- Install Requirements
- Project layout
- Scripts layout
- Labeling your dataset
- Dataset Folder
- Training
- Inference
- Evaluate mAP
pip install modules/requirements.txt- Install requirements
Dataset/
Dataset/ # Folder in which you place images and labels associated you want to make inference on
DatasetAugmented/ # Dataset *8 using orientation/flip/transpose/inverse transformations
DatasetAugmented_VX/ # Filtered dataset using X filter
Inference/
Testset/ # Batch of labelised images for inference and evaluation
mAP/ # Library for mAP computing
yolov5/ # Library for handling yolov5 computation
modules/ # Contains filters, scripts to change images format and requirements
Training/
yolov5/ # Library for handling yolov5 computation
Dataset/
- `Bbox_augmentation.ipynb` - Get 3 transformations + all inverse images in separate subfolders
- `Filter_images.ipynb` - Apply filters and save images in separate folder with Train / Val / Test split for training
- `Training.ipynb` - Training a Yolo algorithm
Inference/
- `Inference.py` - Creates images predictions given a weights file and a testset
- `Evaluate.py` - Evaluates the last inference done on a specific testset
Training/
- `Training.ipynb` - Colab notebook for training yolo algorithm
LabelImg is a graphical image annotation tool.
It is written in Python and uses Qt for its graphical interface.
Annotations are saved as XML files in PASCAL VOC format, the format used by ImageNET. Besides, it also supports YOLO and CreateML formats.
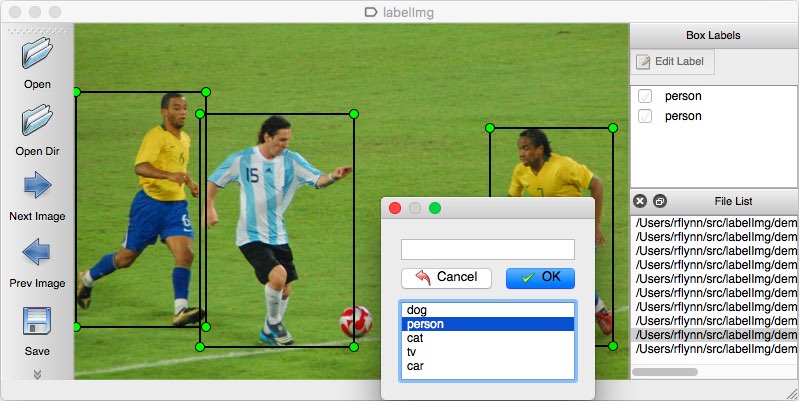
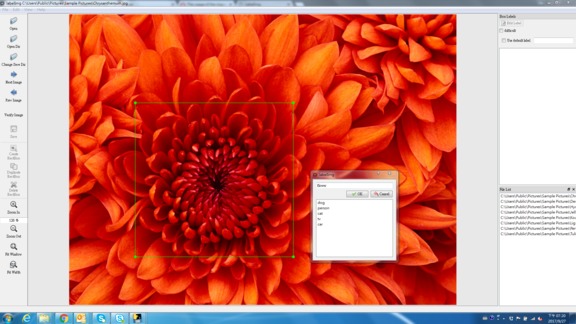
Follow the steps on the LabelImg github page. Be sure to use "YOLO" labeling format
Get started with a folder of images which you labeled using LabelImg :
TRAIN_DATASET/ # Folder in which you place all images and labels associated you watn to make inference on.
classes.txt # Text file with only the class(es) name(s) in it
capture0.jpeg # Image 0
capture0.txt # Label 0 associated to image 0 (format : "0 | x | y | w | h")
capture1.jpeg # Image 1
capture1.txt # Label 1 associated to image 1 (format : "0 | x | y | w | h")
# ...
# ...
You will first deal with the file Bbox_augmentation.ipynb
Change the path in cell 2 to the folder containing the images and the labels you want to be augmented :
# Chemin du dossier qui contient les images et les bounding boxs
PATH = 'TRAIN_DATASET'+"/"You can now execute the whole script, it will automatically create 4 subfolders in which you will find the corresponding images and labels transformed.
TRAIN_DATASET/ # Folder in which you place all images and labels associated you watn to make inference on.
HorizontalFlip/ # Folder with horizontal transformation
capture0_H.jpeg # Flipped horizontal
capture0_H.txt # Flipped horizontal
Invert/ # Folder with all other images inverted
capture0_I.jpeg # Same
capture0_I.txt # Same
capture0_H_I.jpeg # Flipped horizontal
capture0_H_I.txt # Flipped horizontal
capture0_V_I.jpeg # Flipped vertical
capture0_V_I.txt # Flipped vertical
capture0_T_I.jpeg # Transpose
capture0_T_I.txt # Transpose
Transpose/ # Folder with transposed transformation
capture0_T.jpeg # Transpose
capture0_T.txt # Transpose
VerticalFlip/ # Folder with vertical transformation
capture0_V.jpeg # Flipped vertical
capture0_V.txt # Flipped vertical
classes.txt # Same
capture0.jpeg # Same
capture0.txt # Same
# ...
# ...
At the end, if you do the 4 transformations you will have 8 times the amount of images and labels you had to begin with.
Then, you will have to apply a filter on the images (same one as in production) on the training images so the model has the same root for the training as for the inference.
First, gather all the images and labels that you augmented (if you want them) in 1 folder :
TRAIN_DATASET/ # Folder in which you place all images and labels associated you watn to make inference on.
classes.txt # Text file with only the class(es) name(s) in it
capture0.jpeg # Original
capture0.txt # Original
capture0_H.jpeg # Flipped horizontal
capture0_H.txt # Flipped horizontal
capture0_V.jpeg # Flipped vertical
capture0_V.txt # Flipped vertical
capture0_T.jpeg # Transpose
capture0_T.txt # Transpose
# Note : note taking the inverted images and labels here for instance
capture1.jpeg # Original
capture1.txt # Original
capture1_H.jpeg # Flipped horizontal
# ...
# ...
Then you can open the file Filter_images.ipynb :
- Make sure you change in cell 2 the origin of your dataset and the filter_version you want to use.
- You can find de filters in the file /utils/filters.py or in the Codification Section
Assume that you choose TRAIN_DATASET as origin and V1 as filter_version.
You will end up with a new folder like this :
TRAIN_DATASET_V1/
Trainset/
Testset/
Valset/
config.yml
Here is what the config.yml must contain :
train: ../TRAIN_DATASET_V1/Trainset # Path to Trainset
val: ../TRAIN_DATASET_V1/Valset # Path to Valset
nc: 1 # Only 1 class
names: ["class-name"] # Name(s) of the class(es)- Choose a model from n to x :
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| [YOLOv5n] | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| [YOLOv5s] | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| [YOLOv5m] | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| [YOLOv5l] | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| [YOLOv5x] | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| [YOLOv5n6] | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| [YOLOv5s6] | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| [YOLOv5m6] | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| [YOLOv5l6] | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| [YOLOv5x6] + [TTA][tta] |
1280 1536 |
55.0 55.8 |
72.7 72.7 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
python yolov5/train.py
--data TRAIN_DATASET_V1/config.yaml # Path to the "config.yml" of your Train/Val set
--weights yolov5/models/yolov5s.pt # Default yolov5s
# Just replace the "s" with the model you want to use
# Note : you can also use custom weights in this path (ex pre-trained models)
--batch 32 # Default 16
--epochs 300 # Default 300- Copy the whole project to your Google Drive
- Open the Training.ipynb file.
- Adapt the first 6 cells paths to match your Drive account
You can then modify the training line as explained in the previous paragraph
Here is what the output should look like if the training launched successfully :
Train: weights=yolov5/models/yolov5s.pt, cfg=, data=TRAIN_DATASET_V1/config.yaml,
hyp=yolov5/data/hyps/hyp.scratch.yaml, epochs=300, batch_size=32, imgsz=640, rect=False,
resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=None,
image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False,
workers=8, project=yolov5/runs/train, name=exp, exist_ok=False, quad=False, linear_lr=False,
label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, local_rank=-1, entity=None, upload_dataset=False,
bbox_interval=-1, artifact_alias=latest
Github: skipping check (not a git repository), for updates see https://github.com/ultralytics/yolov5
Hyperparameters: lr0=0.01, lrf=0.1, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8,
warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0,
hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0,
fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir yolov5/runs/train', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=1
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 270 layers, 7022326 parameters, 7022326 gradients, 15.8 GFLOPs
Transferred 343/349 items from yolov5/models/yolov5s.pt
Scaled weight_decay = 0.0005
Optimizer: SGD with parameter groups 57 weight (no decay), 60 weight, 60 bias
Albumentations: Blur(always_apply=False, p=0.01, blur_limit=(3, 7)), MedianBlur(always_apply=False,
p=0.01, blur_limit=(3, 7)), ToGray(always_apply=False, p=0.01), CLAHE(always_apply=False, p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
Train: Scanning '/content/drive/MyDrive/Atos/yolov5/../TRAIN_DATASET_V5/Trainset.cache' images and labels...
3237 found, 5 missing, 30 empty, 0 corrupt: 100% 3242/3242 [00:00<?, ?it/s]
Train: New cache created: /Users/dorianvoydie/Documents/team2_pytorch/yolov5/../TRAIN_DATASET_V5/Trainset.cache
Val: Scanning '/content/drive/MyDrive/Atos/yolov5/../TRAIN_DATASET_V5/Valset.cache' images and labels...
812 found, 0 missing, 6 empty, 0 corrupt: 100% 812/812 [00:00<?, ?it/s]
Val: New cache created: /Users/dorianvoydie/Documents/team2_pytorch/yolov5/../TRAIN_DATASET_V5/Valset.cache
Plotting labels to yolov5/runs/train/exp/labels.jpg...
AutoAnchor: 4.11 anchors/target, 0.976 Best Possible Recall (BPR).
Anchors are a poor fit to dataset ⚠️, attempting to improve...
AutoAnchor: WARNING: Extremely small objects found. 4 of 292 labels are < 3 pixels in size.
AutoAnchor: Running kmeans for 9 anchors on 292 points...
AutoAnchor: Evolving anchors with Genetic Algorithm: fitness = 0.6477: 100%|█| 1
AutoAnchor: thr=0.25: 0.9795 best possible recall, 3.54 anchors past thr
AutoAnchor: n=9, img_size=640, metric_all=0.252/0.651-mean/best, past_thr=0.455-mean: 15,23, 46,24, 55,70, 27,150, 158,83, 64,239, 297,51, 120,207, 338,309
AutoAnchor: Original anchors better than new anchors. Proceeding with original anchors.
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to yolov5/runs/train/exp
Starting training for 300 epochs...I advise you to check that most of your data has been taken in account by the model in this section of the debugging :
Train: Scanning '/content/drive/MyDrive/Atos/yolov5/../TRAIN_DATASET_V5/Trainset.cache' images and labels...
3237 found, 5 missing, 30 empty, 0 corrupt: 100% 3242/3242 [00:00<?, ?it/s]
Train: New cache created: /Users/dorianvoydie/Documents/team2_pytorch/yolov5/../TRAIN_DATASET_V5/Trainset.cache
Val: Scanning '/content/drive/MyDrive/Atos/yolov5/../TRAIN_DATASET_V5/Valset.cache' images and labels...
812 found, 0 missing, 6 empty, 0 corrupt: 100% 812/812 [00:00<?, ?it/s]
Val: New cache created: /Users/dorianvoydie/Documents/team2_pytorch/yolov5/../TRAIN_DATASET_V5/Valset.cacheLet's say your training ended.
As shown in the debugging at the end, your experiment will remain in the folder :
yolov5/runs/train/It will have a name like exp, exp1 or expX according to the number of training you launched.
As soon as a training has ended, i advise you to rename this folder as you wish.
The displaying of the training metrics is the easiest part. I advise you to use Tensorboard :
# Load the TensorBoard notebook extension
%load_ext tensorboard
%tensorboard --logdir yolov5/runs/train --host localhost --port 8088Notice that Tensorboard will have access to all training experiments (folders) you have done in yolov5/runs/train
By renaming the experiments you will have a nicer view on tensorboard as you can filter the experiments you want to show.
If you are using a notebook the interface should be displayed in the output of the cell.
If it is not, check localhost:8000 in your favorite browser.
python Inference.py
--origin [FOLDER] # Replace FOLDER by your /Testset containing images and labels
--weights [WEIGHTS_FILE] # Get your weights best.pt file from the "yolov5/runs/train/exp" folder
--conf_thres [CONF_THRES] # I advise using 0.1Be sure to convert your images to jpeg format in the Testset folder
- python3 modules/convert_jpg_to_jpeg.py --origin Testset
- python3 Inference.py --origin Testset --weights yolov5/runs/train/exp/weights/best.pt --conf_thres 0.1Il y a 20 images de test
Voici un extrait :
0 Testset/capture12.jpeg
1 Testset/capture6.jpeg
2 Testset/capture7.jpeg
3 Testset/capture13.jpeg
4 Testset/capture14.jpeg
____ __ _ __ ___ __ __
/ _/___ ___ ____ ____ _____/ /_(_)___ ____ _ / |/ /___ ____/ /__ / /
/ // __ `__ \/ __ \/ __ \/ ___/ __/ / __ \/ __ `/ / /|_/ / __ \/ __ / _ \/ /
_/ // / / / / / /_/ / /_/ / / / /_/ / / / / /_/ / / / / / /_/ / /_/ / __/ /
/___/_/ /_/ /_/ .___/\____/_/ \__/_/_/ /_/\__, / /_/ /_/\____/\__,_/\___/_/
/_/ /____/Fusing layers...
Model Summary: 213 layers, 7012822 parameters, 0 gradients, 15.8 GFLOPs
Loading Model took : 0.2018270492553711
______ __ _ ___ __ _
/ ____/___ ____ ___ ____ __ __/ /_(_)___ ____ _ ____ ________ ____/ (_)____/ /_(_)___ ____ _____
/ / / __ \/ __ `__ \/ __ \/ / / / __/ / __ \/ __ `/ / __ \/ ___/ _ \/ __ / / ___/ __/ / __ \/ __ \/ ___/
/ /___/ /_/ / / / / / / /_/ / /_/ / /_/ / / / / /_/ / / /_/ / / / __/ /_/ / / /__/ /_/ / /_/ / / / (__ )
\____/\____/_/ /_/ /_/ .___/\__,_/\__/_/_/ /_/\__, / / .___/_/ \___/\__,_/_/\___/\__/_/\____/_/ /_/____/
/_/ /____/ /_/
______ ____ __ __ __ __ __ ____ ___
/ ____/___ ____ / __/ / /_/ /_ ________ _____/ /_ ____ / /___/ / _ / __ \ < /
/ / / __ \/ __ \/ /_ / __/ __ \/ ___/ _ \/ ___/ __ \/ __ \/ / __ / (_) / / / / / /
/ /___/ /_/ / / / / __/ / /_/ / / / / / __(__ ) / / / /_/ / / /_/ / _ / /_/ / / /
\____/\____/_/ /_/_/ \__/_/ /_/_/ \___/____/_/ /_/\____/_/\__,_/ (_) \____(_)_/100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:09<00:00, 2.05it/s]
_____ _ _
/ ___/____ __ __(_)___ ____ _ (_)___ ___ ____ _____ ____ _____
\__ \/ __ `/ | / / / __ \/ __ `/ / / __ `__ \/ __ `/ __ `/ _ \/ ___/
___/ / /_/ /| |/ / / / / / /_/ / / / / / / / / /_/ / /_/ / __(__ )
/____/\__,_/ |___/_/_/ /_/\__, / /_/_/ /_/ /_/\__,_/\__, /\___/____/
/____/ /____/100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:02<00:00, 8.65it/s]
python Evaluate.py --origin [FOLDER]Important : Delete the "classes.txt" file from the FOLDER if there is one.
Keeping it will give you wrong results.
rm: ./mAP/input/detection-results/backup: is a directory
rm: ./mAP/input/ground-truth/backup: is a directory
rm: ./mAP/input/ground-truth/backup_no_matches_found: is a directory
./Testset/Prediction/
Conversion completed!
Conversion completed!
total ground-truth files: 20
total detection-results files: 20
No backup required for /Users/dorianvoydie/Documents/team2_pytorch/mAP/input/ground-truth
No backup required for /Users/dorianvoydie/Documents/team2_pytorch/mAP/input/detection-results
total intersected files: 20
Intersection completed!
91.17% = class AP
mAP = 91.17%