Apabila terjadi kesalahan dalam load jupyter file, penulis bagikan versi online menggunakan google collabs :
Mengetahui perkembangan dan segala informasi yang terjadi di seluruh penjuru dunia saat ini tidaklah sulit. Ada berbagai media yang bisa menjadi sarana untuk Anda mendapatkan informasi tentang hal-hal yang sedang terjadi di seluruh penjuru dunia. Inilah yang dinamakan berita. Anda mungkin sering melihat tayangan berita di berbagai media, seperti televisi, internet atau membaca di media cetak.
Berikut beberapa syarat suatu teks di dapat disebut sebagai berita :
- Berdasarkan Fakta
Informasi dalam berita yang disampaikan haruslah sesuai fakta yang sesungguhnya terjadi di lapangan. Berita tidak boleh dibuat berdasarkan karangan atau cerita fiktif.
- Aktual
Informasi dalam berita yang disampaikan adalah informasi terkini atau terbaru. Hal ini bisa dibuktikan dengan jarak waktu antara berita disiarkan dengan kejadian yang diberitakan tidak berbeda terlalu jauh.
- Berimbang
Dalam berita, informasi yang disampaikan tidak hanya harus berupa fakta namun juga berimbang. Berimbang maksudnya, fakta atau informasi yang disampaikan adalah informasi yang sebenarnya serta tidak memihak maupun memojokkan salah satu pihak. Dengan begitu masyarakat yang membaca atau melihat juga tidak akan terpengaruh.
- Lengkap
Unsur terakhir yang harus ada dalam sebuah berita adalah lengkap. Artinya setiap informasi dalam berita harus disajikan secara lengkap, tidak ada yang disembunyikan atau dikurangi. Dengan begitu masyarakat atau khalayak luas yang membaca atau mendengarkan berita tidak menjadi bingung atas informasi yang disampaikan.
Berdasarkan pengertian dan syarat sebuah berita diatas, dapat dipahami gambaran berita secara umum, oleh karena itu penulis berinisiatif untuk membuat sistem rekomendasi berita sehingga dapat mempermudah pengguna dalam membaca berita berdasarkan beberapa metode yang dipelajari di Dicoding.
Menurut (Nurkinan, 2017) Media massa sebagai sarana penyampai informasi menyajikan berita-berita hangat dan aktual kepada khalayak, karena dalam pengaruh berita yang disajikan, media massa dapat membangun kontrol sosial yang ada di masyarakat. Baik dalam mengubah opini atau pandangan seseorang, mengubah sikap dan perilaku, membangun kepercayaan, bahkan mengubah paradigma kehidupan masyarakat. Kontrol sosial yang dibangun media, tujuannya ialah untuk mengawasi segala tindak tanduk pemerintah dalam menjalankan kewajibannya.
Kajian diatas juga memperkuat intuisi penulis dalam mengembangkan model sistem rekomendasi untuk menyajikan berita yang sekiranya sesuai dengan konten, riwayat pengguna, maupun kombinasi dari beragam fitur sehingga dampat pola pikir masyarakat dapat dipengaruhi oleh topik bacaan sehari-hari.
- Bagaimana cara mengimplementasikan model content based untuk rekomendasi berita ?
- Bagaimana cara mengimplementasikan model collaborative filtering untuk rekomendasi berita ?
- Bagaimana cara mengimplementasikan model hybrid untuk rekomendasi berita ?
- Menyajikan rekomendasi berita menggunakan metode yang beragam
- Mengevaluasi metode yang terbaik dalam penyajian berita
-
Content Based
Pendekatan ini digunakan untuk metode yang akan mengambil informasi yang berguna dari item yang telah diekstraksi. Informasi ini harus dipastikan merupakan informasi yang baik dan dapat dipastikan akan menjadi relevan terhadap pengguna. Proses ektraksi terhadap item yang digunakan akan memperbesar kemungkinan munculnya item baru yang belum pernah terlihat sebelumnya. Pada dasarnya metode ini sangat bergantung pada perilaku pengguna. Asumsi utama di bawah pendekatan berbasis konten adalah bahwa item atau dokumen dapat diidentifikasi oleh serangkaian fitur yang diekstraksi langsung dari konten mereka.
-
Collaborative Filtering
collaborative filtering adalah suatu konsep dimana opini dari pengguna lain yang ada digunakan untuk memprediksi item yang mungkin disukai/diminati oleh seorang pengguna.
-
Hybrid Model
Hybrid recommender system adalah suatu teknik yang menggabukan beberapa teknik rekomendasi.
-
Train test split
Train/test split adalah salah satu metode yang dapat digunakan untuk mengevaluasi performa model machine learning. Metode evaluasi model ini membagi dataset menjadi dua bagian yakni bagian yang digunakan untuk training data dan untuk testing data dengan proporsi tertentu.
Untuk mempermudah pendefinisian langkah-langkah yang diperlukan dalam penelitian kali ini, penulis membuat visualisasi diagram tentang alur kerja secara keseluruhan.
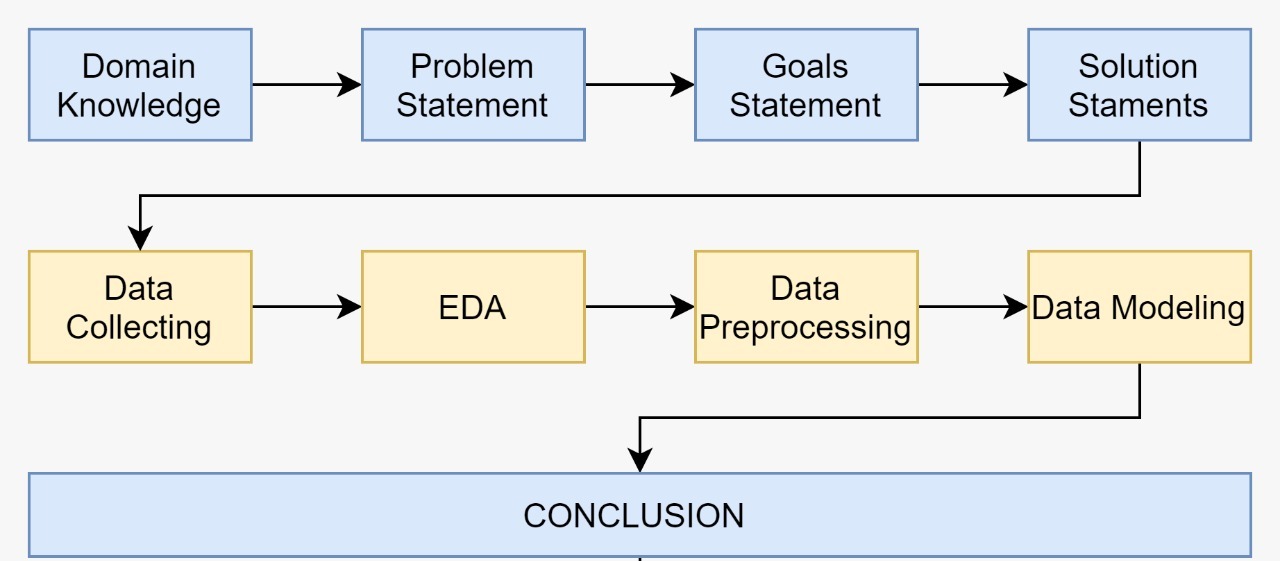

Dataset Article News berisi 2 file berbentuk csv yang mendukung pengimplementasian model sistem rekomendasi content based dan collaborative filtering. Dataset dipublikasikan oleh Gabriel Moreira pada tahun 2017.
Konteks
Deskdrop adalah platform komunikasi internal yang dikembangkan oleh CI&T, yang berfokus pada perusahaan yang menggunakan Google G Suite. Di antara fitur-fitur lainnya, platform ini memungkinkan karyawan perusahaan untuk berbagi artikel yang relevan dengan rekan-rekan mereka, dan berkolaborasi di sekitar mereka.
Konten
Kumpulan data yang kaya dan langka ini berisi sampel nyata dari log 12 bulan (Maret 2016 - Februari 2017) dari platform Komunikasi Internal CI&T (DeskDrop). Dataset berisi sekitar 73 ribu interaksi pengguna yang tercatat di lebih dari 3 ribu artikel publik yang dibagikan di platform.
Dataset ini memiliki beberapa karakteristik khusus:
- Atribut item: URL asli artikel, judul, dan teks biasa konten tersedia dalam dua bahasa (Inggris dan Portugis).
- Informasi kontekstual: Konteks kunjungan pengguna, seperti tanggal/waktu, klien (aplikasi/browser asli seluler) dan geolokasi.
- Pengguna yang dicatat: Semua pengguna diharuskan untuk masuk ke platform, menyediakan pelacakan preferensi pengguna jangka panjang (tidak tergantung pada cookie di perangkat).
- Umpan balik implisit yang kaya: Jenis interaksi yang berbeda dicatat, sehingga memungkinkan untuk menyimpulkan tingkat minat pengguna pada artikel (mis. komentar > suka > tampilan).
- Multi-platform: Interaksi pengguna dilacak di berbagai platform (browser web dan aplikasi asli seluler)
-
Check User Interaction & Article per Months
Gambar diatas merupakan visualisasi dari 2 dataset user interaksi dan artikel, dengan visualisasi diatas penulis dapat memeriksa korelasi antara pengguna dengan artikel.
Visualisasi diatas menjabarkan bahwa peningkatan / penurunan yang terjadi setiap bulannya dan puncaknya terjadi pada bulan maret sampai mei untuk distribusi artikel yang dirilis dan jumlah pengguna yang membaca artikel tersebut. -
Geo Spasial Visualisation
Gambar diatas merupakan visualisasi dari negara asal para pembaca artikel, dengan frekuensi terbesar berada di Afrika Selatan atau lebih tepatnya Negara Brazil.
- Feature Engineering : Penulis melakukan konversi dari huruf menjadi desimal pada kolom eventStrength atau konversi teks ke fitur numerical.
- Feature Combination : Penulis melakukan seleksi berdasarkan pengguna yang aktif dan pasif, berikut adalah hasil visualisasi pengecekan rasio pengguna yang terbagi menjadi 2 tipe.
Umumnya proses visualisasi terdapat pada exploratory data analysis (EDA), namun pada beberapa kasus visualisasi data tetap dilakukan sebagai teori pendukung / penguat hipotesa dalam pengambilan keputusan. Pada visualisasi diagram lingkaran diatas, penulis sedikit ragu dalam melakukan seleksi user dengan interaksi yang dikelompokkan oleh active / passive, namun penulis mencoba melakukan pengurangan data kedepannya dikarenakan apabila suatu sistem menampilkan rekomendasi item yang didasari oleh pengguna yang memiliki interaksi yang rendah dikhawatirkan akan menimbulkan kesan yang tidak nyaman bagi pengguna.
- Feature Selection : Berdasarkan pengecekan pengguna yang aktif / pasif pada tahap sebelumnya, kini penulis melakukan seleksi baris yang termasuk pengguna aktif.
- Split Dataset (train test split) : Train test split adalah salah satu metode yang dapat digunakan untuk mengevaluasi performa model machine learning. Metode evaluasi model ini membagi dataset menjadi dua bagian yakni bagian yang digunakan untuk training data dan untuk testing data dengan proporsi tertentu. Pada penelitian kali ini penulis menggunakan ratio 80:20, 80% untuk training set dan 20% untuk testing set.
Seperti yang dideskripsikan pada subbab goals statement, penulis akan mengimplementasikan 3 metode yang telah dipelajari ke dalam dataset, berikut beberapa metode yang digunakan oleh penulis beserta metode preparasi nya secara masing-masing :
Metode ini memanfaatkan deskripsi atau atribut dari item yang telah berinteraksi dengan pengguna untuk merekomendasikan item serupa. Itu hanya bergantung pada pilihan pengguna sebelumnya, membuat metode ini kuat untuk menghindari masalah cold-start. Untuk item tekstual, seperti artikel, berita, dan buku, mudah menggunakan teks mentah untuk membuat profil item dan profil pengguna.
Di sini penulis menggunakan teknik yang sangat populer dalam pencarian informasi (mesin pencari) bernama TF-IDF. Teknik ini mengubah teks tidak terstruktur menjadi struktur vektor, di mana setiap kata diwakili oleh posisi dalam vektor, dan nilainya mengukur seberapa relevan kata tertentu untuk sebuah artikel. Karena semua item akan direpresentasikan dalam Model Ruang Vektor yang sama, ini untuk menghitung kesamaan antar artikel.
Berikut beberapa metode preparasi yang penulis gunakan :
-
Stopwords : Stopwords adalah setiap kata dalam stop list yang difilter sebelum atau setelah pemrosesan data bahasa alami. Stopwords yang digunakan pada penelitian adalah stopwords bahasa portugis dan inggris.
-
TF-IDF : Term Frequency merupakan frekuensi kemunculan term i pada dokumen j dibagi dengan total term pada dokumen j.
Berikut contoh output dari model content based filtering
pada metode collaborative filtering, penulis menggunakan metode models based. Pendekatan ini, model dikembangkan menggunakan algoritma pembelajaran mesin yang berbeda untuk merekomendasikan item kepada pengguna. Ada banyak model algoritma CF berbasis, seperti jaringan saraf, jaringan bayesian, model clustering, model faktor laten seperti Singular Value Decomposition (SVD), dan analisis semantik laten probabilistik.
Berikut beberapa metode preparasi yang penulis gunakan :
- Tabel Pivot : Tabel pivot adalah tabel nilai yang dikelompokkan yang menggabungkan item individual dari tabel yang lebih luas dalam satu atau beberapa kategori terpisah.
- Matriks Faktorisasi : Matrix Factorization adalah penguraian suatu matriks menjadi beberapa buah matriks. membentuk suatu himpunan konveks.
- Min Max Scaling : Normalisasi data adalah proses membuat beberapa variabel memiliki rentang nilai yang sama, tidak ada yang terlalu besar maupun terlalu kecil sehingga dapat membuat analisis statistik menjadi lebih mudah. Perhatikan dua tabel berikut.
Berikut contoh output dari model collaborative filtering
Bagaimana jika kita menggabungkan pendekatan Collaborative Filtering dan Content-Based Filtering?
Apakah itu akan memberi penulis rekomendasi yang lebih akurat?
Faktanya, metode hibrida telah tampil lebih baik daripada pendekatan individual dalam banyak penelitian dan telah digunakan secara luas oleh para peneliti dan praktisi. Mari kita buat metode hibridisasi sederhana, sebagai ansambel yang mengambil rata-rata tertimbang dari skor CF yang dinormalisasi dengan skor Berbasis Konten, dan memberi peringkat berdasarkan skor yang dihasilkan. Dalam hal ini, karena model CF jauh lebih akurat daripada model CB, bobot untuk model CF dan CB masing-masing adalah 100,0 dan 1,0.
Berikut contoh output dari model collaborative filtering
- Recall : Merupakan rasio prediksi benar positif dibandingkan dengan keseluruhan data yang benar positif.

- Cossine Similarity : Metode Cosine Similarity adalah mengukur kemiripan antara dua dokumen atau teks. Pada Cosine Similarity dokumen atau teks dianggap sebagai vector. Pada penelitian ini, Cosine Similarity digunakan untuk menghitung jumlah kata istilah yang muncul pada halaman-halaman yang diacu pada daftar indeks.

Tabel Evaluasi
| modelName | recall@5 | recall@10 |
|---|---|---|
| Content Based | 0.162874 | 0.261442 |
| Collaborative Filtering | 0.333930 | 0.468039 |
| Hybrid | 0.342623 | 0.479673 |
Grafik Perbandingan Hasil Evaluasi Setiap Model
Metriks terbaik adalah metriks hybrid dikarenakan metode tersebut adalah gabungan dari metode collaborative filtering & content based.
Kesimpulan
Pada notebook ini, penulis mengimplementasikan 3 metode yang telah penulis pelajari pada modul terakhir kelas Dicoding Machine Learning Terapan. Secara keseluruhan dapat dilihat bahwa model hybrid yang menggabungkan 2 model ( content based & collaborative filter ) menghasilkan performa yang baik daripada 2 model original.
Improvement
- Memasukkan fitur waktu sebagai salah satu variabel dalam sistem rekomendasi,
- Menggunakan library lain seperti Surprise yang dikenal sebagai sklearn-nya sistem rekomendasi, dikarenakan memiliki function yang beragam & dataset built-in sehingga developer dapat fokus pada metode preparasi tanpa mengkhawatirkan bagaimana cara mengevaluasi suatu model.
- Pengertian Berita
- Dampak Media Online pada Perkembangan Media
- Pengertian TF-IDF
- Implementasi Cossine Similarity pada K-NN
- Matrix Factorization
- Pengertian Train Test Split
- Implementasi Algoritma Content Based pada Sistem Rekomendasi
- Analisis dan Implementasi Pendekatan Hybrid untuk Sistem Rekomendasi dengan Metode Knowledge Based Recommender System dan Collaborative Filtering
- Implementasi TF-IDF pada Text Vectorization
- Pengertian Normalisasi Data
- Pengertian SVD
- Pengertian Stopwords
- Pengertian Pivot Table
- Metriks Evaluasi: Recall, Precision, F1-Score, dan Accuracy
- Measure Model Performance using Cossine Similarity