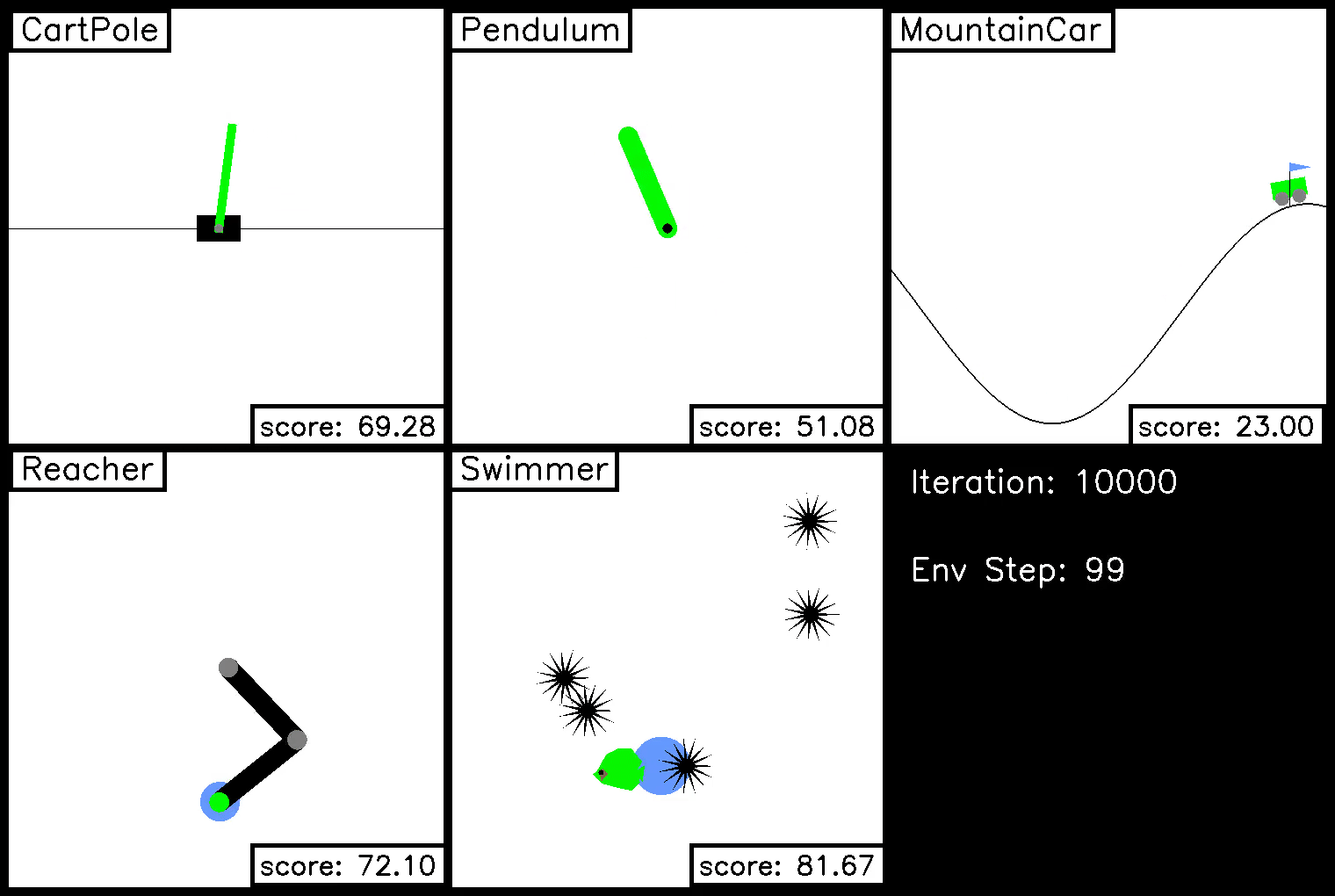
Policy Optimization
In this demo, we show trajectories on each of the five ivy gym environments during the course of policy optimization. The optimization iteration is shown in the bottom right, along with the step in the environment.

We hope the differentiable environments in this library are useful to a wide range of machine learning developers. However, there are many more tasks which could be implemented.
If there are any particular tasks you feel are missing, or you would like to implement your own custom task, then we are very happy to accept pull requests!
We look forward to working with the community on expanding and improving the Ivy gym library.
@article{lenton2021ivy,
title={Ivy: Templated deep learning for inter-framework portability},
author={Lenton, Daniel and Pardo, Fabio and Falck, Fabian and James, Stephen and Clark, Ronald},
journal={arXiv preprint arXiv:2102.02886},
year={2021}
}