Implementation of Stanford's 2.2.4* Advanced Scheduler for PintOS — a multilevel feedback queue scheduler (MLFQS).
*-We reference and hyperlink sections of the Threads chapter of Stanford's Operating Systems digital textbook, as 2.X.X.
We will also reference the "BSD" book where this MLFQS implementation was first proposed (found as an appendix in the above Stanford page). I split that textbook into a PDF with just the process scheduler section that we need.
Stanford's PintOS assignment: 2.2.4
In order to do this assignment, we need to implement priority scheduling sans priority donation (seems to suggest priority inversion is not a problem for MLFQS) as described in 2.2.3 before we can start on 2.2.4 — the actual assignment.
The current scheduler in PintOS is Round Robin, this is good as it is required for MLFQS in the case of multiple threads having the highest priority number. Below is how the process of Round Robinning happens in a fresh clone of PintOS' source:
- thread_tick() -- line 131, thread.c -- calls inter_yield_on_turn() every time our time quantum happens.
- NOTE: by default (declared in timer.h) there are 100 OS ticks per second. Can lower the number of ticks for debugging purposes. Default TIME_SLICE is 4 ticks aka every 2.4s.
- intr_yield_on_return() flags the scheduler to call thread_yield() as soon as the tick_interrupt handler returns execution.
- thread_yield() -- line 310, thread.c -- changes the current thread's status to READY and moves it to the end of the queue before calling schedule().
I highlight this flow-of-control to show the default thread scheduling as we have to modify it. For example, we will have to change thread_yield() such that it properly appends threads to the end of its respective queue (i.e. correct priority) in our MLFQS implementation. This will be qualified further below.
PintOS has a flat Round Robin scheduler as shown above. We need to implement prioritization for 64 priorities (by default, determined by PRI_MIN, PRI_MAX variables in lines 23-25 of thread.h). NOTE: in PintOS, the higher the priority number for the thread, the higher its priority aka 0 is the lowest possible priority a thread can have. General steps to implement this:
- Change ready_list -- line 25, thread.c -- to either be a PRI_MAX sized array of lists or try some priority queue implementation.
- Change every instance of ready_list being used in the code such that properly pops and appends threads, to the right queue(s), with the right priorities.
- Use above Round Robining to resolve the issue of choosing which thread to schedule from many threads of the same priority.
MLFQS works by dynamically recalculating the priorities of every thread every fourth clock tick. It does so with a very careful set of equations that ensures starvation is limited and that threads hogging too much CPU aren't always the highest priority. Below are steps that need to be done to implement this:
-
We must implement helper functions that let us do Fixed-Point Real Arithmetic. This, to me atleast, seems the hardest part of the assignment. The rest is just procedural and might cause issues w.r.t. debugging but that's it.
-
Modify the thread struct found in thread.h to have the field "nice." In the thread_create function, initialize the niceness to either zero or the same as its parent thread. This determines how "nice" the process is so it either gives up CPU time or takes it up accordingly. Additionally, there exist method stubs for the following functions in thread.c (we must implement them):
- Function: int thread_get_nice (void)
- Returns the current thread's nice value.
- Function: void thread_set_nice (int new_nice)
- Sets the current thread's nice value to new_nice and recalculates the thread's priority based on the new value. If the running thread no longer has the highest priority, yields.
- Function: int thread_get_nice (void)
-
Create a new global variable "load_avg" that is assigned to 0 at OS boot.
- Modify timer_interrupt, or thread_tick, to recalculate it every second (or in other words every time that timer_ticks () % TIMER_FREQ == 0), using the below formula:
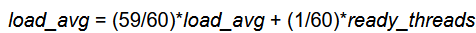

NOTE: As apart of the above requirement, we have to implement the following method stub in thread.c:
- Function: int thread_get_load_avg (void)
- Returns 100 times the current system load average, rounded to the nearest integer.
-
Modify the thread struct found in thread.h to have the field "recent_cpu."
- In the thread_create function, initialize the recent_cpu to either zero or its parent's value (if it has a parent thread).
- Every single time that a timer_interrupt occurs, for the currently running thread (unless it is the idle thread), we must increment recent_cpu by 1.
- Every second (or in other words every time that timer_ticks () % TIMER_FREQ == 0), we must recalculate the recent_cpu for every thread (ASIDE: this is to implement "decay" on threads that have not ran in a while, such that we can limit starvation) with the following formula:

-
Finally, implement the dynamic priority in timer_interrupt so that on every fourth tick, we iterate through all threads and update each priority with the following equation:
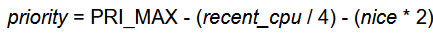


At this point, if all of the above requirements are met, we have a functioning MLFQS.
Sometime around when we hand in this assignment, we need to meet and come up with potential ideas for A3. Semester is really busy, but hopefully we'll be able to do something cool. He said no file system stuff. I will try to come up with some rudimentary ideas in the interim. NOTE: Jeeho asked Sami and I to collect people's opinions on A3, whether its feasible, etc.
There are a lot of MLFQS tests, we can run them all but most pertinently there are separate ones to test separate functionalities. For example, there's one that will test load_avgs to make sure they're correct, one that will tests to make sure they are correct, and then ofc one that tests the entire thing for all requirements. Will add to this section after I read the tests in more detail.
