Code for the paper: ISTA-NAS: Efficient and Consistent Neural Architecture Search by Sparse Coding (NeurIPS 2020),
by Yibo Yang, Hongyang Li, Shan You, Fei Wang, Chen Qian, and Zhouchen Lin
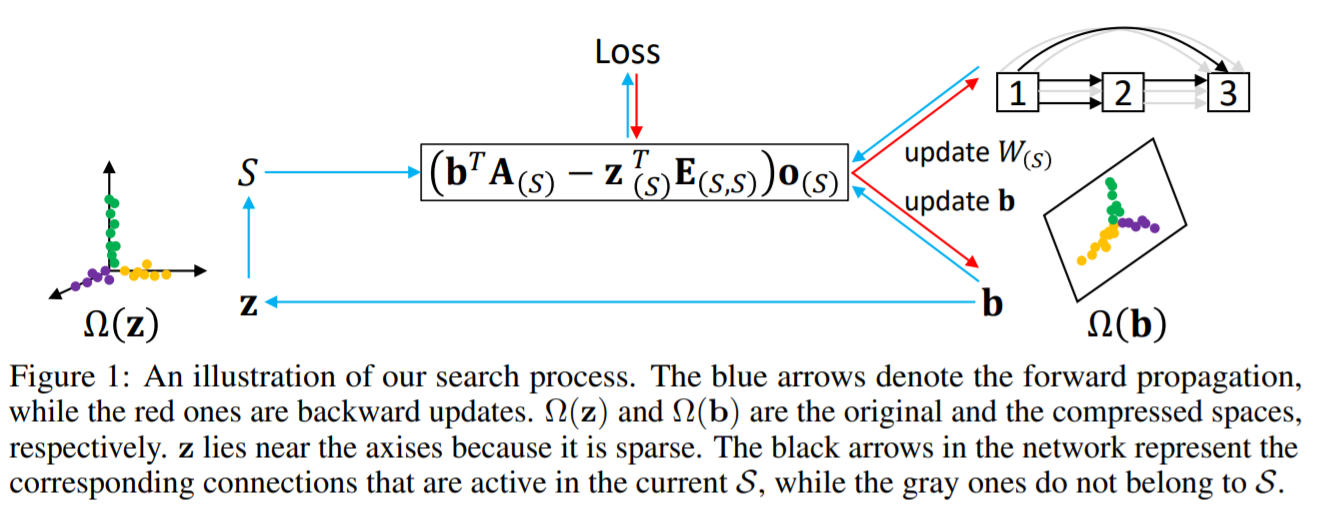
We propose to formulate NAS as a sparse coding problem, named ISTA-NAS. We construct an equivalent compressed search space where each point corresponds to a sparse solution in the original space. We perform gradient-based search in the compressed space with the sparsity constraint inherently satisfied, and then recover a new architecture by the sparse coding problem, which can be efficiently solved by well-developed methods, such as the iterative shrinkage thresholding algorithm (ISTA). The differentiable search and architecture recovery are conducted in an alternate way, so at each update, the network for search is sparse and efficient to train. After convergence, there is no need of projection onto sparsity constraint by post-processing and the searched architecture is directly available for evaluation.
We further develop a one-stage framework where search and evaluation share the same super-net under the target-net settings, such as depth, width and batchsize. After training, architecture variables are absorbed into the parameters of BN layers, and we get the searched architecture and all optimized parameters in a single run with only evaluation cost.
Some code is based on the DARTS repo.
- Python >= 3.7
- PyTorch >= 1.1 and torchvision
- CVXPY
- Mosek
- Please have a licence file
mosek.licfollowing this page, and place this file in the directory$HOME/mosek/mosek.lic.
For our two-stage search, please run:
python ./tools/train_search.py --batch_size 256 --learning_rate 0.1 --arch_learning_rate 6e-4
For our one-stage search, please run:
python ./tools/train_search_single.py --cutout --auxiliary
The one-stage search usually takes about 120 epochs (until the termination condition is satisfied for all intermediate nodes) to co-train the architecture parameters and network weights, after which the architecture is fixed and another 600 epochs follow to optimize the searched architecture. Empirically, a smaller initial learning rate makes an earlier termination.
To retrain (evaluate) our two-stage ISTA-NAS architecture, please run:
python ./tools/evaluation.py --auxiliary --cutout --arch ISTA_twostage
For the architecture searched by one-stage ISTA-NAS, please run:
python ./tools/evaluation.py --auxiliary --cutout --onestage --arch ISTA_onestage
Note that there are BN layers appended to non-parameterized operations in our one-stage ISTA-NAS architectures.
If you find ISTA-NAS useful in your research, please consider citing:
@article{yang2020ista,
title={Ista-nas: Efficient and consistent neural architecture search by sparse coding},
author={Yang, Yibo and Li, Hongyang and You, Shan and Wang, Fei and Qian, Chen and Lin, Zhouchen},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}