![]()
![]()
You will repeat the Twitter/MapReduce assignment using Postgres. Because this assignment will involve many new programming concepts, it will be spread out over several assignments.
In this first assignment, we will focus on:
- working with postgres from python
- inserting data into the database
- understanding JSON/denormalized vs normalized schemas (i.e. NoSQL vs SQL)
-
Getting started:
- Fork this repo
- Enable github actions on your fork
- Clone the fork onto the lambda server
- Modify the
README.mdfile so that the test case image points to your forked repo
-
Main tasks:
-
There are two postgres containers defined in the
docker-compose.ymlfile services: one containes a normalized database schema, and the other is denormalized. You will need to update the ports for each database so that they do not conflict with anyone else.NOTE: Recall that in the pagila assignments, there was no need to adjust the ports. This is because the database was not exposed to the lambda server. In this assignment, we must expose the database to the lambda server. The
load_tweets.shandload_tweets.pyscripts will be run from the lambda server.It would be possible to put these scripts "inside" the database image so that we wouldn't need to expose the ports. But I've put the scripts "outside" the container to give you more practice connecting to the db from a remote system.
-
Complete the missing sections of the
load_tweets.pyfile. This file is responsible for loading data into the normalized database. The schema for the normalized database is summarized as: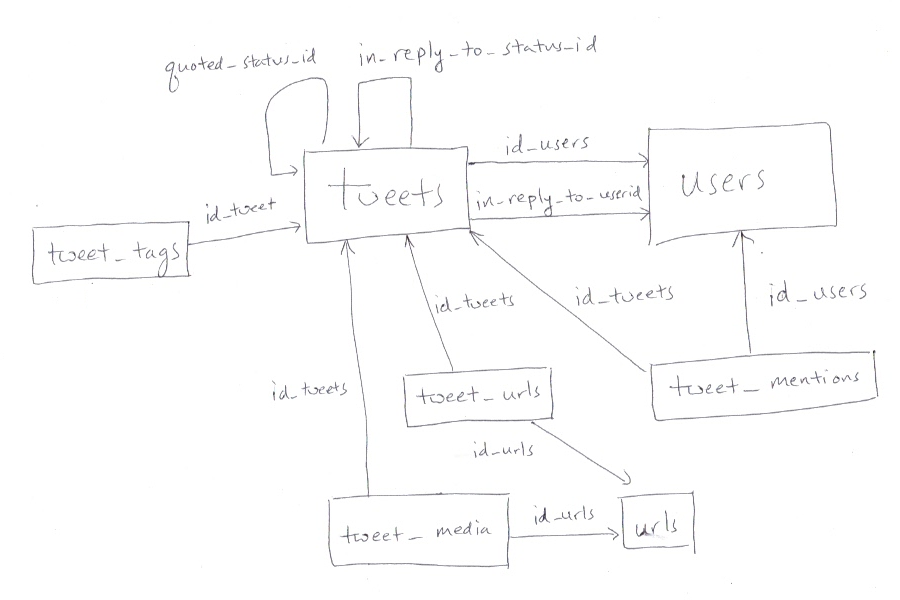
The arrows represent foreign keys onto the primary key of the target table. The foreign keys are likely to cause you many errors when inserting your data. These errors may be frustrating, but they are actually a GOOD thing (some would even say GREAT), because Postgres is preventing you from accidentally adding corrupted data into the database.
-
Complete the missing sections of the
load_tweets.shfile. This file will both call theload_tweets.pyfile, and use the SQLCOPYcommand to load data into the denormalized database.
-

HINT: As you debug your insert code, you may need to delete your database. Calling
$ docker-compose downis not enough, since the database is persisted to a volume. To delete the database, you'll need to use the
$ docker volume ls $ docker volume rm VOLUME_IDcommands to list the docker volumes and delete the appropriate volumes. Alternatively, you can use
$ docker volume pruneto delete all volumes. These commands will only work if all of your docker instances are stopped.
Upload a link to your forked github repo on sakai
GRADING: There are 9 total test cases in the
sqlfolder. If you implement the code above correctly, then the output of theSELECTcommands in each test case should be the same for each database. The assignment is worth 16 points (8 points per database). If you pass all test cases for a database, you will get 8 points. If you fail any test cases, you will receive -4 points for the first test case and -1 point for each additional failing test case. After failing 5 test cases, you will get a 0/8 for that databases (you will not go negative).