
Jingkang Yang1 Chunyuan Li2 Ziwei Liu1


Project Page | Otter Paper | MIMIC-IT Paper | MIMIC-IT Dataset
Video Demo: Otter's Conceptual Demo Video | Bilibili 哔哩哔哩
Interactive Demo:
Checkpoints:
- Checkpoints v0.1 (image version)
- Checkpoints v0.2 (video version, trained on MIMIC-IT-DC)
- Checkpoints v0.2 (video version, trained on MIMIC-IT all videos, upcoming)
- Checkpoints v0.3 (Otter-E, visual assistant version, upcoming)
Otter v0.1 supports multiple images inputs as in-context examples, which is the first multi-modal instruction tuned model that supports to organize inputs this way.
Otter v0.2 supports videos inputs (frames are arranged as original Flamingo's implementation) and multiple images inputs (they serve as in-context examples for each other).
Huge accolades to Flamingo and OpenFlamingo team for the work on this great architecture.
Eval Results: Multi-Modal Arena | Multi-Modal AGI Benchmark (Upcoming)

[2023-06-08]
- Introducing Project Otter's brand new homepage: https://otter-ntu.github.io/. Check it out now!
- Check our paper introducing MIMIC-IT in details. Meet MIMIC-IT, the first multimodal in-context instruction tuning dataset with 2.8M instructions! Designed to create diverse vision-language instructions that align with real-world visual content, MIMIC-IT spans across seven image and video datasets covering a vast array of scenes. From general scene understanding to spotting subtle differences and enhancing egocentric view comprehension for AR headsets, our MIMIC-IT dataset has it all. Discover more about the MIMIC-IT dataset now!
- Stay tuned for our upcoming Otter Model v0.2, trained on the MIMIC-IT dataset! With the ability to understand daily scenes, reason in context, spot differences in observations, and act as an egocentric assistant. Checkout conceptual demo video at Youtube or Bilibili!
[2023-05-14]
- Otter battles with Owl? the Pokémon Arena is here! Our model is selected into Multi-Modal Arena. This is an interesting Multi-Modal Foundation Models competition arena that let you see different models reaction to the same question.
[2023-05-08]
- Check our Arxiv release paper at Otter: A Multi-Modal Model with In-Context Instruction Tuning !
- We support
xformersfor memory efficient attention.
Large Language Models (LLMs) have exhibited exceptional universal aptitude as few/zero-shot learners for numerous tasks, thanks to their pre-training on large-scale text data. GPT-3 is a prominent LLM that has showcased significant capabilities in this regard. Furthermore, variants of GPT-3, namely InstrctGPT and ChatGPT, equipped with instruction tuning, have proven effective in interpreting natural language instructions to perform complex real-world tasks. In this paper, we propose to introduce instruction tuning into multi-modal models, motivated by the Flamingo model's upstream interleaved format pretraining dataset. We adopt a similar approach to construct our MI-Modal In-Context Instruction Tuning (MIMIC-IT) dataset. We then introduce 🦦 Otter, a multi-modal model based on OpenFlamingo (open-sourced version of DeepMind's Flamingo), trained on MIMIC-IT and showcasing improved instruction-following ability and in-context learning. We integrate both OpenFlamingo and Otter into Hugging Face Transformers for more researchers to incorporate the models into their customized training and inference pipelines.
MIMIC-IT covers a vast array of real-life scenarios that empower Vision-Language Models (VLMs) to not only comprehend general scenes, but also to reason about context and astutely differentiate between observations. MIMIC-IT also enables the application of egocentric visual assistant model that can serve that can answer your questions like Hey, Do you think I left my keys on the table?. In addition to English, MIMIC-IT is also multilingual, supporting Chinese, Korean, Japanese, German, French, Spanish, and Arabic, thereby allowing a larger global audience to altogether enjoy from the convenience brought about by advancements in artificial intelligence.

We also introduce Syphus, an automated pipeline for generating high-quality instruction-response pairs in multiple languages. Building upon the framework proposed by LLaVA, we utilize ChatGPT to generate instruction-response pairs based on visual content. To ensure the quality of the generated instruction-response pairs, our pipeline incorporates system messages, visual annotations, and in-context examples as prompts for ChatGPT.
For more details, please check the MIMIC-IT dataset.

Otter is designed to support multi-modal in-context instruction tuning based on the OpenFlamingo model, which involves conditioning the language model on the corresponding media, such as an image that corresponds to a caption or an instruction-response pair.
We train Otter on MIMIC-IT dataset with approximately 2.8 million in-context instruction-response pairs, which are structured into a cohesive template to facilitate various tasks.
The following template encompasses images, user instructions, and model-generated responses, utilizing the User and GPT role labels to enable seamless user-assistant interactions.
prompt = f"<image>User: {instruction} GPT:<answer> {response}<endofchunk>"Training the Otter model on the MIMIC-IT dataset allows it to acquire different capacities, as demonstrated by the LA and SD tasks. Trained on the LA task, the model exhibits exceptional scene comprehension, reasoning abilities, and multi-round conversation capabilities.
# multi-round of conversation
prompt = f"<image>User: {first_instruction} GPT:<answer> {first_response}<endofchunk>User: {second_instruction} GPT:<answer>"Regarding the concept of organizing visual-language in-context examples, we demonstrate here the acquired ability of the Otter model to follow inter-contextual instructions after training on the LA-T2T task. The organized input data format is as follows:
# Multiple in-context example with similar instructions
prompt = f"<image>User:{ict_first_instruction} GPT: <answer>{ict_first_response}<|endofchunk|><image>User:{ict_second_instruction} GPT: <answer>{ict_second_response}<|endofchunk|><image>User:{query_instruction} GPT: <answer>"For more details, please refer to our paper's appendix for other tasks.
You may install via conda env create -f environment.yml. Especially to make sure the transformers>=4.28.0, accelerate>=0.18.0.
You can use the 🦩 Flamingo model / 🦦 Otter model as a 🤗 Hugging Face model with only a few lines! One-click and then model configs/weights are downloaded automatically.
from flamingo import FlamingoModel
flamingo_model = FlamingoModel.from_pretrained("luodian/openflamingo-9b-hf", device_map=auto)
from otter import OtterModel
otter_model = OtterModel.from_pretrained("luodian/otter-9b-hf", device_map=auto)Previous OpenFlamingo was developed with DistributedDataParallel (DDP) on A100 cluster. Loading OpenFlamingo-9B to GPU requires at least 33G GPU memory, which is only available on A100 GPUs.
In order to allow more researchers without access to A100 machines to try training OpenFlamingo, we wrap the OpenFlamingo model into a 🤗 hugging Face model (Jinghao has submitted a PR to the /huggingface/transformers!). Via device_map=auto, the large model is sharded across multiple GPUs when loading and training. This can help researchers who do not have access to A100-80G GPUs to achieve similar throughput in training, testing on 4x RTX-3090-24G GPUs, and model deployment on 2x RTX-3090-24G GPUs. Specific details are below (may vary depending on the CPU and disk performance, as we conducted training on different machines).
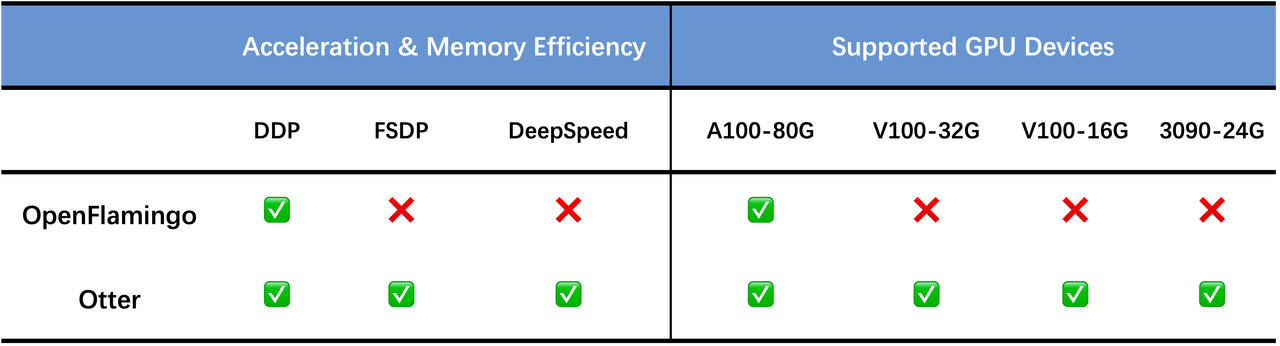
Our Otter model is also developed in this way and it's deployed on the 🤗 Hugging Face model hub. Our model can be hosted on two RTX-3090-24G GPUs and achieve a similar speed to one A100-80G machine.
Train on MIMIC-IT datasets, using the following commands:
First, run, and answer the questions asked. This will generate a config file and save it to the cache folder. The config will be used automatically to properly set the default options when doing accelerate launch.
accelerate configThen run the training script.
accelerate launch --config_file=./accelerate_configs/accelerate_config_fsdp.yaml \
pipeline/train/instruction_following.py \
--pretrained_model_name_or_path=path/to/otter_9b_hf_mm \
--dataset_resampled \
--multi_instruct_path="path/to/instruction.json" \
--images_path="path/to/image.json" \
--train_config_path="path/to/train.json" \
--batch_size=4 \
--num_epochs=9 \
--report_to_wandb \
--wandb_entity=ntu-slab \
--run_name=otter9B_dense_caption \
--wandb_project=otter9B \
--workers=1 \
--cross_attn_every_n_layers=4 \
--lr_scheduler=cosine \
--delete_previous_checkpoint \
--learning_rate=1e-5 \
--warmup_steps_ratio=0.01 \For details, you may refer to the model card.
We host our Otter-9B Demo via dual RTX-3090-24G GPUs. Launch your own demo by following the demo instructions.
We are working towards offering these features to our users. However, we have encountered some issues in the process. If you have the solutions to these issues, we would be grateful if you could submit a pull request with your code. Your contribution would be highly appreciated.
-
xformerssupport: for saving GPU memory and training speedup. issue #35 -
load_in_8bitsupport: for saving GPU memory and training speedup.
If you found this repository useful, please consider citing:
@article{li2023otter,
title={Otter: A Multi-Modal Model with In-Context Instruction Tuning},
author={Li, Bo and Zhang, Yuanhan and Chen, Liangyu and Wang, Jinghao and Yang, Jingkang and Liu, Ziwei},
journal={arXiv preprint arXiv:2305.03726},
year={2023}
}
@article{li2023mimicit,
title={MIMIC-IT: Multi-Modal In-Context Instruction Tuning},
author={Bo Li and Yuanhan Zhang and Liangyu Chen and Jinghao Wang and Fanyi Pu and Jingkang Yang and Chunyuan Li and Ziwei Liu},
year={2023},
eprint={2306.05425},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
We thank Jack Hessel for the advise and support, as well as the OpenFlamingo team for their great contribution to the open source community.