El repositorio se subdivide en 6 carpetas:
-
Guías y Manuales: Manuales para el Maixduino y el chip Kendryte K210
-
MAIXDUINO: Scripts para programar la placa "Maixduino"
-
MATLAB: Scripts utilizados para procesar datasets (Crear anotaciones / Extraer muestras de anotaciones e imágenes / Redimensionar imágenes). Un port de python ya se incluye en la carpeta "YOLOv2/Training and Detection from Scratch"
-
Utilidades:
- kflash_gui: Permite instalar el firmware y subir modelos de red al Maixduino
- nn_case: Convierte un modelo de red neuronal
.tflitea uno.kmodel(El que se sube al Maixduino)
-
YOLOv2: WIP. Implementación de la versión 2 de YOLO (Utilizada por el MAIXDUINO). Esta incluye tanto la capacidad de entrenar al algoritmo, como de generar predicciones.
-
YOLOv3: WIP. Implementación de la versión 3 de YOLO. Se subdivide en dos carpetas.
- Training: Entrenamiento de una red utilizando custom datasets y una variedad de backends (Arquitecturas de red). El dataset que utiliza no se incluye en el repositorio por su tamaño.
- Prediction_generation: Generar "boundary boxes" sobre imágenes, videos o el feed de una webcam. Se utiliza un modelo pre-entrenado utilizando el VOC 2011 dataset. Las frames procesadas de un video pueden ser guardadas como un nuevo video del mismo formato.
-
MAIXDUINO:
- vehicle_tracker: Abrir con
MaixPy IDEy programar desde ahí el Maixduino.
- vehicle_tracker: Abrir con
-
YOLOv2:
-
Training and Detection from Scratch: Mover directorio a carpeta
Training and Detection from Scratch. Agregar las carpetasraw_datasetytrain_datasetal directorio baseroot | │ README.md | backend.py | kmeans.py │ ... │ └───raw_dataset │ └───annotations │ └───images | └───train_dataset │ └───annotations │ └───imagesIncluir el dataset a utilizar en la carpeta de
raw_dataset(Archivos XML enannotationse imágenes enimages). Ejecutarmain.pypara realizar pruebas.
-
-
YOLOv3:
-
Training: Modificar los settings a utilizar en el archivo
config.json. Crear los siguientes directoriosroot └───images │ └───train_image_folder │ └───valid_image_folder | └───annotations │ └───train_annot_folder │ └───valid_annot_folderEl nombre de las carpetas, así como su estructura puede ser cambiada según la preferencia del usuario en
config.json. Colocar las anotaciones e imágenes del dataset a utilizar en las carpetas con el prefijotrain. Ejecutar el comandopython gen_anchors.py -c config.json, para generar las anchorboxes a utilizar (Tamaños representativos de cajas presentes en el dataset). Luego ejecutarpython train.py -c config.jsonpara iniciar el entrenamiento. -
Prediction_Generation: Agregar los archivos que se desean analizar a
media. Luego ejecutarYOLO3 - Make Prediction.py. Seguir los "prompts" que se muestran en consola. Tomar en cuenta que el programa aún no cuenta con programación defensiva, por lo que las opciones que se dan, son exactamente las que se tienen que escribir o se producirán errores.
-
Para los algoritmos incluidos en YOLOv2 y YOLOv3 se utilizaron los siguientes módulos:
- keras == 2.3.1
- matplotlib == 3.1.2 (Opcional. Instalar la versión más reciente. Si no funciona, utilizar esta.)
- opencv-python == 4.1.2.30
- tensorflow == 1.14.0
- tensorflow-gpu == 1.14.0
- numpy == 1.16.4 (Opcional. Se pueden utilizar versiones posteriores, pero se generan muchas alertas si se utilizan en conjunto con tensorflow 1.14.0)
NOTA: Para que funcione tensorflow-gpu, es necesario instalar las librerías de CUDA de Nvidia. Para esto seguir la guía presente en la siguiente sección
-
Instalar drivers del FTDI 232. Si se va a descargar la versión de Windows hacer click en la opción de Available as setup executable para facilitar la instalación.
-
Descargar el firmware del MAIXDUINO
NOTA: Se puede elegir cualquier versión, pero si se desea utilizar el MaixPy IDE entonces utilizar una versión arriba de la v0.4.0_44. Además se debe considerar que para cada versión existen diferentes sub-versiones. Procurar utilizar la que no tiene ningún sufijo como
_minimumo_with_lvglya que estas son versiones con menos features en general. -
Instalar el programa utilizado para escribir en la memoria flash de la placa: kflash_gui. Descargar el archivo .7z, descomprimirlo y ejecutar kflash_gui.exe
-
Hacer click en "open file" y elegir el firmware.bin descargado. Colocar la dirección 0x00000 y los siguientes "settings":
- Board: Sipeed Maixduino
- Burn To: Flash
- Port: Según la computadora
- Baudrate: 1500000
- Speed Mode: Slow Mode
NOTA: Este software tiende a congelarse en muchos casos. Es muy común. Cuando suceda se debe finalizar la ejecución del programa con administrador de tareas o esperar a que este se cierre normalmente (Muy tardado. Preferible si se utiliza el primer método ).
-
Si el proceso fue exitoso, al finalizar el proceso la pantalla LCD conectada a la placa debería de desplegar un fondo de color rojo (En versiones recientes del firmware el fondo es azul) y mostrar un texto blanco que diga "Welcome to Maixpy".
Alternativa: Utilizar una terminal serial (Como Putty), elegir el puerto COM en el que está conectado el MAIXDUINO y colocar un baudrate de 115200. Al abrir la consola y presionar el botón de reset del MAIXDUINO, se debería de mostrar un mensaje de bienvenida parecido al siguiente
[MAIXPY]Pll0:freq:832000000 [MAIXPY]Pll1:freq:398666666 [MAIXPY]Pll2:freq:45066666 [MAIXPY]cpu:freq:416000000 [MAIXPY]kpu:freq:398666666 [MAIXPY]Flash:0xc8:0x17 open second core... mallocmallocmallocmallocgc heap=0x8027cbb0-0x802fcbb0(524288) [MaixPy] init end __ __ _____ __ __ _____ __ __ | \/ | /\ |_ _| \ \ / / | __ \ \ \ / / | \ / | / \ | | \ V / | |__) | \ \_/ / | |\/| | / /\ \ | | > < | ___/ \ / | | | | / ____ \ _| |_ / . \ | | | | |_| |_| /_/ \_\ |_____| /_/ \_\ |_| |_| Official Site : https://www.sipeed.com Wiki : https://maixpy.sipeed.com MicroPython v0.5.0 on 2019-11-29; Sipeed_M1 with kendryte-k210 Type "help()" for more information.
-
Descargar el IDE proveído por los creadores de la placa para programarla en Micro-python. De preferencia elegir la versión más reciente. Durante las pruebas realizadas se utilizó la versión v0.2.4
-
Con el programa ya instalado, conectarse a la placa presionando el ícono de una cadena (2 eslabones) encontrado en la esquina inferior izquierda del IDE.
-
Elegir el puerto COM en el que está conectada la placa y presionar aceptar. La operación de conexión no debería durar más de 10-20s.
NOTA: Si la operación se extiende por un tiempo mayor, a la placa no se le instaló correctamente el firmware o se le colocó un modelo que se "comió" una parte no deseada de la memoria Flash. La placa no cuenta con regiones de memoria protegidas. Si el
.kmodelsubido a la placa abarca una región no deseada de la memoria, la placa deja de funcionar. En este caso, realizar lo descrito en la siguiente sección. -
Si la operación fue exitosa, el icono de la cadena debería de mostrarse ahora rojo y el botón de "play" de abajo debería de habilitarse. En
Archivo (File) > Ejemplos > 01 Basicsexiste el programahelloworld_1.pyel cual debería de desplegar un output por el puerto serial mientras se despliega el video captado por la cámara conectada al Maixduino. Se pueden descargar otros ejemplos del siguiente link. Estos se pueden acceder desde la IDE creando una carpeta en el folder de "Documentos" llamadaMaixPyy luego colocando el contenido del .zip descargado dentro.NOTA: Si se ejecutan los ejemplos de "Machine Vision" incluidos en los ejemplos el IDE comúnmente retornará un error similar al siguiente
ValueError: [MAIXPY]kpu: load error:2Ver la siguiente sección para resolver este problema.
NOTA: Este IDE tiene varias funcionalidades que lo hacen atractivo a utilizar, en particular las gráficas que genera de manera dinámica y el display de la pantalla que presenta dentro del IDE. A pesar de esto, se recomienda utilizar Visual Studio Code y PlatformIO para una experiencia más estable. Este IDE tiende a congelarse muy frecuentemente. Para volver a utilizarlo se debe finalizar la tarea con administrador de tareas o esperar a que reaccione (Muy tardado).
Probablemente el firmware se ha corrompido o el .kmodel subido a la placa cubrió una parte mayor de la memoria de lo que se esperaba. Para solucionarlo, re-descargar el firmware y reinstalar usando kflash_gui. Se recomienda que los modelos utilizados sean menores a 2.9 MB si se va a utilizar Micro-python como método para programar la placa. Si se utiliza Arduino o C el tamaño de los modelos puede ser mayor, aunque no se especifica el tamaño real.
Si se está iniciando con el proyecto o la placa retorna un error relacionado con la librería kpu, es probable que el procesador no cuente con el modelo necesario para implementar la red neuronal deseada. Se debe subir un archivo .kmodel.
Para los ejemplos de detección y reconocimiento facial (Encontrados bajo Archivo (File) > Carpeta de Documentos > MaixPy_Scripts-Master > Machine Vision) los modelos utilizados se encuentran en el siguiente link.
El ejemplo más sencillo de reconocimiento facial utilizando el Maixduino
-
Descargar el modelo denominado
face_model_at_0x300000.kfpkg. Para los board settings y serial settings utilizar los mismos settings utilizados al momento de subir el firmware a la placa por primera vez.- Los archivos
*.kfpkgse les puede cambiar la extensión a .zip. Luego de esto, estos se pueden extraer como si fueran un archivo comprimido normal. Si se quieren evitar complicaciones se puede subir el archivo.kfpkgdirectamente utilizandokflash_gui. En estos casos no se debe especificar una dirección en memoria en la cual se debe de subir. - Si el
.kfpkgse convierte en zip, adentro del nuevo zip debe existir un archivo de extensión.kmodely uno.json. El JSON puede eliminarse. El.kmodeldebe cargarse al MAIXDUINO utilizandokflash_gui.exe. En este caso si debe especificarse una dirección específica. El ejemplodemo_find_face.pycarga el modelo en la dirección 0x300000 (Este hexadecimal tiene cinco ceros).
- Los archivos
-
Si el proceso fue exitoso, la pantalla LCD debería de seguir desplegando la imagen que previamente estaba en pantalla. Por ejemplo, la pantalla de color rojo (O azul) con texto blanco en el centro.
NOTA: Si la pantalla se pone blanca luego de subir el modelo, el archivo de modelo subido era demasiado grande. Ver la sección anterior
-
Se debe instalar PlatformIO, abrir el ícono de la hormiguita en la barra izquierda y bajo el menú de "Quick access" se debe buscar la opción de "Miscellaneous". Dentro de esa opción hacer click en "New Terminal".
-
Se debe ejecutar el comando:
platformio platform install "kendryte210" -
Al finalizar la instalación, se va de nuevo a
Quick access(Presionar primero ícono de hormiguita en barra izquierda) y se hace click enOpenbajo la opción dePIO Home. En Home, ir a "Boards" y buscarSipeed MAIXDUINO. Si aparece una opción válida todo fue correctamente realizado. -
Regresar a "Home". Abrir un ejemplo metiéndose a
Project Examplesy buscarkendryte-standalone-sdk-hello -
Añadir el proyecto al workspace actual buscándolo dentro de la carpeta:
My PC\Documents\PlatformIO\Projects. El programa de "Hola mundo" estará dentro de la subcarpetasrc. -
Antes de comenzar a editar, abrir el archivo
platformio.inidentro de la carpeta del proyecto. Deberían de haber varios bloques de texto, todos empezando con el encabezado[env:sipeed-...]. Buscar el que dice[env:sipeed-maixduino]y borrar el resto (Para minimizar el tiempo de "build". Si se tiene otro board se pueden dejar los demás). Bajo la configuración se recomienda colocar lo siguiente:[env:sipeed-maixduino] platform = kendryte210 framework = kendryte-standalone-sdk upload_port = COM3 ; Seleccionar de acuerdo al puerto en el que se conecte el maixduino board = sipeed-maixduino monitor_speed = 115200
-
Ir a la esquina inferior izquierda de VSCode y buscar en la barra azul inferior un chequecito. Presionar ahí. La carpeta abierta pasa por un proceso de
build. Si todo fue exitoso, al finalizar debería de retornar[SUCCESS]en letras verdes. -
Para subir el programa al MAIXDUINO, presionar el botón de
->en la barra azul inferior de VSSTUDIO.
Fuentes
La información para todo lo descrito previamente se encuentra dispersa en múltiples sitios de internet. A continuación se listan algunas fuentes útiles empleadas como referencia para la redacción de esta sección:
-
Descargar la última versión de NNCase
NOTA: Ejecutar
ncc.exe. Si se presenta el error de un .dll faltante, descargar e instalar los siguientes drivers. Si no funciona la versión correspondiente al número de bits del sistema operativo instalado (x64 por ejemplo) instalar la otra versión (x32) -
Colocar el archivo
.tflite(Modelo de red neuronal) dentro de la misma carpeta en la que se encuentrancc.exe. -
En la consola, navegar hasta la carpeta en la que se colocaron ambos archivos y ejecutar alguno de los siguientes comandos para transformar el archivo
.tflitea.kmodel. Existen dos variaciones, una en la que se debe proveer al programa una parte de las imágenes que se utilizaron para entrenar la red neuronal y otro en la que no.-
Sin imágenes: Tomar en cuenta que NOMBRE es el nombre que se le colocó al archivo.
.\ncc compile .\NOMBRE.tflite .\NOMBRE.kmodel -i tflite --inference-type float -
Con imágenes: Hacer una carpeta dentro del folder actual y colocar el nombre de dicha carpeta donde dice RUTA. Esto no se probó. El modelo se creó utilizando el modelo anterior.
.\ncc compile .\model.tflite .\model.kmodel -i tflite --dataset .\RUTA
-
Fuentes
-
Instalar Tensorflow y Tensorflow-gpu ejecutando los siguientes comandos:
pip install tensorflow==1.14pip install tensorflow-gpu==1.14Para este ejemplo se requiere de tensorflow 1.14, ya que en versiones posteriores algunas funciones utilizadas por el ejemplo fueron descontinuadas y depreciadas. Si se desea utilizar la versión 1.2 o superior para algún otro uso, únicamente es necesario instalar
tensorflow-gpu. -
Descargar e instalar CUDA Toolkit de Nvidia. Asegurarse de descargar la versión 10.0 publicada en septiembre del 2018 (Versiones posteriores presentarán conflictos con Tensorflow). Tomar nota de la ruta de instalación.
-
Descargar cuDNN de Nvidia. Se le solicitará crear una cuenta. La estructura dentro de la carpeta descargada debería de ser la siguiente:
cuda | │ bin │ include │ lib └─── NVIDIA_SLA_cuDNN_Support.txt
-
Contrario al CUDA Toolkit, cuDNN debe instalarse manualmente. Para esto, navegar hasta la ruta de instalación del CUDA Toolkit (Por defecto:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0) y combinar el contenido de las carpetasbin,includeylibpresentes en la ruta de instalación, con el contenido descargado en la carpeta decudade cuDNN.NOTA: En caso de errores o dudas en torno a las librerías de CUDA, consultar la respuesta dada por Jozef Jarosciak en JetBrains o su guía más a detalle en joe0.com.
Existen dos tipos de algoritmos que pueden llegar a ser implementados utilizando machine vision:
-
Algoritmo que estima la probabilidad de que una imagen contenga un objeto específico.
- PROS: Fácil de implementar y entrenar
- CONS: Sin modificación, el algoritmo es óptimo para reconocer un único objeto en pantalla.
- Funcionamiento y Particularidades: Este retorna un valor entre 0 y 1 en función de que tan probable sea que un objeto se presente en pantalla. Si existen 2 categorías de objeto y se detecta la primera, lo más probable es que se retorne un vector de la siguiente forma: [0.995 0.005] (Una probabilidad alta para el primer objeto y una muy baja para el segundo). El problema con este algoritmo, es que si se presentan dos objetos simultáneos en una imagen, la estimación se torna imprecisa, ya que en el mejor de los casos, ambos objetos serán igualmente probables de existir en la imagen, entonces el vector de probabilidad retornado será similar al siguiente: [0.5 0.5]. Debido a valor cercano a 1 (0.8 - 0.99) se utiliza como un indicador para una detección adecuada, este vector resultaría en una detección nula de ambos objetos.
- Guía de implementación con MAIXDUINO
-
Una mejora del algoritmo anterior. Algoritmo que detecta en que sección de la imagen se presenta el objeto deseado, incluso colocándole una "bounding box" alrededor.
- PROS: Puede reconocer múltiples objetos en pantalla, en conjunto con su ubicación en la imagen
- CONS: Mucho más complejo de entrenar.
- Funciones y Particularidades: Para entrenarse, esta requiere de un "annotated" dataset, un dataset consistente de dos partes: Un conjunto de imágenes con los objetos que se desean detectar y un archivo que especifique en que sección de la pantalla se encuentran los objetos (Comúnmente dado en un archivo que establece las coordenadas de una boundary box). Si no se tiene una base de datos con ambas partes, comúnmente los propios investigadores deben "anotar" las imágenes especificando en que secciones se encuentra el objeto de interés.
- Guía de Implementación con MAIXDUINO
Para el caso de la aplicación en cuestión, se utilizará el segundo algoritmo. De esta manera, no solo se puede llegar a detectar si existen vehículos frente a la cámara, sino que simultáneamente se puede determinar su ubicación y movimiento relativo, facilitando la detección de si este está entrando, saliendo o está detenido. Por suerte, ya existen múltiples "annotated" datasets para vehículos, lo que facilita en gran medida el entrenamiento de la red neuronal.
A continuación se presentan algunas de las bases de datos o datasets encontrados para entrenar a la red neuronal en el reconocimiento de vehículos
-
PASCAL 2 VOC 2011: 28952 imágenes [1.2 GB] (50% test / 50% training). Se incluyen imágenes de 4 categorías distintas. Dentro de cada categoría existen datos para diferentes objetos
- Personas: Diferentes poses han sido catalogadas
- Animales: Pájaro, gato, vaca, perro, caballo y oveja
- Vehículos: Avión, bicicleta, bote, bus, carro, moto y tren
- Interiores: Botella, silla, mesa comedor, planta en maceta, sofá, tv/monitor.
Las anotaciones no solo incluyen boundary boxes sino que también incluyen lo que se le denomina como segmentaciones. Las segmentaciones son regiones coloreadas (Colores planos) que únicamente abarcan el objeto que se desea detectar. IMPORTANTE: Todas las imágenes se encuentran mezcladas en una sola carpeta. Existen archivos de texto que catalogan cada una de las categorías, no obstante, si se desea separarlas en carpetas lo más conveniente sería hacer un programa que tome los .txt que catalogan cada categoría y separe en carpetas distintas.
Formato de Anotaciones: XML
Forma: El formato que tienen las anotaciones es compatible con el formato requerido por YOLO (El algoritmo utilizado por las placas MAIX al ser programadas para utilizar el algoritmo 2).
<annotation> <folder>VOC2011</folder> <filename>2007_000243.jpg</filename> <source> <database>The VOC2007 Database</database> <annotation>PASCAL VOC2007</annotation> <image>flickr</image> </source> <size> <width>500</width> <height>333</height> <depth>3</depth> </size> <segmented>1</segmented> <object> <name>aeroplane</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>181</xmin> <ymin>127</ymin> <xmax>274</xmax> <ymax>193</ymax> </bndbox> </object> </annotation>
-
KITTI Object Detection: 14k imágenes [12 GB] (7518 test images / 7481 training images). Los vehículos se presentan en una variedad de posiciones, la desventaja es que la cámara permanece a la altura de un humano promedio. La anotación incluye, no solo bounding boxes sino que también información de la posición tridimensional de los vehículos relativo al ángulo de la cámara.
Formato de Anotaciones: TXT
Forma:
type truncated occluded alpha bbox dimensions location rotation_y score#Values Name Description ---------------------------------------------------------------------------- 1 type Describes the type of object: 'Car', 'Van', 'Truck', 'Pedestrian', 'Person_sitting', 'Cyclist', 'Tram', 'Misc' or 'DontCare' 1 truncated Float from 0 (non-truncated) to 1 (truncated), where truncated refers to the object leaving image boundaries 1 occluded Integer (0,1,2,3) indicating occlusion state: 0 = fully visible, 1 = partly occluded 2 = largely occluded, 3 = unknown 1 alpha Observation angle of object, ranging [-pi..pi] 4 bbox 2D bounding box of object in the image (0-based index): contains left, top, right, bottom pixel coordinates 3 dimensions 3D object dimensions: height, width, length (in meters) 3 location 3D object location x,y,z in camera coordinates (in meters) 1 rotation_y Rotation ry around Y-axis in camera coordinates [-pi..pi] 1 score Only for results: Float, indicating confidence in detection, needed for p/r curves, higher is better. -
Stanford Cars Dataset: 16k imágenes [1.6 GB] (196 clases diferentes). Las imágenes incluyen vehículos en una variedad de posiciones, así como cámaras posicionadas frente, por encima, detrás, a un lado de los vehículos. La anotación incluye únicamente una boundary box, en conjunto con la categoría a la que pertenece el carro.
Formato de Anotaciones: Vector MATLAB
Forma: [Relative Image Path, BBox X Coord 1, BBox Y Coord 1, BBox X Coord 2, BBox Y Coord 2, Label]
-
"Toyota Motor Europe" Motorway Dataset: Más de 30k imágenes distribuidas en 27 minutos de video, separados en 28 clips diferentes [6 GB]. Debido a que los videos fueron tomados por un vehículo especialmente equipado, todos los videos fueron grabados desde la perspectiva de un conductor. Como consecuencia las imágenes solo incluyen vehículos vistos desde atrás y parcialmente desde un lado. IMPORTANTE: Si se desea descargar y utilizar la base datos, se debe contactar a los propietarios de la misma. El dataset tiene contraseña y solo los propietarios cuentan con ella.
Se eligió el dataset de Stanford, debido a la disposición de las imágenes, la variedad de las mismas y el hecho que las anotaciones vienen en la forma de vector de Matlab (Algo que puede ser manipulado fácilmente para obtener el formato del XML que utiliza el algoritmo de YOLO, el mismo de la base de datos PASCAL VOC). A continuación se presenta un ejemplo del formato de los XML's a emplear.
<annotation verified="yes">
<folder>images</folder>
<filename>raccoon-1.jpg</filename>
<path>/Users/datitran/Desktop/raccoon/images/raccoon-1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>650</width>
<height>417</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>raccoon</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>81</xmin>
<ymin>88</ymin>
<xmax>522</xmax>
<ymax>408</ymax>
</bndbox>
</object>
</annotation>Muchos algoritmos para reconocimiento de objetos funcionan estableciendo las dimensiones de una "ventana de observación" y luego deslizando dicha ventana a lo largo de la imagen, generando estimaciones para la presencia de los objetos presentes en la base de datos. Esto se repite múltiples veces, con diferentes tamaños de ventanas, por lo que el proceso tiende a durar mucho tiempo (Algunos segundos). YOLO toma un diferente enfoque para acelerar las cosas
-
La imagen de entrada es dividida en una cuadrícula de SxS celdas.
-
S = No. celdas en las que se divide el largo y alto de la imagen.
-
-
Para cada celda se predicen B "bounding boxes" y C "probabilidades". Una celda está encargada de predecir si existe un objeto dentro de ella si se detecta que el centro del mismo existe dentro de la celda.
- B = No. de boundary boxes por celda
- C = Probabilidades por celda. Mismo número de probabilidades que de boundary boxes.
-
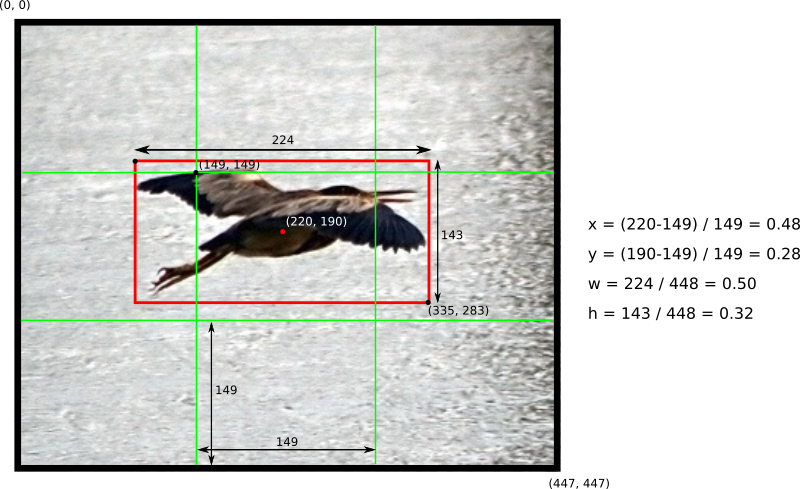
El output de la red neuronal consiste de un vector de 5 componentes: (x, y, w, h, confidence)
-
x: Coordenada X para el centro de la bounding box. Este valor se mide con respecto al origen de la celda central. Esta medida es luego normalizada para que x se encuentre en el intervalo [0, 1]
-
y: Coordenada Y para el centro de la bounding box. Normalizado de la misma manera que x
-
w: Ancho de la bounding box. Su magnitud está normalizada con respecto a las dimensiones completas de la imagen.
-
h: Alto de la bounding box. Normalizado de la misma manera que w
-
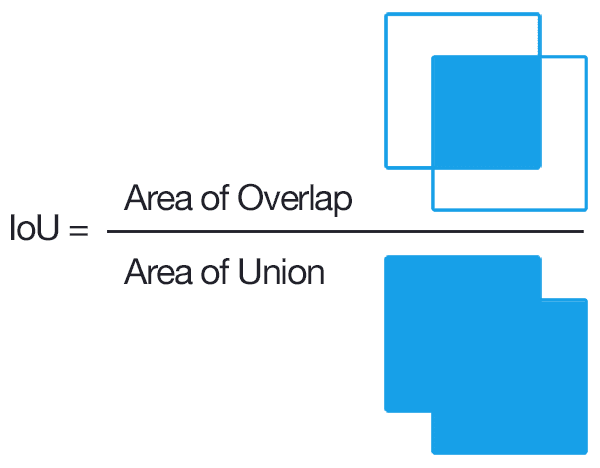
Confidence: Definido por el paper de YOLO como la probabilidad del objeto (
Pr(Class(i)|Object)) por el Intersection Over Union (IOU(Pred, Truth))-
IOU: Métrica utilizada como una manera para medir la similitud entre la bounding box deseada y la bounding box predicha. Esta simplemente consiste de la razón entre el área presente en la intersección entre ambas bounding boxes y el área total de ambas bounding boxes.
-
-

Aunque el funcionamiento general del algoritmo se encuentra explicado brevemente en la sección anterior, al momento de indagar un poco al respecto de su implementación, se hizo evidente que casi ninguna persona se ha dado a la tarea de recrear YOLO desde cero. Existen algunos tutoriales que explican la forma de recrear la arquitectura de YOLO v1, no obstante, para las dos versiones posteriores del algoritmo (v2 y v3) únicamente existen scripts cuya única instrucción de uso es: Cambie la línea 1, 3, 5... y luego haga click en run.
Por lo tanto, para las primeras pruebas de entrenamiento, se buscó una implementación ya establecida de YOLO v3. Se intentaron diferentes variedades de scripts, no obstante, aquel que presentaba la estructura de anotaciones más conveniente y más importante aún: que llegó a correr con las librerías de Keras y opencv fue el ejemplo proporcionado por Rokas Balsys.
Para hacer que el script corriera correctamente se siguieron los siguientes pasos:
-
Se clonó el repositorio proporcionado por el autor.
-
Utilizando el script de Matlab
XML_Generator.mlxse transfirieron los datos almacenados encars_annos.mat(Anotaciones del Stanford Cars Dataset) a archivos individuales XML compatibles con la estructura utilizada por el Pascal VOC Dataset. -
Utilizando el script de Matlab
Batch_Extractor.mlxse extrajo un total de 300 imágenes del Stanford Cars Dataset. El script debe ser ejecutado dos veces, una para extraer las imágenes y otra para extraer las anotaciones en formato XML. Los parámetros a cambiar son:- DirectorioBase: Ruta del folder que contiene las imágenes\anotaciones del dataset.
- DirectorioMod: Ruta donde se guardarán las muestras extraídas. La extracción crea una copia del archivo original. Los archivos en el directorio base no se modifican.
- FileFormat: Formato de los archivos a extraer. En la sección de imágenes colocar el formato de las mismas (
jpg,png, etc.). En la sección de etiquetas colocarxml - BatchSize: Tamaño del batch a extraer. Colocar el mismo número en tanto la sección de imágenes como de anotaciones.
-
Dentro del repositorio clonado, se colocó una nueva carpeta (Agregar una por cada objeto o clase para el que se desea entrenar al algoritmo) con la siguiente estructura:
main_folder │ convert.py │ image_detect.py │ realtime_detect.py │ train.py │ train_bottleneck.py │ logs │ model_data │ ... └─── Dataset │ └─── train │ └─── "Nombre Clase" (Ejemplo: car) -
Todas las imágenes y anotaciones extraídas utilizando
Batch_Extractor.mlxse colocaron dentro de la carpeta con el nombre de la clase para la que se desea entrenar (caren este caso. Crear una carpeta por clase). Las imágenes y los archivosxmldeben ir juntos dentro de la misma carpeta.NOTA: Evitar el uso de espacios en el nombre de folders y archivos. Algunos scripts de este ejemplo utilizan un tipo de parsing que no soporta la utilización de estos caracteres.
-
Dentro del main_folder crear un nuevo archivo
.py(En este caso se llamóVOC to YOLOv3.py) conteniendo el siguiente script:import xml.etree.ElementTree as ET from os import getcwd import os dataset_train = 'Dataset\\train\\' dataset_file = 'YOLOv3 Annotations.txt' classes_file = dataset_file[:-4]+'_classes.txt' CLS = os.listdir(dataset_train) # Lista de todos los elementos presentes dentro de la ruta especificada classes =[dataset_train+CLASS for CLASS in CLS] # Vector con las rutas relativas de todos los subfolders dentro de dataset_train def test(fullname): bb = "" in_file = open(fullname) # Abre el archivo tree = ET.parse(in_file) # Se "parsea" el archivo XML root = tree.getroot() # Root obtiene la estructura del XML pero codificada. Para verla en forma de texto debe utilizarse .text for _, obj in enumerate(root.iter('object')): # obj adquiere el valor de todas las subclases dentro de "object" difficult = obj.find('difficult').text # Parámetro dentro de "difficult" cls = obj.find('name').text # Parámetro dentro de "name" if cls not in CLS or int(difficult)==1: # Si el nombre de la clase no es igual al nombre de alguno de los folders dentro de "dataset" continue # Se pasa al siguiente elemento del ciclo for cls_id = CLS.index(cls) xmlbox = obj.find('bndbox') b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text)) bb += (" " + ",".join([str(a) for a in b]) + ',' + str(cls_id)) if bb != "": list_file = open(dataset_file, 'a') file_string = str(fullname)[:-4]+'.jpg'+bb+'\n' list_file.write(file_string) list_file.close() for CLASS in classes: for filename in os.listdir(CLASS): if not filename.endswith('.xml'): continue fullname = os.getcwd()+'\\'+CLASS+'\\'+filename test(fullname) for CLASS in CLS: list_file = open(classes_file, 'a') file_string = str(CLASS)+"\n" list_file.write(file_string) list_file.close()
En este, únicamente cambiar dos parámetros:
- dataset_train: Colocar la ruta relativa hacia la carpeta de
traincreada hace 2 pasos. Utilizar\\para separar cada folder o directorio incluido en la ruta. Asegurarse que el directorio actual de la consola de Python sea main_folder. - dataset_file: Nombre del nuevo archivo que generará el programa al finalizar su ejecución. Este traduce todos los XML a un único archivo para facilitar el parsing posterior del mismo. Su modificación es opcional.
NOTA: Si las imágenes del dataset se presentan en un formato distinto a
.jpgcambiar la mención de esta extensión en el script para acomodar el uso del nuevo formato. - dataset_train: Colocar la ruta relativa hacia la carpeta de
-
Ejecutar el script creado. El resultado deberían de ser dos archivos en el directorio actual de la consola de Python:
YOLOv3 Annotations.txtyYOLOv3 Annotations_classes.txt(Nombres por defecto). Tomar en cuenta que el script no tiene la habilidad de sobre-escribir un archivo ya existente. Para crear una nueva versión del mismo, eliminar primero el previo. -
[Opcional] La red neuronal se puede entrenar utilizando el CPU o la GPU de la computadora, pero se recomienda utilizar la GPU para acelerar significativamente la operación. Para conseguir que Python y Tensorflow reconozcan a la tarjeta gráfica seguir los pasos en esta sección.
-
Proceder a entrenar a la red neuronal. Para esto existen dos opciones. Utilizar el script
train.pyo el scripttrain_bottleneck.py. Para los parámetros a modificar en cada script, se recomienda leer la sección de Modify before training del tutorial redactado por el autor del ejemplo.-
train_bottleneck.py: No recomendadoTiempo de entrenamiento con 300 imágenes: +6 horas
Hardware empleado: Intel Core I7-4790k
Descripción: Utilizado para entrenar a la red neuronal cuando no existe una GPU. Este aprovecha computadoras con una alta cantidad de RAM y CPU. Durante las pruebas realizadas el entrenamiento se debió detener ya que únicamente la primera fase del mismo tomó 6 horas. De acuerdo a los estimados proporcionados por keras, la segunda fase hubiera tomado aún más. La única ventaja es que este método permite el uso de un batch size relativamente grande, no importando el procesador con el que se cuente.
-
train.py: RecomendadoTiempo de entrenamiento con 300 imágenes: 45 minutos
Hardware empleado: Nvidia GTX 780 Classified
Descripción: Utilizado cuando se tiene disponible una GPU con la cual trabajar. En la manera de lo posible, utilizar este script, pero asegurarse que durante su ejecución se esté empleando la GPU del sistema (Instalar CUDA. Ver paso opcional anterior para conseguir esto). Durante las pruebas realizadas, también se debió cambiar el bloque de código
import os os.environ["CUDA_VISIBLE_DEVICES"] = "0"
A la siguiente forma:
import os os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # see issue #152 os.environ["CUDA_VISIBLE_DEVICES"] = "0"
De la misma manera, dada la capacidad de la tarjeta gráfica utilizada, se debieron alterar los parámetros de batch size del script. Existen dos instancias de este parámetro. El primero se utiliza para entrenar únicamente las últimas capas de la red neuronal, por lo que su valor puede ser relativamente alto. El segundo se utiliza para entrenar a la totalidad de la red, por lo que debe ser más bajo. Durante las pruebas, se utilizaron los siguientes valores:
- Primer batch size: 16
- Segundo batch size: 1
Incluso con un segundo batch size de 1 se obtuvieron errores. No obstante, parece que el error no fue catastrófico, ya que a pesar de todo el programa finalizó el entrenamiento y generó un modelo válido.
-
-
Al finalizar, el programa genera un conjunto de modelos para la red neuronal dentro del directorio
logs\000. El modelo a utilizar se llamatrained_weights_final.h5