Forked from Froussios/Intro-To-RxJava, combine all pages into one for easy look-up.
Users expect real time data. They want their tweets now. Their order confirmed now. They need prices accurate as of now. Their online games need to be responsive. As a developer, you demand fire-and-forget messaging. You don't want to be blocked waiting for a result. You want to have the result pushed to you when it is ready. Even better, when working with result sets, you want to receive individual results as they are ready. You do not want to wait for the entire set to be processed before you see the first row. The world has moved to push; users are waiting for us to catch up. Developers have tools to push data, this is easy. Developers need tools to react to push data
Welcome to Rx. This book is based on Rx.NET's www.introtorx.com and it introduces beginners to RxJava, the Netflix implementation of the original Microsoft library. Rx is a powerful tool that enables the solution of problems in an elegant declarative style, familiar to functional programmers. Rx has several benefits:
- Unitive
- Queries in Rx are done in the same style as other libraries inspired by functional programming, such as Java streams. In Rx, one can use functional style transformations on event streams.
- Extensible
- RxJava can be extended with custom operators. Although Java does not allow for this to happen in an elegant way, RxJava offers all the extensibility one can find Rx implementations in other languages.
- Declarative
- Functional transformations are read in a declarative way.
- Composable
- Rx operators can be combined to produce more complicated operations.
- Transformative
- Rx operators can transform one type of data to another, reducing, mapping or expanding streams as needed.
Rx is fit for composing and consuming sequences of events. We present some of the use cases for Rx, according to www.introtorx.com
- UI events like mouse move, button click
- Domain events like property changed, collection updated, "Order Filled", "Registration accepted" etc.
- Infrastructure events like from file watcher, system and WMI events
- Integration events like a broadcast from a message bus or a push event from WebSockets API or other low latency middleware like Nirvana
- Integration with a CEP engine like StreamInsight or StreamBase.
- Result of
Futureor equivalent pattern
Those patterns are already well adopted and you may find that introducing Rx on top of that does not add to the development process.
- Translating iterables to observables, just for the sake of working on them through an Rx library.
Rx is based around two fundamental types, while several others expand the functionality around the core types. Those two core types are the Observable and the Observer, which will be introduced in this chapter. We will also introduce Subjects, which ease the learning curve.
Rx builds upon the Observer pattern. It is not unique in doing so. Event handling already exists in Java (e.g. JavaFX's EventHandler). Those are simpler approaches, which suffer in comparison to Rx:
- Events through event handlers are hard to compose.
- They cannot be queried over time
- They can lead to memory leaks
- These is no standard way of signaling completion.
- Require manual handling of concurrency and multithreading.
Observable is the first core element that we will see. This class contains a lot of the implementation of Rx, including all of the core operators. We will be examining it step by step throughout this book. For now, we must understand the Subscribe method. Here is one key overload of the method:
public final Subscription subscribe(Subscriber<? super T> subscriber)This is the method that you use to receive the values emitted by the observable. As the values come to be pushed (through policies that we will discuss throughout this book), they are pushed to the subscriber, which is then responsible for the behaviour intended by the consumer. The Subscriber here is an implementation of the Observer interface.
An observable pushes 3 kinds of events
- Values
- Completion, which indicates that no more values will be pushed.
- Errors, if something caused the sequence to fail. These events also imply termination.
We already saw one abstract implementation of the Observer, Subscriber. Subscriber implements some extra functionality and should be used as the basis for our implementations of Observer. For now, it is simpler to first understand the interface.
interface Observer<T> {
void onCompleted();
void onError(java.lang.Throwable e);
void onNext(T t);
}Those three methods are the behaviour that is executed every time the observable pushes a value. The observer will have its onNext called zero or more times, optionally followed by an onCompleted or an onError. No calls happen after a call to onError or onCompleted.
When developing Rx code, you'll see a lot of Observable, but not so much of Observer. While it is important to understand the Observer, there are shorthands that remove the need to instantiate it yourself.
You could manually implement Observer or extend Observable. In reality that will usually be unnecessary, since Rx already provides all the building blocks you need. It is also dangerous, as interaction between parts of Rx includes conventions and internal plumming that are not obvious to a beginner. It is both simpler and safer to use the many tools that Rx gives you for generating the functionality that you need.
To subscribe to an observable, it is not necessary to provide instances of Observer at all. There are overloads to subscribe that simply take the functions to be executed for onNext, onError and onSubscribe, hiding away the instantiation of the corresponding Observer. It is not even necessary to provide each of those functions. You can provide a subset of them, i.e. just onNext or just onNext and onError.
The introduction of lambda functions in Java 1.8 makes these overloads very convenient for the short examples that exist in this book.
Subjects are an extension of the Observable that also implements the Observer interface. The idea may sound odd at first, but they make things a lot simpler in some cases. They can have events pushed to them (like observers), which they then push further to their own subscribers (like observables). This makes them ideal entry points into Rx code: when you have values coming in from outside of Rx, you can push them into a Subject, turning them into an observable. You can think of them as entry points to an Rx pipeline.
Subject has two parameter types: the input type and the output type. This was designed so for the sake of abstraction and not because the common uses for subjects involve transforming values. There are transformation operators to do that, which we will see later.
There are a few different implementations of Subject. We will now examine the most important ones and their differences.
PublishSubject is the most straight-forward kind of subject. When a value is pushed into a PublishSubject, the subject pushes it to every subscriber that is subscribed to it at that moment.
public static void main(String[] args) {
PublishSubject<Integer> subject = PublishSubject.create();
subject.onNext(1);
subject.subscribe(System.out::println);
subject.onNext(2);
subject.onNext(3);
subject.onNext(4);
}2
3
4
As we can see in the example, 1 isn't printed because we weren't subscribed when it was pushed. After we subscribed, we began receiving the values that were pushed to the subject.
This is the first time we see subscribe being used, so it is worth paying attention to how it was used. In this case, we used the overload which expects one Function for the case of onNext. That function takes an argument of type Integer and returns nothing. Functions without a return type are also called actions. We can provide that function in different ways:
- we can supply an instance of
Action1<Integer>, - implicitly create one using a lambda expression or
- pass a reference to an existing method that fits the signature.
In this case,
System.out::printlnhas an overload that acceptsObject, so we passed a reference to it.subscribewill callprintlnwith the arriving values as the argument.
ReplaySubject has the special feature of caching all the values pushed to it. When a new subscription is made, the event sequence is replayed from the start for the new subscriber. After catching up, every subscriber receives new events as they come.
ReplaySubject<Integer> s = ReplaySubject.create();
s.subscribe(v -> System.out.println("Early:" + v));
s.onNext(0);
s.onNext(1);
s.subscribe(v -> System.out.println("Late: " + v));
s.onNext(2);Early:0
Early:1
Late: 0
Late: 1
Early:2
Late: 2
All the values are received by the subscribers, even though one was late. Also notice that the late subscriber had everything replayed to it before proceeding to the next value.
Caching everything isn't always a good idea, as an observable sequence can run for a long time. There are ways to limit the size of the internal buffer. ReplaySubject.createWithSize limits the size of the buffer, while ReplaySubject.createWithTime limits how long an object can stay cached.
ReplaySubject<Integer> s = ReplaySubject.createWithSize(2);
s.onNext(0);
s.onNext(1);
s.onNext(2);
s.subscribe(v -> System.out.println("Late: " + v));
s.onNext(3);Late: 1
Late: 2
Late: 3
Our late subscriber now missed the first value, which fell off the buffer of size 2. Similarily, old values fall off the buffer as time passes, when the subject is created with createWithTime
ReplaySubject<Integer> s = ReplaySubject.createWithTime(150, TimeUnit.MILLISECONDS,
Schedulers.immediate());
s.onNext(0);
Thread.sleep(100);
s.onNext(1);
Thread.sleep(100);
s.onNext(2);
s.subscribe(v -> System.out.println("Late: " + v));
s.onNext(3);Late: 1
Late: 2
Late: 3
Creating a ReplaySubject with time requires a Scheduler, which is Rx's way of keeping time. Feel free to ignore this for now, as we will properly introduce schedulers in the chapter about concurrency.
ReplaySubject.createWithTimeAndSize limits both, which ever comes first.
BehaviorSubject only remembers the last value. It is similar to a ReplaySubject with a buffer of size 1. An initial value can be provided on creation, therefore guaranteeing that a value always will be available immediately on subscription.
BehaviorSubject<Integer> s = BehaviorSubject.create();
s.onNext(0);
s.onNext(1);
s.onNext(2);
s.subscribe(v -> System.out.println("Late: " + v));
s.onNext(3);Late: 2
Late: 3
The following example just completes, since that is the last event.
BehaviorSubject<Integer> s = BehaviorSubject.create();
s.onNext(0);
s.onNext(1);
s.onNext(2);
s.onCompleted();
s.subscribe(
v -> System.out.println("Late: " + v),
e -> System.out.println("Error"),
() -> System.out.println("Completed")
);An initial value is provided to be available if anyone subscribes before the first value is pushed.
BehaviorSubject<Integer> s = BehaviorSubject.create(0);
s.subscribe(v -> System.out.println(v));
s.onNext(1);0
1
Since the defining role of a BehaviorSubject is to always have a value readily available, it is unusual to create one without an initial value. It is also unusual to terminate one.
AsyncSubject also caches the last value. The difference now is that it doesn't emit anything until the sequence completes. Its use is to emit a single value and immediately complete.
AsyncSubject<Integer> s = AsyncSubject.create();
s.subscribe(v -> System.out.println(v));
s.onNext(0);
s.onNext(1);
s.onNext(2);
s.onCompleted();2
Note that, if we didn't do s.onCompleted();, this example would have printed nothing.
As we already mentioned, there are contracts in Rx that are not obvious in the code. An important one is that no events are emitted after a termination event (onError or onCompleted). The implemented subjects respect that, and the subscribe method also prevents some violations of the contract.
Subject<Integer, Integer> s = ReplaySubject.create();
s.subscribe(v -> System.out.println(v));
s.onNext(0);
s.onCompleted();
s.onNext(1);
s.onNext(2);0
Safety nets like these are not guaranteed in the entirety of the implementation of Rx. It is best that you are mindful not to violate the contract, as this may lead to undefined behaviour.
The idea behind Rx is that it is unknown when a sequence emits values or terminates, but you still have control over when you begin and stop accepting values. Subscriptions may be linked to allocated resources that you will want to release at the end of a sequence. Rx provides control over your subscriptions to enable you to do that.
There are several overloads to Observable.subscribe, which are shorthands for the same thing.
Subscription subscribe()
Subscription subscribe(Action1<? super T> onNext)
Subscription subscribe(Action1<? super T> onNext, Action1<java.lang.Throwable> onError)
Subscription subscribe(Action1<? super T> onNext, Action1<java.lang.Throwable> onError, Action0 onComplete)
Subscription subscribe(Observer<? super T> observer)
Subscription subscribe(Subscriber<? super T> subscriber)subscribe() consumes events but performs no actions. The overloads that take one or more Action will construct a Subscriber with the functions that you provide. Where you don't give an action, the event is practically ignored.
In the following example, we handle the error of a sequence that failed.
Subject<Integer, Integer> s = ReplaySubject.create();
s.subscribe(
v -> System.out.println(v),
e -> System.err.println(e));
s.onNext(0);
s.onError(new Exception("Oops"));Output
0
java.lang.Exception: Oops
If we do not provide a function for error handling, an OnErrorNotImplementedException will be thrown at the point where s.onError is called, which is the producer's side. It happens here that the producer and the consumer are side-by-side, so we could do a traditional try-catch. However, on a compartmentalised system, the producer and the subscriber very often are in different places. Unless the consumer provides a handle for errors to subscribe, they will never know that an error has occured and that the sequence was terminated.
You can also stop receiving values before a sequence terminates. Every subscribe overload returns an instance of Subscription, which is an interface with 2 methods:
boolean isUnsubscribed()
void unsubscribe()Calling unsubscribe will stop events from being pushed to your observer.
Subject<Integer, Integer> values = ReplaySubject.create();
Subscription subscription = values.subscribe(
v -> System.out.println(v),
e -> System.err.println(e),
() -> System.out.println("Done")
);
values.onNext(0);
values.onNext(1);
subscription.unsubscribe();
values.onNext(2);0
1
Unsubscribing one observer does not interfere with other observers on the same observable.
Subject<Integer, Integer> values = ReplaySubject.create();
Subscription subscription1 = values.subscribe(
v -> System.out.println("First: " + v)
);
Subscription subscription2 = values.subscribe(
v -> System.out.println("Second: " + v)
);
values.onNext(0);
values.onNext(1);
subscription1.unsubscribe();
System.out.println("Unsubscribed first");
values.onNext(2);First: 0
Second: 0
First: 1
Second: 1
Unsubscribed first
Second: 2
onError and onCompleted mean the termination of a sequence. An observable that complies with the Rx contract will not emit anything after either of those events. This is something to note both when consuming in Rx and when implementing your own observables.
Subject<Integer, Integer> values = ReplaySubject.create();
Subscription subscription1 = values.subscribe(
v -> System.out.println("First: " + v),
e -> System.out.println("First: " + e),
() -> System.out.println("Completed")
);
values.onNext(0);
values.onNext(1);
values.onCompleted();
values.onNext(2);First: 0
First: 1
Completed
A Subscription is tied to the resources it uses. For that reason, you should remember to dispose of subscriptions. You can create the binding between a Subscription and the necessary resources using the Subscriptions factory.
Subscription s = Subscriptions.create(() -> System.out.println("Clean"));
s.unsubscribe();Clean
Subscriptions.create takes an action that will be executed on unsubscription to release the resources. There also are shorthand for common actions when creating a sequence.
Subscriptions.empty()returns aSubscriptionthat does nothing when disposed. This is useful when you are required to return an instance ofSubscription, but your implementation doesn't actually need to release any resources.Subscriptions.from(Subscription... subscriptions)returns aSubscriptionthat will dispose of multiple other subscriptions when it is disposed.Subscriptions.unsubscribed()returns aSubscriptionthat is already disposed of.
There are several implementations of Subscription.
BooleanSubscriptionCompositeSubscriptionMultipleAssignmentSubscriptionRefCountSubscriptionSafeSubscriberScheduler.WorkerSerializedSubscriberSerialSubscriptionSubscriberTestSubscriber
We will see more of them later in this book. It is interesting to note that Subscriber also implements Subscription. This means that we can also use a reference to a Subscriber to terminate a subscription.
Now that you understand what Rx is in general, it is time to start creating and manipulating sequences. The original implementation of manipulating sequences was based on C#'s LINQ, which in turn was inspired from functional programming. Knowledge about either isn't necessary, but it would make the learning process a lot easier for the reader. Following the original www.introtorx.com, we too will divide operations into themes that generally go from the simpler to the more advanced. Most Rx operators manipulate existing sequences. But first, we will see how to create an Observable to begin with.
In previous examples we used Subjects and manually pushed values into them to create a sequence. We used that sequence to demonstrate some key concepts and the first and most important Rx method, subscribe. In most cases, subjects are not the best way to create a new Observable. We will now see tidier ways to create observable sequences.
The just method creates an Observable that will emit a predifined sequence of values, supplied on creation, and then terminate.
Observable<String> values = Observable.just("one", "two", "three");
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Received: one
Received: two
Received: three
Completed
This observable will emit a single onCompleted and nothing else.
Observable<String> values = Observable.empty();
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Completed
This observable will never emit anything
Observable<String> values = Observable.never();
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);The code above will print nothing. Note that this doesn't mean that the program is blocking. In fact, it will terminate immediately.
This observable will emit a single error event and terminate.
Observable<String> values = Observable.error(new Exception("Oops"));
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Error: java.lang.Exception: Oops
defer doesn't define a new kind of observable, but allows you to declare how an observable should be created every time a subscriber arrives. Consider how you would create an observable that returns the current time and terminates. You are emitting a single value, so it sounds like a case for just.
Observable<Long> now = Observable.just(System.currentTimeMillis());
now.subscribe(System.out::println);
Thread.sleep(1000);
now.subscribe(System.out::println);1431443908375
1431443908375
Notice how the two subscribers, 1 second apart, see the same time. That is because the value for the time is aquired once: when execution reaches just. What you want is for the time to be aquired when a subscriber asks for it by subscribing. defer takes a function that will executed to create and return the Observable. The Observable returned by the function is also the Observable returned by defer. The important thing here is that this function will be executed again for every new subscription.
Observable<Long> now = Observable.defer(() ->
Observable.just(System.currentTimeMillis()));
now.subscribe(System.out::println);
Thread.sleep(1000);
now.subscribe(System.out::println);1431444107854
1431444108858
create is a very powerful function for creating observables. Let have a look at the signature.
static <T> Observable<T> create(Observable.OnSubscribe<T> f)The Observable.OnSubscribe<T> is simpler than it looks. It is basically a function that takes a Subscriber<T> for type T. Inside it we can manually determine the events that are pushed to the subscriber.
Observable<String> values = Observable.create(o -> {
o.onNext("Hello");
o.onCompleted();
});
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Received: Hello
Completed
When someone subscribes to the observable (here: values), the corresponding Subscriber instance is passed to your function. As the code is executed, values are being pushed to the subscriber. Note that you have to call onCompleted in the end by yourself, if you want the sequence to signal its completion.
This method should be your preferred way of creating a custom observable, when none of the existing shorthands serve your purpose. The code is similar to how we created a Subject and pushed values to it, but there are a few important differences. First of all, the source of the events is neatly encapsulated and separated from unrelated code. Secondly, Subjects carry dangers that are not obvious: with a Subject you are managing state, and anyone with access to the instance can push values into it and alter the sequence. We will see more about this issue later on.
Another key difference to using subjects is that the code is executed lazily, when and if an observer subscribes. In the example above, the code is run not when the observable is created (because there is no Subscriber yet), but each time subscribe is called. This means that every value is generated again for each subscriber, similar to ReplaySubject. The end result is similar to a ReplaySubject, except that no caching takes place. However, if we had used a ReplaySubject, and the creation method was time-consuming, that would block the thread that executes the creation. You'd have to manually create a new thread to push values into the Subject. We're not presenting Rx's methods for concurrency yet, but there are convenient ways to make the execution of the onSubscribe function concurrently.
You may have already noticed that you can trivially implement any of the previous observables using Observable.create. In fact, our example for create is equivalent to Observable.just("hello").
In functional programming it is common to create sequences of unrestricted or infinite length. RxJava has factory methods that create such sequences.
A straight forward and familiar method to any functional programmer. It emits the specified range of integers.
Observable<Integer> values = Observable.range(10, 15);The example emits the values from 10 to 24 in sequence.
This function will create an infinite sequence of ticks, separated by the specified time duration.
Observable<Long> values = Observable.interval(1000, TimeUnit.MILLISECONDS);
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);
System.in.read();Received: 0
Received: 1
Received: 2
Received: 3
...
This sequence will not terminate until we unsubscribe.
We should note why the blocking read at the end is necessary. Without it, the program terminates without printing something. That's because our operations are non-blocking: we create an observable that will emit values over time, then we register the actions to execute if and when values arrive. None of that is blocking and the main thread proceeds to terminate. The timer that produces the ticks runs on its own thread, which does not prevent the JVM from terminating, killing the timer with it.
There are two overloads to Observable.timer. The first example creates an observable that waits a given amount of time, then emits 0L and terminates.
Observable<Long> values = Observable.timer(1, TimeUnit.SECONDS);
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Received: 0
Completed
The second one will wait a specified amount of time, then begin emitting like interval with the given frequency.
Observable<Long> values = Observable.timer(2, 1, TimeUnit.SECONDS);
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Received: 0
Received: 1
Received: 2
...
The example above waits 2 seconds, then starts counting every 1 second.
There are well established tools for dealing with sequences, collections and asychronous events, which may not be directly compatible with Rx. Here we will discuss ways to turn their output into input for your Rx code.
If you are using an asynchronous tool that uses event handlers, like JavaFX, you can use Observable.create to turn the streams into an observable
Observable<ActionEvent> events = Observable.create(o -> {
button2.setOnAction(new EventHandler<ActionEvent>() {
@Override public void handle(ActionEvent e) {
o.onNext(e)
}
});
})Depending on what the event is, the event type (here ActionEvent) may be meaningful enough to be the type of your sequence. Very often you will want something else, like the contents of a field. The place to get the value is in the handler, while the GUI thread is blocked by the handler and the field value is relevant. There is no guarantee what the value will be by the time the value reaches the final Subscriber. On the other hand, a value moving though an observable should remain unchanged, if the pipeline is properly implemented.
Much like most of the functions we've seen so far, you can turn any kind of input into an Rx observable with create. There are several shorthands for converting common types of input.
Futures are part of the Java framework and you may come across them while using frameworks that use concurrency. They are a less powerful concept for concurrency than Rx, since they only return one value. Naturally, you'd like to them into observables.
FutureTask<Integer> f = new FutureTask<Integer>(() -> {
Thread.sleep(2000);
return 21;
});
new Thread(f).start();
Observable<Integer> values = Observable.from(f);
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Received: 21
Completed
The observable emits the result of the FutureTask when it is available and then terminates. If the task is canceled, the observable will emit a java.util.concurrent.CancellationException error.
If you're interested in the results of the Future for a limited amount of time, you can provide a timeout period like this
Observable<Integer> values = Observable.from(f, 1000, TimeUnit.MILLISECONDS);If the Future has not completed the specified amount of time, the observable will ignore it and fail with a TimeoutException.
You can also turn any collection into an observable using the overloads of Observable.from that take arrays and iterables. This will result in every item in the collection being emitted and then a final onCompleted event.
Integer[] is = {1,2,3};
Observable<Integer> values = Observable.from(is);
Subscription subscription = values.subscribe(
v -> System.out.println("Received: " + v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Received: 1
Received: 2
Received: 3
Completed
Observable is not interchangeable with Iterable or Stream. Observables are push-based, i.e., the call to onNext causes the stack of handlers to execute all the way to the final subscriber method (unless specified otherwise). The other models are pull-based, which means that values are requested as soon as possible and execution blocks until the result is returned.
The examples we've seen so far were all very small. Nothing should stop you from using Rx on a huge stream of realtime data, but what good would Rx be if it dumped the whole bulk of the data onto you, and force you handle it like you would otherwise? Here we will explore operators that can filter out irrelevant data, or reduce the data to the single value that you want.
Most of the operators here will be familiar to anyone who has worked with Java's Streams or functional programming in general. All the operators here return a new observable and do not affect the original observable. This principle is present throughout Rx. Transformations of observables create a new observable every time and leave the original unaffected. Subscribers to the original observable should notice no change, but we will see in later chapters that guaranteeing this may require caution from the developer as well.
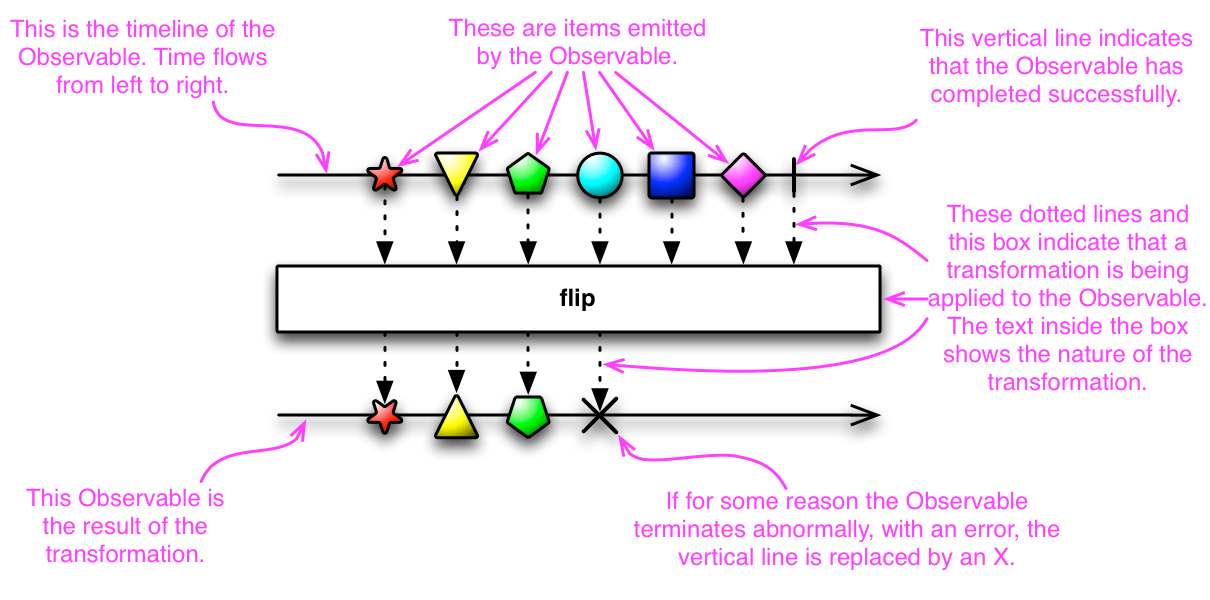
This is an appropriate time to introduce to concept of marble diagrams. It is a popular way of explaining the operators in Rx, because of their intuitive and graphical nature. They are present a lot in the documentation of RxJava and it only makes sense that we take advantage of their explanatory nature. The format is mostly self-explanatory: time flows left to right, shapes represent values, a slash is a onCompletion, an X is an error. The operator is applied to the top sequence and the result is the sequence below.
filter takes a predicate function that makes a boolean decision for each value emitted. If the decision is false, the item is omitted from the filtered sequence.
public final Observable<T> filter(Func1<? super T,java.lang.Boolean> predicate)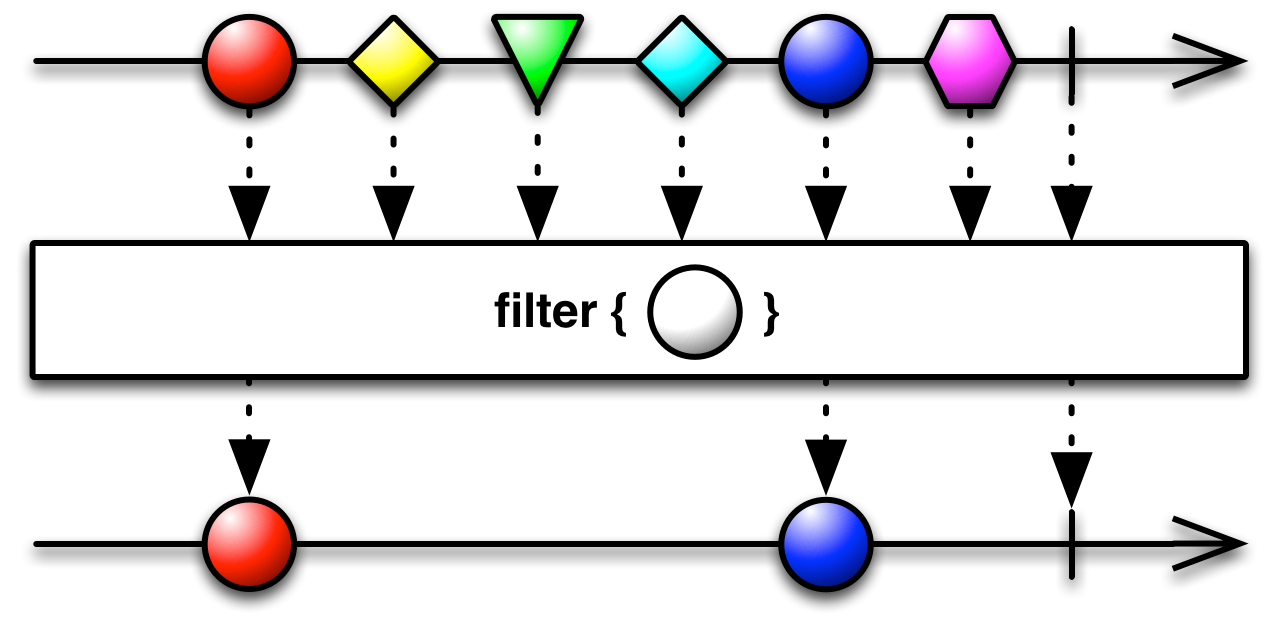
We will use filter to create a sequence of numbers and filter out all the even ones, keeping only odd values.
Observable<Integer> values = Observable.range(0,10);
Subscription oddNumbers = values
.filter(v -> v % 2 == 0)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);0
2
4
6
8
Completed
distinct filters out any element that has already appeared in the sequence.
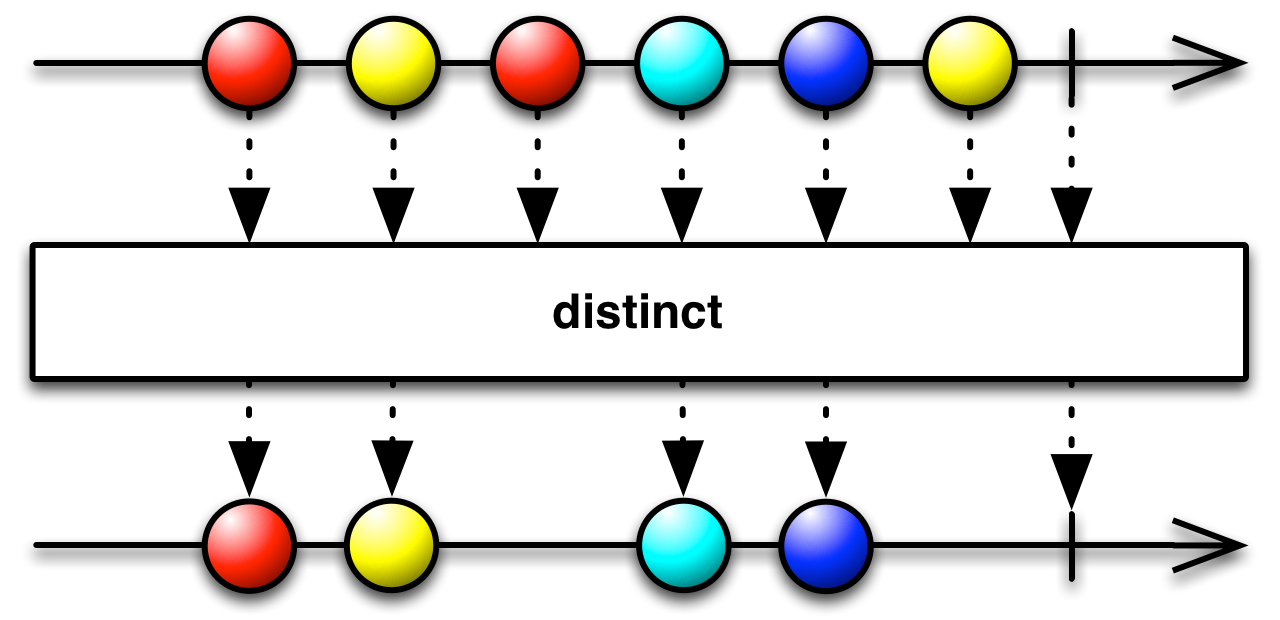
Observable<Integer> values = Observable.create(o -> {
o.onNext(1);
o.onNext(1);
o.onNext(2);
o.onNext(3);
o.onNext(2);
o.onCompleted();
});
Subscription subscription = values
.distinct()
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);1
2
3
Completed
An overload of distinct takes a key selector. For each item, the function generates a key and the key is then used to determine distinctiveness.
public final <U> Observable<T> distinct(Func1<? super T,? extends U> keySelector)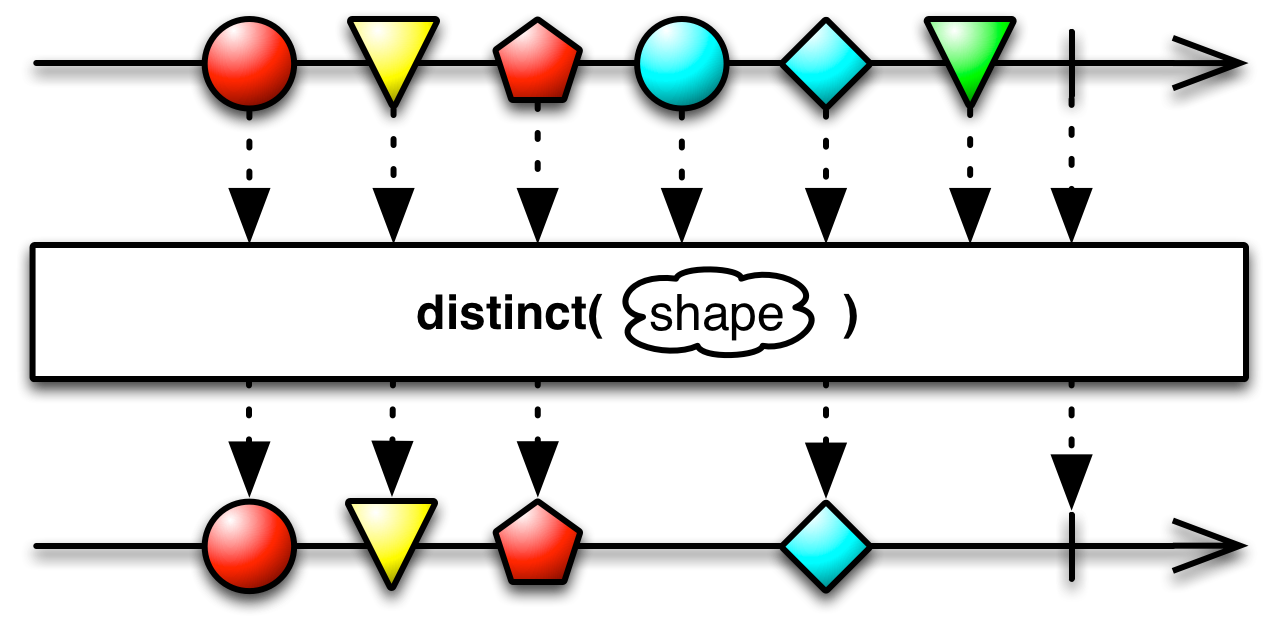
In this example, we use the first character as a key.
Observable<String> values = Observable.create(o -> {
o.onNext("First");
o.onNext("Second");
o.onNext("Third");
o.onNext("Fourth");
o.onNext("Fifth");
o.onCompleted();
});
Subscription subscription = values
.distinct(v -> v.charAt(0))
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);First
Second
Third
Completed
"Fourth" and "Fifth" were filtered out because their first character is 'F' and that has already appeared in "First".
An experienced programmer already knows that this operator maintains a set internally with every unique value that passes through the observable and checks every new value against it. While Rx operators neatly hide these things, you should still be aware that an Rx operator can have a significant cost and consider what you are using it on.
A variant of distinct is distinctUntilChanged. The difference is that only consecutive non-distinct values are filtered out.
public final Observable<T> distinctUntilChanged()
public final <U> Observable<T> distinctUntilChanged(Func1<? super T,? extends U> keySelector)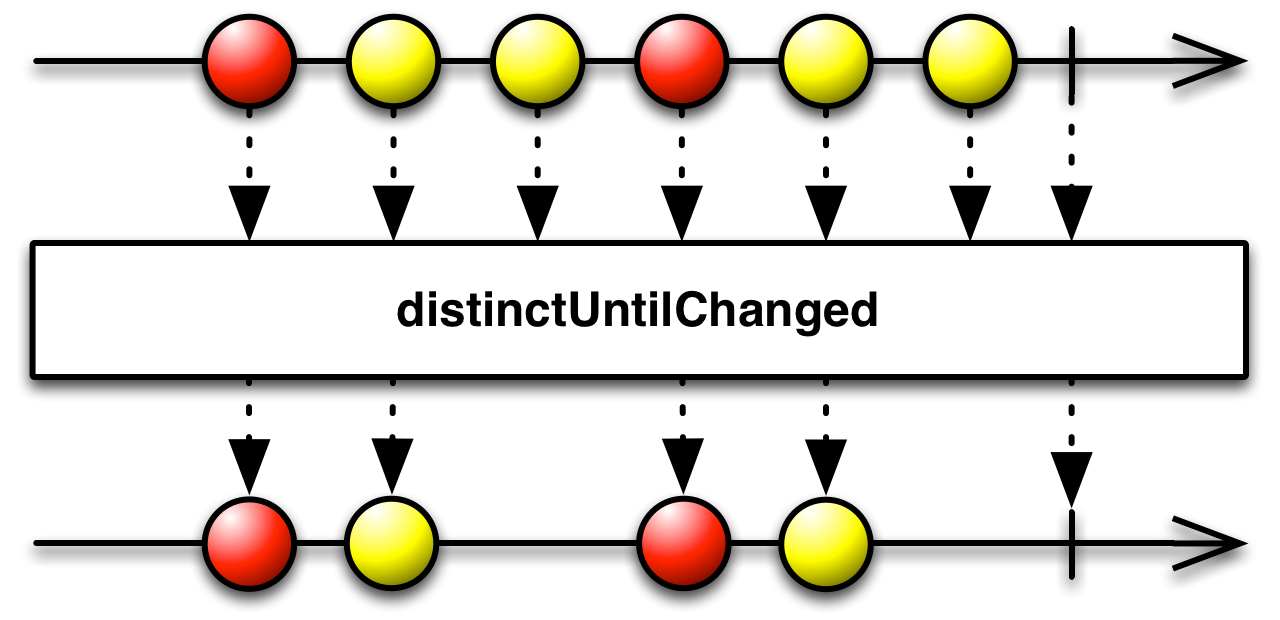
Observable<Integer> values = Observable.create(o -> {
o.onNext(1);
o.onNext(1);
o.onNext(2);
o.onNext(3);
o.onNext(2);
o.onCompleted();
});
Subscription subscription = values
.distinctUntilChanged()
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);1
2
3
2
Completed
You can you use a key selector with distinctUntilChanged, as well.
Observable<String> values = Observable.create(o -> {
o.onNext("First");
o.onNext("Second");
o.onNext("Third");
o.onNext("Fourth");
o.onNext("Fifth");
o.onCompleted();
});
Subscription subscription = values
.distinctUntilChanged(v -> v.charAt(0))
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);First
Second
Third
Fourth
Completed
ignoreElements will ignore every value, but lets pass through onCompleted and onError.
Observable<Integer> values = Observable.range(0, 10);
Subscription subscription = values
.ignoreElements()
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Completed
ignoreElements() produces the same result as filter(v -> false)
The next group of methods serve to cut the sequence at a specific point based on the item's index, and either take the first part or the second part. take takes the first n elements, while skip skips them. Note that neither function considers it an error if there are fewer items in the sequence than the specified index.
Observable<T> take(int num)
Observable<Integer> values = Observable.range(0, 5);
Subscription first2 = values
.take(2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);0
1
Completed
Users of Java 8 streams should know the take operator as limit. The limit operator exists in Rx too, for symmetry purposes. It is an alias of take, but it lacks the richer overloads that we will soon see.
take completes as soon as the n-th item is available. If an error occurs, the error will be forwarded, but not if it occurs after the cutting point. take doesn't care what happens in the observable after the n-th item.
Observable<Integer> values = Observable.create(o -> {
o.onNext(1);
o.onError(new Exception("Oops"));
});
Subscription subscription = values
.take(1)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);1
Completed
skip returns the other half of a take.
Observable<T> skip(int num)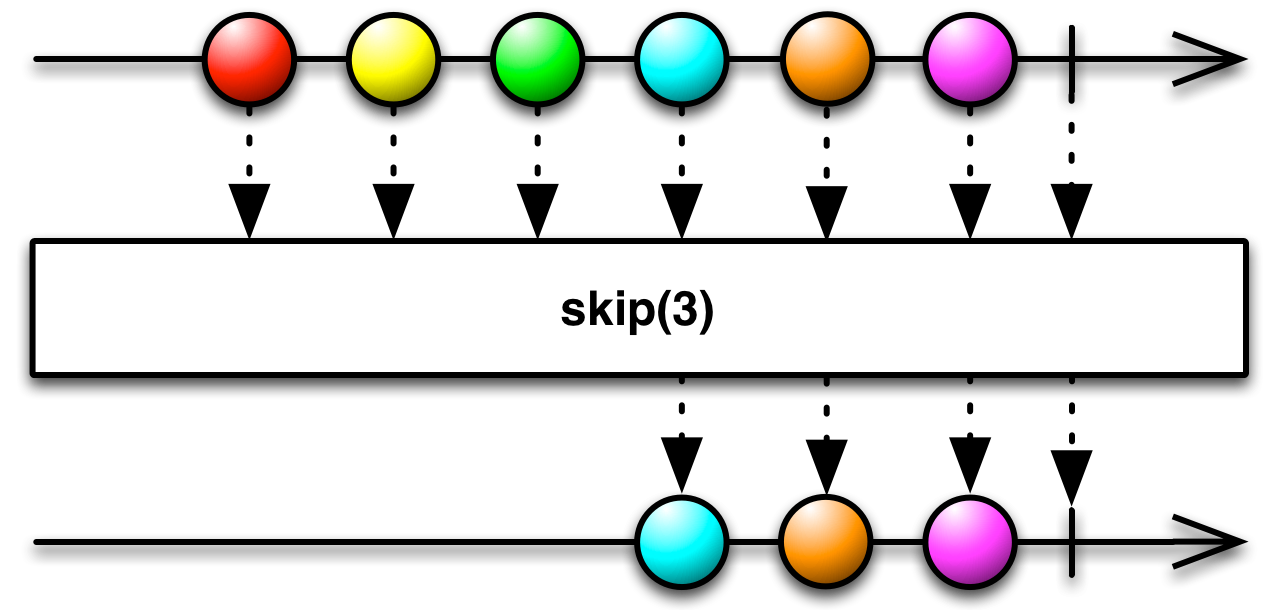
Observable<Integer> values = Observable.range(0, 5);
Subscription subscription = values
.skip(2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);2
3
4
Completed
There are overloads where the cutoff is a moment in time rather than place in the sequence.
Observable<T> take(long time, java.util.concurrent.TimeUnit unit)
Observable<T> skip(long time, java.util.concurrent.TimeUnit unit)Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
Subscription subscription = values
.take(250, TimeUnit.MILLISECONDS)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);0
1
Completed
take and skip work with predefined indices. If you want to "discover" the cutoff point as the values come, takeWhile and skipWhile will use a predicate instead. takeWhile takes items while a predicate function returns true
Observable<T> takeWhile(Func1<? super T,java.lang.Boolean> predicate)Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
Subscription subscription = values
.takeWhile(v -> v < 2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);0
1
Completed
As you would expect, skipWhile returns the other half of the sequence
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
Subscription subscription = values
.skipWhile(v -> v < 2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);2
3
4
...
skipLast and takeLast work just like take and skip, with the difference that the point of reference is from the end.
Observable<Integer> values = Observable.range(0,5);
Subscription subscription = values
.skipLast(2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);0
1
2
Completed
By now you should be able to guess how takeLast is related to skipLast. There are overloads for both indices and time.
There are also two methods named takeUntil and skipUntil. takeUntil works exactly like takeWhile except that it takes items while the predictate is false. The same is true of skipUntil.
Along with that, takeUntil and skipUntil each have a very interesting overload. The cutoff point is defined as the moment when another observable emits an item.
public final <E> Observable<T> takeUntil(Observable<? extends E> other)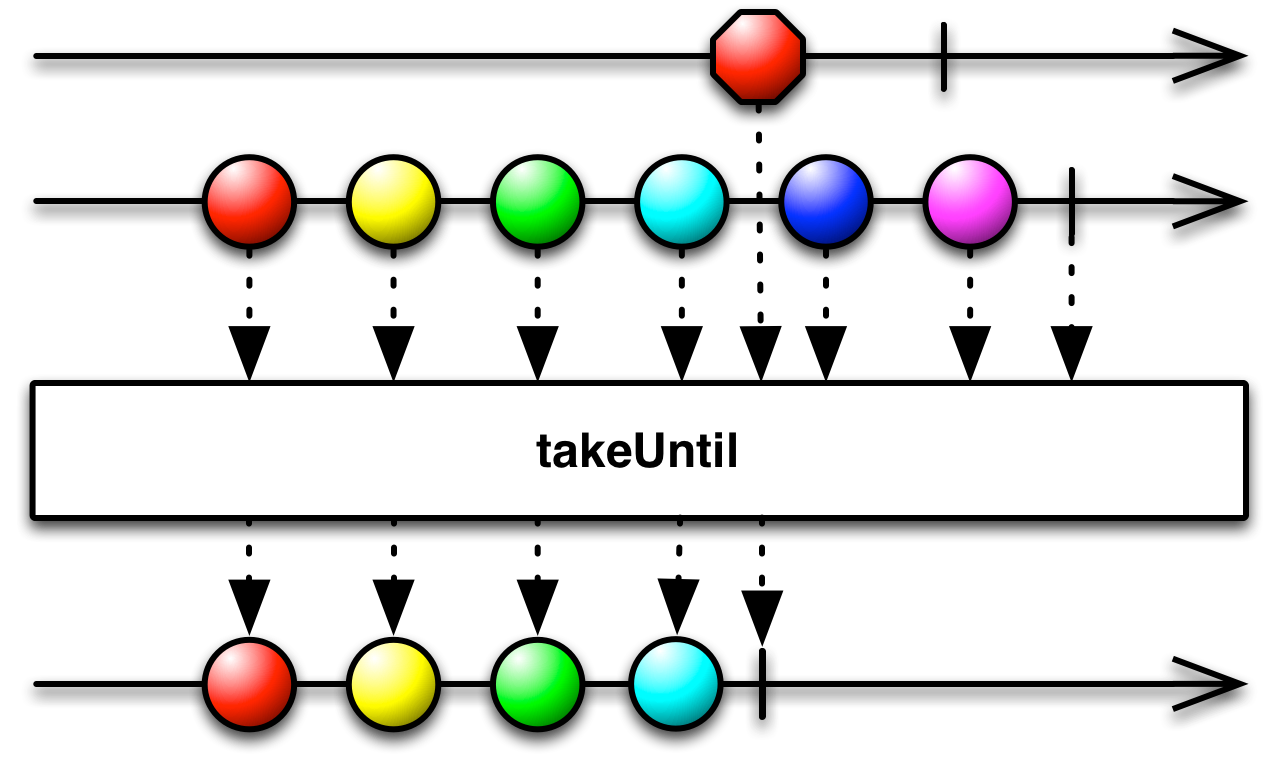
Observable<Long> values = Observable.interval(100,TimeUnit.MILLISECONDS);
Observable<Long> cutoff = Observable.timer(250, TimeUnit.MILLISECONDS);
Subscription subscription = values
.takeUntil(cutoff)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);0
1
Completed
As you may remember, timer here will wait 250ms and emit one event. This signals takeUntil to stop the sequence. Note that the signal can be of any type, since the actual value is not used.
Once again skipUntil works by the same rules and returns the other half of the observable. Values are ignored until the signal comes to start letting values pass through.
Observable<Long> values = Observable.interval(100,TimeUnit.MILLISECONDS);
Observable<Long> cutoff = Observable.timer(250, TimeUnit.MILLISECONDS);
Subscription subscription = values
.skipUntil(cutoff)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);2
3
4
...
In the previous chapter we just saw ways to filter out data that we don't care about. Sometimes what we want is information about the sequence rather than the values themselves. We will now introduce some methods that allow us to reason about a sequence.
The all method establishes that every value emitted by an observable meets a criterion. Here's the signature and an example:
public final Observable<java.lang.Boolean> all(Func1<? super T,java.lang.Boolean> predicate)Observable<Integer> values = Observable.create(o -> {
o.onNext(0);
o.onNext(10);
o.onNext(10);
o.onNext(2);
o.onCompleted();
});
Subscription evenNumbers = values
.all(i -> i % 2 == 0)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);true
Completed
An interesting fact about this method is that it returns an observable with a single value, rather than the boolean value directly. This is because it is unknown how long it will take to establish whether the result should be true or false. Even though it completes as soon as it can know, that may take as long the source sequence itself. As soon as an item fails the predicate, false will be emitted. A value of true on the other hand cannot be emitted until the source sequence has completed and all of the items are checked. Returning the decision inside an observable is a convenient way of making the operation non-blocking. We can see all failing as soon as possible in the next example:
Observable<Long> values = Observable.interval(150, TimeUnit.MILLISECONDS).take(5);
Subscription subscription = values
.all(i -> i<3) // Will fail eventually
.subscribe(
v -> System.out.println("All: " + v),
e -> System.out.println("All: Error: " + e),
() -> System.out.println("All: Completed")
);
Subscription subscription2 = values
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);0
1
2
All: false
All: Completed
3
4
Completed
If the source observable emits an error, then all becomes irrelevant and the error passes through, terminating the sequence.
Observable<Integer> values = Observable.create(o -> {
o.onNext(0);
o.onNext(2);
o.onError(new Exception());
});
Subscription subscription = values
.all(i -> i % 2 == 0)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Error: java.lang.Exception
If, however, the predicate fails, then false is emitted and the sequence terminates. Even if the source observable fails after that, the event is ignored, as required by the Rx contract (no events after a termination event).
Observable<Integer> values = Observable.create(o -> {
o.onNext(1);
o.onNext(2);
o.onError(new Exception());
});
Subscription subscription = values
.all(i -> i % 2 == 0)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);false
Completed
The exists method returns an observable that will emit true if any of the values emitted by the observable make the predicate true.
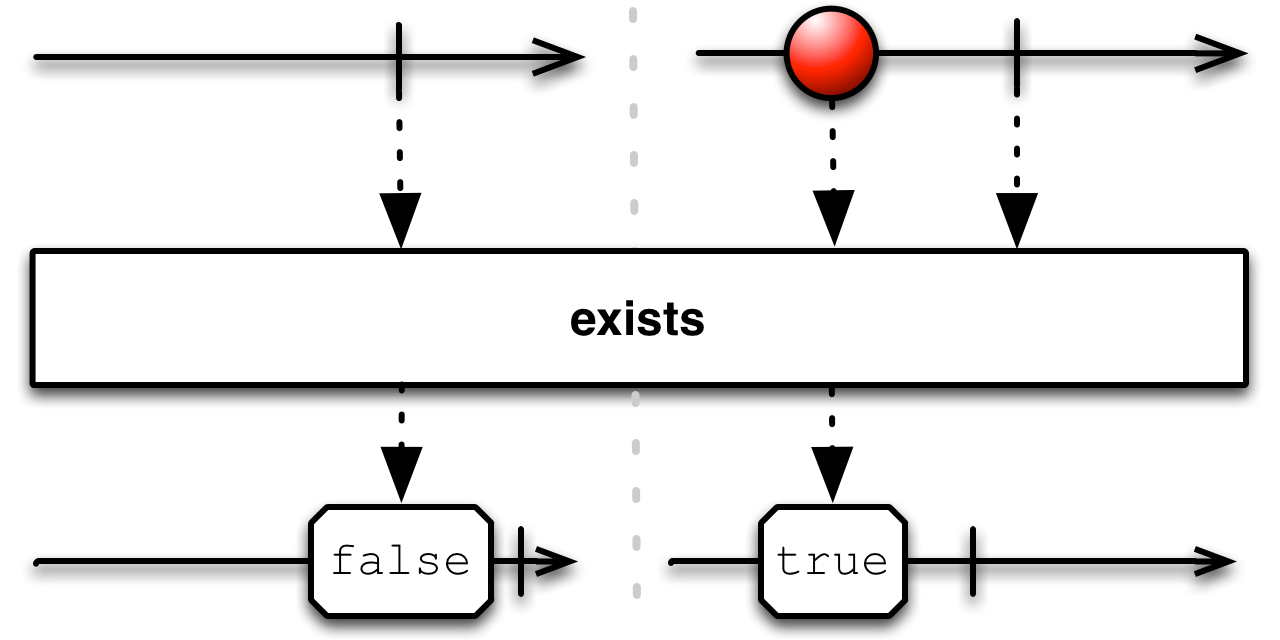
Observable<Integer> values = Observable.range(0, 2);
Subscription subscription = values
.exists(i -> i > 2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);false
Completed
Here our range didn't go high enough for the i > 2 condition to succeed. If we extend our range in the same example with
Observable<Integer> values = Observable.range(0, 4);We will get a successful result
true
Completed
This operator's result is a boolean value, indicating if an observable emitted values before completing or not.
Observable<Long> values = Observable.timer(1000, TimeUnit.MILLISECONDS);
Subscription subscription = values
.isEmpty()
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);false
Completed
Falsehood is established as soon as the first value is emitted. true will be returned once the source observable has terminated.
The method contains establishes if a particular element is emitted by an observable. contains will use the Object.equals method to establish the equality. Just like previous operators, it emits its decision as soon as it can be established and immediately completes.
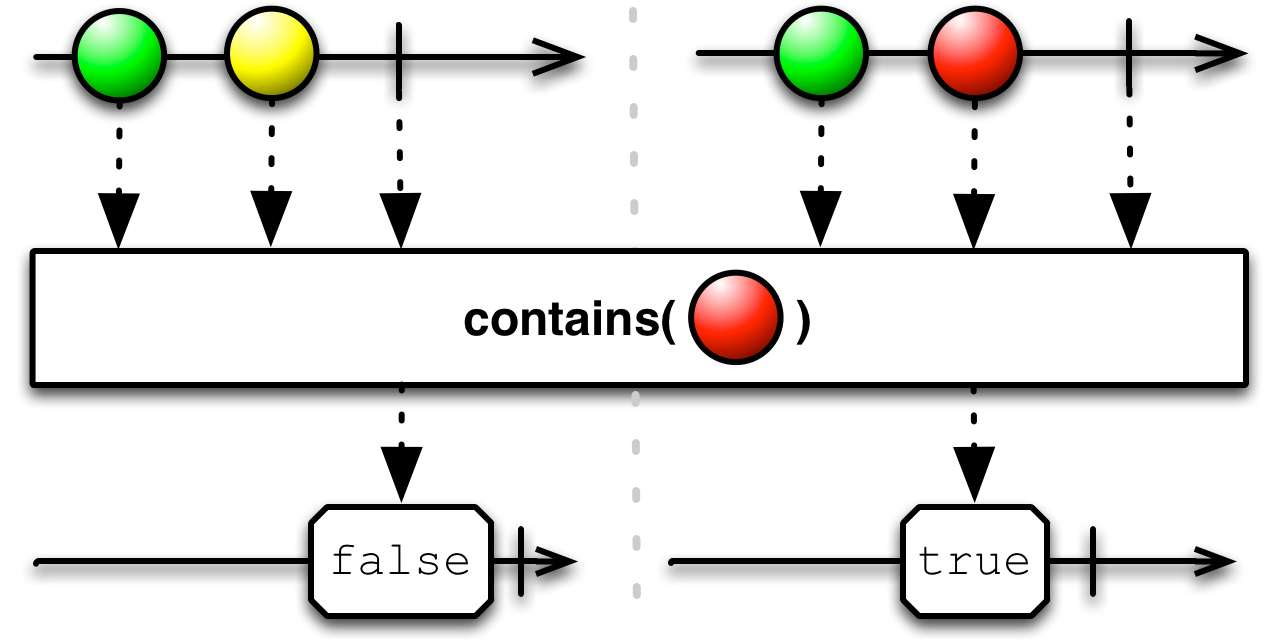
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
Subscription subscription = values
.contains(4L)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);true
Completed
If we had used contains(4) where we used contains(4L), nothing would be printed. That's because 4 and 4L are not equal in Java. Our code would wait for the observable to complete before returning false, but the observable we used is infinite.
If an empty sequence would cause you problems, rather than checking with isEmpty and handling the case, you can force an observable to emit a value on completion if it didn't emit anything before completing.
Observable<Integer> values = Observable.empty();
Subscription subscription = values
.defaultIfEmpty(2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);2
Completed
The default value is emitted only if no other values appeared and only on successful completion. If the source is not empty, the result is just the source observable. In the case of the error, the default value will not be emitted before the error.
Observable<Integer> values = Observable.error(new Exception());
Subscription subscription = values
.defaultIfEmpty(2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Output
Error: java.lang.Exception
You can select exactly one element out of an observable using the elementAt method
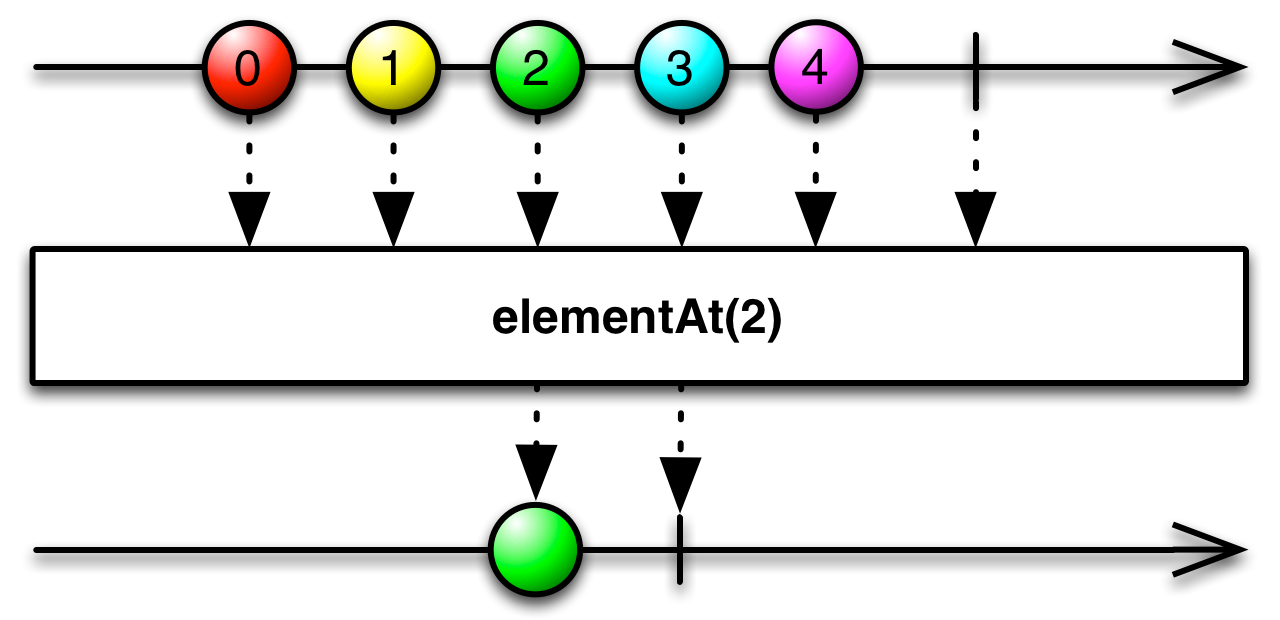
Observable<Integer> values = Observable.range(100, 10);
Subscription subscription = values
.elementAt(2)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);102
Completed
If the sequence doesn't have enough items, an java.lang.IndexOutOfBoundsException will be emitted. To avoid that specific case, we can provide a default value that will be emitted instead of an IndexOutOfBoundsException.
Observable<Integer> values = Observable.range(100, 10);
Subscription subscription = values
.elementAtOrDefault(22, 0)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);0
Completed
The last operator for this chapter establishes that two sequences are equal by comparing the values at the same index. Both the size of the sequences and the values must be equal. The function will either use Object.equals or the function that you supply to compare values.
Observable<String> strings = Observable.just("1", "2", "3");
Observable<Integer> ints = Observable.just(1, 2, 3);
Observable.sequenceEqual(strings, ints, (s,i) -> s.equals(i.toString()))
//Observable.sequenceEqual(strings, ints)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);true
Completed
If we swap the operator for the one that is commented out, i.e, the one using the standard Object.equals, the result would be false.
Failing is not part of the comparison. As soon as either sequence fails, the resulting observable forwards the error.
Observable<Integer> values = Observable.create(o -> {
o.onNext(1);
o.onNext(2);
o.onError(new Exception());
});
Observable.sequenceEqual(values, values)
.subscribe(
v -> System.out.println(v),
e -> System.out.println("Error: " + e),
() -> System.out.println("Completed")
);Error: java.lang.Exception
We've seen how to cut away parts of a sequence that we don't want, how to get single values and how to inspect the contents of sequence. Those things can be seen as reasoning about the containing sequence. Now we will see how we can use the data in the sequence to derive new meaningful values.
The methods we will see here resemble what is called catamorphism. In our case, it would mean that the methods consume the values in the sequence and compose them into one. However, they do not strictly meet the definition, as they don't return a single value. Rather, they return an observable that promises to emit a single value.
If you've been reading through all of the examples, you should have noticed some repetition. To do away with that and to focus on what matters, we will now introduce a custom Subscriber, which we will use in our examples.
class PrintSubscriber extends Subscriber{
private final String name;
public PrintSubscriber(String name) {
this.name = name;
}
@Override
public void onCompleted() {
System.out.println(name + ": Completed");
}
@Override
public void onError(Throwable e) {
System.out.println(name + ": Error: " + e);
}
@Override
public void onNext(Object v) {
System.out.println(name + ": " + v);
}
}This is a very basic implementation that prints every event to the console, along with a helpful tag.
Our first method is count. It serves the same purpose as length and size, found in most Java containers. This method will return an observable that waits until the sequence completes and emits the number of values encountered.
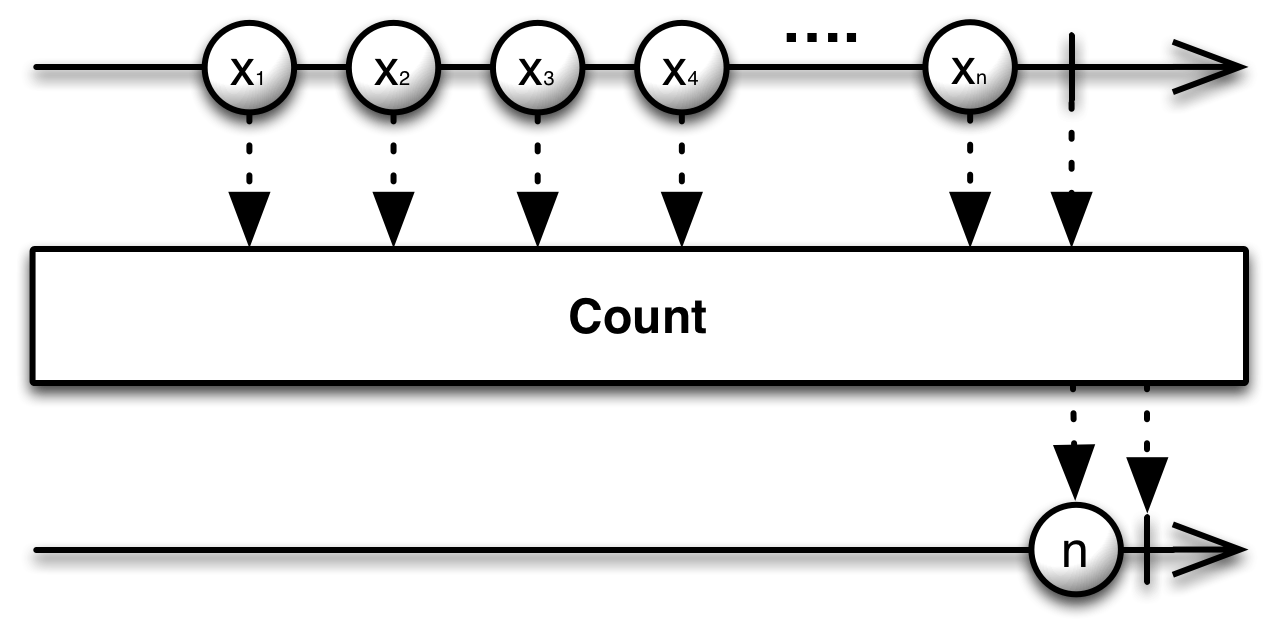
Observable<Integer> values = Observable.range(0, 3);
values
.subscribe(new PrintSubscriber("Values"));
values
.count()
.subscribe(new PrintSubscriber("Count"));Values: 0
Values: 1
Values: 2
Values: Completed
Count: 3
Count: Completed
There is also countLong for sequences that may exceed the capacity of a standard integer.
first will return an observable that emits only the first value in a sequence. It is similar to take(1), except that it will emit java.util.NoSuchElementException if none is found. If you use the overload that takes a predicate, the first value that matches the predicate is returned.
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values
.first(v -> v>5)
.subscribe(new PrintSubscriber("First"));First: 6
Instead of getting a java.util.NoSuchElementException, you can use firstOrDefault to get a default value when the sequence is empty.
last and lastOrDefault work in the same way as first, except that the item returned is the last item before the sequence completed. When using the overload with a predicate, the item returned is the last item that matched the predicate. We'll skip presenting examples, because they are trivial, but you can find them in the example code.
single emits the only value in the sequence, or the only value that met predicate when one is given. It differs from first and last in that it does not ignore multiple matches. If multiple matches are found, it will emit an error. It can be used to assert that a sequence must only contain one such value.
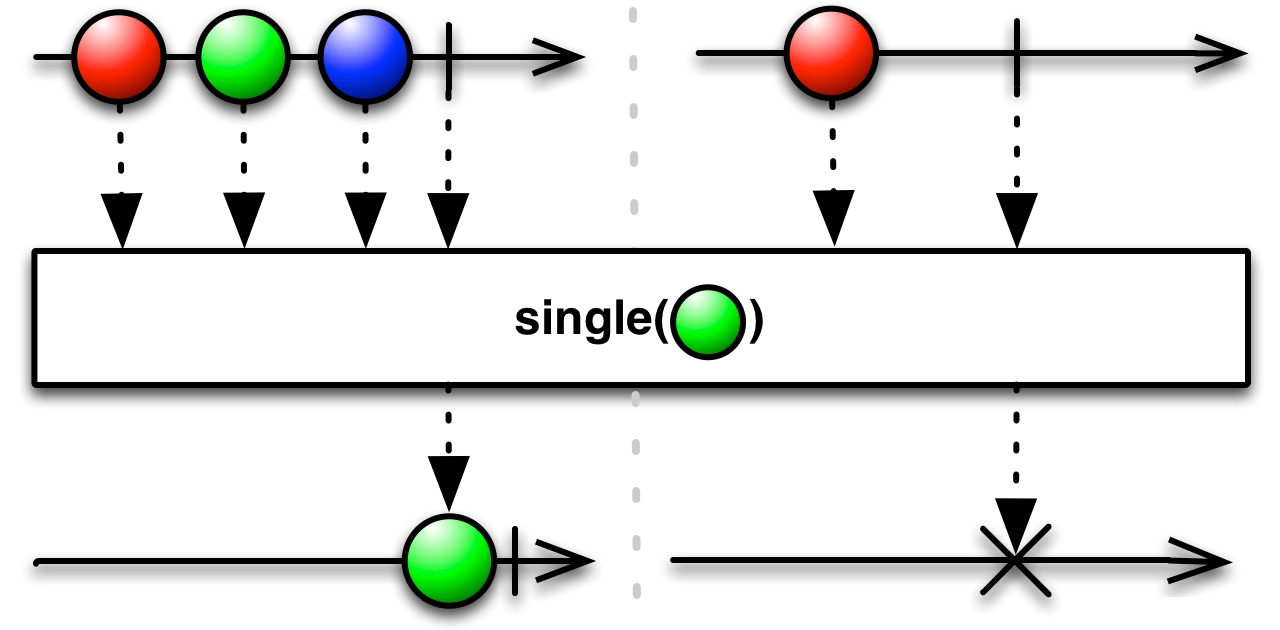
Remember that single must check the entire sequence to ensure your assertion.
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values.take(10)
.single(v -> v == 5L) // Emits a result
.subscribe(new PrintSubscriber("Single1"));
values
.single(v -> v == 5L) // Never emits
.subscribe(new PrintSubscriber("Single2"));Single1: 5
Single1: Completed
Like in the previous methods, you can have a default value with singleOrDefault
The methods we saw on this chapter so far don't seem that different from the ones in previous chapters. We will now see two very powerful methods that will greatly expand what we can do with an observable. Many of the methods we've seen so far can be implemented using those.
You may have heard of reduce from [MapReduce] (https://en.wikipedia.org/wiki/MapReduce). Alternatively, you might have met it under the names "aggregate", "accumulate" or "fold". The general idea is that you produce a single value out of many by combining them two at a time. In its most basic overload, all you need is a function that combines two values into one.
public final Observable<T> reduce(Func2<T,T,T> accumulator)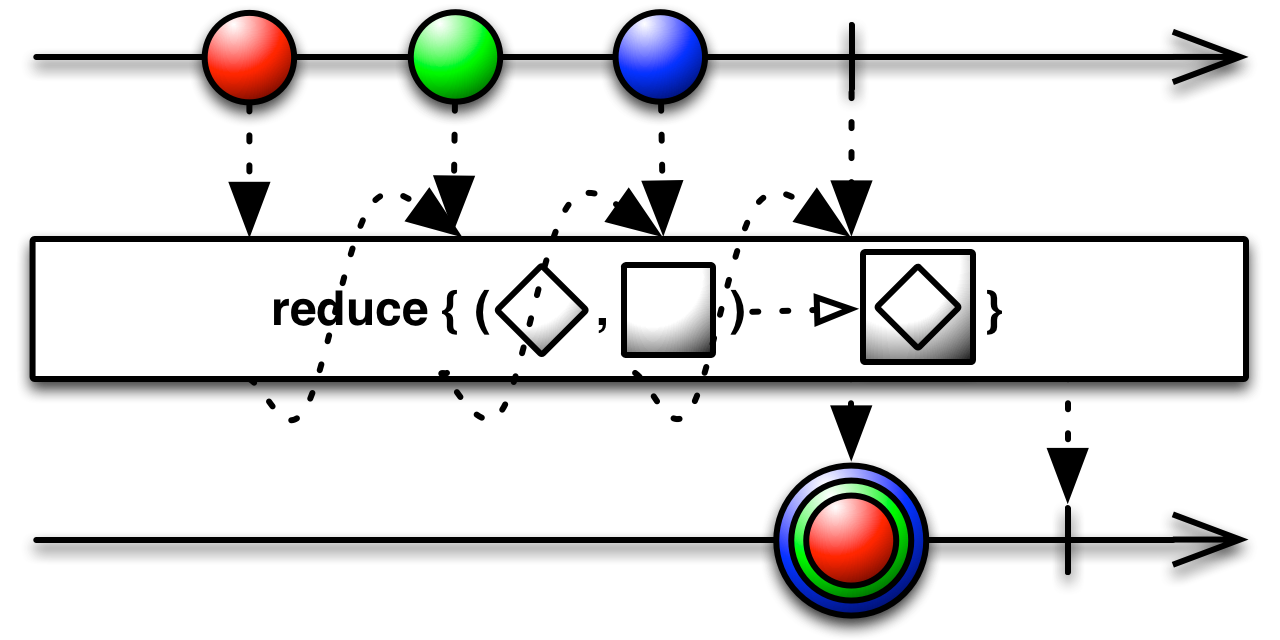
This is best explained with an example. Here we will calculate the sum of a sequence of integers: 0+1+2+3+4+.... We will also calculate the minimum value for a different example;
Observable<Integer> values = Observable.range(0,5);
values
.reduce((i1,i2) -> i1+i2)
.subscribe(new PrintSubscriber("Sum"));
values
.reduce((i1,i2) -> (i1>i2) ? i2 : i1)
.subscribe(new PrintSubscriber("Min"));Sum: 10
Sum: Completed
Min: 0
Min: Completed
reduce in Rx is not identical to "reduce" in parallel systems. In the context of parallel systems, it implies that the pairs of values can be choosen arbitrarily so that multiple machines can work independently. In Rx, the accumulator function is applied in sequence from left to right (as seen on the marble diagram). Each time, the accumulator function combines the result of the previous step with the next value. This is more obvious in another overload:
public final <R> Observable<R> reduce(R initialValue, Func2<R,? super T,R> accumulator)The accumulator returns a different type than the one in the observable. The first parameter for the accumulator is the previous partial result of the accumulation process and the second is the next value. To begin the process, an initial value is supplied. We will demonstrate the usefulness of this by reimplementing count
Observable<String> values = Observable.just("Rx", "is", "easy");
values
.reduce(0, (acc,next) -> acc + 1)
.subscribe(new PrintSubscriber("Count"));Count: 3
Count: Completed
We start with an accumulator of 0, as we have counted 0 items. Every time a new item arrives, we return a new accumulator that is increased by one. The last value corresponds to the number of elements in the source sequence.
reduce can be used to implement the functionality of most of the operators that emit a single value. It can not implement behaviour where a value is emitted before the source completes. So, you can implement last using reduce, but an implementation of all would not behave exactly like the original.
scan is very similar to reduce, with the key difference being that scan will emit all the intermediate results.
public final Observable<T> scan(Func2<T,T,T> accumulator)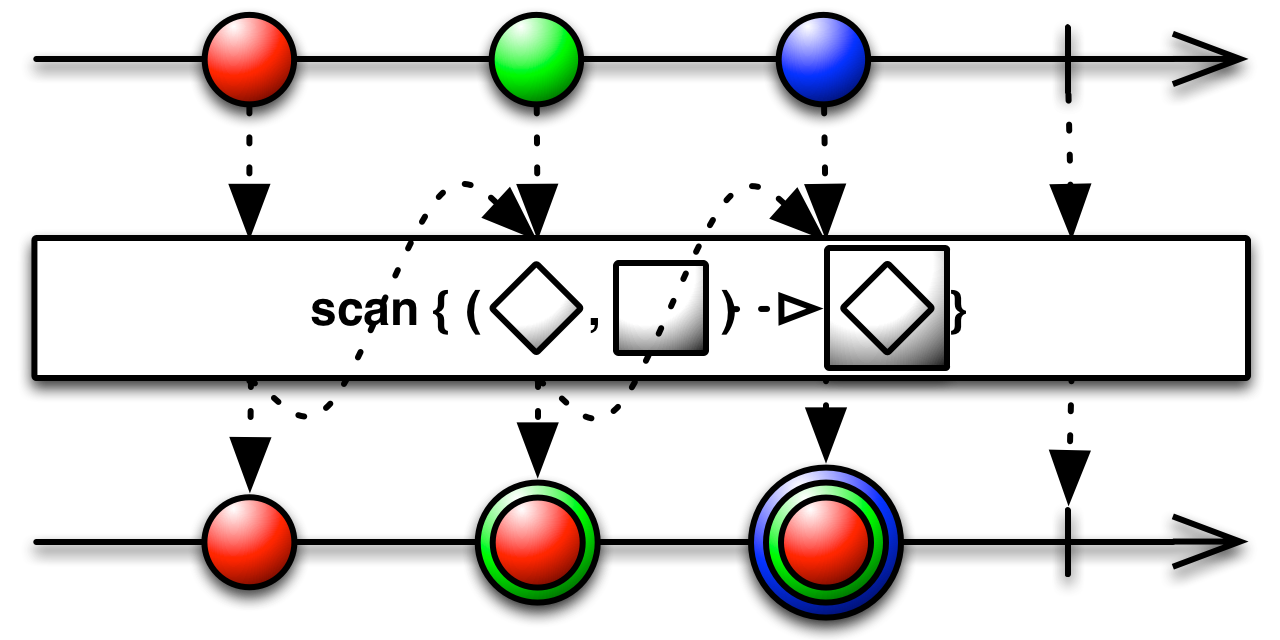
In the case of our example for a sum, using scan will produce a running sum.
Observable<Integer> values = Observable.range(0,5);
values
.scan((i1,i2) -> i1+i2)
.subscribe(new PrintSubscriber("Sum"));Sum: 0
Sum: 1
Sum: 3
Sum: 6
Sum: 10
Sum: Completed
scan is more general than reduce, since reduce can be implemented with scan: reduce(acc) = scan(acc).takeLast()
scan emits when the source emits and does not need the source to complete. We demonstrate that by implementing an observable that returns a running minimum:
Subject<Integer, Integer> values = ReplaySubject.create();
values
.subscribe(new PrintSubscriber("Values"));
values
.scan((i1,i2) -> (i1<i2) ? i1 : i2)
.distinctUntilChanged()
.subscribe(new PrintSubscriber("Min"));
values.onNext(2);
values.onNext(3);
values.onNext(1);
values.onNext(4);
values.onCompleted();Values: 2
Min: 2
Values: 3
Values: 1
Min: 1
Values: 4
Values: Completed
Min: Completed
In reduce nothing is stopping your accumulator from being a collection. You can use reduce to collect every value in Observable<T> into a List<T>.
Observable<Integer> values = Observable.range(10,5);
values
.reduce(
new ArrayList<Integer>(),
(acc, value) -> {
acc.add(value);
return acc;
})
.subscribe(v -> System.out.println(v));[10, 11, 12, 13, 14]
The code above has a problem with formality: reduce is meant to be a functional fold and such folds are not supposed to work on mutable accumulators. If we were to do this the "right" way, we would have to create a new instance of ArrayList<Integer> for every new item, like this:
// Formally correct but very inefficient
.reduce(
new ArrayList<Integer>(),
(acc, value) -> {
ArrayList<Integer> newAcc = (ArrayList<Integer>) acc.clone();
newAcc.add(value);
return newAcc;
})The performance of creating a new collection for every new item is unacceptable. For that reason, Rx offers the collect operator, which does the same thing as reduce, only using a mutable accumulator this time. By using collect you document that you are not following the convention of immutability and you also simplify your code a little:
Observable<Integer> values = Observable.range(10,5);
values
.collect(
() -> new ArrayList<Integer>(),
(acc, value) -> acc.add(value))
.subscribe(v -> System.out.println(v));[10, 11, 12, 13, 14]
Usually, you won't have to collect values manually. RxJava offers a variety of operators for collecting your sequence into a container. Those aggregators return an observable that will emit the corresponding collection when it is ready, just like what we did here. We will see such aggregators next.
The example above could be implemented as
Observable<Integer> values = Observable.range(10,5);
values
.toList()
.subscribe(v -> System.out.println(v));The toSortedList aggregator works like toList, except that the resulting list is sorted. Here are the signatures:
public final Observable<java.util.List<T>> toSortedList()
public final Observable<java.util.List<T>> toSortedList(
Func2<? super T,? super T,java.lang.Integer> sortFunction)As we can see, we can either use the default comparison for the objects, or supply our own sorting function. The sorting function follows the semantics of Comparator's compare method.
In this example, we sort integers in reverse order with a custom sort function
Observable<Integer> values = Observable.range(10,5);
values
.toSortedList((i1,i2) -> i2 - i1)
.subscribe(v -> System.out.println(v));[14, 13, 12, 11, 10]
toMap turns our sequence of T into a Map<TKey,T>. There are 3 overloads
public final <K> Observable<java.util.Map<K,T>> toMap(
Func1<? super T,? extends K> keySelector)
public final <K,V> Observable<java.util.Map<K,V>> toMap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector)
public final <K,V> Observable<java.util.Map<K,V>> toMap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector,
Func0<? extends java.util.Map<K,V>> mapFactory)keySelector is a function that produces a key from a value. valueSelector produces from the emitted value the actual value that will be stored in the map. mapFactory creates the collection that will hold the items.
Lets start with an example of the simplest overload. We want to map people to their age. First, we need a data structure to work on:
class Person {
public final String name;
public final Integer age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}Observable<Person> values = Observable.just(
new Person("Will", 25),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMap(person -> person.name)
.subscribe(new PrintSubscriber("toMap"));toMap: {Saul=Person@7cd84586, Nick=Person@30dae81, Will=Person@1b2c6ec2}
toMap: Completed
Now we will only use the age as a value
Observable<Person> values = Observable.just(
new Person("Will", 25),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMap(
person -> person.name,
person -> person.age)
.subscribe(new PrintSubscriber("toMap"));toMap: {Saul=35, Nick=40, Will=25}
toMap: Completed
If we want to be explicit about the container that will be used or initialise it, we can supply our own container:
values
.toMap(
person -> person.name,
person -> person.age,
() -> new HashMap())
.subscribe(new PrintSubscriber("toMap"));The container is provided as a factory function because a new container needs to be created for every new subscription.
When mapping, it is very common that many values share the same key. The datastructure that maps one key to multiple values is called a multimap and it is a map from keys to collections. This process can also be called "grouping".
public final <K> Observable<java.util.Map<K,java.util.Collection<T>>> toMultimap(
Func1<? super T,? extends K> keySelector)
public final <K,V> Observable<java.util.Map<K,java.util.Collection<V>>> toMultimap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector)
public final <K,V> Observable<java.util.Map<K,java.util.Collection<V>>> toMultimap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector,
Func0<? extends java.util.Map<K,java.util.Collection<V>>> mapFactory)
public final <K,V> Observable<java.util.Map<K,java.util.Collection<V>>> toMultimap(
Func1<? super T,? extends K> keySelector,
Func1<? super T,? extends V> valueSelector,
Func0<? extends java.util.Map<K,java.util.Collection<V>>> mapFactory,
Func1<? super K,? extends java.util.Collection<V>> collectionFactory)And here is an example where we group by age.
Observable<Person> values = Observable.just(
new Person("Will", 35),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMultimap(
person -> person.age,
person -> person.name)
.subscribe(new PrintSubscriber("toMap"));toMap: {35=[Will, Saul], 40=[Nick]}
toMap: Completed
The first three overloads are familiar from toMap. The fourth allows us to provide not only the Map but also the Collection that the values will be stored in. The key is provided as a parameter, in case we want to customise the corresponding collection based on the key. In this example we'll just ignore it.
Observable<Person> values = Observable.just(
new Person("Will", 35),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMultimap(
person -> person.age,
person -> person.name,
() -> new HashMap(),
(key) -> new ArrayList())
.subscribe(new PrintSubscriber("toMap"));The operators just presented have actually limited use. It is tempting for a beginner to collect the data in a collection and process them in the traditional way. That should be avoided not just for didactic purposes, but because this practice defeats the advantages of using Rx in the first place.
The last general function that we will see for now is groupBy. It is the Rx way of doing toMultimap. For each value, it calculates a key and groups the values into separate observables based on that key.
public final <K> Observable<GroupedObservable<K,T>> groupBy(Func1<? super T,? extends K> keySelector)
The return value is an observable of GroupedObservable. Every time a new key is met, a new inner GroupedObservable will be emitted. That type is nothing more than a standard observable with a getKey() accessor, for getting the group's key. As values come from the source observable, they will be emitted by the observable with the corresponding key.
The nested observables may complicate the signature, but they offer the advantage of allowing the groups to start emitting their items before the source observable has completed.
In the next example, we will take a set of words and, for each starting letter, we will print the last word that occured.
Observable<String> values = Observable.just(
"first",
"second",
"third",
"forth",
"fifth",
"sixth"
);
values.groupBy(word -> word.charAt(0))
.subscribe(
group -> group.last()
.subscribe(v -> System.out.println(group.getKey() + ": " + v))
);The above example works, but it is a bad idea to have nested subscribes. You can do the same with
Observable<String> values = Observable.just(
"first",
"second",
"third",
"forth",
"fifth",
"sixth"
);
values.groupBy(word -> word.charAt(0))
.flatMap(group ->
group.last().map(v -> group.getKey() + ": " + v)
)
.subscribe(v -> System.out.println(v));s: sixth
t: third
f: fifth
map and flatMap are unknown for now. We will introduce them properly in the next chapter.
Nested observables may be confusing at first, but they are a powerful construct that has many uses. We borrow some nice examples, as outlined in www.introtorx.com
- Partitions of Data
- You may partition data from a single source so that it can easily be filtered and shared to many sources. Partitioning data may also be useful for aggregates as we have seen. This is commonly done with the
groupByoperator.
- You may partition data from a single source so that it can easily be filtered and shared to many sources. Partitioning data may also be useful for aggregates as we have seen. This is commonly done with the
- Online Game servers
- Consider a sequence of servers. New values represent a server coming online. The value itself is a sequence of latency values allowing the consumer to see real time information of quantity and quality of servers available. If a server went down then the inner sequence can signal that by completing.
- Financial data streams
- New markets or instruments may open and close during the day. These would then stream price information and could complete when the market closes.
- Chat Room
- Users can join a chat (outer sequence), leave messages (inner sequence) and leave a chat (completing the inner sequence).
- File watcher
- As files are added to a directory they could be watched for modifications (outer sequence). The inner sequence could represent changes to the file, and completing an inner sequence could represent deleting the file.
When dealing with nested observables, the nest operator becomes useful. It allows you to turn a non-nested observable into a nested one. nest takes a source observable and returns an observable that will emit the source observable and then terminate.
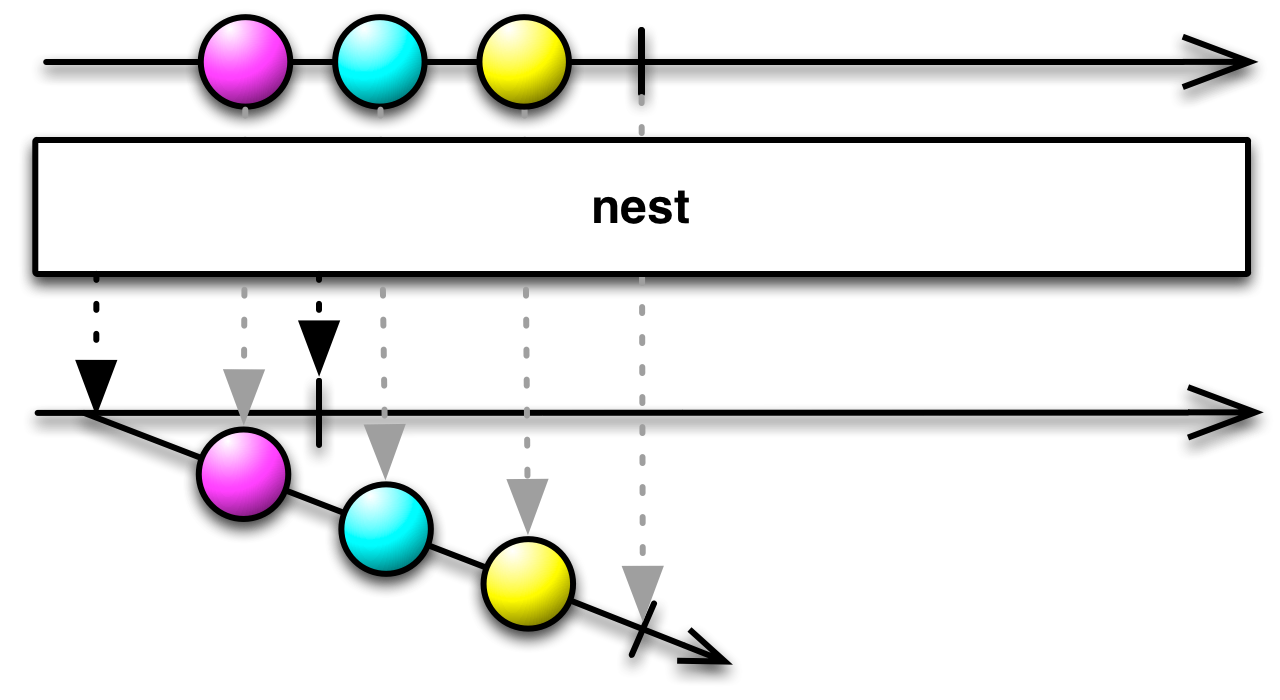
Observable.range(0, 3)
.nest()
.subscribe(ob -> ob.subscribe(System.out::println));0
1
2
Nesting observables to consume them doesn't make much sense. Towards the end of the pipeline, you'd rather flatten and simplify your observables, rather than nest them. Nesting is useful when you need to make a non-nested observable be of the same type as a nested observable that you have from elsewhere. Once they are of the same type, you can combine them, as we will see in the chapter about [combining sequences](/Part 3 - Taming the sequence/4. Combining sequences.md).
In this chapter we will see ways of changing the format of the data. In the real world, an observable may be of any type. It is uncommon that the data is already in format that we want them in. More likely, the values need to be expanded, trimmed, evaluated or simply replaced with something else.
This will complete the three basic categories of operations. map and flatMap are the fundamental methods in the third category. In literature, you will often find them refered to as "bind", for reasons that are beyond the scope of this guide.
- Ana(morphism)
T-->IObservable<T> - Cata(morphism)
IObservable<T>-->T - Bind
IObservable<T1>-->IObservable<T2>
In the last chapter we introduced an implementation of Subscriber for convenience. We will continue to use it in the examples of this chapter.
class PrintSubscriber extends Subscriber{
private final String name;
public PrintSubscriber(String name) {
this.name = name;
}
@Override
public void onCompleted() {
System.out.println(name + ": Completed");
}
@Override
public void onError(Throwable e) {
System.out.println(name + ": Error: " + e);
}
@Override
public void onNext(Object v) {
System.out.println(name + ": " + v);
}
}The basic method for transformation is map (also known as "select" in SQL-inspired systems like LINQ). It takes a transformation function which takes an item and returns a new item of any type. The returned observable is composed of the values returned by the transformation function.
public final <R> Observable<R> map(Func1<? super T,? extends R> func)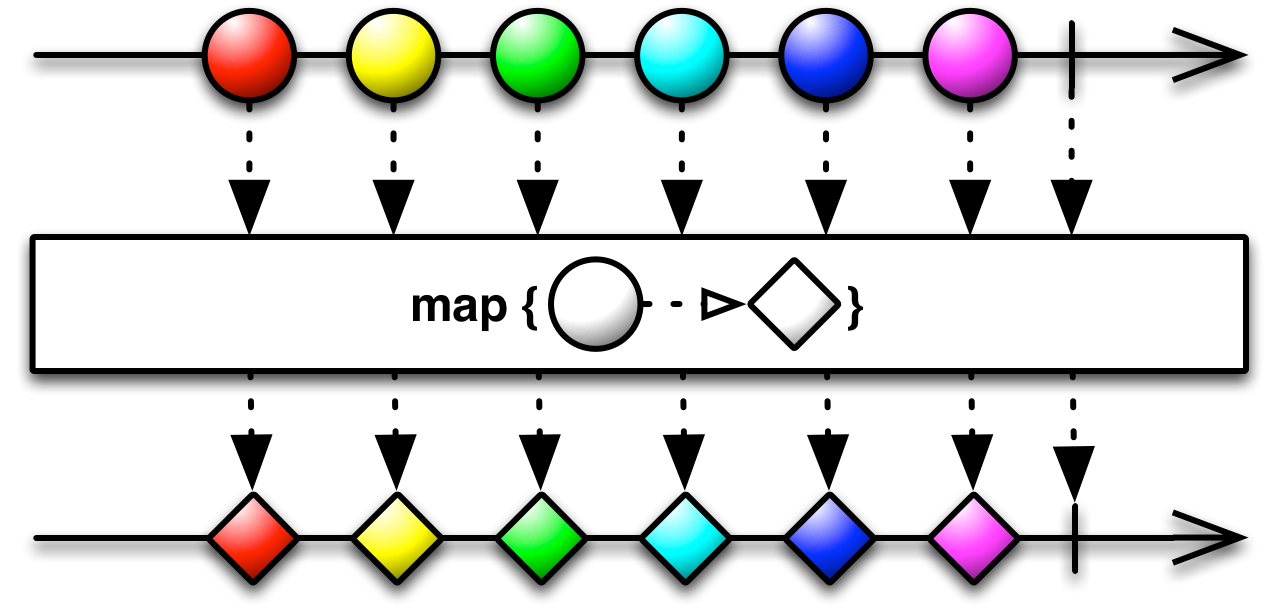
In the first example, we will take a sequence of integers and increase them by 3
Observable<Integer> values = Observable.range(0,4);
values
.map(i -> i + 3)
.subscribe(new PrintSubscriber("Map"));Map: 3
Map: 4
Map: 5
Map: 6
Map: Completed
This was something we could do without map, for example by using Observable.range(3,4). In the following, we will do something more practical. The producer will emit numeric values as a string, like many UIs often do, and then use map to convert them to a more processable integer format.
Observable<Integer> values =
Observable.just("0", "1", "2", "3")
.map(Integer::parseInt);
values.subscribe(new PrintSubscriber("Map"));Map: 0
Map: 1
Map: 2
Map: 3
Map: Completed
This transformation is simple enough that we could also do it on the subscriber's side, but that would be a bad division of responsibilities. When developing the side of the producer, you want to present things in the neatest and most convenient way possible. You wouldn't dump the raw data and let the consumer figure it out. In our example, since we said that the API produces integers, it should do just that. Tranfomation operators allow us to convert the initial sequences into the API that we want to expose.
cast is a shorthand for the transformation of casting the items to a different type. If you had an Observable<Object> that you knew would only only emit values of type T, then it is just simpler to cast the observable, rather than do the casting in your lambda functions.
Observable<Object> values = Observable.just(0, 1, 2, 3);
values
.cast(Integer.class)
.subscribe(new PrintSubscriber("Map"));Map: 0
Map: 1
Map: 2
Map: 3
Map: Completed
The cast method will fail if not all of the items can be cast to the specified type.
Observable<Object> values = Observable.just(0, 1, 2, "3");
values
.cast(Integer.class)
.subscribe(new PrintSubscriber("Map"));Map: 0
Map: 1
Map: 2
Map: Error: java.lang.ClassCastException: Cannot cast java.lang.String to java.lang.Integer
If you would rather have such cases ignored, you can use the ofType method. This will filter our items that cannot be cast and then cast the sequence to the desired type.
Observable<Object> values = Observable.just(0, 1, "2", 3);
values
.ofType(Integer.class)
.subscribe(new PrintSubscriber("Map"));Map: 0
Map: 1
Map: 3
Map: Completed
The timestamp and timeInterval methods enable us to enrich our values with information about the asynchronous nature of sequences. timestamp transforms values into the Timestamped<T> type, which contains the original value, along with a timestamp for when the event was emitted.
public final Observable<Timestamped<T>> timestamp()Here's an example:
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values.take(3)
.timestamp()
.subscribe(new PrintSubscriber("Timestamp"));Timestamp: Timestamped(timestampMillis = 1428611094943, value = 0)
Timestamp: Timestamped(timestampMillis = 1428611095037, value = 1)
Timestamp: Timestamped(timestampMillis = 1428611095136, value = 2)
Timestamp: Completed
The timestamp allows us to see that the items were emitted roughly 100ms apart (Java offers few guarantees on that).
If we are more interested in how much time has passed since the last item, rather than the absolute moment in time when the items were emitted, we can use the timeInterval method.
public final Observable<TimeInterval<T>> timeInterval()Using timeInterval in the same sequence as before:
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values.take(3)
.timeInterval()
.subscribe(new PrintSubscriber("TimeInterval"));TimeInterval: TimeInterval [intervalInMilliseconds=131, value=0]
TimeInterval: TimeInterval [intervalInMilliseconds=75, value=1]
TimeInterval: TimeInterval [intervalInMilliseconds=100, value=2]
TimeInterval: Completed
The information captured by timestamp and timeInterval is very useful for logging and debugging. It is Rx's way of acquiring information about the asynchronicity of sequences.
Also useful for logging is materialize. materialize transforms a sequence into its metadata representation.
public final Observable<Notification<T>> materialize()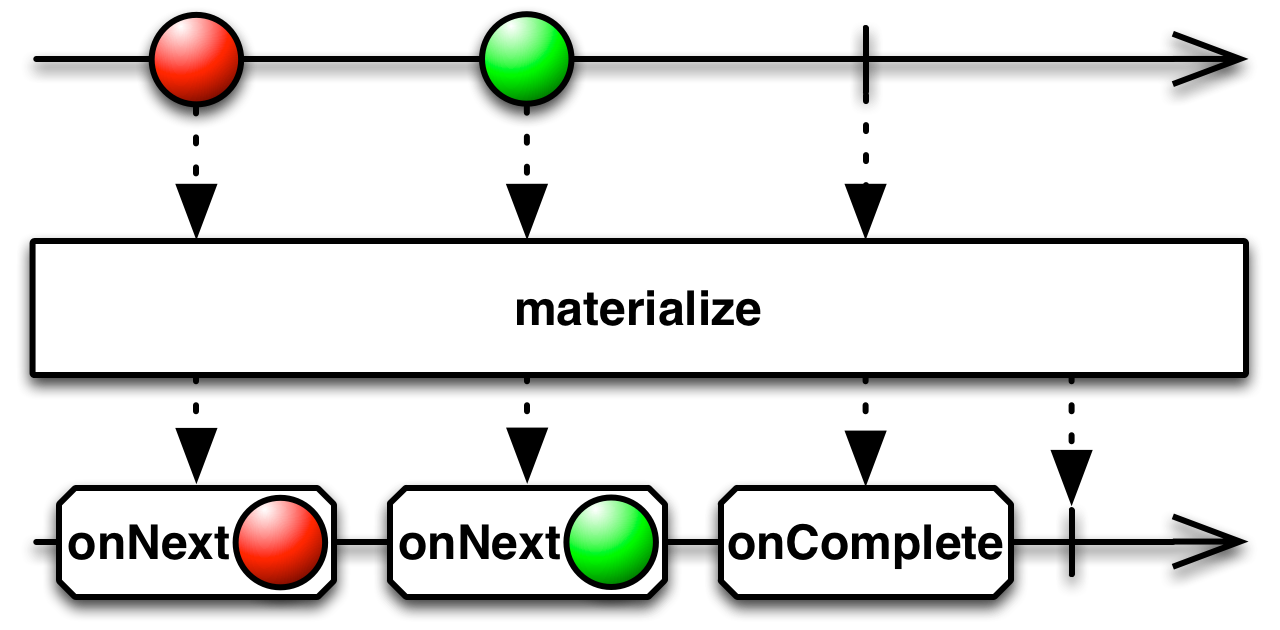
The notification type can represent any event, i.e. the emission of a value, an error or completion. Notice in the marble diagram above that the emission of "onCompleted" did not mean the end of the sequence, as the sequence actually ends afterwards. Here's an example
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values.take(3)
.materialize()
.subscribe(new PrintSubscriber("Materialize"));Materialize: [rx.Notification@a4c802e9 OnNext 0]
Materialize: [rx.Notification@a4c802ea OnNext 1]
Materialize: [rx.Notification@a4c802eb OnNext 2]
Materialize: [rx.Notification@18d48ace OnCompleted]
Materialize: Completed
The Notification type contains methods for determining the type of the event as well the carried value or Throwable, if any.
dematerialize will reverse the effect of materialize, returning a materialized observable to its normal form.
map took one value and returned another, replacing items in the sequence one-for-one. flatMap will replace an item with any number of items, including zero or infinite items. flatMap's transformation method takes values from the source observable and, for each of them, returns a new observable that emits the new values.
public final <R> Observable<R> flatMap(Func1<? super T,? extends Observable<? extends R>> func)
The observable returned by flatMap will emit all the values emitted by all the observables produced by the transformation function. Values from the same observable will be in order, but they may be interleaved with values from other observables.
Let's start with a simple example, where flatMap is applied on an observable with a single value. values will emit a single value, 2. flatMap will turn it into an observable that is the range between 0 and 2. The values in this observable are emitted in the final observable.
Observable<Integer> values = Observable.just(2);
values
.flatMap(i -> Observable.range(0,i))
.subscribe(new PrintSubscriber("flatMap"));flatMap: 0
flatMap: 1
flatMap: Completed
When flatMap is applied on an observable with multiple values, each value will produce a new observable. values will emit 1, 2 and 3. The resulting observables will emit the values [0], [0,1] and [0,1,2], respectively. The values will be flattened together into one observable: the one that is returned by flatMap.
Observable<Integer> values = Observable.range(1,3);
values
.flatMap(i -> Observable.range(0,i))
.subscribe(new PrintSubscriber("flatMap"));flatMap: 0
flatMap: 0
flatMap: 1
flatMap: 0
flatMap: 1
flatMap: 2
flatMap: Completed
Much like map, flatMap's input and output type are free to differ. In the next example, we will transform integers into Character
Observable<Integer> values = Observable.just(1);
values
.flatMap(i ->
Observable.just(
Character.valueOf((char)(i+64))
))
.subscribe(new PrintSubscriber("flatMap"));This hasn't helped us more than the map operator. There is one key difference that we can exploit to get more out of the flatMap operator. While every value must result in an Observable, nothing prevents this observable from being empty. We can use that to silenty filter the sequence while transforming it at the same time.
Observable<Integer> values = Observable.range(0,30);
values
.flatMap(i -> {
if (0 < i && i <= 26)
return Observable.just(Character.valueOf((char)(i+64)));
else
return Observable.empty();
})
.subscribe(new PrintSubscriber("flatMap"));flatMap: A
flatMap: B
flatMap: C
...
flatMap: X
flatMap: Y
flatMap: Z
flatMap: Completed
This example results in the entire alphabet being printed without errors, even though the initial range exceeds that of the alphabet.
In our examples for flatMap so far, the values where in sequence: first all the values from the first observable, then all the values from the second observable. Though this seems intuitive, especially when coming from a synchronous environment, it is important to note that this is not always the case. The observable returned by flatMap emits values as soon as they are available. It just happened that in our examples, all of the observables had all of their values ready synchronously. To demonstrate, we construct asynchronous observables using the interval method.
Observable.just(100, 150)
.flatMap(i ->
Observable.interval(i, TimeUnit.MILLISECONDS)
.map(v -> i)
)
.take(10)
.subscribe(new PrintSubscriber("flatMap"));We started with the values 100 and 150, which we used as the interval period for the asynchronous observables created in flatMap. Since interval emits the numbers 1,2,3... in both cases, to better distinguish the two observables, we replaced those values with interval time that each observable operates on.
flatMap: 100
flatMap: 150
flatMap: 100
flatMap: 100
flatMap: 150
flatMap: 100
flatMap: 150
flatMap: 100
flatMap: 100
flatMap: 150
flatMap: Completed
We can see that the two observables are interleaved into one.
Even though flatMap shares its name with a very common operator in functional programming, we saw that it doesn't behave exactly like a functional programmer would expect. flatMap may interleave the supplied sequences. There is an operator that won't interleave the sequences and is called concatMap, because it is related to the concat operator that we will see later.
Observable.just(100, 150)
.concatMap(i ->
Observable.interval(i, TimeUnit.MILLISECONDS)
.map(v -> i)
.take(3))
.subscribe(
System.out::println,
System.out::println,
() -> System.out.println("Completed"));100
100
100
150
150
150
Completed
We can see in the output that the two sequences are kept separate. Note that the concatMap operator only works with terminating sequences: it can't move on to the next sequence before the current sequence terminates. For that reason, we had to limit interval's infinite sequence with take.
flatMap and concatMap flatten a sequence of observables, as produced by their selector function, into one observable. We can also flatten a sequence of iterables with flatMapIterable. This is similar to flatMap, only our selector function creates iterables instead.
Consider, instead of Observable.range, a function that produces the range as an iterable.
public static Iterable<Integer> range(int start, int count) {
List<Integer> list = new ArrayList<>();
for (int i=start ; i<start+count ; i++) {
list.add(i);
}
return list;
}Observable.range(1, 3)
.flatMapIterable(i -> range(1, i))
.subscribe(System.out::println);1
1
2
1
2
3
As expected, the 3 iterables that we created are flattened in a single observable sequence.
As an Rx developer, you are advised to present your data as observable sequences and avoid mixing observables with iterables. However, when your data is already in the format of a collection, e.g. because standard Java operations returned them like that, it can be simpler or faster to just use them as they are without converting them first. flatMapIterable also eliminates the need to make a choice about interleaving or not: flatMapIterable doesn't interleave, just like you would expect from a synchronous flatMap.
There is a second overload to flatMapIterable that allows you to combine every value in the iterable with the value that produced the iterable.
Observable.range(1, 3)
.flatMapIterable(
i -> range(1, i),
(ori, rv) -> ori * (Integer) rv)
.subscribe(System.out::println);1
2
4
3
6
9
Here, we multiplied every value in the iterable range with the value that seeded the range: [1*1], [1*2, 2*2], [1*3, 2*3, 3*3].
Java lacks a way to do map on its standard collections. It is therefore impossible to transform the iterable before the seeding value disappears (here, the i in i -> range(1, i)). Here, our iterable is just a list, so we could have just modified the iterable before returning it. However, if our iterable isn't a collection, we would have to either implement a map for iterables ourselves, or manually collect the modified values into a new collection and return that. This overload of flatMapIterable saves us from having to insert this ugliness in the middle of our pipeline.
The concept of laziness isn't very common in Java, so you may be confused as to what kind of iterable isn't a collection. For the sake of example, consider the following iterable that generates a range lazily. It allows us to iterate over a range by calculating the next value from the previous one. In this way, we save the memory of storing the whole range.
public static class Range implements Iterable<Integer> {
private static class RangeIterator implements Iterator<Integer> {
private int next;
private final int end;
RangeIterator(int start, int count) {
this.next = start;
this.end = start + count;
}
@Override
public boolean hasNext() {
return next < end;
}
@Override
public Integer next() {
return next++;
}
}
private final int start;
private final int count;
public Range(int start, int count) {
this.start = start;
this.count = count;
}
@Override
public Iterator<Integer> iterator() {
return new RangeIterator(start, count);
}
}We can now iterate over a range and transform it without the need to store anything.
Observable.range(1, 3)
.flatMapIterable(
i -> new Range(1, i),
(ori, rv) -> ori * (Integer) rv)
.subscribe(System.out::println);1
2
4
3
6
9
So far we've learned how to create observables and how to extract relevant data from observables. In this chapter we will go beyond what is necessary for simple examples and discuss more advanced functionality, as well as some good practices for using Rx in bigger applications.
Functions without side-effects interact with the rest of the program exclusively through their arguments and return values. When the operations within a function can affect the outcome of another function (or a subsequent call to the same function), we say that the function has side effects. Common side effects are writes to storage, logging, debugging or prints to a user interface. A more language-dependent form of side effect is the ability to modify the state of an object that is visible to other functions, which is something that Java considers legal. A function passed as an argument to an Rx operator can modify values in a wider scope, perform IO operations or update a display.
Side effects can be very useful and are unavoidable in many cases. But they also have pitfalls. Rx developers are encouraged to avoid unnecessary side effects, and to have a clear intention when they do use them. While some cases are justified, abuse introduces unnecessary hazards.
Functional programming in general tries to avoid creating any side effects. Functions with side effects, especially which modify state, require the programmer to understand more than just the inputs and outputs of the function. The surface area they are required to understand needs to now extend to the history and context of the state being modified. This can greatly increase the complexity of a function, and thus make it harder to correctly understand and maintain. Side effects are not always accidental, nor are they always intentional. An easy way to reduce the accidental side effects is to reduce the surface area for change. The simple actions coders can take are to reduce the visibility or scope of state and to make what you can immutable. You can reduce the visibility of a variable by scoping it to a code block like a method. You can reduce visibility of class members by making them private or protected. By definition immutable data can't be modified so cannot exhibit side effects. These are sensible encapsulation rules that will dramatically improve the maintainability of your Rx code.
We start with an example of an implementation with a side effect. Java doesn't allow references to non-final variables from lambdas (or anonymous implementations in general). However, the final keyword in Java protects only the reference and not the state of the referred object. Nothing stops you from modifying the state of objects from your lambda. Consider this simple counter, that is implemented as an object, rather than a primitive int.
class Inc {
private int count = 0;
public void inc() {
count++;
}
public int getCount() {
return count;
}
}An instance of Inc can have its state modified even if it is declared as final. We are going to use this to index the items of an observable. Note that, while Java didn't force us to explicitly declare it as final, it would produce an error if we tried to change the reference while also using the reference in our lambda.
Observable<String> values = Observable.just("No", "side", "effects", "please");
Inc index = new Inc();
Observable<String> indexed =
values.map(w -> {
index.inc();
return w;
});
indexed.subscribe(w -> System.out.println(index.getCount() + ": " + w));1: No
2: side
3: effects
4: please
So far it appears ok. Let's see what happens when we try to subscribe to that observable a second time.
Observable<String> values = Observable.just("No", "side", "effects", "please");
Inc index = new Inc();
Observable<String> indexed =
values.map(w -> {
index.inc();
return w;
});
indexed.subscribe(w -> System.out.println("1st observer: " + index.getCount() + ": " + w));
indexed.subscribe(w -> System.out.println("2nd observer: " + index.getCount() + ": " + w));1st observer: 1: No
1st observer: 2: side
1st observer: 3: effects
1st observer: 4: please
2nd observer: 5: No
2nd observer: 6: side
2nd observer: 7: effects
2nd observer: 8: please
The second subscriber sees the indexing starting at 5, which is non-sense. While the bug here is straight-forward to discover, side effects can lead to bugs which are a lot more subtle.
The safest way to use state in Rx is to include it in the data emitted. We can pair items with their indices using scan.
class Indexed <T> {
public final int index;
public final T item;
public Indexed(int index, T item) {
this.index = index;
this.item = item;
}
}Observable<String> values = Observable.just("No", "side", "effects", "please");
Observable<Indexed<String>> indexed =
values.scan(
new Indexed<String>(0, null),
(prev,v) -> new Indexed<String>(prev.index+1, v))
.skip(1);
indexed.subscribe(w -> System.out.println("1st observer: " + w.index + ": " + w.item));
indexed.subscribe(w -> System.out.println("2nd observer: " + w.index + ": " + w.item));1st observer: 1: No
1st observer: 2: side
1st observer: 3: effects
1st observer: 4: please
2nd observer: 1: No
2nd observer: 2: side
2nd observer: 3: effects
2nd observer: 4: please
The result now is valid. We removed the shared state between the two subscriptions and now they can't affect each other.
There are cases where we do want a side effect, for example when logging. The subscribe method always has a side effect, otherwise it is not useful. We could put our logging in the body of a subscriber but then we would have two disadvantages:
- We are mixing the less interesting code of logging with the critical code of our subscription
- If we wanted to log an intermediate state in our pipeline, e.g. before and after mapping, we would have to to introduce an additional subscription just for that, which won't necessarily see exactly what the consumer saw and at the time when they saw it.
The next family of methods helps us declare side effects in a tidier manner.
public final Observable<T> doOnCompleted(Action0 onCompleted)
public final Observable<T> doOnEach(Action1<Notification<? super T>> onNotification)
public final Observable<T> doOnEach(Observer<? super T> observer)
public final Observable<T> doOnError(Action1<java.lang.Throwable> onError)
public final Observable<T> doOnNext(Action1<? super T> onNext)
public final Observable<T> doOnTerminate(Action0 onTerminate)As we can see, they take actions to perform when items are emitted. They also return the Observable<T>, which means that we can use them between operators in our pipeline. In some cases, you could achieve the same result using map or filter. Using doOn* is better because it documents your intention to have a side effect. Here's an example
Observable<String> values = Observable.just("side", "effects");
values
.doOnEach(new PrintSubscriber("Log"))
.map(s -> s.toUpperCase())
.subscribe(new PrintSubscriber("Process"));Log: side
Process: SIDE
Log: effects
Process: EFFECTS
Log: Completed
Process: Completed
We reused our convenient PrintSubscriber from previous chapters. The "do" methods are not affected by the transformations later in the pipeline. We can log what our service produces regardless of what the consumer actually consumes. Consider the following service:
static Observable<String> service() {
return Observable.just("First", "Second", "Third")
.doOnEach(new PrintSubscriber("Log"));
}Then we use it:
service()
.map(s -> s.toUpperCase())
.filter(s -> s.length() > 5)
.subscribe(new PrintSubscriber("Process"));Log: First
Log: Second
Process: SECOND
Log: Third
Log: Completed
Process: Completed
We logged everything that our service produced, even though the consumer modified and filtered the results.
The differences between the different variants for "do" should be apparent by this point. In summary:
doOnEachruns when any notification is emitteddoOnNextruns when a value is emitteddoOnErrorruns when the observable terminates with an errordoOnCompletedruns when the observable terminates with no errordoOnTerminateruns when the observable terminates
One special note is the onTerminate, which runs right before the observable terminates with either onCompleted or onError. There is also the method finallyDo, which will run immediately after the observable terminates.
public final Observable<T> doOnSubscribe(Action0 subscribe)
public final Observable<T> doOnUnsubscribe(Action0 unsubscribe)Subscription and unsubscription are not events that are emitted by an observable. They can still be seen as events in a general sense and you may want to perform some actions when they occur. Most likely, you'll be using them for logging purposes.
ReplaySubject<Integer> subject = ReplaySubject.create();
Observable<Integer> values = subject
.doOnSubscribe(() -> System.out.println("New subscription"))
.doOnUnsubscribe(() -> System.out.println("Subscription over"));
Subscription s1 = values.subscribe(new PrintSubscriber("1st"));
subject.onNext(0);
Subscription s2 = values.subscribe(new PrintSubscriber("2st"));
subject.onNext(1);
s1.unsubscribe();
subject.onNext(2);
subject.onNext(3);
subject.onCompleted();New subscription
1st: 0
New subscription
2st: 0
1st: 1
2st: 1
Subscription over
2st: 2
2st: 3
2st: Completed
Subscription over
Rx is designed in the style of functional programming, but it exists within an object-oriented environment. We also have to protect against object-oriented dangers. Consider this naive implementation for a service that returns an observable.
public class BrakeableService {
public BehaviorSubject<String> items = BehaviorSubject.create("Greet");
public void play() {
items.onNext("Hello");
items.onNext("and");
items.onNext("goodbye");
}
}The code above does not prevent a naughty consumer from changing your items with one of their own. After that happens, subscriptions done before the change will no longer receive items, because you are not calling onNext on the right Subject any more. We obviously need to hide access to our Subject
public class BrakeableService {
private final BehaviorSubject<String> items = BehaviorSubject.create("Greet");
public BehaviorSubject<String> getValues() {
return items;
}
public void play() {
items.onNext("Hello");
items.onNext("and");
items.onNext("goodbye");
}
}Now our reference is safe, but we are still exposing a reference to a Subject. Anyone can call onNext on our Subject and inject values in our sequence. We should only return Observable<T>, which is an immutable object. Subjects extend Observable and we can cast our subject
public Observable<String> getValuesUnsafe() {
return items;
}Our API now looks safe, but it isn't. Nothing is stopping a user from discovering that our Observable is actually a Subject (e.g. using instanceof), casting it to a Subject and using it like previously.
The idea behind the asObservable method is to wrap extensions of Observable into an actual Observable that can be safely shared, since Observable is immutable.
public Observable<String> getValues() {
return items.asObservable();
}Now we have properly protected our Subject. This protection is not only against malicious attacks but also against mistakes. We have mentioned before that subjects should be avoided when alternatives exist, and now we've seen examples of why. Subjects introduce state to our observables. Calls to onNext, onCompleted and onError alter the sequence that consumers will see. Observables that are constructed with any of the factory methods or operators exposed on Observable are immutable, provided that we don't introduce side-effects ourselves, as we saw in Issues with side effects.
You can find the full code of the examples discussed here
As one might expect, an Rx pipeline forwards references to objects and doesn't create copies (unless we do so ourselves in the functions we supply). Modifications to the objects will be visible to every position in the pipeline that uses them. Consider the following mutable class:
class Data {
public int id;
public String name;
public Data(int id, String name) {
this.id = id;
this.name = name;
}
}Now we show an observable of that type and two subscribers.
Observable<Data> data = Observable.just(
new Data(1, "Microsoft"),
new Data(2, "Netflix")
);
data.subscribe(d -> d.name = "Garbage");
data.subscribe(d -> System.out.println(d.id + ": " + d.name));1: Garbage
2: Garbage
The first subscriber is the first to be called for each item. Its action is to modify the data. Once the first subscriber is done, the same reference is also passed to the second subscriber, only now the data is changed in a way that was not declared in the producer. A developer needs to have a deep understanding of Rx, Java and their environment in order to reason about the sequence of modifications, and then argue that such code would run according to a plan. It is simpler to avoid mutable state altogether. Observables should be seen as a sequence notifications about resolved events.
A monad is an abstract concept from functional programming that is unfamiliar to most programmers. It is beyond the scope of this guide teaching monads. In www.introtorx.com we find a short definition:
Monads are a kind of abstract data type constructor that encapsulate program logic instead of data in the domain model.
Monads are of interest to us, because the observable is a monad. Rx code declares what needs to be done but the actual processing happens not when Rx statements are executed, but rather when values are emitted. Readers may find it interesting to read more about monads in general. For this guide, when refering to monads the reader only needs to think about the observable.
There are two main reasons one may want to leave the monad. The first reason is that a new Rx developer will still be more comfortable in more traditional paradigms. Doing parts of the computation in a different paradigm may enable you to get some parts working, while you're still figuring out how to do things in Rx. The second reason is that we usually interact with components and libraries that weren't designed with Rx in mind. When refactoring existing code into Rx, it may be useful to have Rx behave in a blocking way.
The first step to getting data out of an observable in a blocking manner is to transition to a BlockingObservable. Any Observable can be converted to a BlockingObservable in one of two ways:
You can use the Observable's toBlocking method
public final BlockingObservable<T> toBlocking()or the static factory of BlockingObservable
public static <T> BlockingObservable<T> from(Observable<? extends T> o)BlockingObservable does not extend the Observable and it can't be used with our usual Rx operators. It has its own implementations of a small set functions, which allow you to extract data out of an Observable in a blocking manner. Many of those methods are the blocking counterparts to methods that we have already seen.
Observable has a method called forEach. forEach is defined as an alias to subscribe, with the main difference being that it doesn't return a Subscription.
Consider this example
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values
.take(5)
.forEach(v -> System.out.println(v));
System.out.println("Subscribed");Subscribed
0
1
2
3
4
The code here behaves like subscribe would. First you register an observer (no overload for forEach accepts Observer, but the semantics are the same). Execution then proceeds to print "Subscribed" and exits our snippet. As values are emitted (the first one with a 100ms delay), they are passed to our observer for processing.
BlockingObservable doesn't have a subscribe function, but it has forEach. Let's see the same example with BLockingObservable
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values
.take(5)
.toBlocking()
.forEach(v -> System.out.println(v));
System.out.println("Subscribed");0
1
2
3
4
Subscribed
We see here that the call to forEach blocked until the observable completed. Another difference is that there can be no handlers for onError and onCompleted. onCompleted is a given if the execution completes, while exceptions will be thrown into the runtime to be caught:
Observable<Long> values = Observable.error(new Exception("Oops"));
try {
values
.take(5)
.toBlocking()
.forEach(v -> System.out.println(v));
}
catch (Exception e) {
System.out.println("Caught: " + e.getMessage());
}
System.out.println("Subscribed");Caught: java.lang.Exception: Oops
Subscribed
BlockingObservable has methods for first, last and single, along with implementations for default values firstOrDefault, lastOrDefault and singleOrDefault. Having read about their namesakes in Observable, you already know what the returned value is. Once again, the difference is the blocking nature of the methods. They don't return an observable that will emit the value when it is available. Rather, they block until the value is available and return the value itself, without the surrounding observable.
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
long value = values
.take(5)
.toBlocking()
.first(i -> i>2);
System.out.println(value);3
As we can see, the call to first blocked until a value was available, and only then was a value returned.
Like with forEach, exceptions are thrown in the runtime to be caught
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
try {
long value = values
.take(5)
.toBlocking()
.single(i -> i>2);
System.out.println(value);
}
catch (Exception e) {
System.out.println("Caught: " + e);
}Caught: java.lang.IllegalArgumentException: Sequence contains too many elements
You can transform your observables to iterables throught a variety of methods on BlockingObservable. Iterables are pull-based, unlike Rx, which is push-based. That means that when the consumer is ready to consume a value, one is requested with next() on the iterable's Iterator. The call to next() will either return a value immediately or block until one is ready.
There are several ways to go from BlockingObservable<T> to Iterable<T> and each has a different behaviour.
public java.lang.Iterable<T> toIterable()
In this implementation, all the emitted values are collected and cached. Because of the caching, no items will be missed. The iterator gets the next value as soon as possible, either immediately if it has already occured, or it blocks until the next value becomes available.
Observable<Long> values = Observable.interval(500, TimeUnit.MILLISECONDS);
Iterable<Long> iterable = values.take(5).toBlocking().toIterable();
for (long l : iterable) {
System.out.println(l);
}0
1
2
3
4
An interesting thing to note is that either hasNext() or next() block until the next notification is available. If the observable completes, hasNext returns false and next throws a java.util.NoSuchElementException
public java.lang.Iterable<T> next()
In this implementation values are not cached at all. The iterator will always wait for the next value and return that.
Observable<Long> values = Observable.interval(500, TimeUnit.MILLISECONDS);
values.take(5)
.subscribe(v -> System.out.println("Emitted: " + v));
Iterable<Long> iterable = values.take(5).toBlocking().next();
for (long l : iterable) {
System.out.println(l);
Thread.sleep(750);
}Emitted: 0
0
Emitted: 1
Emitted: 2
2
Emitted: 3
Emitted: 4
4
In this example the consumer is slower than the producer and always misses the next value. The iterator gets the next after that.
public java.lang.Iterable<T> latest()The latest method is similar to next, with the difference that it will cache one value. The iterator only blocks if no events have been emitted by the observable since the last value was consumed. As long as there has been a new event, the iterator will return immediately with a value, or with the termination of the iteration.
Observable<Long> values = Observable.interval(500, TimeUnit.MILLISECONDS);
values.take(5)
.subscribe(v -> System.out.println("Emitted: " + v));
Iterable<Long> iterable = values.take(5).toBlocking().latest();
for (long l : iterable) {
System.out.println(l);
Thread.sleep(750);
}Emitted: 0
0
Emitted: 1
1
Emitted: 2
Emitted: 3
3
Emitted: 4
When using the latest iterator, values will be skipped if they are not pulled before the next event is emitted. If the consumer is faster than the producer, the iterator will block and wait for the next value.
It is interesting here that 4 was never consumed. That was because an onCompleted followed immediately, resulting in the next pull seeing a terminated observable. The implicit iterator.hasNext() method reports a terminated observable without checking if the last value has been consumed.
public java.lang.Iterable<T> mostRecent(T initialValue)
The mostRecent iterator never blocks. It caches a single value, therefore values may be skipped if the consumer is slow. Unlike latest, the last cached value is always returned, resulting in repetitions if the consumer is faster than the producer. To allow the mostRecent iterator to be completely non-blocking, an initial value is needed. That value is returned if the observable has not emitted any values yet.
Observable<Long> values = Observable.interval(500, TimeUnit.MILLISECONDS);
values.take(5)
.subscribe(v -> System.out.println("Emitted: " + v));
Iterable<Long> iterable = values.take(5).toBlocking().mostRecent(-1L);
for (long l : iterable) {
System.out.println(l);
Thread.sleep(400);
}-1
-1
Emitted: 0
0
Emitted: 1
1
Emitted: 2
2
Emitted: 3
3
3
Emitted: 4
A BlockingObservable<T> can be presented as a Future<T> using the toFuture method. This method only creates an instance of Future and does not block. Execution blocks as necessary when getting the value. Future allows the consumer to decide how to approach an asynchronous operation. A Future is also capable of reporting errors in the operation.
Observable<Long> values = Observable.timer(500, TimeUnit.MILLISECONDS);
values.subscribe(v -> System.out.println("Emitted: " + v));
Future<Long> future = values.toBlocking().toFuture();
System.out.println(future.get());Emitted: 0
0
Futures that are created in this way expect that the observable will emit a single value, just like the single method does. If multiple items are emitted, the Future will report a java.lang.IllegalArgumentException.
So far we were able to ignore potential deadlocks. Rx's non-blocking nature makes it harder to create unnecessary deadlocks. However, in this chapter we returned to blocking methods, thus bringing deadlocks to the forefront again.
The example below would work as a non-blocking case. But because we used blocking operations, it will never unblock
ReplaySubject<Integer> subject = ReplaySubject.create();
subject.toBlocking().forEach(v -> System.out.println(v));
subject.onNext(1);
subject.onNext(2);
subject.onCompleted();forEach returns only after the termination of the sequence. However, the termination event requires forEach to return before being pushed. Therefore, forEach will never unblock.
Some blocking ways to access observables, such as last(), require the observable to terminate to unblock. Others, like first(), require it to emit at least one event to unblock. Using those methods on Observable isn't a big danger, as they only return a non-terminating observable. These same methods on BlockingObservable can result in a permanent block if the consumer hasn't taken the time to enforce some guarantees, such as timeouts (we will see how this is done in [Timeshifter sequences](/Part 3 - Taming the sequence/5. Time-shifted sequences.md)).
We've already seen how we can handle an error in the observer. However, by that time, we are practically outside of the monad. There can be many kinds of errors and not every error is worth pushing all the way to the top. In standard Java, you can catch an exception at any level and decide if you want to handle it there or throw it further. Similarly in Rx, you can define behaviour based on errors without terminating the observable and forcing the observer to deal with everything.
The onErrorReturn operator allows you to ignore an error and emit one final value before terminating (successfully this time).

In the next example, we will convert an error into a normal value to be printed:
Observable<String> values = Observable.create(o -> {
o.onNext("Rx");
o.onNext("is");
o.onError(new Exception("adjective unknown"));
});
values
.onErrorReturn(e -> "Error: " + e.getMessage())
.subscribe(v -> System.out.println(v));Rx
is
Error: adjective unknown
The onErrorResumeNext allows you to resume a failed sequence with another sequence. The error will not appear in the resulting observable.
public final Observable<T> onErrorResumeNext(
Observable<? extends T> resumeSequence)
public final Observable<T> onErrorResumeNext(
Func1<java.lang.Throwable,? extends Observable<? extends T>> resumeFunction)
The first overload uses the same followup observable in every case. The second overload allows you to decide what the resume sequence should be based on the error that occurred.
Observable<Integer> values = Observable.create(o -> {
o.onNext(1);
o.onNext(2);
o.onError(new Exception("Oops"));
});
values
.onErrorResumeNext(Observable.just(Integer.MAX_VALUE))
.subscribe(new PrintSubscriber("with onError: "));with onError: 1
with onError: 2
with onError: 2147483647
with onError: Completed
There's nothing stopping the resumeSequence from failing as well. In fact, if you wanted to change the type of the error, you can return an observable that fails immediately. In standard Java, components may decide they can't handle an error and that they should re-throw it. In such cases, it is common wrap a new exception around the original error, thus providing additional context. You can do the same in Rx:
.onErrorResumeNext(e -> Observable.error(new UnsupportedOperationException(e)))Now the sequence still fails, but you've wrapped the original error in a new error.
onExceptionResumeNext only has one difference to onErrorResumeNext: it only catches errors that are Exceptions.
Observable<String> values = Observable.create(o -> {
o.onNext("Rx");
o.onNext("is");
//o.onError(new Throwable() {}); // this won't be caught
o.onError(new Exception()); // this will be caught
});
values
.onExceptionResumeNext(Observable.just("hard"))
.subscribe(v -> System.out.println(v));If the error is non-deterministic, it may make sense to retry. retry re-subscribes to the source and emits everything again from the start.
public final Observable<T> retry()
public final Observable<T> retry(long count)
If the error doesn't go away, retry() will lock us in an infinite loop of retries. The second overload limits the number of retries. If errors persist and the sequence fails n times, retry(n) will fail too. Let's see this in an example
Random random = new Random();
Observable<Integer> values = Observable.create(o -> {
o.onNext(random.nextInt() % 20);
o.onNext(random.nextInt() % 20);
o.onError(new Exception());
});
values
.retry(1)
.subscribe(v -> System.out.println(v));0
13
9
15
java.lang.Exception
Here we've specified that we want to retry once. Our observable fails after two values, then tries again, fails again. The second time it fails the exception is allowed pass through.
In this example, we have done something naughty: we have made our subscription stateful to demonstrate that the observable is restarted from the source: it produced different values the second time around. retry does not cache any elements like replay, nor would it make sense to do so. Retrying makes sense only if there are side effects, or if the observable is hot.
retry will restart the subscription as soon as the failure happens. If we need more control over this, we can use retryWhen.
public final Observable<T> retryWhen(
Func1<? super Observable<? extends java.lang.Throwable>,? extends Observable<?>> notificationHandler)The argument to retryWhen is a function that takes an observable and returns another. The input observable emits all the errors that retryWhen encounters. The resulting observable signals when to retry:
- if it emits a value,
retryWhenwill retry, - if it terminates with error,
retryWhenwill emit the error and not retry. - if it terminates successfully,
retryWhenwill terminate successfully.
Note that the type of the signaling observable and the actual values emitted don't matter. The values are discarded and the observable is only used for timing.
In the next example, we will construct a retrying policy where we wait 100ms before retrying.
Observable<Integer> source = Observable.create(o -> {
o.onNext(1);
o.onNext(2);
o.onError(new Exception("Failed"));
});
source.retryWhen((o) -> o
.take(2)
.delay(100, TimeUnit.MILLISECONDS))
.timeInterval()
.subscribe(
System.out::println,
System.out::println);TimeInterval [intervalInMilliseconds=21, value=1]
TimeInterval [intervalInMilliseconds=0, value=2]
TimeInterval [intervalInMilliseconds=104, value=1]
TimeInterval [intervalInMilliseconds=0, value=2]
TimeInterval [intervalInMilliseconds=103, value=1]
TimeInterval [intervalInMilliseconds=0, value=2]
Our source observable emits 2 values and immediately fails. When that happens, the observable of failures inside retryWhen emits the error. We delay that emission by 100ms and send it back to signal a retry. take(2) guarantees that our signaling observable will terminate after we receive two errors. retryWhen sees the termination and doesn't retry after the second failures.
The using operator is for creating observables from resources that need to be managed. It guarantees that your resources will be managed regardless of when and how subscriptions are terminated. If you were to just use create, you would have to do the managing in the traditional Java paradigm and inject it into Rx. using is a more natural way of managing resources in Rx.
public static final <T,Resource> Observable<T> using(
Func0<Resource> resourceFactory,
Func1<? super Resource,? extends Observable<? extends T>> observableFactory,
Action1<? super Resource> disposeAction)When a new subscription begins, resourceFactory leases the necessary resource. observableFactory uses that resource to produce items. When the resource is no longer needed, it is disposed of with the disposeAction. The dispose action is executed regardless of the way the subscription terminates (successfully or with a failure).
In the next example, we pretend that a string is a resource that needs managing.
Observable<Character> values = Observable.using(
() -> {
String resource = "MyResource";
System.out.println("Leased: " + resource);
return resource;
},
(resource) -> {
return Observable.create(o -> {
for (Character c : resource.toCharArray())
o.onNext(c);
o.onCompleted();
});
},
(resource) -> System.out.println("Disposed: " + resource));
values
.subscribe(
v -> System.out.println(v),
e -> System.out.println(e));Leased: MyResource
M
y
R
e
s
o
u
r
c
e
Disposed: MyResource
When we subscribe to values, the resource factory function is called which returns "MyResource". That string is used to produce an observable which emits all of the characters in the string. Once the subscription ends, the resource is disposed of. A String doesn't need any more managing than what the garbage collector will do. Resources may actually need such managing, e.g., database connections, opened files etc.
It is important to note here that we are responsible for terminating the observable, just like we were when using the create method. With create, terminating is a matter of semantics. With using, not terminating defeats the point of using it in the first place. Only upon termination the resources will be released. If we had not called o.onCompleted(), the sequence would be assumed to be still active and needing its resources.
So far, we've seen most of the methods that allow us to create a sequence and transform it into what we want. However, most applications will have more than one source of input. We need a way a of combining sequences. We've already seen a few sequences that use more than one observable. In this chapter, we will see the most important operators that use multiple sequences to produce one.
The most straight-forward combination of sequences is to have one run after the other.
The concat operator concatenates sequences one after the other. There are many overloads to concat, which allow you to provide source observables in different numbers and formats.
public static final <T> Observable<T> concat(
Observable<? extends Observable<? extends T>> observables)
public static final <T> Observable<T> concat(
Observable<? extends T> t1,
Observable<? extends T> t2)
public static final <T> Observable<T> concat(Observable<? extends T> t1,
Observable<? extends T> t2,
Observable<? extends T> t3)
public static final <T> Observable<T> concat(Observable<? extends T> t1,
Observable<? extends T> t2,
Observable<? extends T> t3,
Observable<? extends T> t4)
// All the way to 10 observables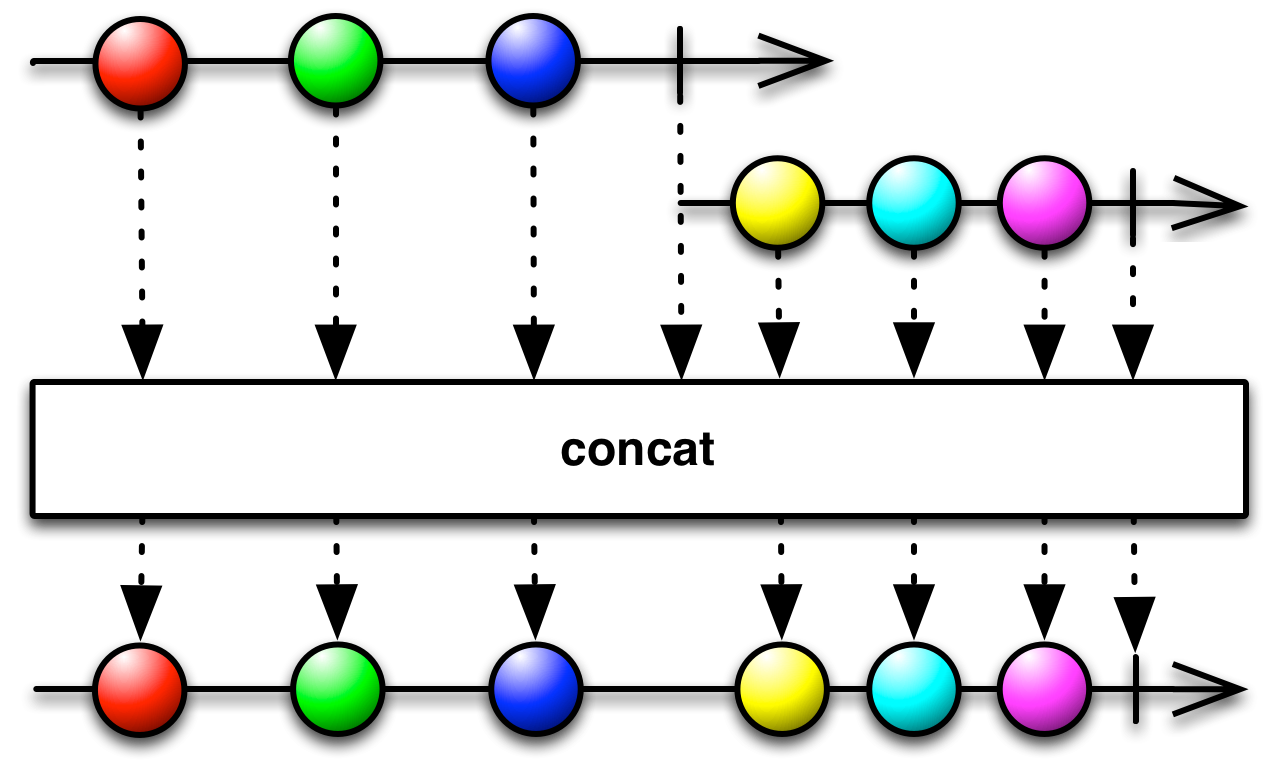
Concatenating two (or more) given observables is straightforward.
Observable<Integer> seq1 = Observable.range(0, 3);
Observable<Integer> seq2 = Observable.range(10, 3);
Observable.concat(seq1, seq2)
.subscribe(System.out::println);0
1
2
10
11
12
If the number of sequences to be combined is dynamic, you can provide an observable that emits the sequences to be concatenated. In this example, we will use our familiar groupBy to create a sequence that emits words starting with the same letter together.
Observable<String> words = Observable.just(
"First",
"Second",
"Third",
"Fourth",
"Fifth",
"Sixth"
);
Observable.concat(words.groupBy(v -> v.charAt(0)))
.subscribe(System.out::println);First
Fourth
Fifth
Second
Sixth
Third
concat behaves like the flattening phase of concatMap. In fact, concatMap is an alias for applying map and then concat.
The concatWith operator is an alternative style of doing concat, which allows you to combine sequences one by one in a chain:
public void exampleConcatWith() {
Observable<Integer> seq1 = Observable.range(0, 3);
Observable<Integer> seq2 = Observable.range(10, 3);
Observable<Integer> seq3 = Observable.just(20);
seq1.concatWith(seq2)
.concatWith(seq3)
.subscribe(System.out::println);
}0
1
2
10
11
12
20
repeat allows you to concatenate a sequence after itself, either an infinite or a finite number of times. repeat doesn't cache the values to repeat them. When the time comes, it will start a new subscription and dispose of the old one.
public final Observable<T> repeat()
public final Observable<T> repeat(long count)Its application is very simple
Observable<Integer> words = Observable.range(0,2);
words.repeat(2)
.subscribe(System.out::println);0
1
0
1
If you need more control than repeat gives, you can control when the repetition starts with the repeatWhen operator. The when is defined by an observable that you provide. When the original sequence completes, it waits for the handling observable to emit something (the value is irrelevant) and only then does it repeat. If the handling observable terminates, that means that the repetitions should stop.
It may be useful for the signal to know when a repetition has been completed. repeatWhen provides a special observable that emits void when a repetition terminates. You can use that observable to construct your signal.
public final Observable<T> repeatWhen(
Func1<? super Observable<? extends java.lang.Void>,? extends Observable<?>> notificationHandler)
The argument of repeatWhen is a function that takes an observable and returns an observable. The types emitted by both objects do not matter. The input is the observable that signals the end of a repetition and the returned observable will be used to signal a restart.
In the next example, we create our version of repeat(n) using repeatWhen.
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values
.take(2)
.repeatWhen(ob -> {
return ob.take(2);
})
.subscribe(new PrintSubscriber("repeatWhen"));repeatWhen: 0
repeatWhen: 1
repeatWhen: 0
repeatWhen: 1
repeatWhen: Completed
Here the repetition happens immediately: ob emits when a repetition has ended, so the returned observable also emits right after a completed repetition. That signal the new repetition to begin.
In the next example, we create sequence that repeats every two seconds, forever.
Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values
.take(5)
.repeatWhen((ob)-> {
ob.subscribe();
return Observable.interval(2, TimeUnit.SECONDS);
})
.subscribe(new PrintSubscriber("repeatWhen"));Note that the sequence repeats every 2 seconds regardless of when it completed. That's because we created an independent interval observable that sends a signal every 2 seconds. In the next chapter, [Time-shifted sequences](/Part 3 - Taming the sequence/5. Time-shifted sequences.md), we will see ways of dealing with sequences in time with more control.
Another thing to note is the ob.subscribe() statement, which appears to be useless. That is necessary because it forces ob to be created. In the current implementation of repeatWhen, if ob is not subscribed to, then repetitions never begin.
startWith takes a sequence and concatenates it before the observable it is applied to.
public final Observable<T> startWith(java.lang.Iterable<T> values)
public final Observable<T> startWith(Observable<T> values)
public final Observable<T> startWith(T t1)
public final Observable<T> startWith(T t1, T t2)
public final Observable<T> startWith(T t1, T t2, T t3)
// up to 10 values
Here an example
Observable<Integer> values = Observable.range(0, 3);
values.startWith(-1,-2)
.subscribe(System.out::println);-1
-2
0
1
2
startWith is a shorthand for using concat with a just and our source sequence.
Observable.concat(
Observable.just(-1,-2,-3),
values)
// Same as
values.startWith(-1,-2,-3)Observables aren't always emitting values at predictable moments in time. We will now see some operators intended for combining sequences that emit values concurrently.
ambtakes a number of observables and returns the one that emits a value first. The rest are discarded.
public static final <T> Observable<T> amb(
java.lang.Iterable<? extends Observable<? extends T>> sources)
public static final <T> Observable<T> amb(
Observable<? extends T> o1,
Observable<? extends T> o2)
public static final <T> Observable<T> amb(
Observable<? extends T> o1,
Observable<? extends T> o2,
Observable<? extends T> o3)
// Up to 10 observables
In the following example, amb will mirror the second observable, because it waits less to start.
Observable.amb(
Observable.timer(100, TimeUnit.MILLISECONDS).map(i -> "First"),
Observable.timer(50, TimeUnit.MILLISECONDS).map(i -> "Second"))
.subscribe(System.out::println);Second
It's usefulness may be not be obvious
The amb feature can be useful if you have multiple cheap resources that can provide values, but latency is widely variable. For an example, you may have servers replicated around the world. Issuing a query is cheap for both the client to send and for the server to respond, however due to network conditions the latency is not predictable and varies considerably. Using the Amb operator, you can send the same request out to many servers and consume the result of the first that responds. -Lee Cambell www.introtorx.com
An alternative style of doing amb is the ambWith operator. ambWith allows you to combine the observables one by one in a chain. This is more convenient when using amb in the middle of a chain or operators.
Observable.timer(100, TimeUnit.MILLISECONDS).map(i -> "First")
.ambWith(Observable.timer(50, TimeUnit.MILLISECONDS).map(i -> "Second"))
.ambWith(Observable.timer(70, TimeUnit.MILLISECONDS).map(i -> "Third"))
.subscribe(System.out::println);Second
merge combines a set of observables into one. The resulting observable emits the values that the source observables emit, as they emit them. This means that values from different sequences can be mixed.
public static final <T> Observable<T> merge(
java.lang.Iterable<? extends Observable<? extends T>> sequences)
public static final <T> Observable<T> merge(
java.lang.Iterable<? extends Observable<? extends T>> sequences,
int maxConcurrent)
public static final <T> Observable<T> merge(
Observable<? extends Observable<? extends T>> source)
public static final <T> Observable<T> merge(
Observable<? extends Observable<? extends T>> source,
int maxConcurrent)
public static final <T> Observable<T> merge(
Observable<? extends T> t1,
Observable<? extends T> t2)
public static final <T> Observable<T> merge(
Observable<? extends T> t1,
Observable<? extends T> t2,
Observable<? extends T> t3)
...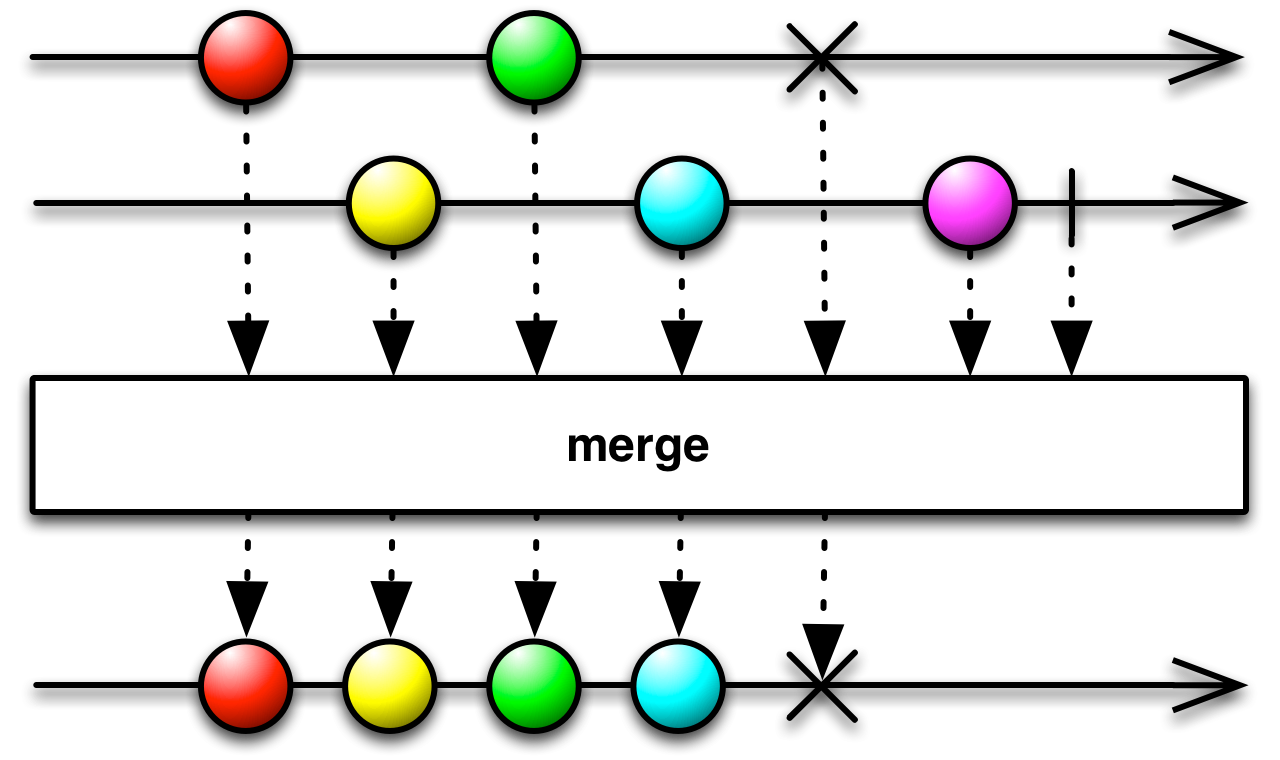
The many overloads are different ways of supplying a set of observables to merge. Here an example of what merge does
Observable.merge(
Observable.interval(250, TimeUnit.MILLISECONDS).map(i -> "First"),
Observable.interval(150, TimeUnit.MILLISECONDS).map(i -> "Second"))
.take(10)
.subscribe(System.out::println);Second
First
Second
Second
First
Second
Second
First
Second
First
The difference between concat and merge is that merge does not wait for the current observable to terminate before moving to the next. merge subscribes to every observable available to it and emits items as they come. In that way, merge is similar to the flattening part of flatMap.
Like other combinators that are static methods, merge has an alternative that allows you to merge sequences one by one in a chain. The operator is called mergeWith and the behaviour is the same. The following example has the same result as the one above.
Observable.interval(250, TimeUnit.MILLISECONDS).map(i -> "First")
.mergeWith(Observable.interval(150, TimeUnit.MILLISECONDS).map(i -> "Second"))
.take(10)
.subscribe(System.out::println);With merge, as soon as any of the source sequences fails, the merged sequence fails as well. An alternative to that behaviour is mergeDelayError, which will postpone the emission of an error and continue to merge values from sequences that haven't failed.
public static final <T> Observable<T> mergeDelayError(
Observable<? extends Observable<? extends T>> source)
public static final <T> Observable<T> mergeDelayError(
Observable<? extends T> t1,
Observable<? extends T> t2)
public static final <T> Observable<T> mergeDelayError(
Observable<? extends T> t1,
Observable<? extends T> t2,
Observable<? extends T> t3)
...
In the next example, we merge two observables which emit every 100ms. One fails early while the other observable continues to complete.
Observable<Long> failAt200 =
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(2),
Observable.error(new Exception("Failed")));
Observable<Long> completeAt400 =
Observable.interval(100, TimeUnit.MILLISECONDS)
.take(4);
Observable.mergeDelayError(failAt200, completeAt400)
.subscribe(
System.out::println,
System.out::println);0
0
1
1
2
3
java.lang.Exception: Failed
In the beginning, both observables emit the same value. After value 1, the first sequence fails, and the merged sequence continues with values only from the second sequence.
When merging more than two sequences, the merged sequence will go on until all of the sources have terminated, successfully or with an error. If more than one sequences fail, the error in the merged sequence will be of type CompositeException
Observable<Long> failAt200 =
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(2),
Observable.error(new Exception("Failed")));
Observable<Long> failAt300 =
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(3),
Observable.error(new Exception("Failed")));
Observable<Long> completeAt400 =
Observable.interval(100, TimeUnit.MILLISECONDS)
.take(4);
Observable.mergeDelayError(failAt200, failAt300, completeAt400)
.subscribe(
System.out::println,
System.out::println);0
0
0
1
1
1
2
2
3
rx.exceptions.CompositeException: 2 exceptions occurred.
The switchOnNext operator takes an observable that emits observables. The returned observable emits items from the most recent observable. As soon as a new observable comes, the old one is discarded and values from the newer one are emitted.

Observable.switchOnNext(
Observable.interval(100, TimeUnit.MILLISECONDS)
.map(i ->
Observable.interval(30, TimeUnit.MILLISECONDS)
.map(i2 -> i)
)
)
.take(9)
.subscribe(System.out::println);0
0
0
1
1
1
2
2
2
This example may be a bit confusing. What we've done is creating an observable that creates a new observable every 100ms. Every created observable emits its number in the sequence every 30ms. After 100ms, each of those observables has had enough time to emit its number 3 times. Then a new observable is created, which causes them to be replaced by the new one.
Where flatMap internally uses merge to combine the generated sequences and concatMap uses concat, there is switchMap to use switchOnNext for the flattening phase.
public final <R> Observable<R> switchMap(Func1<? super T,? extends Observable<? extends R>> func)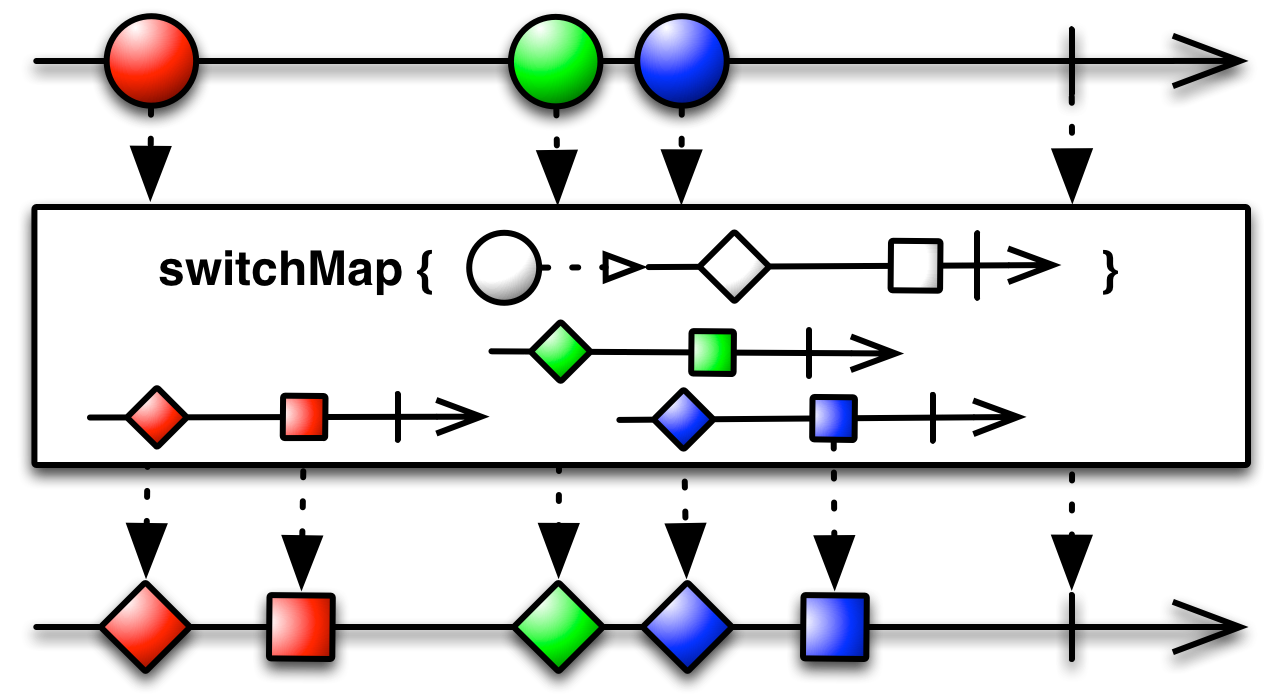
Every value from the source sequence is mapped through func to an observable. The values from the generated observable are emitted by the returned observable. Every time a new value arrives, func generates a new observable and switches to it, dropping the old one. The example we showed for switchOnNext can also be implemented with switchMap:
Observable.interval(100, TimeUnit.MILLISECONDS)
.switchMap(i ->
Observable.interval(30, TimeUnit.MILLISECONDS)
.map(l -> i))
.take(9)
.subscribe(System.out::println);0
0
0
1
1
1
2
2
2
So far, we've seen operators which, in one way or the other, flattened multiple sequences into one of the same type. The next operators put the source sequences side-by-side and use the values to create a composite value.
zip is a very basic function out of functional programming. It takes two or more sequences and matches their values one-to-one by index. A function is required to combine the values. Unlike what you might expect from other environments, in RxJava zip doesn't default to combining all the values in a tuple.
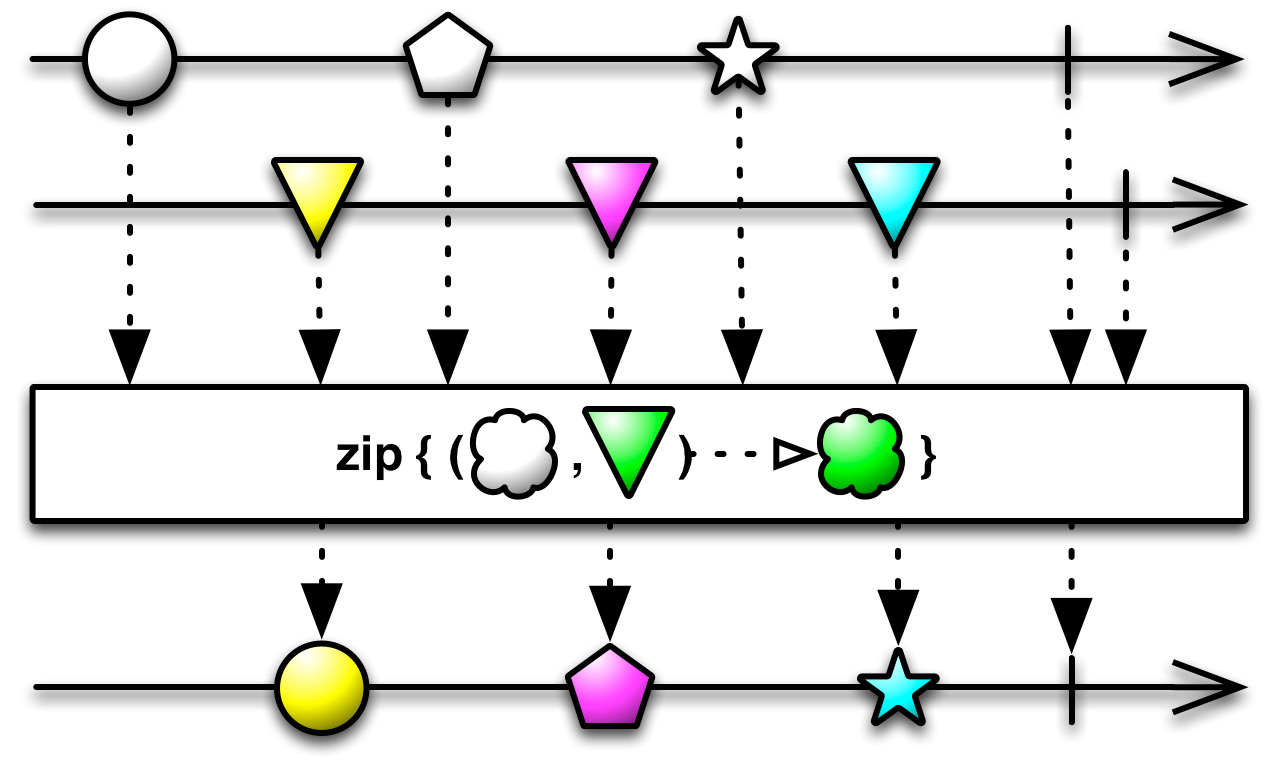
In the next example, we have two sources that emit items at different rates.
Observable.zip(
Observable.interval(100, TimeUnit.MILLISECONDS)
.doOnNext(i -> System.out.println("Left emits " + i)),
Observable.interval(150, TimeUnit.MILLISECONDS)
.doOnNext(i -> System.out.println("Right emits " + i)),
(i1,i2) -> i1 + " - " + i2)
.take(6)
.subscribe(System.out::println);Left emits 0
Right emits 0
0 - 0
Left emits 1
Right emits 1
Left emits 2
1 - 1
Left emits 3
Right emits 2
2 - 2
Left emits 4
Left emits 5
Right emits 3
3 - 3
Left emits 6
Right emits 4
4 - 4
Left emits 7
Right emits 5
Left emits 8
5 - 5
As we can see, zip matched values based on index.
zip has multiple overloads for zipping more than two sequences together.
public static final <R> Observable<R> zip(
java.lang.Iterable<? extends Observable<?>> ws,
FuncN<? extends R> zipFunction)
public static final <R> Observable<R> zip(
Observable<? extends Observable<?>> ws,
FuncN<? extends R> zipFunction)
public static final <T1,T2,R> Observable<R> zip(
Observable<? extends T1> o1,
Observable<? extends T2> o2,
Func2<? super T1,? super T2,? extends R> zipFunction)
public static final <T1,T2,T3,R> Observable<R> zip(
Observable<? extends T1> o1,
Observable<? extends T2> o2,
Observable<? extends T3> o3,
Func3<? super T1,? super T2,? super T3,? extends R> zipFunction)
/// etcWhen zipping more than two sequences, the operator will wait until all of the sources have emitted the next value before it emits the next zipped value. In the next example, we add another source with its own frequency again.
Observable.zip(
Observable.interval(100, TimeUnit.MILLISECONDS),
Observable.interval(150, TimeUnit.MILLISECONDS),
Observable.interval(050, TimeUnit.MILLISECONDS),
(i1,i2,i3) -> i1 + " - " + i2 + " - " + i3)
.take(6)
.subscribe(System.out::println);0 - 0 - 0
1 - 1 - 1
2 - 2 - 2
3 - 3 - 3
4 - 4 - 4
5 - 5 - 5
The zipped sequence terminates when any of the source sequences terminates successfully. Further values from the other sequences will be ignored. We can see that in the next example, where we zip sequences of different sizes and count the elements in the zipped sequence.
Observable.zip(
Observable.range(0, 5),
Observable.range(0, 3),
Observable.range(0, 8),
(i1,i2,i3) -> i1 + " - " + i2 + " - " + i3)
.count()
.subscribe(System.out::println);3
The zipped sequence contains as many elements as the shortest source sequence.
There is also the zipWith operator, which is an alternative style of zipping 2 sequences. zipWith allows you to zip in a chain, but it can be inconvenient for zipping more that two sequences.
Observable.interval(100, TimeUnit.MILLISECONDS)
.zipWith(
Observable.interval(150, TimeUnit.MILLISECONDS),
(i1,i2) -> i1 + " - " + i2)
.take(6)
.subscribe(System.out::println);0 - 0
1 - 1
2 - 2
3 - 3
4 - 4
5 - 5
The zipWith also has an overload that allows you to zip your observable sequence with an iterable.
Observable.range(0, 5)
.zipWith(
Arrays.asList(0,2,4,6,8),
(i1,i2) -> i1 + " - " + i2)
.subscribe(System.out::println);0 - 0
1 - 2
2 - 4
3 - 6
4 - 8
Where zip uses indices, combineLatest will use time. Every time one of the observables being combined emits a value, that value is combined with the latest value by the other observable. Once again, a function is required to combine the values.
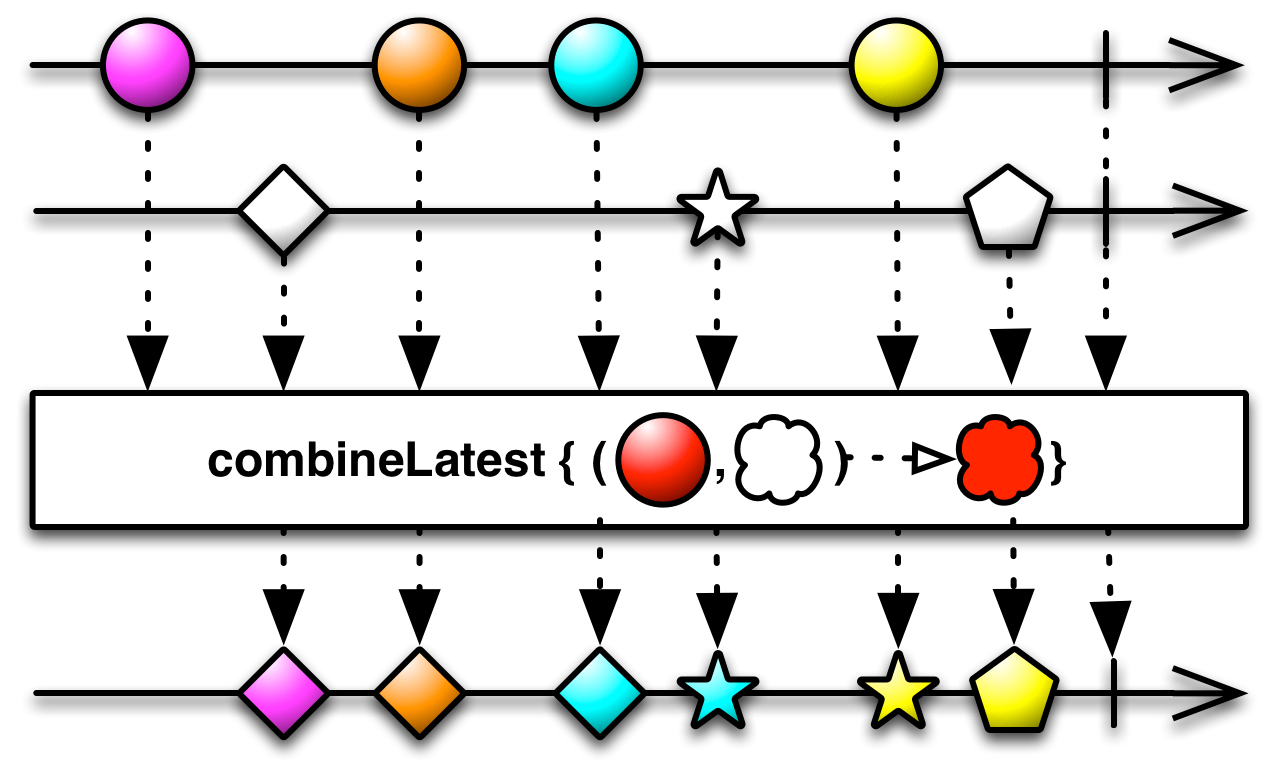
Observable.combineLatest(
Observable.interval(100, TimeUnit.MILLISECONDS)
.doOnNext(i -> System.out.println("Left emits")),
Observable.interval(150, TimeUnit.MILLISECONDS)
.doOnNext(i -> System.out.println("Right emits")),
(i1,i2) -> i1 + " - " + i2
)
.take(6)
.subscribe(System.out::println);Left emits
Right emits
0 - 0
Left emits
1 - 0
Left emits
2 - 0
Right emits
2 - 1
Left emits
3 - 1
Right emits
3 - 2
As we can see, combineLatest first it waits for every sequence to have a value. After that, every value emitted by either observable results in a combined value being emitted.
Just like every combinator we've seen in this chapter, there are overloads that allow to combine more than two sequences.
I like to think of combineLatest as one event occuring in the context of another. combineLatest is very useful when consuming input from GUIs, where multiple stateful GUI controls affect the same output. Imagine a text input field, a paragraph that echoes the text and a checkbox that signals to capitalise it or not. Everytime the text field or the checkbox changes, combineLatest will combine the text with the decision to capitalise it or not. The end result is ready to be written to the output.
One of the key features in Rx is that you don't know when items will be emitted. Some observables will emit everything immediately and synchronously(e.g. range), some emit on regular intervals, and some are hard or even impossible to predict. For example, mouse events and UDP packets simply arrive when they arrive. We need tools to decide what to do with those events, not only based on what they are, but also based on when they arrived and at what frequency.
buffer allows you to collect values and get them in bulks, rather than one at a time. The are several different ways of buffering values.
First we will examine variants of buffer where every value is buffered exactly once, with no losses and no duplicates.
The simplest overload groups a fixed number of values together and emits the group when it's ready.
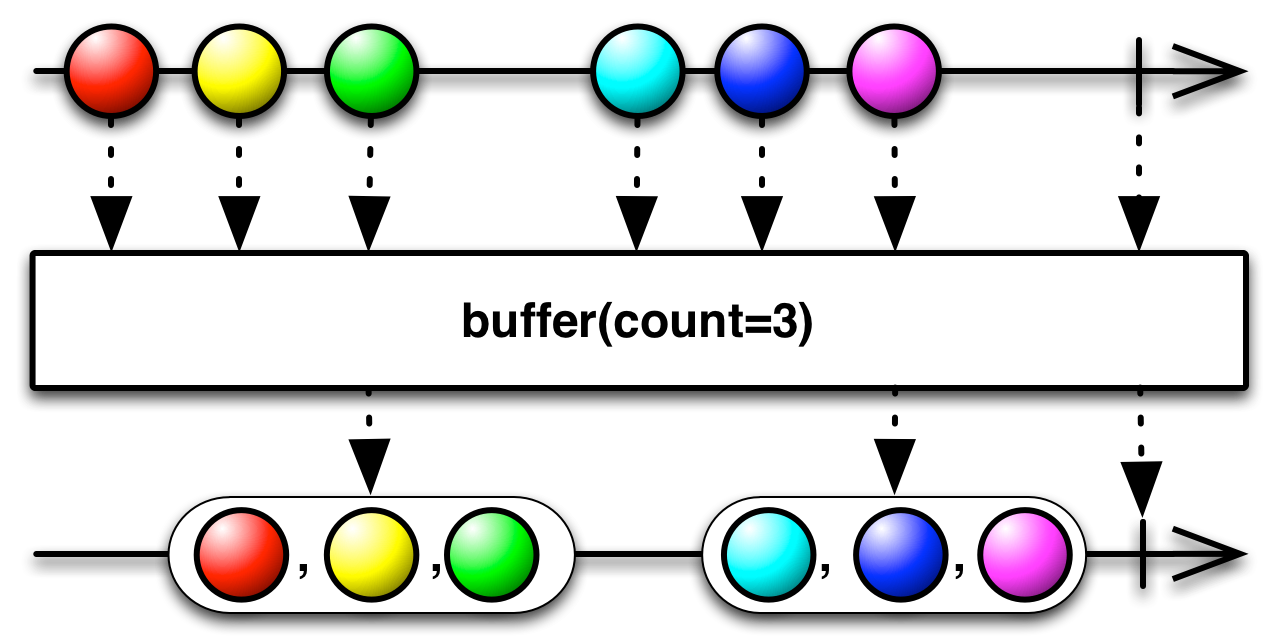
Observable.range(0, 10)
.buffer(4)
.subscribe(System.out::println);[0, 1, 2, 3]
[4, 5, 6, 7]
[8, 9]
The next overload allows you to buffer based on time. Time is divided into windows of equal length. Values are collected for the each window and at the end of each window the buffer is emited.
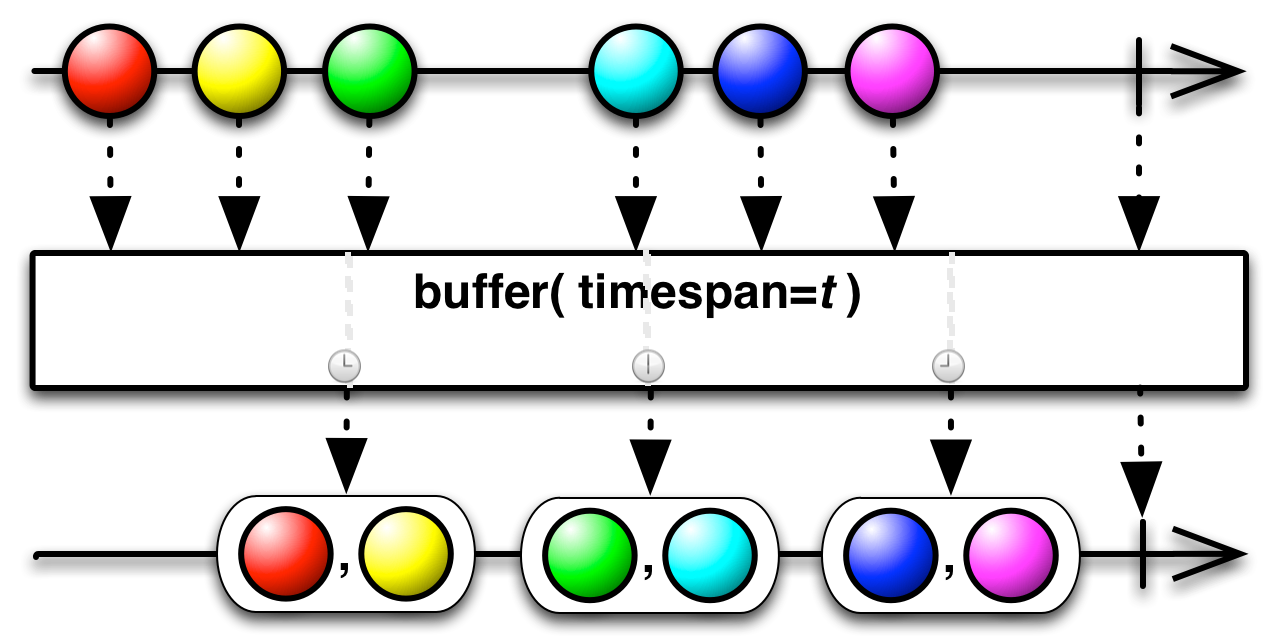
In the next example, we produce values every 100ms and buffer them in windows of 250ms.
Observable.interval(100, TimeUnit.MILLISECONDS).take(10)
.buffer(250, TimeUnit.MILLISECONDS)
.subscribe(System.out::println);[0, 1]
[2, 3]
[4, 5, 6]
[7, 8]
[9]
The size of a collection here depends on how many values were emitted in that timespan and not on a desired size. The collection can even be empty, if there where no events during the window.
You can use both a buffer size and a timespan to buffer values. The buffered values are emitted if either the buffer is full or if the time slot ends and a new one starts.
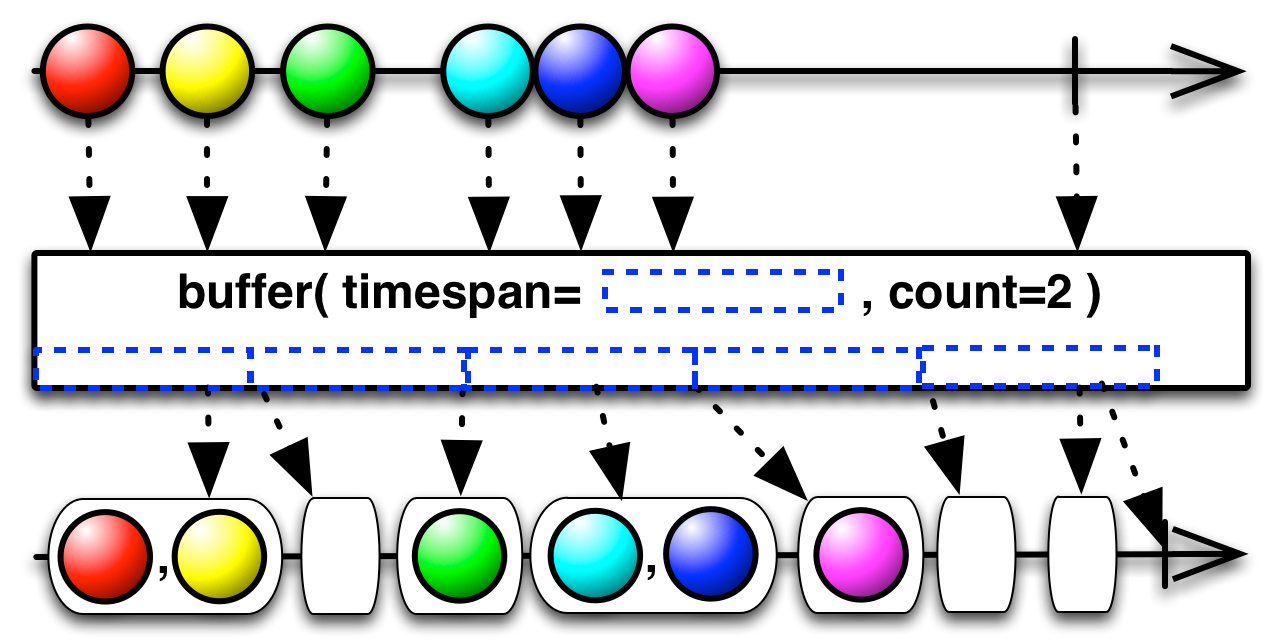
Observable.interval(100, TimeUnit.MILLISECONDS)
.take(10)
.buffer(250, TimeUnit.MILLISECONDS, 2)
.subscribe(System.out::println);[0, 1]
[]
[2, 3]
[]
[4, 5]
[6]
[7, 8]
[]
[9]
We see a lot of empty lists here. This is because the buffer is emitted both when it reaches size 2 and when a time window closes. As we can see from our previous example, only two values belong in those windows. Since the buffer was emptied when it reached size 2, it is empty when the window closes.
Instead of fixed points in time, you can also signal buffer with an observable to flush. Every time the signal emits onNext, the values in the buffer will be emitted will be emitted. Buffering with a signal can be very useful if you want to buffer values until the moment that you are ready for them.
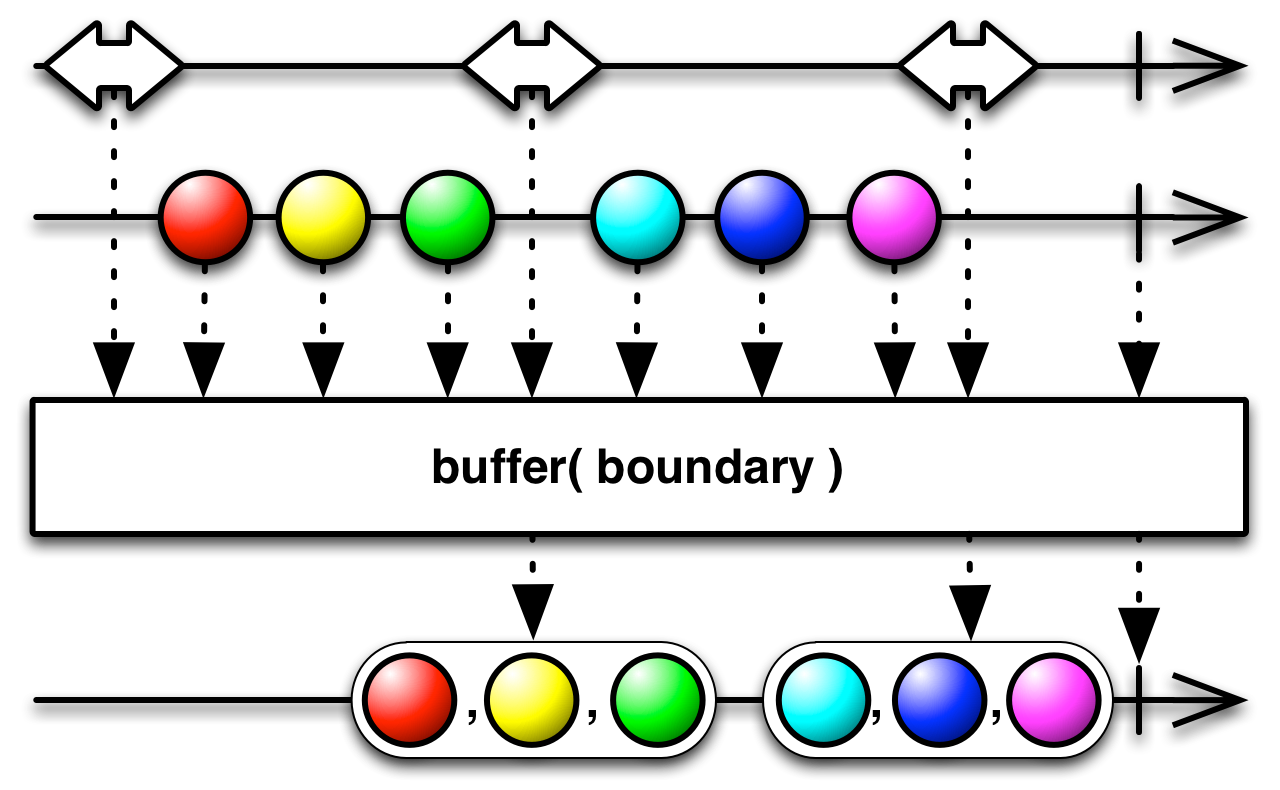
The following example does the same as .buffer(250, TimeUnit.MILLISECONDS)
Observable.interval(100, TimeUnit.MILLISECONDS).take(10)
.buffer(Observable.interval(250, TimeUnit.MILLISECONDS))
.subscribe(System.out::println);There is a variant for the way above, where you provide the signaling observable through a function: .buffer(() -> Observable.interval(250, TimeUnit.MILLISECONDS)). The difference here is that the function that creates the observable is executed when a subscription happens. You can use to start your signal when the subscription starts.
Every method for buffering that we've seen has an alternative that allows buffers to overloap or to leave out values.
When buffering based on the desired buffer size, you can also declare how far apart the beginings of each buffer are.
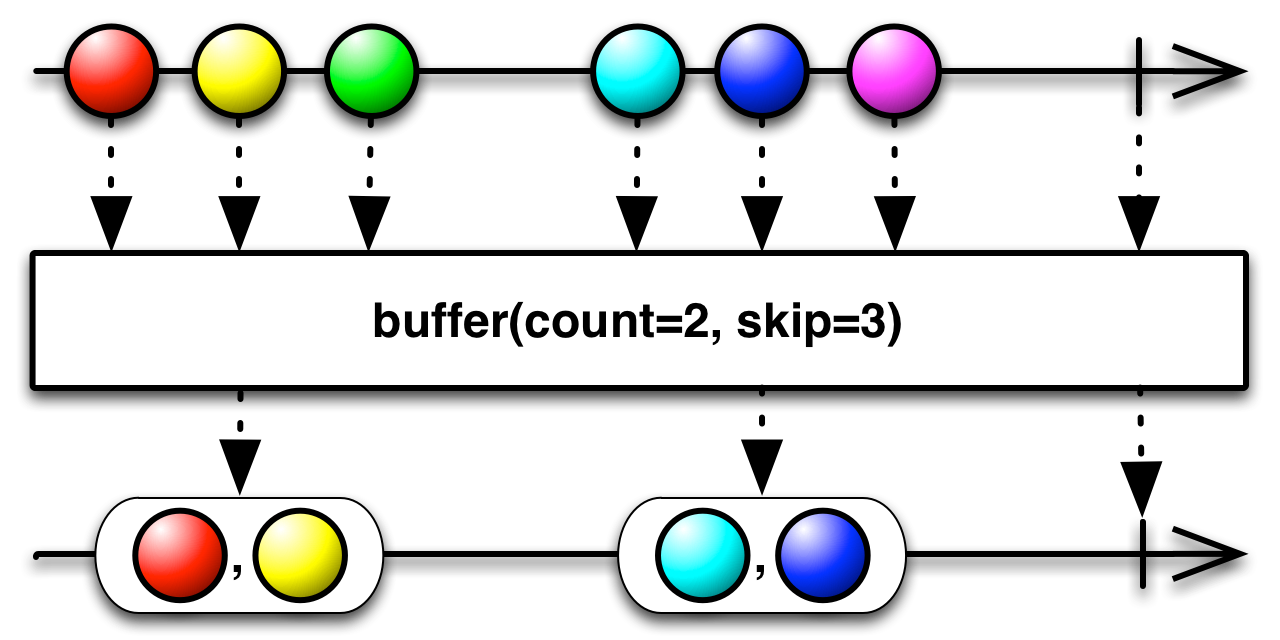
As we can see in the marble diagram, we start a new buffer every 3 values but the buffer is limited to 2 values. Therefore, every third element is left out. You can also start the new buffer before the previous buffer closes.
- When
count>skip, the buffers overlap - When
count<skip, elements are left out - The case of
count=skipis equivalent to the simpler case we saw in the previous subchapter.
Here's an example in code, where the buffers overlap
Observable.range(0,10)
.buffer(4, 3)
.subscribe(System.out::println);Output
[0, 1, 2, 3]
[3, 4, 5, 6]
[6, 7, 8, 9]
[9]
As we can see, a new buffer starts every 3 elements, and that buffer contains the next 4 elements.
We can do a very similar thing for the variant where buffering is based on a timespan. You decide how frequently to open new buffers and how long they should last.
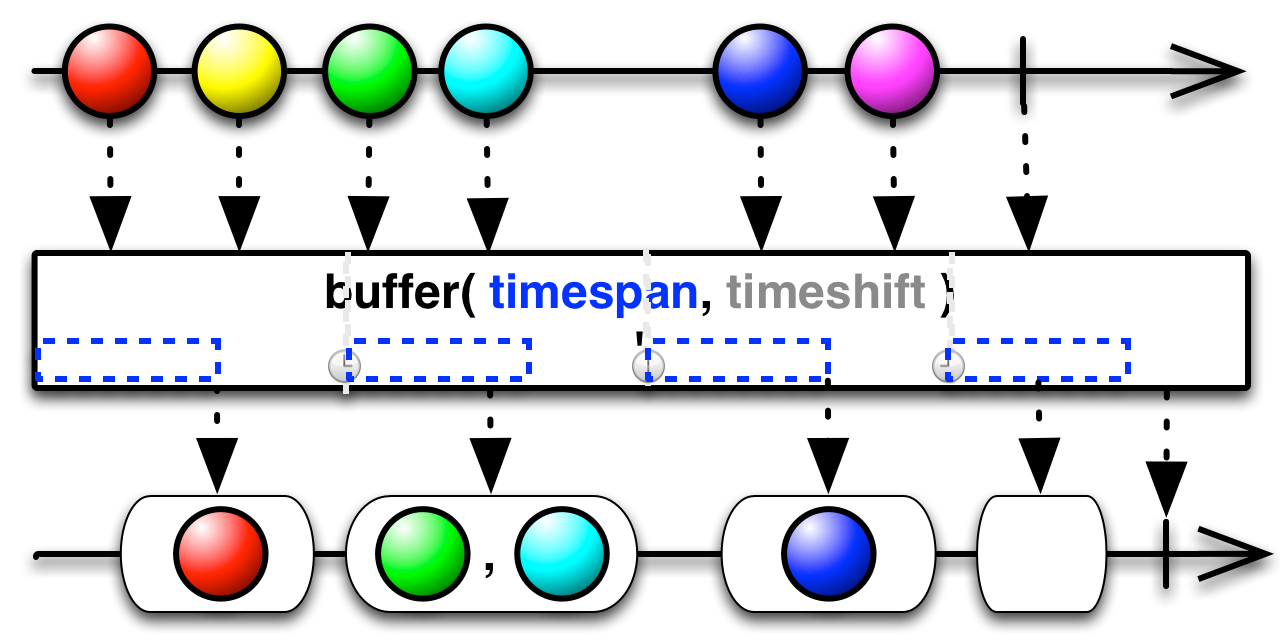
Once again, this allows you either to make your buffers overlap or leave out elements.
- When
timespan>timeshift, the buffers overlap - When
timespan<timeshift, elements are left out - The case of
timespan=timeshiftis equivalent to the simpler case we saw in the previous subchapter.
In the next example we will create a new buffer every 200ms and have it collect for 350ms. That means that buffers overlap by 150ms.
Observable.interval(100, TimeUnit.MILLISECONDS).take(10)
.buffer(350, 200, TimeUnit.MILLISECONDS)
.subscribe(System.out::println);[0, 1, 2]
[2, 3, 4]
[3, 4, 5, 6]
[5, 6, 7, 8]
[7, 8, 9]
[9]
The last and most powerful variant or buffer allows you to define the start and the end of buffers using signaling observables.
public final <TOpening,TClosing> Observable<java.util.List<T>> buffer(
Observable<? extends TOpening> bufferOpenings,
Func1<? super TOpening,? extends Observable<? extends TClosing>> bufferClosingSelector)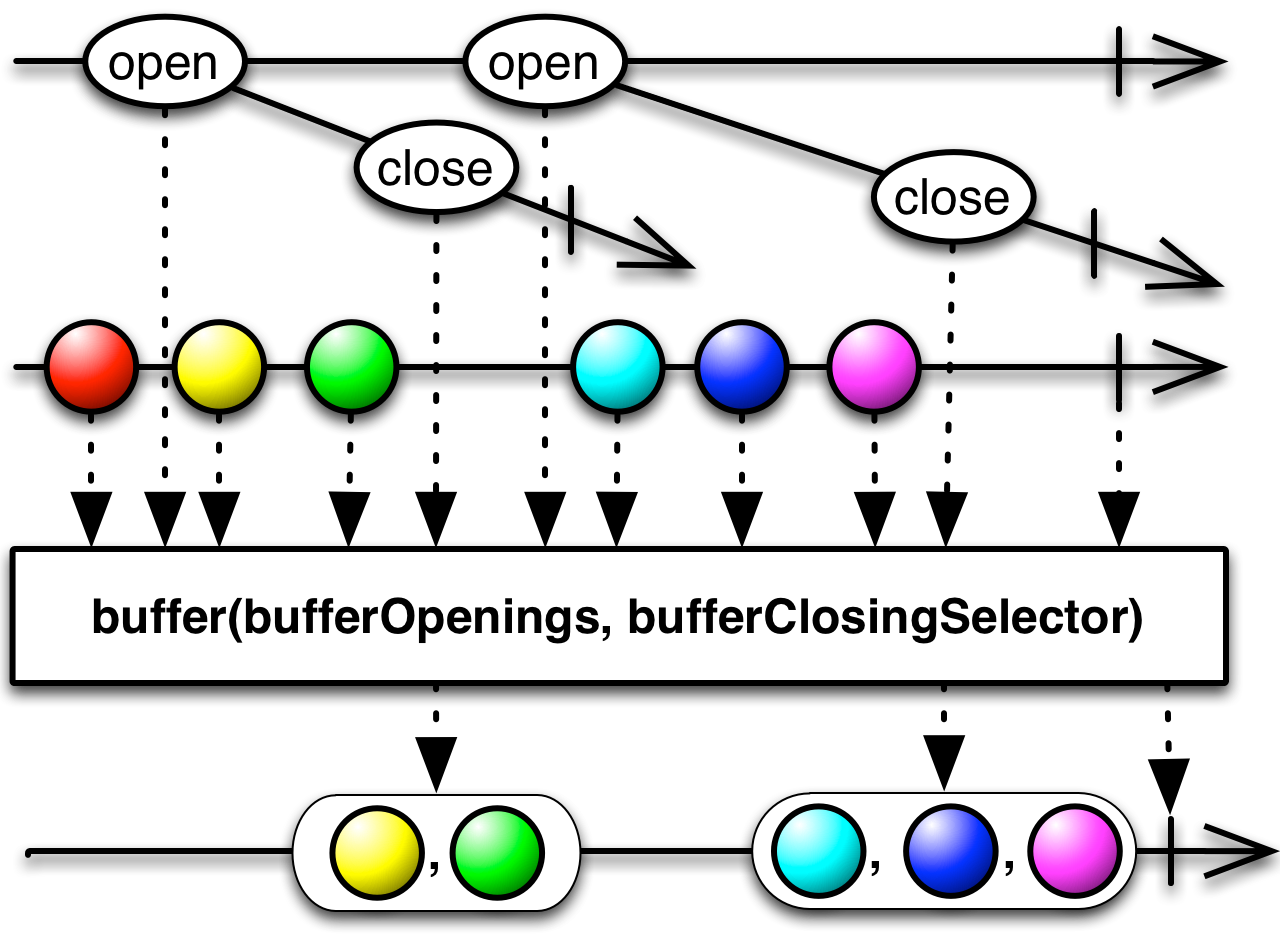
This function takes two arguments. The first argument, bufferOpenings, is an observable. Every time this observable emits a value, a new buffer begins. Along with opening a new buffer, the value which it emitted is passed to the bufferClosingSelector, which is a function. This function uses the value to create a new observable, which will signal the end of the corresponding buffer when it emits its first onNext event.
Let's see this in code:
Observable.interval(100, TimeUnit.MILLISECONDS).take(10)
.buffer(
Observable.interval(250, TimeUnit.MILLISECONDS),
i -> Observable.timer(200, TimeUnit.MILLISECONDS))
.subscribe(System.out::println);[2, 3]
[4, 5]
[7, 8]
[9]
We've created an Observable.interval, which signals the opening of a new buffer every 250ms. Because observables created with interval do not immediately emit a value, and first buffer actually starts at 250ms and the values before were lost. For the closing of a buffer, we provided a lambda function that took every value emitted by bufferOpenings. The values generated by interval are the natural progression 0,1,2,3... but we don't actually use the value, because such an example would be too complicated. Instead, we just created an observable that waits 200ms and then emits a single value. That means that each buffer last exactly 200ms, similarily to buffering by time.
We have already seen the takeLast operator, which returns the last N number of items. Internally, takeLast needs to buffer items and re-emits them when the source sequence ends. The takeLastBuffer operator returns the last elements as one buffer.
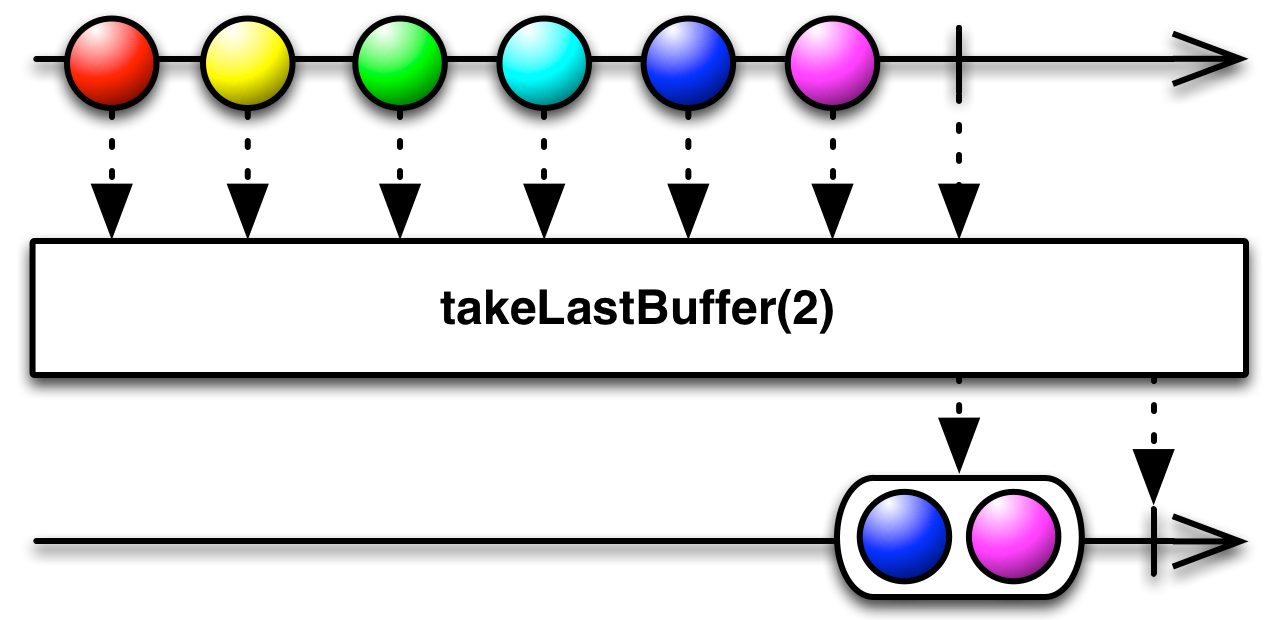
takeLastBuffer by count will emit the last N elements in a list.
Observable.range(0, 5)
.takeLastBuffer(2)
.subscribe(System.out::println);[3, 4]

takeLastBuffer by time will emit, as a buffer, the items that were received during the specified timespan, which is measure from the end of the source sequence.
Observable.interval(100, TimeUnit.MILLISECONDS)
.take(5)
.takeLastBuffer(200, TimeUnit.MILLISECONDS)
.subscribe(System.out::println);[2, 3, 4]
The buffer emitted by this overload of takeLastBuffer will contain items that were emitted over the specified timespan before the end. If this window contains more than the specified number of items, the buffer will contain the last N items.
Observable.interval(100, TimeUnit.MILLISECONDS)
.take(5)
.takeLastBuffer(2, 200, TimeUnit.MILLISECONDS)
.subscribe(System.out::println);[3, 4]
As we saw in the previous example, the last 200ms include three values. With .takeLastBuffer(2, 200, TimeUnit.MILLISECONDS) we specified that we want values from the last 200ms, but no more than 2 values. For that reason, we only get the last two values.
delay, as the name suggests, will postpone the emission of values for a specified amount of time. The are two ways to do that. One is by storing values until you are ready to emit them. The other is to delay the subscription to observable.
The simplest overload of delay will delay every item by the same amount of time. You can think of it as delaying the beginning of the sequence, while maintaining the time intervals between successive elements.
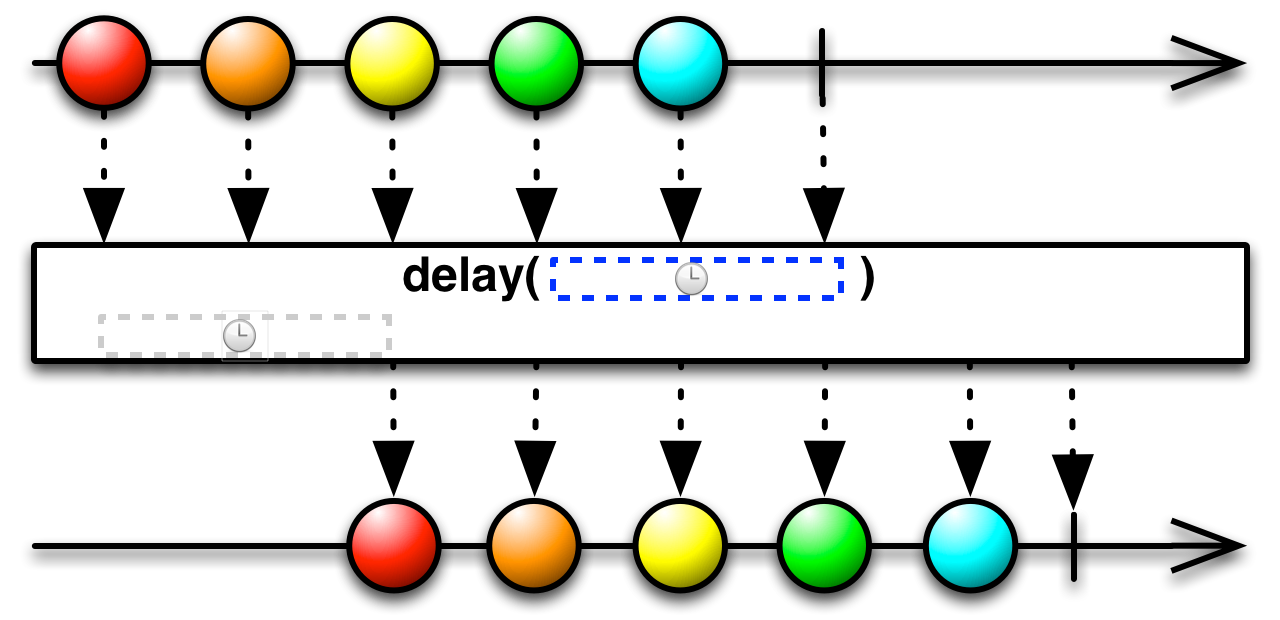
Here's an example in code
Observable.interval(100, TimeUnit.MILLISECONDS).take(5)
.delay(1, TimeUnit.SECONDS)
.timeInterval()
.subscribe(System.out::println);TimeInterval [intervalInMilliseconds=1109, value=0]
TimeInterval [intervalInMilliseconds=94, value=1]
TimeInterval [intervalInMilliseconds=100, value=2]
TimeInterval [intervalInMilliseconds=100, value=3]
TimeInterval [intervalInMilliseconds=101, value=4]
We created 5 values spaced 100ms apart and then we delayed the sequence by 1s. We can see that the first value takes ~(1000 + 100)ms and the next values take 100ms each.
You can also delay each value individually.
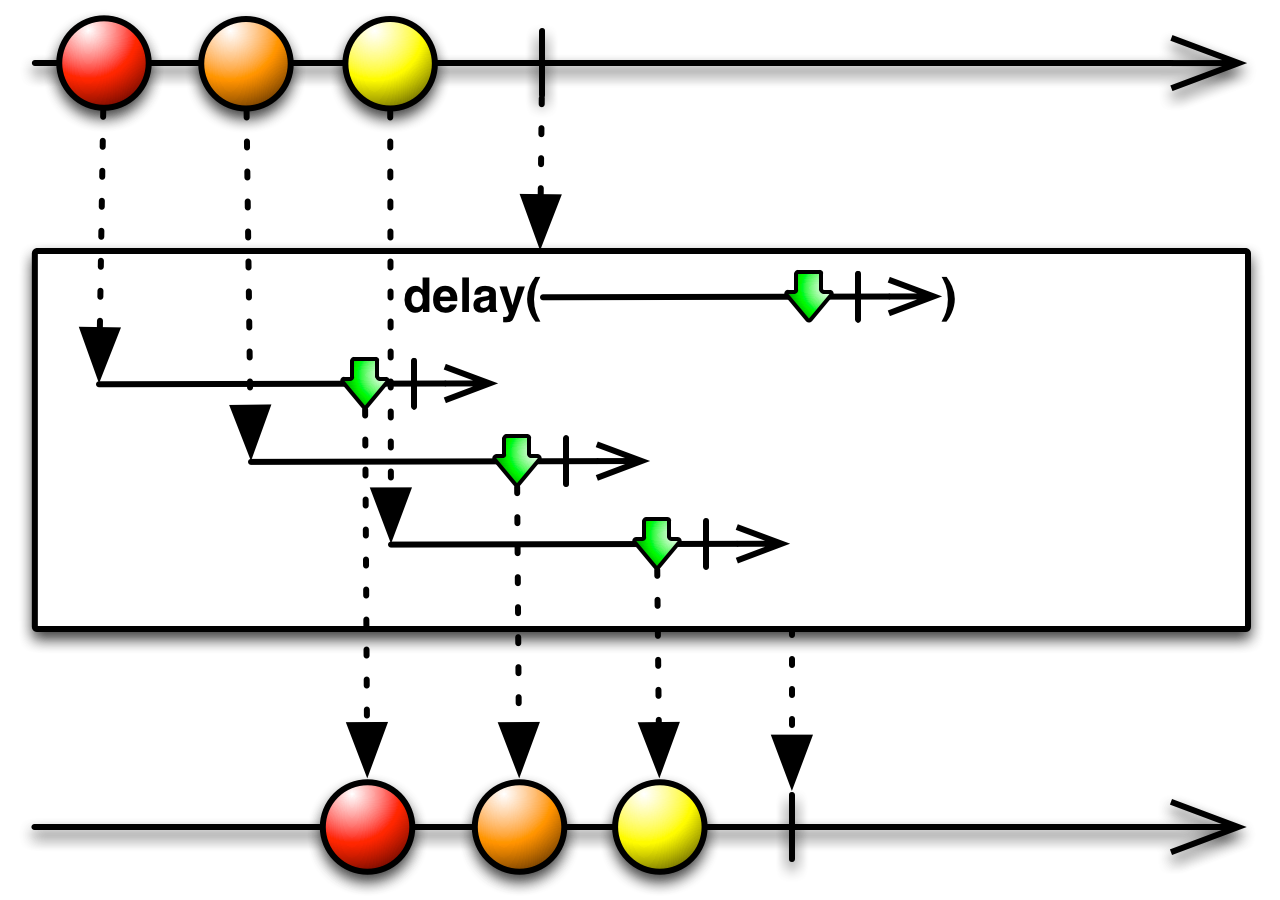
This overload takes a function which will create an observable for each item. When that observable emits onNext, the corresponding item is emitted in the delayed sequence. Here's some code:
Observable.interval(100, TimeUnit.MILLISECONDS).take(5)
.delay(i -> Observable.timer(i * 100, TimeUnit.MILLISECONDS))
.timeInterval()
.subscribe(System.out::println);TimeInterval [intervalInMilliseconds=152, value=0]
TimeInterval [intervalInMilliseconds=173, value=1]
TimeInterval [intervalInMilliseconds=199, value=2]
TimeInterval [intervalInMilliseconds=201, value=3]
TimeInterval [intervalInMilliseconds=199, value=4]
The initial sequence is spaced 100ms apart, while the resulting is 200ms. If you remember, interval emits the numbers i = 1,2,3,etc. We delay each item i by i*100, so the first item is delayed by 100ms, then second by 200ms, the third by 300ms. The difference between the successive delays is 100ms. Added to the initial 100ms interval, that results in 200ms interval between items.
Rather than storing values and emitting them later, you can delay the subscription altogether. This will have a different effect depending on if the observable is hot or cold. This will be discussed more in the [Hot and cold observables](/Part 3 - Taming the sequence/6. Hot and Cold observables.md) chapter. For our examples so far, the observables are cold and subscription event is when the source observable is created (i.e. the begining of the sequence). What that means is that there is no difference in the sequences between delaying each item by the same amount and delaying the subscription. Since that is the case here, delaying the subscription is more efficient, since the operator doesn't need to buffer items internally.
Let's see code for the different overloads for delaying a subscription
Observable.interval(100, TimeUnit.MILLISECONDS).take(5)
.delaySubscription(1000, TimeUnit.MILLISECONDS)
.timeInterval()
.subscribe(System.out::println);TimeInterval [intervalInMilliseconds=1114, value=0]
TimeInterval [intervalInMilliseconds=92, value=1]
TimeInterval [intervalInMilliseconds=101, value=2]
TimeInterval [intervalInMilliseconds=100, value=3]
TimeInterval [intervalInMilliseconds=99, value=4]
What we see here is that the subscription of the interval observable (i.e. its creation) was delayed by 1000ms. After that, the sequence goes as defined.
You can also delay the subscription based on a signaling observable through the following overload:
public final <U> Observable<T> delaySubscription(Func0<? extends Observable<U>> subscriptionDelay)The argument is a function that will create a new observable for each subscription. The subscription is delayed until the corresponding observable emits a value. The following example is equivalent to the one we've just seen.
Observable.interval(100, TimeUnit.MILLISECONDS).take(5)
.delaySubscription(() -> Observable.timer(1000, TimeUnit.MILLISECONDS))
.timeInterval()
.subscribe(System.out::println);The last method in this category allows you to delay both the subscription and each item individually.
public final <U,V> Observable<T> delay(
Func0<? extends Observable<U>> subscriptionDelay,
Func1<? super T,? extends Observable<V>> itemDelay)
This combines two delay variants we've already seen into one. The first argument is a function that creates an observable that will signal when to perform the subscription. The second argument takes every item and decides how long it should be delayed.
sample allows you to thin-out a sequence by dividing it into time windows and taking only one value out of each window. When each window ends, the last value within that window (if any) is emitted.
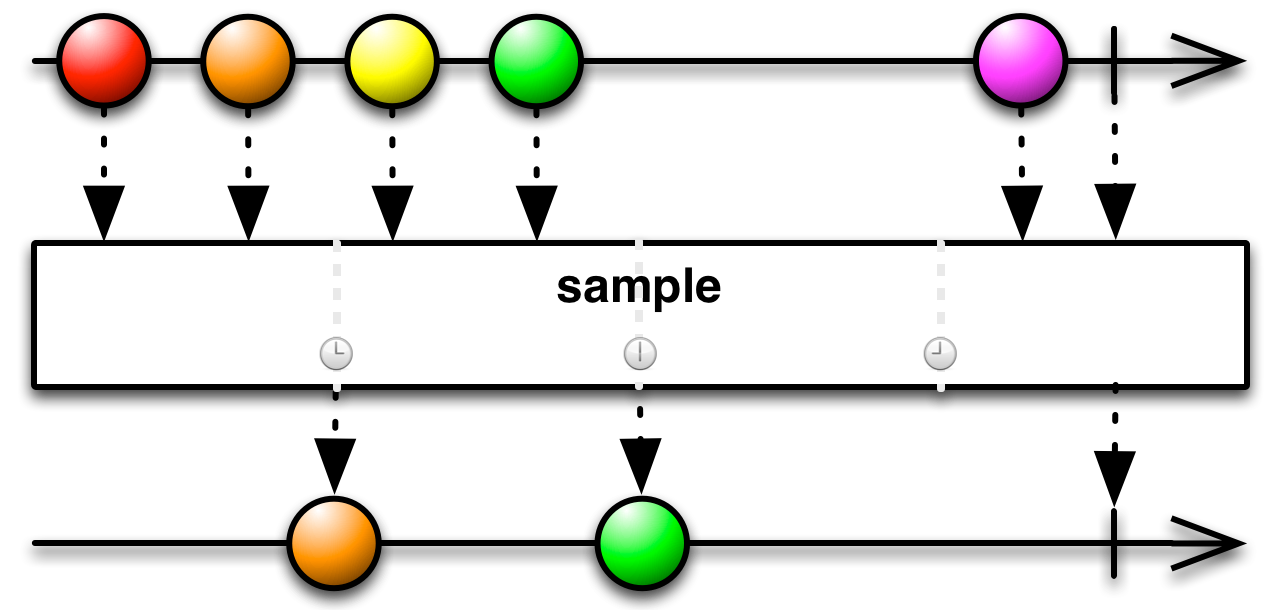
Observable.interval(150, TimeUnit.MILLISECONDS)
.sample(1, TimeUnit.SECONDS)
.subscribe(System.out::println);5
12
18
...
The division of time doesn't have to be uniform. You can specify the end of each part with a signaling observable.
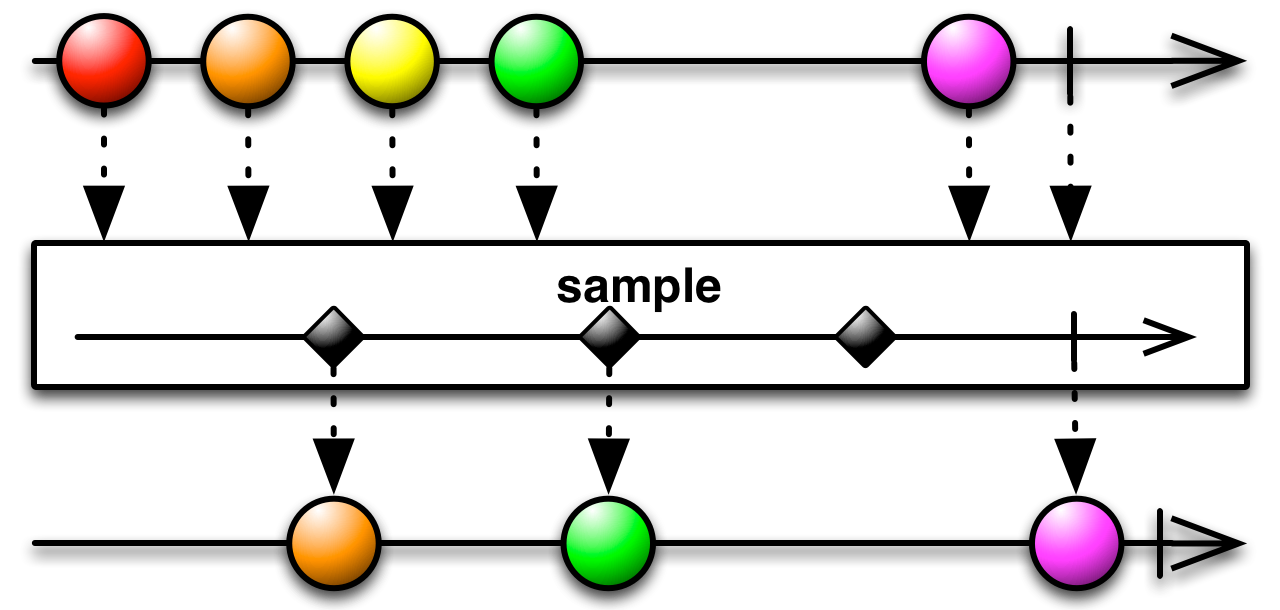
The following code does the same thing as before
Observable.interval(150, TimeUnit.MILLISECONDS)
.sample(Observable.interval(1, TimeUnit.SECONDS))
.subscribe(System.out::println);Throttling is also intended for thining out a sequence. When the producer emits more values than we want and we don't need every sequential value, we can thin out the sequence by throttling it.
The throttleFirst operators filter out values relative to the values that were already accepted. After a value has been accepted, values will be rejected for the duration of the window. Once The window expires, the next value will be accepted and a new window starts.

Observable.interval(150, TimeUnit.MILLISECONDS)
.throttleFirst(1, TimeUnit.SECONDS)
.subscribe(System.out::println);0
7
14
...
Here, interval emits every 150ms. The values seen as output were emitted at (i+1)*150ms, relative to the start of the sequence. The first item is emitted at 150ms and is accepted by default. Now items are rejected for the next 1000ms. The first item after that comes at 1200ms. Again, items are rejected for the next 1000ms, so the next item comes at 2250ms.
The throttleLast operator divides time at regular intervals, rather than relative to the last item. it emits the last value in each window, rather than the first after it.

Observable.interval(150, TimeUnit.MILLISECONDS)
.throttleLast(1, TimeUnit.SECONDS)
.subscribe(System.out::println);5
12
18
...
Here, a window starts with the creation of the sequence at 0ms. That window expires at 1000ms and the last value in that window was at 900ms. The next window last 1000ms until 2000ms. The last item in that window is at 1950. In the next window, the item is at 2850ms.
In this operator, a time window starts every time a value is received. Once the window expires, the value is emitted. If, however, another value is received before the window expires, the previous value is rejected and the window restarts for the next value.
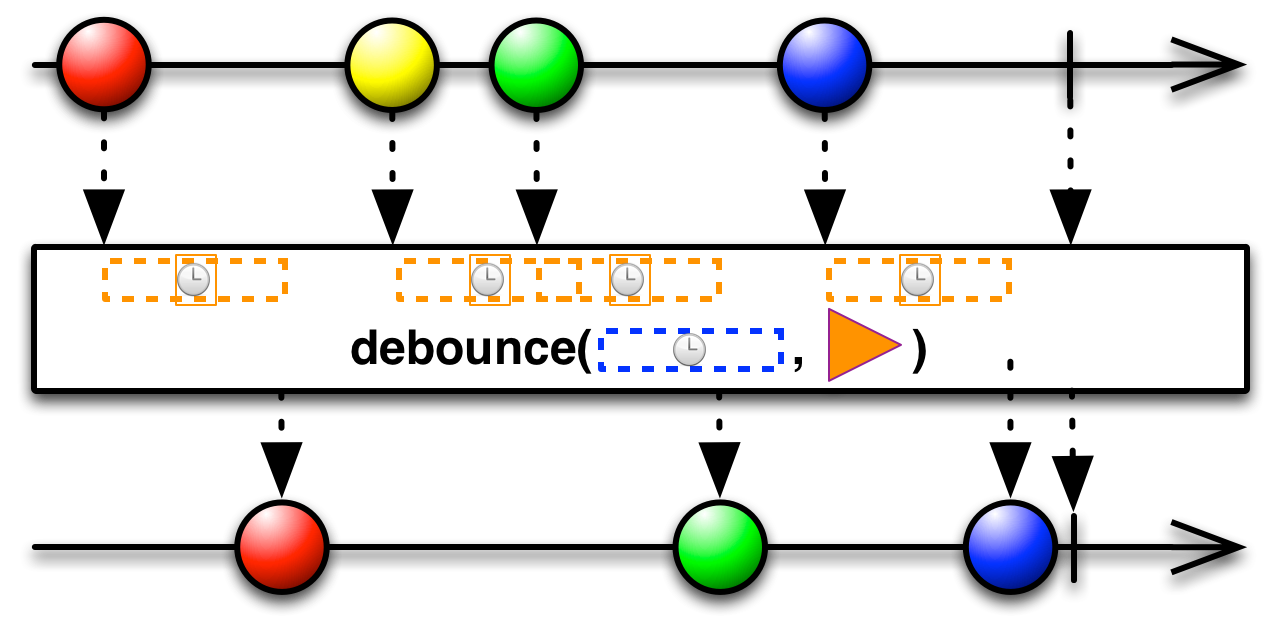
Demonstrating this is a bit more complicated, since an interval observable will either have all of its values accepted or only its last value accepted (which is never if the observable is infinite). For that reason we will construct a more complicated observable.
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(3),
Observable.interval(500, TimeUnit.MILLISECONDS).take(3),
Observable.interval(100, TimeUnit.MILLISECONDS).take(3)
)
.scan(0, (acc, v) -> acc+1)
.timeInterval()
.subscribe(System.out::println);Output
TimeInterval [intervalInMilliseconds=110, value=0]
TimeInterval [intervalInMilliseconds=1, value=1]
TimeInterval [intervalInMilliseconds=98, value=2]
TimeInterval [intervalInMilliseconds=101, value=3]
TimeInterval [intervalInMilliseconds=502, value=4]
TimeInterval [intervalInMilliseconds=500, value=5]
TimeInterval [intervalInMilliseconds=499, value=6]
TimeInterval [intervalInMilliseconds=102, value=7]
TimeInterval [intervalInMilliseconds=99, value=8]
TimeInterval [intervalInMilliseconds=101, value=9]
As we can see here, our observable will emit 4 values in quick succession, then 3 values in greater intervals and finally 3 values in quick succession. The scan only serves to turn the values into the natural sequence, rather than 3 repetitions of 1,2,3. The reason the first two emissions are simultaneous is that that scan emits the initial value and the first value together.
Now that we understand our source observable, let's debounce it:
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(3),
Observable.interval(500, TimeUnit.MILLISECONDS).take(3),
Observable.interval(100, TimeUnit.MILLISECONDS).take(3)
)
.scan(0, (acc, v) -> acc+1)
.debounce(150, TimeUnit.MILLISECONDS)
.subscribe(System.out::println);3
4
5
9
We debounced with a window of 150ms. The bursts of emissions in our observable were faster than that (100ms), so only the last value in each burst passed through. During the slower part of our observable, all the values were accepted, because the 150ms window expired before the next value arrived.
There is a throttleWithTimeout operator which has the same behaviour as the debounce operator that we just saw. One is practically an alias of the other, even though neither is officially declared as such in the documentation.
You can also debounce based on a per item basis. In this case, you provide a function that calculates for each item how long the window should be after it. You signal that the window is using a new observable for each item . When the observable terminates, the window expires.
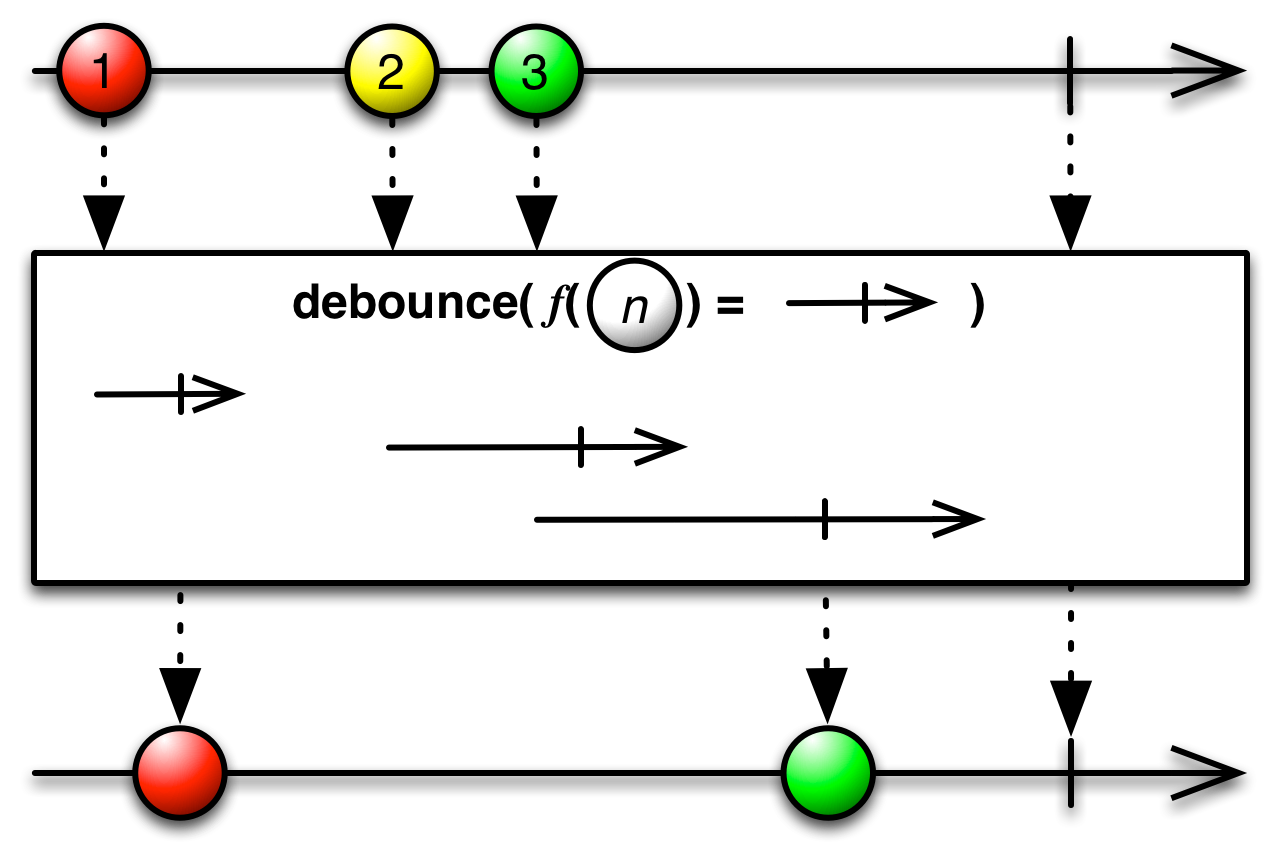
In the next example, the window size for each value i is i*50ms.
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(3),
Observable.interval(500, TimeUnit.MILLISECONDS).take(3),
Observable.interval(100, TimeUnit.MILLISECONDS).take(3)
)
.scan(0, (acc, v) -> acc+1)
.debounce(i -> Observable.timer(i * 50, TimeUnit.MILLISECONDS))
.subscribe(System.out::println);1
3
4
5
9
Let's map each item to the length of its window and the time that the next item actually arrives
| Item | Calculated Window | Time until next value | Window < next value |
|---|---|---|---|
| 0 | 0 | 1 | |
| 1 | 50 | 98 | Yes |
| 2 | 100 | 101 | (timed operations in Java are not 100% accurate) |
| 3 | 150 | 502 | Yes |
| 4 | 200 | 500 | Yes |
| 5 | 250 | 499 | Yes |
| 6 | 300 | 102 | |
| 7 | 350 | 99 | |
| 8 | 400 | 101 | |
| 9 | 450 | Yes |
We can now see why the values turned out to be so.
This operator is useful against observables that undergo periods of uncertainty, where the value changes frequently from one non-definitive state to another. For example, imagine that you are monitoring the contents of a text field and you want to offer suggestions based on what the user is writting. You could recompute your suggestions on every keystroke, but that would be too noisy and too costly. If, instead, you debounce the changes to the text field, you will offer suggestions only when the user has paused or finished typing.
timeout is used to detect observables that have remained inactive for a given amount of time. If a specified amount of time passes without the source emitting any items, timeout makes the observable fail with a TimeoutException.
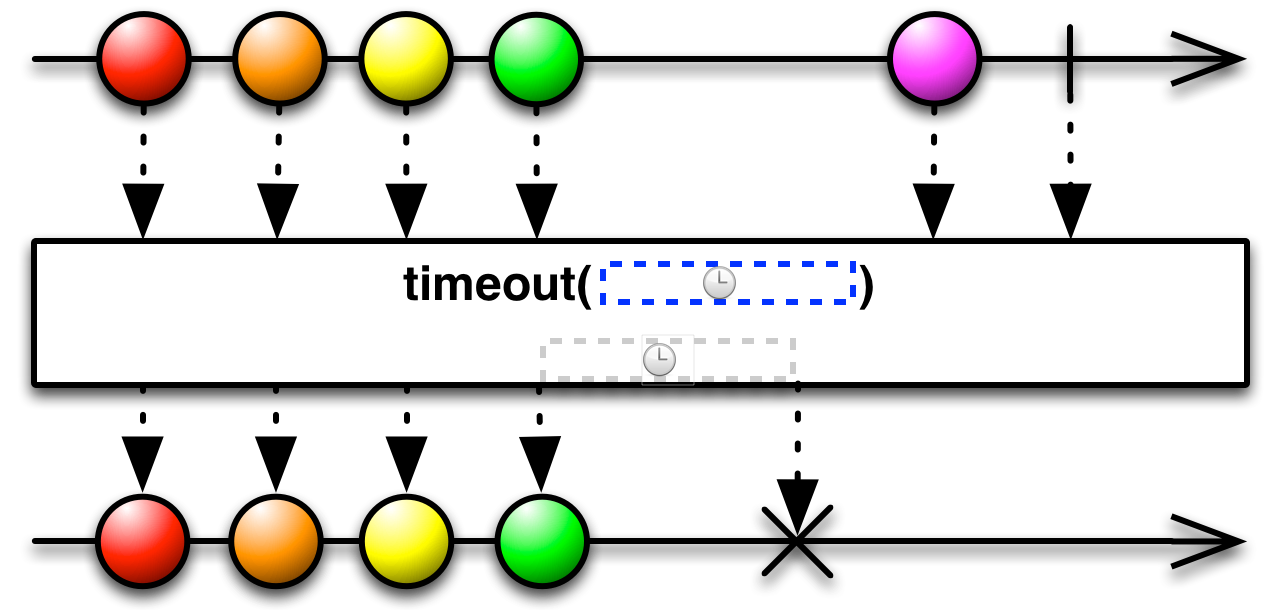
We will reuse our composite observable from the examples of debounce to demonstrate timeout.
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(3),
Observable.interval(500, TimeUnit.MILLISECONDS).take(3),
Observable.interval(100, TimeUnit.MILLISECONDS).take(3)
)
.scan(0, (acc, v) -> acc+1)
.timeout(200, TimeUnit.MILLISECONDS)
.subscribe(
System.out::println,
System.out::println);0
1
2
3
java.util.concurrent.TimeoutException
The output mirrors the source observable for as long as values come more frequently than 200ms. As soon as a value takes more than that to arrive, an error is pushed.
Instead of failing, you can provide a fallback observable. When a timeout occures, the resulting observable will switch to the fallback. The original observable will be ignored from then on, even if it resumes.
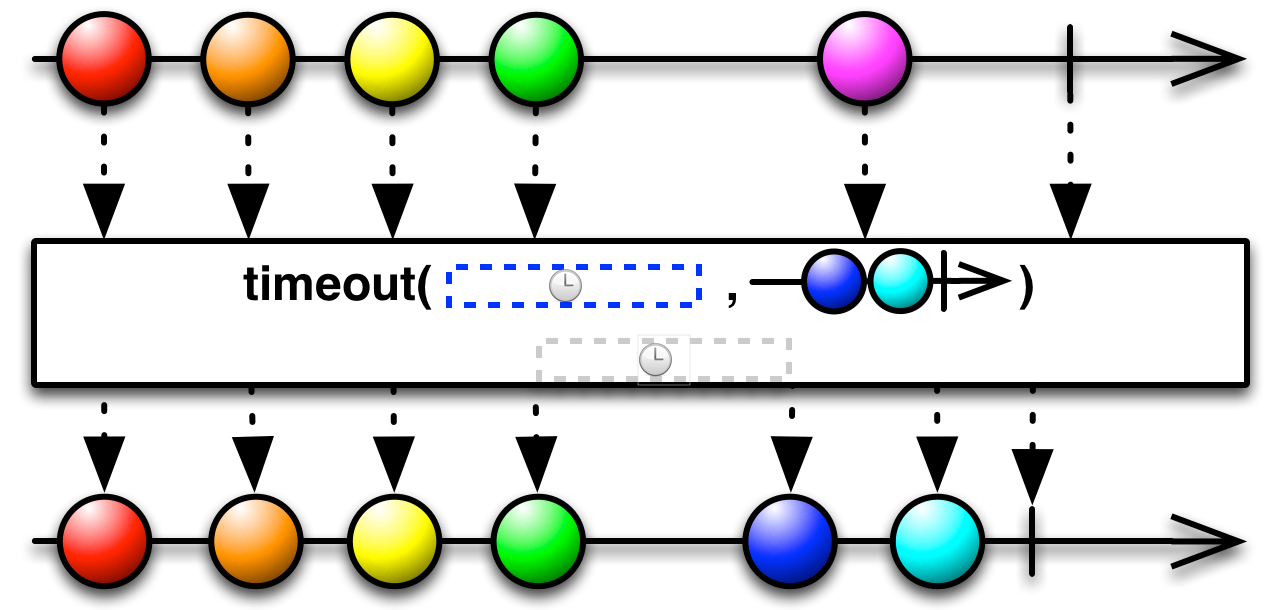
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(3),
Observable.interval(500, TimeUnit.MILLISECONDS).take(3),
Observable.interval(100, TimeUnit.MILLISECONDS).take(3)
)
.scan(0, (acc, v) -> acc+1)
.timeout(200, TimeUnit.MILLISECONDS, Observable.just(-1))
.subscribe(
System.out::println,
System.out::println);0
1
2
3
-1
You can also specify the timeout window per item. In that case, you provide a function that creates an observable for each value. When the observable terminates, that is the signal for the timeout. If no values had been emitted until that, that triggers the timeout.
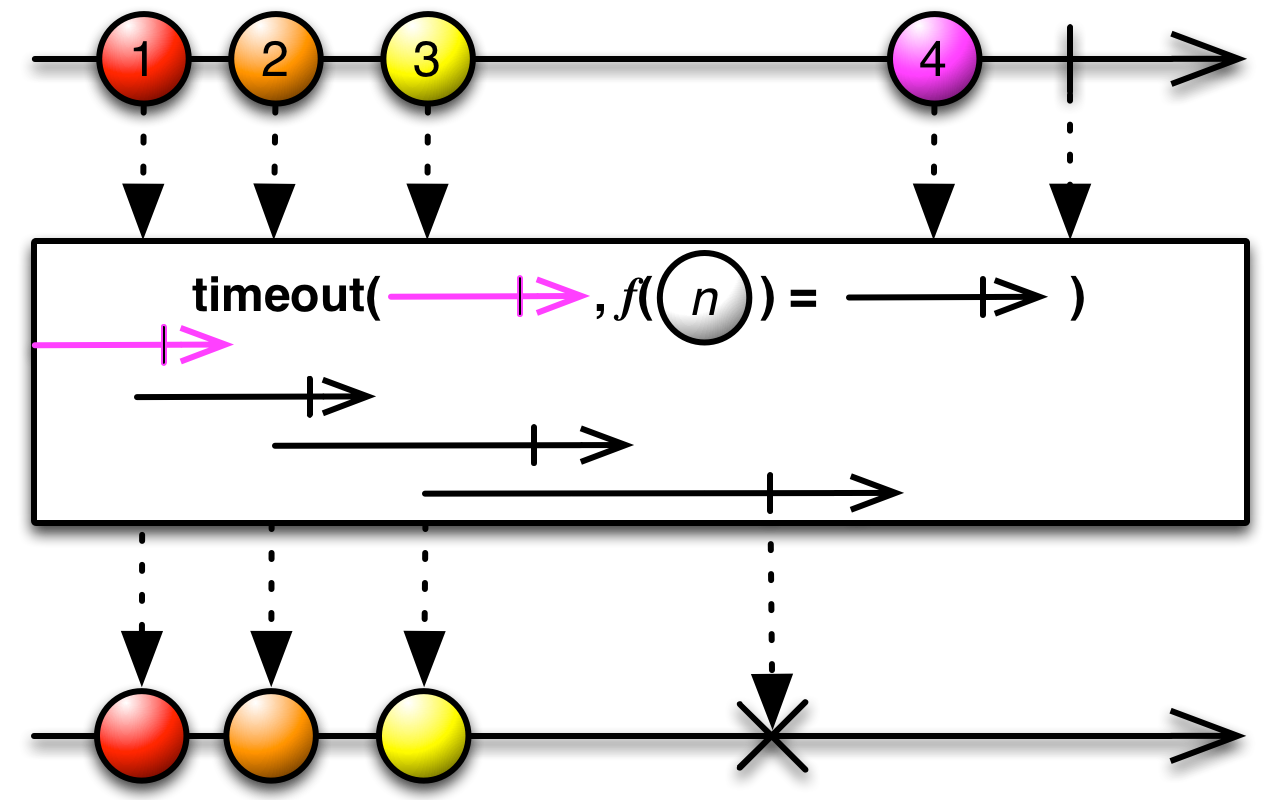
Here is the previous example, implemented using this overload.
Observable.concat(
Observable.interval(100, TimeUnit.MILLISECONDS).take(3),
Observable.interval(500, TimeUnit.MILLISECONDS).take(3),
Observable.interval(100, TimeUnit.MILLISECONDS).take(3)
)
.scan(0, (acc, v) -> acc+1)
.timeout(i -> Observable.timer(200, TimeUnit.MILLISECONDS))
.subscribe(
System.out::println,
System.out::println);Again, you can provide a fallback observable with
.timeout(i -> Observable.timer(200, TimeUnit.MILLISECONDS), Observable.just(-1))The output is the same as the previous two examples
Observable sequences come in two flavours, called "hot" and "cold", that have important differences. In this chapter, we will explain what each type is and what that means for you as an Rx developer.
Cold observables are observables that run their sequence when and if they are subscribed to. They present the sequence from the start to each subscriber. An example of a cold observable would be Observable.interval. Regardless of when it is created and when it is subscribed to, it will generate the same sequence for every subscriber.
Observable<Long> cold = Observable.interval(200, TimeUnit.MILLISECONDS);
cold.subscribe(i -> System.out.println("First: " + i));
Thread.sleep(500);
cold.subscribe(i -> System.out.println("Second: " + i));First: 0
First: 1
First: 2
Second: 0
First: 3
Second: 1
First: 4
Second: 2
...
The two subscribers don't receive the same value at the same time, even though they are both subscribed to the same observable. They do see the same sequence, except that each of them sees it as having begun when they subscribed.
The code samples that we've seen in this guide so far have been cold observables, because cold observables are easier to reason about. Every observable that is created with the Observable.create is a cold observable. That includes all the shorthands that we've seen, such as just, range, timer and from.
Cold observables don't necessarily present the same sequence to each subscriber. If, for example, an observable connects to a database and emits the results of a query, the actual value will depend on the state of the database at the time of subscription. It is the fact that a subscriber will receive the whole query from the start that makes this observable cold.
Hot observables emit values independent of individual subscriptions. They have their own timeline and events occur whether someone is listening or not. An example of this is mouse events. A mouse is generating events regardless of whether there is a subscription listening for them. When a subscription is made, the observer receives current events as they happen. You don't receive and you don't want to receive a recap of everything that the mouse has done since booting the system. When you unsubscribe, it doesn't stop your mouse from generating events either. You're just not receiving them. If you resubscribe, you will again see current events with no recap of what you've missed.
There are ways to transform cold observables into hot and vice versa. Cold observables become hot with the publish() operator.
public final ConnectableObservable<T> publish()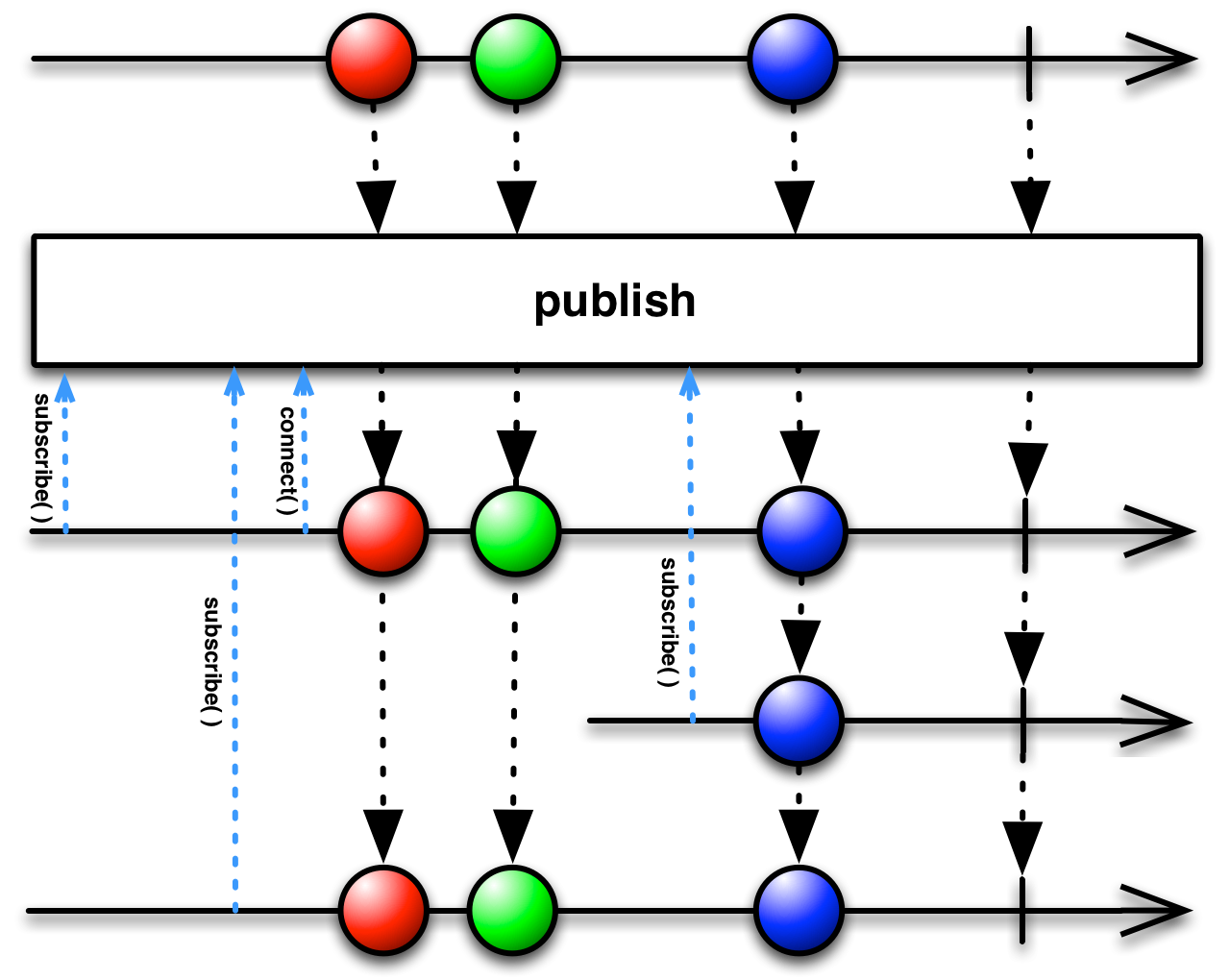
publish returns a ConnectableObservable<T>, which is an extension of Observable<T> with three additional methods
public final Subscription connect()
public abstract void connect(Action1<? super Subscription> connection)
public Observable<T> refCount()There is a variant that takes a selector that transforms a sequence before publishing it.
public final <R> Observable<R> publish(Func1<? super Observable<T>,? extends Observable<R>> selector)The selector can do anything that we've learned to do on observables. The usefulness of this is that a single subscription is made for the selector, which can be reused as much as needed. Without this overload, reusing the observable could lead to multiple subscriptions. There is no way to guarantee that the subscriptions would happen at the same exact time and therefore see the exact same sequence.
This method returns an Observable<T> instead of a ConnectableObservable<T>, so the connection functionality we are about to discuss does not apply there.
The ConnectableObservable will initially emit nothing. When calling connect, it will create a new subscription to its source observable (the one we called publish on). It will begin receiving events and pushing them to its subscribers. All of the subscribers will receive the same events at the same time, as they are practically sharing the same subscription: the one that connect created.
ConnectableObservable<Long> cold = Observable.interval(200, TimeUnit.MILLISECONDS).publish();
cold.connect();
cold.subscribe(i -> System.out.println("First: " + i));
Thread.sleep(500);
cold.subscribe(i -> System.out.println("Second: " + i));First: 0
First: 1
First: 2
Second: 2
First: 3
Second: 3
First: 4
Second: 4
First: 5
Second: 5
As we saw in connect's signature, this method returns a Subscription, just like Observable.subscribe does. You can use that reference to terminate the ConnectableObservable's subscription. That will stop events from being propagated to observers but it will not unsubscribe them from the ConnectableObservable. If you call connect again, the ConnectableObservable will start a new subscription and the old observers will begin receiving values again.
ConnectableObservable<Long> connectable = Observable.interval(200, TimeUnit.MILLISECONDS).publish();
Subscription s = connectable.connect();
connectable.subscribe(i -> System.out.println(i));
Thread.sleep(1000);
System.out.println("Closing connection");
s.unsubscribe();
Thread.sleep(1000);
System.out.println("Reconnecting");
s = connectable.connect();0
1
2
3
4
Closing connection
Reconnecting
0
1
2
...
When you restart by calling connect again, a new subscription will be created. If the source observable is cold, that means that the whole sequence is restarted.
If instead of terminating the connection, you want to unsubscribe from the hot observable, you can use the Subscription returned by the subscribe method.
ConnectableObservable<Long> connectable = Observable.interval(200, TimeUnit.MILLISECONDS).publish();
Subscription s = connectable.connect();
Subscription s1 = connectable.subscribe(i -> System.out.println("First: " + i));
Thread.sleep(500);
Subscription s2 = connectable.subscribe(i -> System.out.println("Second: " + i));
Thread.sleep(500);
System.out.println("Unsubscribing second");
s2.unsubscribe();First: 0
First: 1
First: 2
Second: 2
First: 3
Second: 3
First: 4
Second: 4
Unsubscribing second
First: 5
First: 6
ConnectableObservable.refCount returns Observable<T> that is connected as long as there are subscribers to it.
Observable<Long> cold = Observable.interval(200, TimeUnit.MILLISECONDS).publish().refCount();
Subscription s1 = cold.subscribe(i -> System.out.println("First: " + i));
Thread.sleep(500);
Subscription s2 = cold.subscribe(i -> System.out.println("Second: " + i));
Thread.sleep(500);
System.out.println("Unsubscribe second");
s2.unsubscribe();
Thread.sleep(500);
System.out.println("Unsubscribe first");
s1.unsubscribe();
System.out.println("First connection again");
Thread.sleep(500);
s1 = cold.subscribe(i -> System.out.println("First: " + i));First: 0
First: 1
First: 2
Second: 2
First: 3
Second: 3
Unsubscribe second
First: 4
First: 5
First: 6
Unsubscribe first
First connection again
First: 0
First: 1
First: 2
First: 3
First: 4
We see here that the sequence doesn't start until there are subscribers to refCount. If they all go away, the connection stops. If more come later, a new connection starts.
public final ConnectableObservable<T> replay()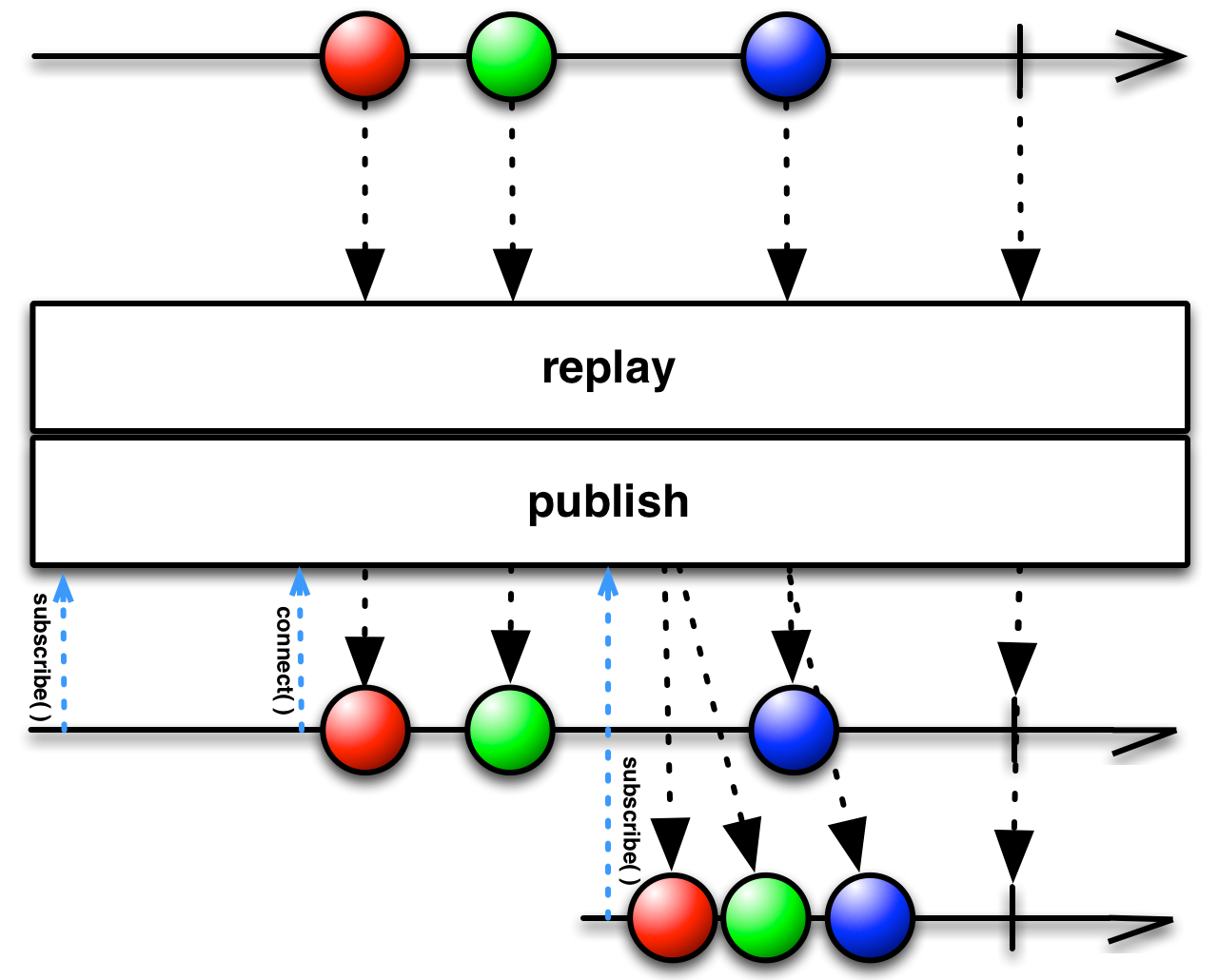
replay resembles the ReplaySubject. Upon connection, it will begin collecting values. Once a new observer subscribes to the observable, it will have all the collected values replayed to it. Once it has caught up, it will receive values in parallel to every other observer.
ConnectableObservable<Long> cold = Observable.interval(200, TimeUnit.MILLISECONDS).replay();
Subscription s = cold.connect();
System.out.println("Subscribe first");
Subscription s1 = cold.subscribe(i -> System.out.println("First: " + i));
Thread.sleep(700);
System.out.println("Subscribe second");
Subscription s2 = cold.subscribe(i -> System.out.println("Second: " + i));
Thread.sleep(500);Subscribe first
First: 0
First: 1
First: 2
Subscribe second
Second: 0
Second: 1
Second: 2
First: 3
Second: 3
replay returns an ConnectableObservable like publish, so we can use the same ways to unsubscribe or create a refCount observable.
There are 8 overloads for replay.
ConnectableObservable<T> replay()
<R> Observable<R> replay(Func1<? super Observable<T>,? extends Observable<R>> selector)
<R> Observable<R> replay(Func1<? super Observable<T>,? extends Observable<R>> selector, int bufferSize)
<R> Observable<R> replay(Func1<? super Observable<T>,? extends Observable<R>> selector, int bufferSize, long time, java.util.concurrent.TimeUnit unit)
<R> Observable<R> replay(Func1<? super Observable<T>,? extends Observable<R>> selector, long time, java.util.concurrent.TimeUnit unit)
ConnectableObservable<T> replay(int bufferSize)
ConnectableObservable<T> replay(int bufferSize, long time, java.util.concurrent.TimeUnit unit)
ConnectableObservable<T> replay(long time, java.util.concurrent.TimeUnit unit)They are different ways of providing one or more of 3 parameters: bufferSize, selector and time (plus unit for time).
bufferSizedetermines the maximum amount of items to be stored and replayed. Upon subscription, the observable will replay the lastbufferSizenumber of items. Older items are forgotten. This is useful for conserving memory.time,unitdetermines how old an element can be before being forgotten. Upon subscription, the observable will replay items that are newer thantime.selectorwill transform the replayed observable, in the same way thatpublish(selector)works.
Here's an example with bufferSize
ConnectableObservable<Long> source = Observable.interval(1000, TimeUnit.MILLISECONDS)
.take(5)
.replay(2);
source.connect();
Thread.sleep(4500);
source.subscribe(System.out::println);2
3
4
When we connect, the source begins emitting the sequence 0,1,2,3,4 in 1s intervals. We sleep for 4.5s before subscribing, which means that the source has emitted 0,1,2,3. 0 and 1 have fallen off the buffer, so only 2 and 3 are replayed. When 4 is emitted, we receive it normally.
When providing a time window, items fall off the buffer based on time
ConnectableObservable<Long> source = Observable.interval(1000, TimeUnit.MILLISECONDS)
.take(5)
.replay(2000, TimeUnit.MILLISECONDS);
source.connect();
Thread.sleep(4500);
source.subscribe(System.out::println);2
3
4
The cache operator has a similar function to replay, but hides away the ConnectableObservable and removes the managing of subscriptions. The internal ConnectableObservable is subscribed to when the first observer arrives. Subsequent subscribers have the previous values replayed to them from the cache and don't result in a new subscription to the source observable.
public final Observable<T> cache()
public final Observable<T> cache(int capacity)
Observable<Long> obs = Observable.interval(100, TimeUnit.MILLISECONDS)
.take(5)
.cache();
Thread.sleep(500);
obs.subscribe(i -> System.out.println("First: " + i));
Thread.sleep(300);
obs.subscribe(i -> System.out.println("Second: " + i));First: 0
First: 1
First: 2
Second: 0
Second: 1
Second: 2
First: 3
Second: 3
First: 4
Second: 4
In this example, we see that the sequence begins not when the observable was created, but when the first subscriber arrived 500ms later. The second subscribers caught up with earlier values upon subscription and received future values normally.
An important thing to note is that the internal ConnectableObservable doesn't unsubscribe if all the subscribers go away, like refCount would. Once the first subscriber arrives, the source observable will be observed and cached once and for all. This matters because we can't walk away from an infinite observable anymore. Values will continue to cached until the source terminates or we run out of memory. The overload that specifies capacity isn't a solution either, as the capacity is received as a hint for optimisation and won't actually restrict the size of our cache.
Observable<Long> obs = Observable.interval(100, TimeUnit.MILLISECONDS)
.take(5)
.doOnNext(System.out::println)
.cache()
.doOnSubscribe(() -> System.out.println("Subscribed"))
.doOnUnsubscribe(() -> System.out.println("Unsubscribed"));
Subscription subscription = obs.subscribe();
Thread.sleep(150);
subscription.unsubscribe();Subscribed
0
Unsubscribed
1
2
3
4
In this example, doOnNext prints the values as they are produced and cached from the source observable, while doOnSubscribe and doOnUnsubscribe show the subscribers after the caching. We see that the emission of values begins with the first subscription but ignores the fact that we unsubscribed.
The share method is an alias for Observable.publish().refCount(). It allows your subscribers to share a subscription, which is kept for as long as there are subscribers.
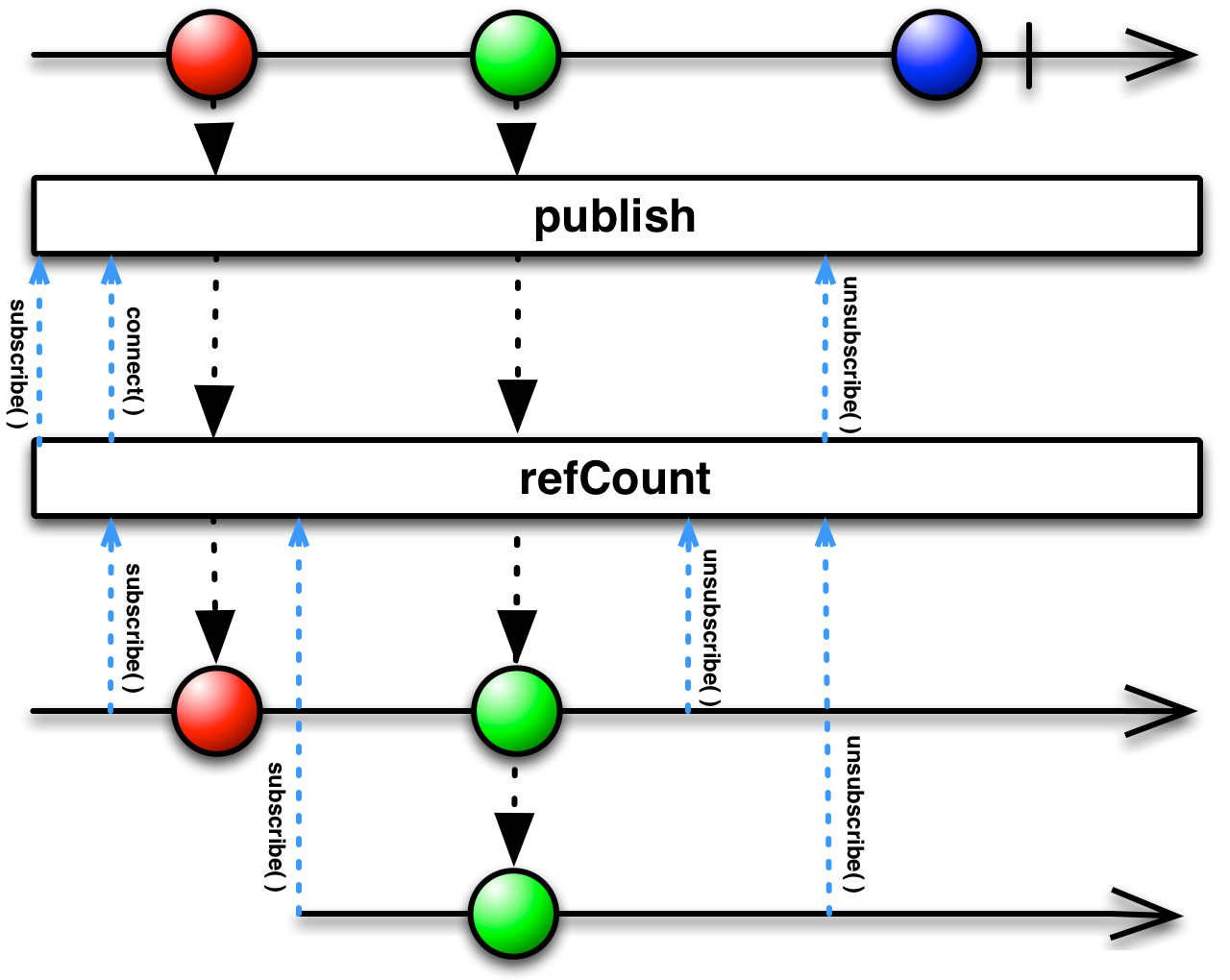
RxJava offers a very large operator set. Counting all the overloads, the number of operators on Rx is over 300. A smaller number of those is essential, meaning that you cannot achieve an Rx implementation without them. Many are there just for convenience and a self-descriptive name. For example, if source.First(user -> user.isOnline()) didn't exist, we would still be able to do source.filter(user -> user.isOnline()).First().
Despite many convenience operators, the operator set of RxJava is still very basic. Rx offers the building blocks that you can combine into anything, but eventually you will want to define reuseable code for repeated cases. In standard Java, this would be done with custom classes and methods. In Rx, you would like the ability to design custom operators. For example, calculating a running average from a sequence of numbers may be very common in your financial application. That doesn't already exist in Observable, but you can make it yourself:
class AverageAcc {
public final int sum;
public final int count;
public AverageAcc(int sum, int count) {
this.sum = sum;
this.count = count;
}
}source
.scan(
new AverageAcc(0,0),
(acc, v) -> new AverageAcc(acc.sum + v, acc.count + 1))
.filter(acc -> acc.count > 0)
.map(acc -> acc.sum/(double)acc.count);That does it, but it's not reusable. In a real financial application, you will probably want to do the same kind of processing over many different sequences. Even if you don't, it would still be nice to hide all this code behind a single phrase: "running average". Understandably, a Java developer's first instinct would be to make a function out of it:
public static Observable<Double> runningAverage(Observable<Integer> source) {
return source
.scan(
new AverageAcc(0,0),
(acc, v) -> new AverageAcc(acc.sum + v, acc.count + 1))
.filter(acc -> acc.count > 0)
.map(acc -> acc.sum/(double)acc.count);
}And you can easily use it:
runningAverage(Observable.just(3, 5, 6, 4, 4))
.subscribe(System.out::println);Output
3.0
4.0
4.666666666666667
4.5
4.4
The above example looks fine because it's simple. Let's do something a little more complicated with our custom operator. Let's take a phrase, turn it into a sequence of word lengths and calculate the running average for that.
runningAverage(
Observable.just("The brown fox jumped and I forget the rest")
.flatMap(phrase -> Observable.from(phrase.split(" ")))
.map(word -> word.length()))
.subscribe(System.out::println);Once again, this works, but it doesn't look 100% Rx. Imagine if everything in Rx was done like the method which we designed (including all the existing operators).
subscribe(
lastOperator(
middleOperator(
firstOperator(source))))We're reading our pipeline in reverse! Yikes!
Rx has a particular style for applying operators, by chaining them, rather than nesting them. This style is not uncommon for objects whose methods return instances of the same type. This makes even more sense for immutable objects and can be found even in standard Java features, such as strings:
String s = new String("Hi").toLowerCase().replace('a', 'c');
This style allows you to see modifications in the order that they are applied, and it also looks neater when a lot of operators are used.
Ideally, you would want your Rx operators to fit into the chain just like any other operator:
Observable.range(0,10)
.map(i -> i*2)
.myOperator()
.subscribe();Many languages have ways of supporting this. Inconveniently, Java doesn't. You'd have to edit Observable itself to add your own methods. There's no point asking the RxJava team to add your idea to the operator set, since there are so many already and the RxJava team are conservative about adding yet another operator. You could extend Observable and add your own operators there. In that case, you'd no longer be able to share and combine libraries of operators.
There is a way of fitting a custom operator into the chain, with the compose method.
public <R> Observable<R> compose(Observable.Transformer<? super T,? extends R> transformer)Aha! A Transformer interface! Transformer<T,R> actually just an alias for the Func1<Observable<T>,Observable<R>> interface. It is a method that takes an Observable<T> and returns an Observable<R>, just like the one we made for calculating a running average.
Observable.just(3, 5, 6, 4, 4)
.compose(Main::runningAverage)
.subscribe(System.out::println);Java doesn't let you reference a function by its name alone, so here we assumed the custom operator is in our Main class. We can see that now our operator fits perfecty into the chain, albeit with the boilerplate of calling compose first. For even better encapsulation, you should implement Observable.Transformer in a new class and move the whole implementation out of sight, along with its helper class(es).
public class RunningAverage implements Observable.Transformer<Integer, Double> {
private static class AverageAcc {
public final int sum;
public final int count;
public AverageAcc(int sum, int count) {
this.sum = sum;
this.count = count;
}
}
@Override
public Observable<Double> call(Observable<Integer> source) {
return source
.scan(
new AverageAcc(0,0),
(acc, v) -> new AverageAcc(acc.sum + v, acc.count + 1))
.filter(acc -> acc.count > 0)
.map(acc -> acc.sum/(double)acc.count);
}
}And we use it like this
source.compose(new RunningAverage())Most Rx operators are parameterisable. We can do this too. Let's extend the functionality of our operator with the possiblity to ignore values above a certain threshold.
public class RunningAverage implements Observable.Transformer<Integer, Double> {
private static class AverageAcc {
public final int sum;
public final int count;
public AverageAcc(int sum, int count) {
this.sum = sum;
this.count = count;
}
}
final int threshold;
public RunningAverage() {
this.threshold = Integer.MAX_VALUE;
}
public RunningAverage(int threshold) {
this.threshold = threshold;
}
@Override
public Observable<Double> call(Observable<Integer> source) {
return source
.filter(i -> i< this.threshold)
.scan(
new AverageAcc(0,0),
(acc, v) -> new AverageAcc(acc.sum + v, acc.count + 1))
.filter(acc -> acc.count > 0)
.map(acc -> acc.sum/(double)acc.count);
}
}We just added the parameter as a field in the operator, added constructors for the uses that we cover and used the parameter in our Rx operations. Now we can do source.compose(new RunningAverage(5)), where, ideally, we would be calling source.runningAverage(5). Java only lets us go this far. Rx is a functional paradigm, but Java is still primarily an object oriented language and quite conservative at that.
You can a complete example of for this example operator here.
Internally, every Rx operator does 3 things
- It subscribes to the source and observes the values.
- It transforms the observed sequence according to the operator's purpose.
- It pushes the modified sequence to its own subscribers, by calling
onNext,onErrorandonCompleted.
The compose operator works with a method that makes an observable out of another. In doing so, it spares you the trouble of doing the 3 steps above manually: the intermediate subscribing and pushing is implicit within an Rx chain. That presumes that you can do the transformation by using existing operators. If the operators don't already exist, you need to do the processing in the traditional Java OOP way. This means extracting the values from the pipeline and re-pushing when processed. An Observable.Transformer that does this would include an explicit subscription to the source Observable and/or the explicit creation of a new Observable to be returned.
You'll find that this is often just boilerplate, and that you can avoid some of it by going to a lower level. The lift operator is similar to compose, with the difference of transforming a Subscriber, instead of an Observable.
public final <R> Observable<R> lift(Observable.Operator<? extends R,? super T> lift)And Observable.Operator<R,T> is an alias for Func1<Subscriber<? super R>,Subscriber<? super T>>: a function that will transform a Subscriber<R> into Subscriber<T>. By dealing directly with Subscriber we avoid involving Observable. The boilerplate of subscribing to and creating Observable types will be handled by lift.
If you studied the signature, there's something which seems backwards at first: to turn an Observable<T> into Observable<R>, we need a function that turns Subscriber<R> into Subscriber<T>. To understand why that is the case, remember that a subscription begins at the end of the chain and is propagated to the source. In other words, a subscription goes backwards through the chain of operators. Each operator receives a subscription (i.e. is subscribed to) and uses that subscription to create a subscription to the preceeding operator.
In the next example, we will reimplement map, without using the existing implementation or any other existing operator.
class MyMap<T,R> implements Observable.Operator<R, T> {
private Func1<T,R> transformer;
public MyMap(Func1<T,R> transformer) {
this.transformer = transformer;
}
@Override
public Subscriber<? super T> call(Subscriber<? super R> subscriber) {
return new Subscriber<T>() {
@Override
public void onCompleted() {
if (!subscriber.isUnsubscribed())
subscriber.onCompleted();
}
@Override
public void onError(Throwable e) {
if (!subscriber.isUnsubscribed())
subscriber.onError(e);
}
@Override
public void onNext(T t) {
if (!subscriber.isUnsubscribed())
subscriber.onNext(transformer.call(t));
}
};
}
}A map operator requires a function that transforms items from T to R. In our implementation, that's the transformer field. The key part is the call method. We receive a Subscriber<R> that wants to receive items of type R. For that subscriber we create a new Subscriber<T> that takes items of type T, transforms them to type R and pushes them to the Subscriber<R>. lift handles the boilerplate of receiving the Subscriber<R>, as well as using the created Subscriber<T> to subscribe on the source observable.
Using an Observable.Operator is as simple as using Observable.Transformer:
Observable.range(0, 5)
.lift(new MyMap<Integer, String>(i -> i + "!"))
.subscribe(System.out::println);0!
1!
2!
3!
4!
A class constructor in Java can't have its type parameters infered. A logical last step would be to make a method that can infer the types for us
public static <T,R> MyMap<T,R> create(Func1<T,R> transformer) {
return new MyMap<T,R>(transformer);
}And use like this
Observable.range(0, 5)
.lift(MyMap.create(i -> i + "!"))
.subscribe(System.out::println);When doing manual pushes to subscribers, like we do when implementing Observable.Operator, there are a few things to consider
- A subscriber is free to unsubscribe. Don't push without checking first:
!subscriber.isUnsubscribed(). - You are responsible for complying with the Rx contract: any number of
onNextnotifications, optionally followed by a singleonCompletedoronError. - If you need to perform asynchronous operations and scheduling, use the Schedulers of Rx. That will allow your operator to become testable.
If you can't guarantee that your operator will obey the Rx contract, for example because you push asynchronously from multiple sources, you can use the serialize operator. The serialize operator will turn an unreliable observable into a lawful, sequential observable.
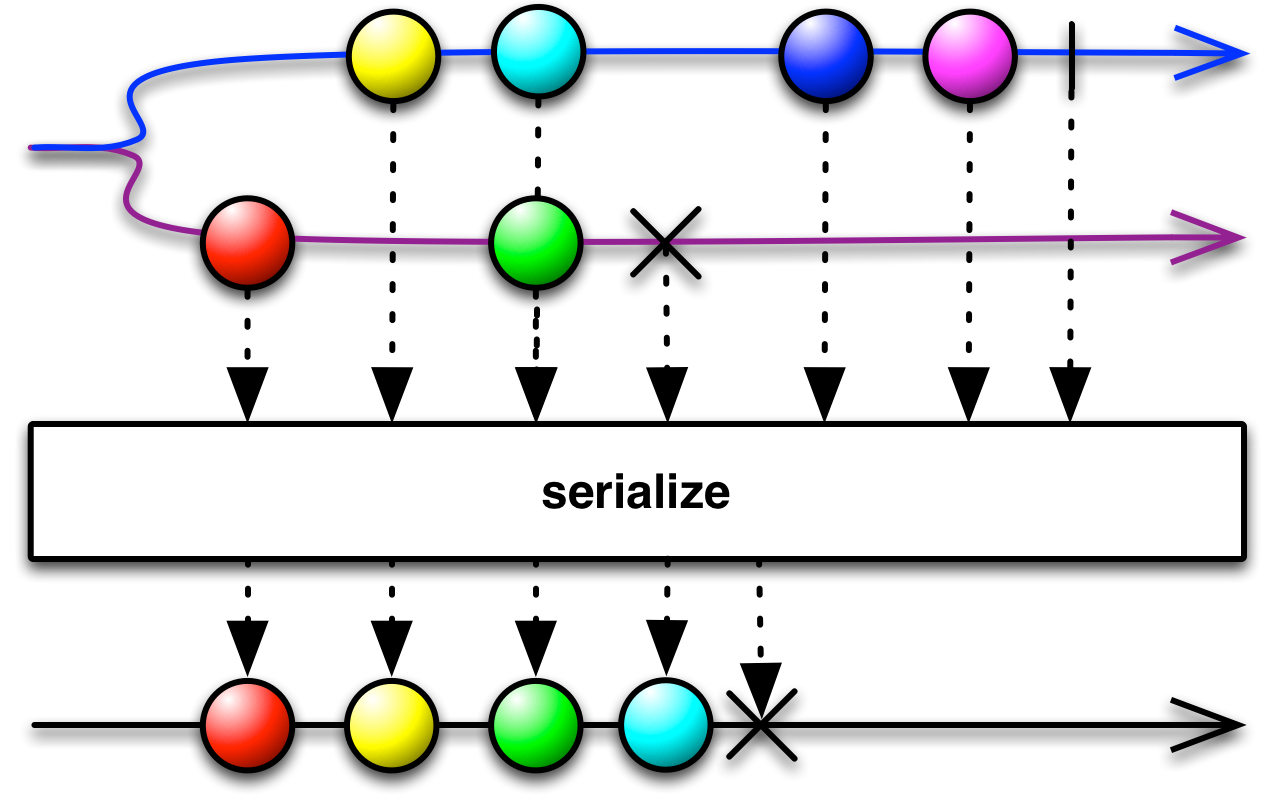
Let's first create an observable that breaks the contract and subscribe to it.
Observable<Integer> source = Observable.create(o -> {
o.onNext(1);
o.onNext(2);
o.onCompleted();
o.onNext(3);
o.onCompleted();
});
source.doOnUnsubscribe(() -> System.out.println("Unsubscribed"))
.subscribe(
System.out::println,
System.out::println,
() -> System.out.println("Completed"));1
2
Completed
Unsubscribed
Despite what our observable tried to emit, the end result obeyed the Rx contract. That happened because subscribe terminated the subscription when it (very reasonably) thought that the sequence ended. This doesn't mean that the problem will always be taken care for us. There is also a method called unsafeSubscribe, which won't unsubscribe automatically.
Observable<Integer> source = Observable.create(o -> {
o.onNext(1);
o.onNext(2);
o.onCompleted();
o.onNext(3);
o.onCompleted();
});
source.doOnUnsubscribe(() -> System.out.println("Unsubscribed"))
.unsafeSubscribe(new Subscriber<Integer>() {
@Override
public void onCompleted() {
System.out.println("Completed");
}
@Override
public void onError(Throwable e) {
System.out.println(e);
}
@Override
public void onNext(Integer t) {
System.out.println(t);
}
});1
2
Completed
3
Completed
Our subscriber's intended behaviour was identical to the previous example (we created an instance of Subscriber because unsafeSubscribe doesn't have overloads that take lambdas). However, we can see here we weren't unsubscribed and we kept receiving notifications.
unsafeSubscribe is unsafe in other regards as well, such as error handling. It's usefulness is limited. The documentation says that it should only be used for custom operators that use nested subscriptions. To protect such operators from receiving and illegal sequence, we can apply the serialize operator
Observable<Integer> source = Observable.create(o -> {
o.onNext(1);
o.onNext(2);
o.onCompleted();
o.onNext(3);
o.onCompleted();
})
.cast(Integer.class)
.serialize();;
source.doOnUnsubscribe(() -> System.out.println("Unsubscribed"))
.unsafeSubscribe(new Subscriber<Integer>() {
@Override
public void onCompleted() {
System.out.println("Completed");
}
@Override
public void onError(Throwable e) {
System.out.println(e);
}
@Override
public void onNext(Integer t) {
System.out.println(t);
}
});1
2
Completed
We see that, despite the fact that we did not unsubscribe, the illegal notifications were filtered out.
If the ability to use your custom operator in the chain like a standard operator is not convincing enough, using lift has one more unexpected advantage. Standard operators are also implemented using lift, which makes lift a hot method at runtime. JVM optimises for lift and operators that use lift receive a performance boost. That can include your operator, if you use lift.
Both lift and compose are meta-operators, used for injecting a custom operator into the chain. In both cases, the custom operator can be implemented as a function or a class.
compose:Observable.TransformerorFunc<Observable<TSource>, Observable<TReturn>>lift:Observable.OperatororFunc<Subscriber<TReturn>, Subscriber<TSource>>
Theoretically, any operator can be implemented as both Observable.Operator and Observable.Transformer. The choice between the two is a question of convenience, and what kind of boilerplate you want to avoid.
- If the custom operator is a composite of existing operators,
composeis a natural fit. - If the custom operator needs to extract values from the pipeline to process them and then push them back,
liftis a better fit.
Because Rx is targeted at asynchronous systems and because Rx can naturally support multithreading, new Rx developers sometimes assume that Rx is multithreaded by default. It is important clarify before anything else that Rx is single-threaded by default.
Unless you specify otherwise, every call to onNext/onError/onCompleted executes the entire chain of operators synchronously, including the actions of the final subscriber. We can see than in the following example:
final BehaviorSubject<Integer> subject = BehaviorSubject.create();
subject.subscribe(i -> {
System.out.println("Received " + i + " on " + Thread.currentThread().getId());
});
int[] i = {1}; // naughty side-effects for examples only ;)
Runnable r = () -> {
synchronized(i) {
System.out.println("onNext(" + i[0] + ") on " + Thread.currentThread().getId());
subject.onNext(i[0]++);
}
};
r.run(); // Execute on main thread
new Thread(r).start();
new Thread(r).start();onNext(1) on 1
Received 1 on 1
onNext(2) on 11
Received 2 on 11
onNext(3) on 12
Received 3 on 12
We see here that we called onNext on our subject from 3 different threads. Every time, the subscriber's action was executed on the same thread where the first onNext call came from. The same would be true no matter how many operators we had chained together. The value goes through the chain synchronously, unless we request otherwise.
subscribeOn and observeOn allow you to control you to control the invocation of the subscription and the reception of notifications (what thread will call onNext/onError/onCompleted on your observer).
public final Observable<T> observeOn(Scheduler scheduler)
public final Observable<T> subscribeOn(Scheduler scheduler)In Rx you don't juggle threads directly. Instead you wrap them in policies called Scheduler. We will see more on that later.
With subscribeOn you decide on what Scheduler the Observable.create is executed. Even if you're not calling create yourself, there is an internal equivalent to it. Consider the following example:
System.out.println("Main: " + Thread.currentThread().getId());
Observable.create(o -> {
System.out.println("Created on " + Thread.currentThread().getId());
o.onNext(1);
o.onNext(2);
o.onCompleted();
})
//.subscribeOn(Schedulers.newThread())
.subscribe(i -> {
System.out.println("Received " + i + " on " + Thread.currentThread().getId());
});
System.out.println("Finished main: " + Thread.currentThread().getId());Main: 1
Created on 1
Received 1 on 1
Received 2 on 1
Finished main: 1
We see here that, not only is everything executed on the same thread, it is actually sequential: subscribe does not unblock until it has completed subscribing to (and thus creating) the observable, which includes executing the body of create's lambda parameter. The calls to onNext within that lambda execute the entire chain of operators, all the way to the println. Effectively, subscribing on a created observable is blocking.
If you uncomment .subscribeOn(Schedulers.newThread()), the output now is
Main: 1
Finished main: 1
Created on 11
Received 1 on 11
Received 2 on 11
Schedulers.newThread() provided a new thread for our lambda function to run on. subscribe no longer blocks until create's lambda is executed and the main thread is free to proceed.
Some observables create their own threads regardless of you what you requested. For example, Observable.interval is asynchronous regardless. In such cases, subscribeOn will dictate on what thread to run the function which creates the resources, which typically won't be helpful. It gives you no control over what resources will be leased.
System.out.println("Main: " + Thread.currentThread().getId());
Observable.interval(100, TimeUnit.MILLISECONDS)
.subscribe(i -> {
System.out.println("Received " + i + " on " + Thread.currentThread().getId());
});
System.out.println("Finished main: " + Thread.currentThread().getId());Main: 1
Finished main: 1
Received 0 on 11
Received 1 on 11
Received 2 on 11
observeOn controls the other side of the pipeline. The creation and emission of values will work like normal, but the actions of your observer will be invoked on a different thread, as specified by the Scheduler policy.
Observable.create(o -> {
System.out.println("Created on " + Thread.currentThread().getId());
o.onNext(1);
o.onNext(2);
o.onCompleted();
})
.observeOn(Schedulers.newThread())
.subscribe(i ->
System.out.println("Received " + i + " on " + Thread.currentThread().getId()));Created on 1
Received 1 on 13
Received 2 on 13
Unlike subscribeOn, observeOn's effect doesn't jump to the start of the pipeline. It just changes the thread for the operators that come after it. You can think of it as intercepting events and changing the thread for the rest of the chain. Here's an example for this:
Observable.create(o -> {
System.out.println("Created on " + Thread.currentThread().getId());
o.onNext(1);
o.onNext(2);
o.onCompleted();
})
.doOnNext(i ->
System.out.println("Before " + i + " on " + Thread.currentThread().getId()))
.observeOn(Schedulers.newThread())
.doOnNext(i ->
System.out.println("After " + i + " on " + Thread.currentThread().getId()))
.subscribe();Created on 1
Before 1 on 1
Before 2 on 1
After 1 on 13
After 2 on 13
We can see here that events start on the thread that calls onNext and stay on that thread until they encounter the observeOn operator. After that, they continue on the new thread. This way you can assign different threading policies to different parts of an Rx pipeline.
This is very useful if you, as the consumer of an observable, know that processing is time-consuming and you don't want to block the producing thread. A typical case for this is applications with a GUI. GUI libraries have a special thread that has the exclusive right to access GUI components (buttons etc). While the GUI thread is busy, everything becomes non-responsive. Handlers to GUI events are invoked on the GUI thread and everything the handler does will block the GUI thread. In order not to have your application freeze for the duration of the processing, you must move heavy processing to another thread. You can use observeOn to move away and again to return to the GUI thread, when the data is ready to be displayed.
As we have seen, some observables depend on resources which are leased on subscription and released when subscriptions end. Typically, releasing resources is cheap. In exceptional cases, where you need the unsubscription actions to not block or to specifically take place on a special thread, you can specify the scheduler that will execute those actions with unsubscribeOn
Observable<Object> source = Observable.using(
() -> {
System.out.println("Subscribed on " + Thread.currentThread().getId());
return Arrays.asList(1,2);
},
(ints) -> {
System.out.println("Producing on " + Thread.currentThread().getId());
return Observable.from(ints);
},
(ints) -> {
System.out.println("Unubscribed on " + Thread.currentThread().getId());
}
);
source
.unsubscribeOn(Schedulers.newThread())
.subscribe(System.out::println);Subscribed on 1
Producing on 1
1
2
Unubscribed on 11
The using method executes 3 functions, one that leases a resource, one that uses it and one the releases it. With unsubscribeOn we only affected the function that releases the resource.
The observeOn and subscribeOn methods take as an argument a Scheduler. A Scheduler, as the name suggests, is a tool that can schedule individual actions to be performed. The specifics of how the action will be invoked depends on the implementation of the scheduler used. You can create your own implementation of scheduler, but most of time you'll find that RxJava already has you covered with a set of Schedulers for the common cases. You can get the existing implementations from the factory methods on Schedulers.
The existing schedulers are as follows
immediateexecutes the scheduled action synchronously. No actual scheduling takes place.trampolinequeues work on the current thread to be executed after the current work completes.newThreadcreates a new thread for each scheduled unit of work.computationis intended for CPU workiois intended for IO worktestis useful for testing and debugging.
In the current implementation, computation and io schedulers aren't actually unique implementations. The point of this separation is to have unique instances, while also documenting your intent.
Many of the Rx operators use schedulers internally. If you revisit the Observable operators that you've seen so far, you'll see that all the asynchronous operators have overloads that take a Scheduler. You can dictate exactly what scheduler each operator uses. You can also find in the documentation which scheduler they use when you don't provide one.
The approaches and implementations for scheduling used in Rx schedulers aren't specific to Rx. In fact, they are quite standard and could be used without any Rx code. You typically won't have to use schedulers directly, except for when you are designing a custom asynchronous operator. Using schedulers in custom operators isn't only convenient, but it also allow asynchronous operators to become testable, as we will see in the next chapter.
An implementation of Scheduler has two parts. One is the notion of time, which you can get through the now() method. Implementing time through the scheduler is going to prove useful when virtualising time for testing, but for now this feature isn't interesting.
The interesting part is createWorker(), which returns a Scheduler.Worker. A worker accepts actions and executes them sequentially on a single thread. In a way, a worker is a scheduler itself, but we will not refer to it as a scheduler to avoid confusion.
The way to schedule a job on any Scheduler is to create a new worker for that scheduler and schedule actions on that worker.
Scheduler.Worker worker = scheduler.createWorker();
worker.schedule(
() -> System.out.println("Action"));The action is then queued to be executed on the thread that the worker is assigned to.
As you would expect from a scheduler, you can also schedule actions to be executed in the future once or repeatedly with the following methods:
Subscription schedule(
Action0 action,
long delayTime,
java.util.concurrent.TimeUnit unit)
Subscription schedulePeriodically(
Action0 action,
long initialDelay,
long period,
java.util.concurrent.TimeUnit unit)Scheduler scheduler = Schedulers.newThread();
long start = System.currentTimeMillis();
Scheduler.Worker worker = scheduler.createWorker();
worker.schedule(
() -> System.out.println(System.currentTimeMillis()-start),
5, TimeUnit.SECONDS);
worker.schedule(
() -> System.out.println(System.currentTimeMillis()-start),
5, TimeUnit.SECONDS);5033
5035
We can see here that delay for the execution is measured from the moment of scheduling. The specified time is not a mandatory sleep period in between tasks. The worker can do work in the meantime, if there is work ready for execution.
Scheduler.Worker extends Subscription. Calling the unsubscribe method on a worker will result in the queue being emptied and all pending tasks being cancelled. We can see that by modifying out previous example
Scheduler scheduler = Schedulers.newThread();
long start = System.currentTimeMillis();
Scheduler.Worker worker = scheduler.createWorker();
worker.schedule(
() -> {
System.out.println(System.currentTimeMillis()-start);
worker.unsubscribe();
},
5, TimeUnit.SECONDS);
worker.schedule(
() -> System.out.println(System.currentTimeMillis()-start),
5, TimeUnit.SECONDS);5032
The second task is never executed because the one before it cancelled everything. Actions that were in the process of being executed will be interrupted. In the next example, we will create a task that sleeps for 2000ms. 500ms after it has begun executing we cancel all work on the worker. This results in an InterruptedException.
Scheduler scheduler = Schedulers.newThread();
long start = System.currentTimeMillis();
Scheduler.Worker worker = scheduler.createWorker();
worker.schedule(() -> {
try {
Thread.sleep(2000);
System.out.println("Action completed");
} catch (InterruptedException e) {
System.out.println("Action interrupted");
}
});
Thread.sleep(500);
worker.unsubscribe();Action interrupted
As we saw earlier in the signature of schedule, scheduling returns a Subscription. Rather that canceling all work, you can cancel individual tasks via that Subscription that was created while scheduling.
ImmediateScheduler doesn't do any scheduling at all. Upon request for scheduling, the scheduler instead just executes the action synchronously and returns when the action is completed. Nested requests for scheduling will result in the actions being executed recursively.
Scheduler scheduler = Schedulers.immediate();
Scheduler.Worker worker = scheduler.createWorker();
worker.schedule(() -> {
System.out.println("Start");
worker.schedule(() -> System.out.println("Inner"));
System.out.println("End");
});Start
Inner
End
The TrampolineScheduler's worker is also synchronous but does not nest tasks. Instead, it begins with the initial task and any tasks scheduled while executing will be queued for after the current task has completed.
Scheduler scheduler = Schedulers.trampoline();
Scheduler.Worker worker = scheduler.createWorker();
worker.schedule(() -> {
System.out.println("Start");
worker.schedule(() -> System.out.println("Inner"));
System.out.println("End");
});
Start
End
Inner
The TrampolineScheduler's worker executes every task on the thread that scheduled the first task. In this implementation, the first call to schedule is blocking until the queue is emptied. Any calls to schedule while executing will be non-blocking and the task will be executed by the thread is blocked.
The NewThreadScheduler creates workers that each have their own thread. Every scheduled task will be executed on the thread corresponding to that particular worker.
Let us first define a convenient method will make the following examples more readable.
public static void printThread(String message) {
System.out.println(message + " on " + Thread.currentThread().getId());
}Now we schedule work on a NewThreadScheduler worker and demonstrate that the worker is bound to a specific thread.
printThread("Main");
Scheduler scheduler = Schedulers.newThread();
Scheduler.Worker worker = scheduler.createWorker();
worker.schedule(() -> {
printThread("Start");
worker.schedule(() -> printThread("Inner"));
printThread("End");
});
Thread.sleep(500);
worker.schedule(() -> printThread("Again"));Main on 1
Start on 11
End on 11
Inner on 11
Again on 11
When designing any system, you want guarantees about the correctness of the operations and that this quality does not regress as the system is modified throughout its lifetime. You'll design tests, which, ideally, should be automated. Modern software is backed by thorough unit tests and Rx code should be no different.
Testing a synchronous piece of Rx code is as straight-forward as any unit test you are likely to find, using predefined sequences and [inspection](/Part 2 - Sequence Basics/3. Inspection.md). But what about asynchronous code? Consider testing the following piece of code:
Observable.interval(1, TimeUnit.SECONDS)
.take(5)That is a sequence that takes 5 seconds to complete. That means every test that uses this sequence will take 5 seconds or more. That's not convenient at all, if you have thousands of tests to run.
The piece of code above isn't just time-consuming, it actually wastes all of that time doing nothing while waiting. If you could fast-forward the clock, that sequence would be evaluated almost instantly. You can't actually fast-forward your system's clock, but you can fast-forward a virtualised clock. It was a design decision in Rx to only use time through schedulers. This decision allows you to replace real time with a scheduler that virtualises time, called TestScheduler.
The TestScheduler does scheduling in the same way as the schedulers that we saw in the chapter about [Scheduling and threading](/Part 4 - Concurrency/1. Scheduling and threading.md). It schedules actions to be executed either immediately or in the future. The difference is that time is frozen and only progresses upon request. We decide when time progresses and by how much.
As the name suggests, advanceTimeTo will execute all actions that are scheduled for up to a specific moment in time. That includes actions scheduled while the scheduler was being fast-forwarded, i.e. actions scheduled by other actions.
TestScheduler s = Schedulers.test();
s.createWorker().schedule(
() -> System.out.println("Immediate"));
s.createWorker().schedule(
() -> System.out.println("20s"),
20, TimeUnit.SECONDS);
s.createWorker().schedule(
() -> System.out.println("40s"),
40, TimeUnit.SECONDS);
System.out.println("Advancing to 1ms");
s.advanceTimeTo(1, TimeUnit.MILLISECONDS);
System.out.println("Virtual time: " + s.now());
System.out.println("Advancing to 10s");
s.advanceTimeTo(10, TimeUnit.SECONDS);
System.out.println("Virtual time: " + s.now());
System.out.println("Advancing to 40s");
s.advanceTimeTo(40, TimeUnit.SECONDS);
System.out.println("Virtual time: " + s.now());Advancing to 1ms
Immediate
Virtual time: 1
Advancing to 10s
Virtual time: 10000
Advancing to 40s
20s
40s
Virtual time: 40000
We scheduled 3 tasks: one to be executed immediately, and two to be executed in the future. Nothing happens until we advance time, including the tasks scheduled immediately. When we advance time, the scheduler synchronously executes all the tasks that were scheduled for that period of time, in the order of the time they were scheduled for.
advanceTimeTo allows you to set time to any value, including one that is before the current time. This implementation decision can needlessly introduce bugs in the tests, so it is probably better to use the next method, when applicable.
advanceTimeBy advances time relative to the current moment in time. In every other regard, works like advanceTimeTo.
TestScheduler s = Schedulers.test();
s.createWorker().schedule(
() -> System.out.println("Immediate"));
s.createWorker().schedule(
() -> System.out.println("20s"),
20, TimeUnit.SECONDS);
s.createWorker().schedule(
() -> System.out.println("40s"),
40, TimeUnit.SECONDS);
System.out.println("Advancing by 1ms");
s.advanceTimeBy(1, TimeUnit.MILLISECONDS);
System.out.println("Virtual time: " + s.now());
System.out.println("Advancing by 10s");
s.advanceTimeBy(10, TimeUnit.SECONDS);
System.out.println("Virtual time: " + s.now());
System.out.println("Advancing by 40s");
s.advanceTimeBy(40, TimeUnit.SECONDS);
System.out.println("Virtual time: " + s.now());Advancing by 1ms
Immediate
Virtual time: 1
Advancing by 10s
Virtual time: 10001
Advancing by 40s
20s
40s
Virtual time: 50001
triggerActions does not advance time. It only executes actions that were scheduled to be executed up to the present.
TestScheduler s = Schedulers.test();
s.createWorker().schedule(
() -> System.out.println("Immediate"));
s.createWorker().schedule(
() -> System.out.println("20s"),
20, TimeUnit.SECONDS);
s.triggerActions();
System.out.println("Virtual time: " + s.now());Immediate
Virtual time: 0
There is nothing preventing actions from being scheduled for the same moment in time. When that happens, we have a scheduling collision. The order that two simultaneous tasks are executed is the same as the order in which they where scheduled.
TestScheduler s = Schedulers.test();
s.createWorker().schedule(
() -> System.out.println("First"),
20, TimeUnit.SECONDS);
s.createWorker().schedule(
() -> System.out.println("Second"),
20, TimeUnit.SECONDS);
s.createWorker().schedule(
() -> System.out.println("Third"),
20, TimeUnit.SECONDS);
s.advanceTimeTo(20, TimeUnit.SECONDS);First
Second
Third
Rx operators which involve asynchronous actions schedule those actions using a scheduler. If you take a look at all the operators in Observable, you will see that such operators have overloads that take a scheduler. This is the way that you can supplement their real-time schedulers for your TestScheduler.
Here is an example where we will test the output of Observable.interval against what we expect it to emit.
@Test
public void test() {
TestScheduler scheduler = new TestScheduler();
List<Long> expected = Arrays.asList(0L, 1L, 2L, 3L, 4L);
List<Long> result = new ArrayList<>();
Observable
.interval(1, TimeUnit.SECONDS, scheduler)
.take(5)
.subscribe(i -> result.add(i));
assertTrue(result.isEmpty());
scheduler.advanceTimeBy(5, TimeUnit.SECONDS);
assertTrue(result.equals(expected));
}This is useful for testing small, self-contained pieces of Rx code, such as custom operators. A complete system may be using schedulers on its own, thus defeating our virtual time. Lee Campbell suggested abstracting over Rx's scheduler factories (Schedulers), with a provider of our own. When in debug-mode, our custom scheduler factory will replace all schedulers with a TestScheduler, which we will then use to control time throughout our system.
In the test above, we manually collected the values emitted and compared them against what we expected. This process is common enough in tests that Rx comes packaged with TestScubscriber, which will do that for us. Its event handlers will collect every notification received and make them available for us to inspect. With TestSubscriber our previous test becomes:
@Test
public void test() {
TestScheduler scheduler = new TestScheduler();
TestSubscriber<Long> subscriber = new TestSubscriber<>();
List<Long> expected = Arrays.asList(0L, 1L, 2L, 3L, 4L);
Observable
.interval(1, TimeUnit.SECONDS, scheduler)
.take(5)
.subscribe(subscriber);
assertTrue(subscriber.getOnNextEvents().isEmpty());
scheduler.advanceTimeBy(5, TimeUnit.SECONDS);
subscriber.assertReceivedOnNext(expected);
}A TestSubscriber collects more than just values and exposes them through the following methods:
java.lang.Thread getLastSeenThread()
java.util.List<Notification<T>> getOnCompletedEvents()
java.util.List<java.lang.Throwable> getOnErrorEvents()
java.util.List<T> getOnNextEvents()There are two things to notice here. First is the getLastSeenThread method. A TestSubscriber checks on what thread it is notified and logs the most recent. That can be useful if, for example, you want to verify that an operation is/isn't executed on the GUI thread. Another interesting thing to notice is that there can be more than one termination event. That goes against how we defined our sequences in the begining of this guide. That is also the reason why the subscriber is capable of collecting multiple termination events: that would be a violation of the Rx contract and needs to be debugged.
TestSubscriber provides shorthands for a few basic assertions:
void assertNoErrors()
void assertReceivedOnNext(java.util.List<T> items)
void assertTerminalEvent()
void assertUnsubscribed()There is also a way to block execution until the observable, to which the TestSubscriber is subscribed, terminates.
void awaitTerminalEvent()
void awaitTerminalEvent(long timeout, java.util.concurrent.TimeUnit unit)
void awaitTerminalEventAndUnsubscribeOnTimeout(long timeout, java.util.concurrent.TimeUnit unit)Awaiting with a timeout will cause an exception if the observable fails to complete on time.
Rx tries to avoid state outside of the pipeline. However, some things are inherently stateful. A server can be up or down, a mobile device may have access to wifi, a button is held down. In Rx, we see those as events with a duration and we call them windows. Other events that happen within those windows may need to be treated differently. For example, a mobile device will postpone network requests with low priority while using more expensive channels of communication.
With buffer, we saw an operator that can take a sequence and group values into chunks, based on a variety of overloads. The window operator has a one-to-one relationship with buffer. The main difference is that it doesn't return the groups in buffered chunks. Instead, it returns a sequence of sequences, each sequence corresponding to what would have been a buffer. This means that every emitted observable emits its values as soon as they appear in the source observable, rather than emitting them all at the end of the window. That relationship between buffer and window is immediately apparent by a quick look on the marble diagrams of two corresponding overloads:
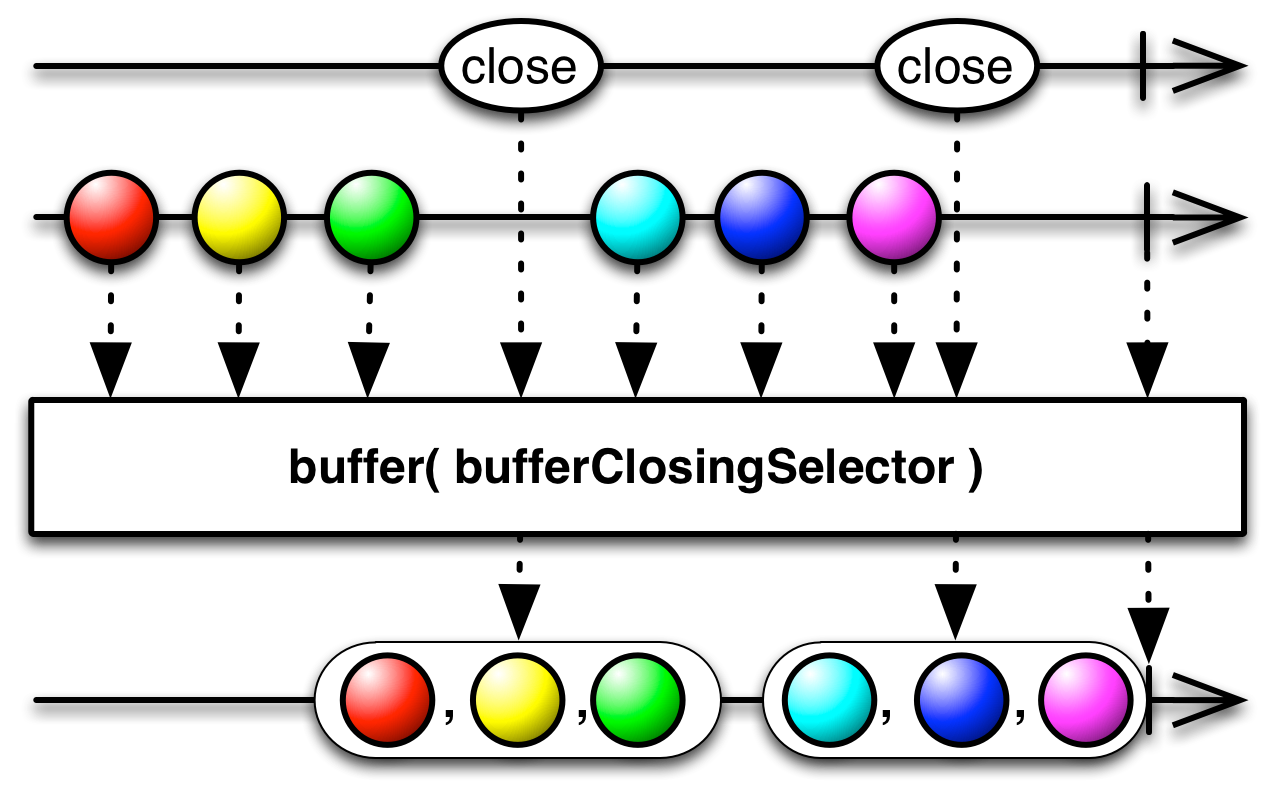
With window this becomes:
If you are not already familiar with buffer, I strongly recommend that you begin with that. The overloads and resulting groupings are the same in both operators, but buffer is easier to understand and present examples for. Every buffer overload can be contructed from the window overload with the same arguments as such:
source.buffer(...)
// same as
source.window(...).flatMap(w -> w.toList())You can have windows with a fixed number of elements. Once the window has emitted the required number of elements, the observable terminates and a new one starts.
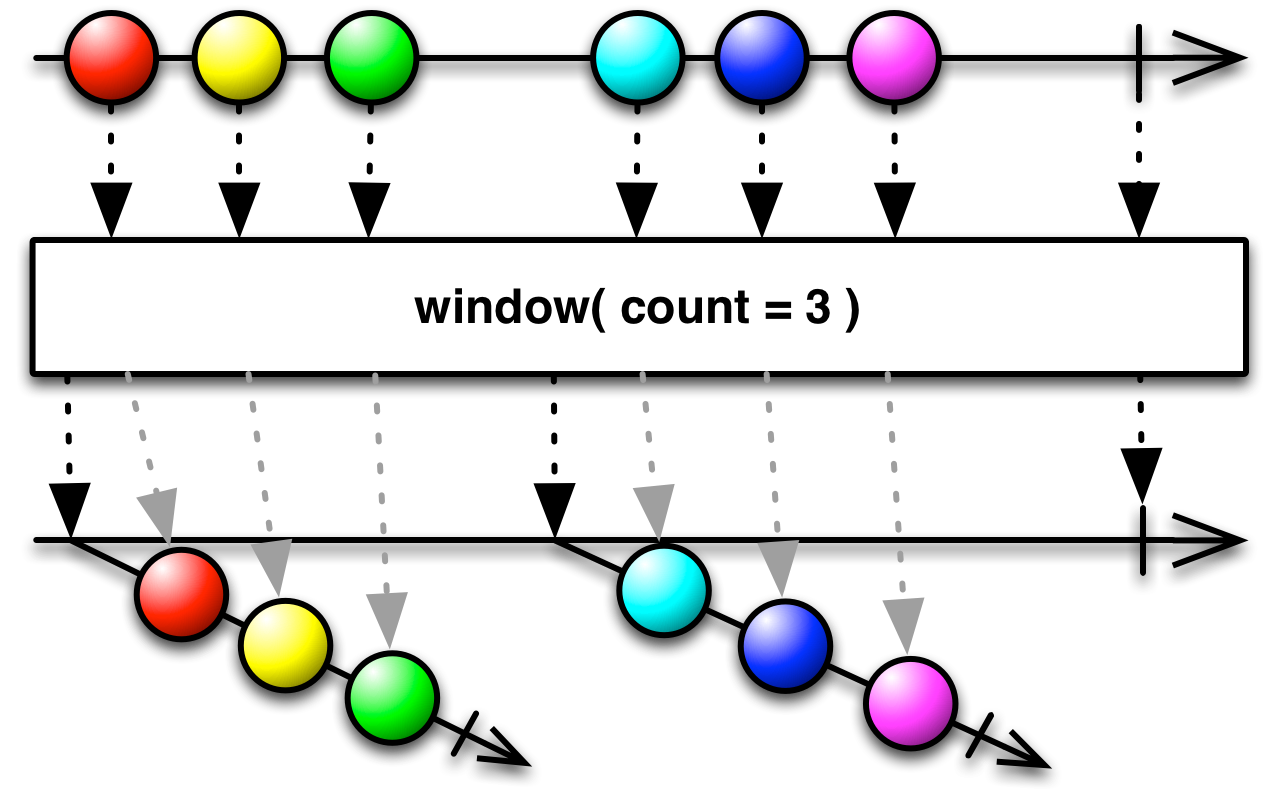
You can also have skipping and overlapping windows like you do in buffer with window(int count, int skip). When windows overlap they will be emitting values simultaneously, as can be seen in the next example.
Observable
.merge(
Observable.range(0, 5)
.window(3,1))
.subscribe(System.out::println);0
1
1
2
2
2
3
3
3
4
4
4
We can see here that the inner observables are emitting the same item simultaneously. To more clearly see what each observable is emitting, let us format the output in a different way:
Observable.range(0, 5)
.window(3, 1)
.flatMap(o -> o.toList())
.subscribe(System.out::println);[0, 1, 2]
[1, 2, 3]
[2, 3, 4]
[3, 4]
[4]
By turning the inner observables into lists, we see how closely related window is to buffer.
Rather than having windows of fixed size, you can have windows of a fixed duration in time.
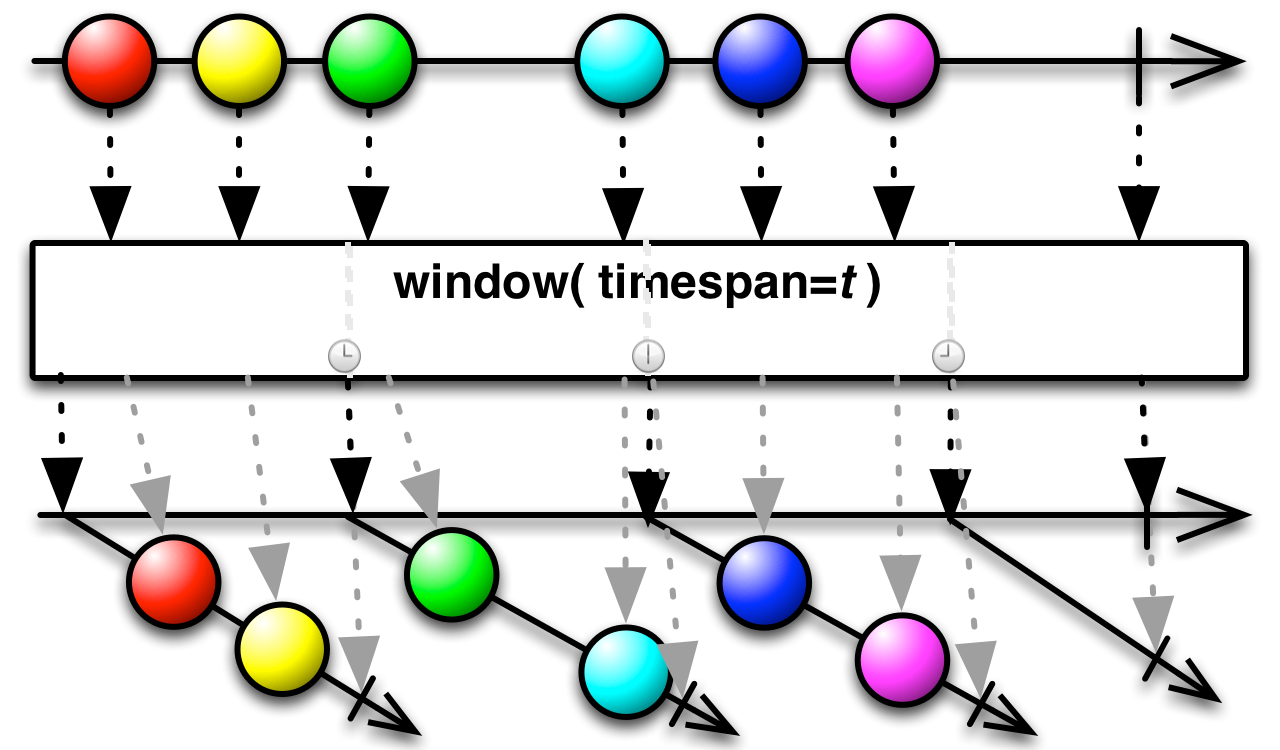
You can contruct windows that overlap or skip elements, just like you would with buffer, with
public final Observable<Observable<T>> window(long timespan, long timeshift, java.util.concurrent.TimeUnit unit)Observable.interval(100, TimeUnit.MILLISECONDS)
.take(5)
.window(250, 100, TimeUnit.MILLISECONDS)
.flatMap(o -> o.toList())
.subscribe(System.out::println);[0, 1]
[0, 1, 2]
[1, 2, 3]
[2, 3, 4]
[3, 4]
[4]
In this example, a new window begins every 100ms and lasts 250ms. The first window opens at time 0ms and remains open long enough to catch [0, 1] (interval emits the first value at time 100ms). Every subsequent window remains open long enough to catch the next 3 values, except for when the values stop.
Lastly, you can define windows using another observable. Every time your signaling observable emits a value, the old window closes and a new one starts.
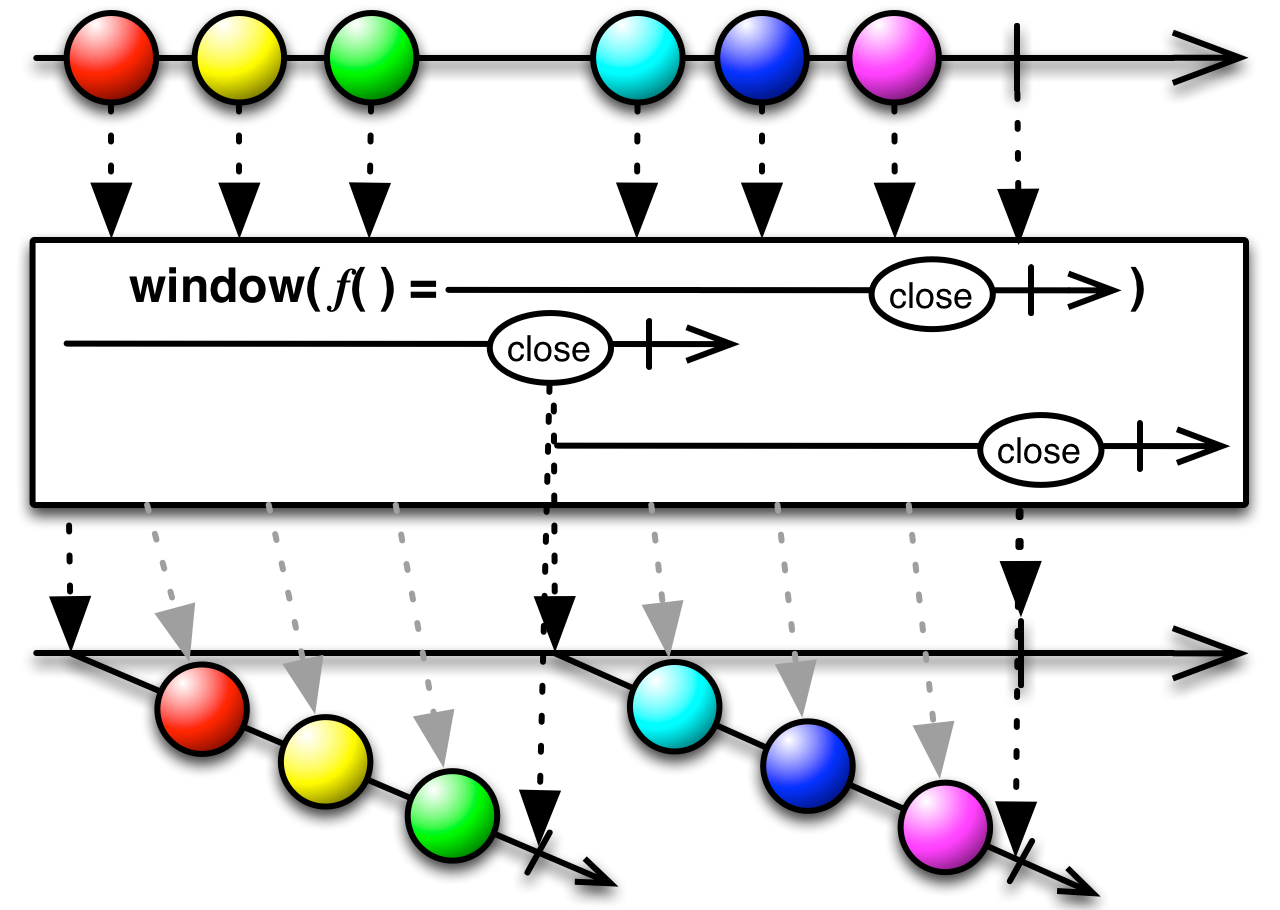
Alternatively, to have overlapping windows, you can provide a function that uses the values emitted by your signaling observable to contruct another observable that will signal the closing of the window. When the observable terminates, the corresponding window closes.
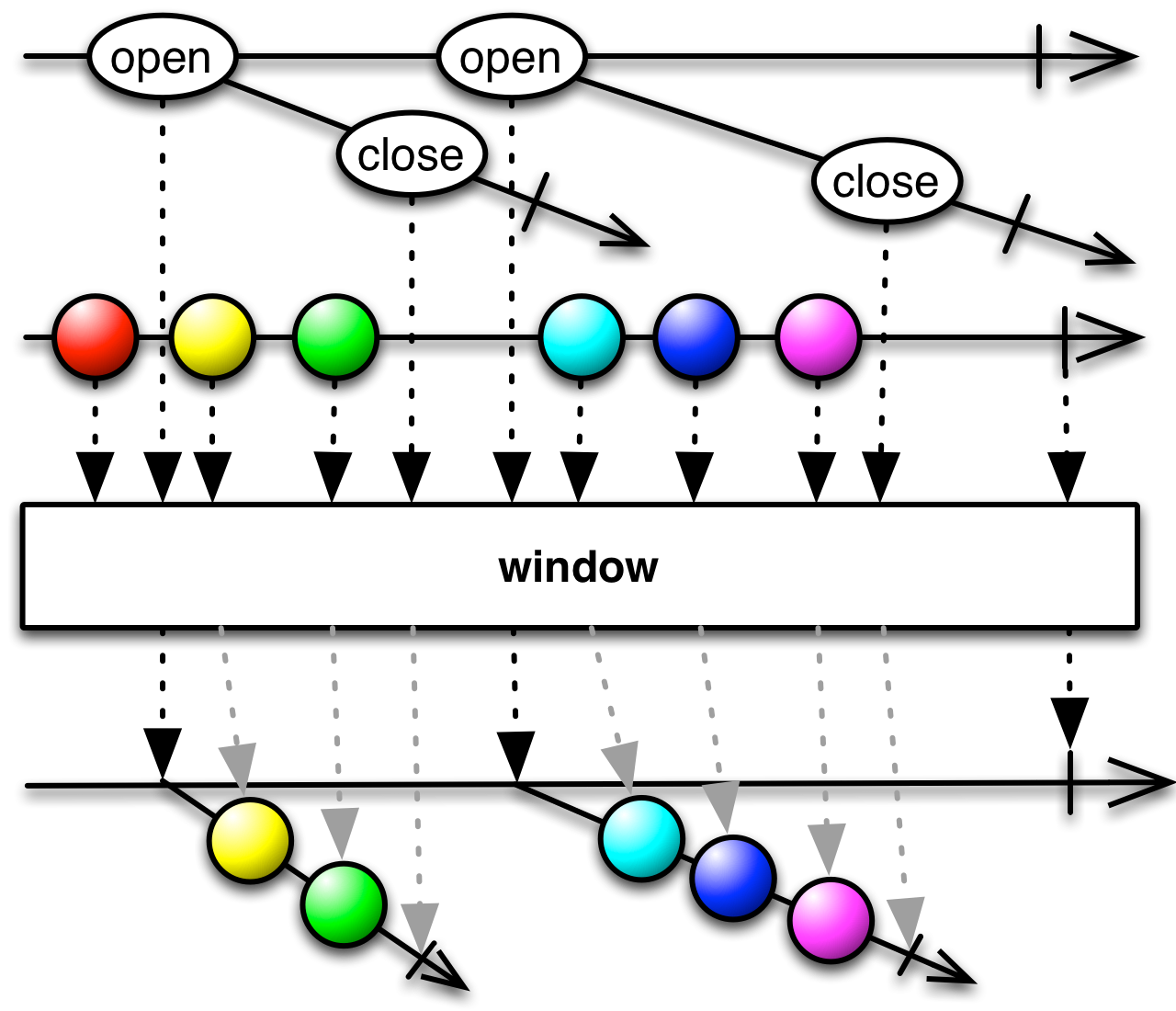
Here's an example with overlapping windows based on signaling observables
Observable.interval(100, TimeUnit.MILLISECONDS)
.take(5)
.window(
Observable.interval(100, TimeUnit.MILLISECONDS),
o -> Observable.timer(250, TimeUnit.MILLISECONDS))
.flatMap(o -> o.toList())
.subscribe(System.out::println);[1, 2]
[2, 3]
[3, 4]
[4]
[]
This example is the same as the previous example: a new window opens every 100ms and lasts 250ms, with the exception that the first window starts at 100ms rather than 0ms. We see a difference in results, however. The window that begins at time 100ms does not catch the value that is emitted at 100ms, and the same goes for every other window. This happens because the interval event that begins the window fires just after the interval event that is the value. Even though the two events are simultaneous in theory, in practice there is no such thing.
join allows you to pair together items from two sequences. We've already seen zip, which pairs values based on their index. join allows you to pair values based on durations. Let's see the signature first:
public final <TRight,TLeftDuration,TRightDuration,R> Observable<R> join(
Observable<TRight> right,
Func1<T,Observable<TLeftDuration>> leftDurationSelector,
Func1<TRight,Observable<TRightDuration>> rightDurationSelector,
Func2<T,TRight,R> resultSelector)join combines two sequences, called "left" and "right". The method is not static and the left sequence is implied to be the one that join is being called on. In the signature, we can see two methods called leftDurationSelector and rightDurationSelector, which take as an argument an item of the respective sequence. They return an observable that defines a duration (i.e. a window), just like in the last overload of window. These windows are used to select values to be paired together. Values that are paired are passed to the resultSelector function which will combine them into a single value, like a resultSelector in zip does. That value will be emitted by join.
The thing that makes join powerful, but also complicated to understand, is how values are selected to be paired. Every value that arrives in a sequence begins a window for itself. The corresponding duration selector decides when the window for each value will terminate. While the window is open, any value arriving in the opposite sequence will be paired with it. The process is symmetrical for the left and right sequences, so let's just consider a case where the items of only one sequence have windows.
In the first example, the windows in the left sequence never close, while the windows in the right sequence are 0.
Observable<String> left =
Observable.interval(100, TimeUnit.MILLISECONDS)
.map(i -> "L" + i);
Observable<String> right =
Observable.interval(200, TimeUnit.MILLISECONDS)
.map(i -> "R" + i);
left
.join(
right,
i -> Observable.never(),
i -> Observable.timer(0, TimeUnit.MILLISECONDS),
(l,r) -> l + " - " + r
)
.take(10)
.subscribe(System.out::println);L0 - R0
L1 - R0
L0 - R1
L1 - R1
L2 - R1
L3 - R1
L0 - R2
L1 - R2
L2 - R2
L3 - R2
When a window for a left value never ends, what that means is that every value from the left sequence will be paired with every value that comes after it from the right sequence. Because here the right sequence has half the frequence of the left sequence, between two right values, two more windows have opened on the left. The first right value is paired with the first 2 left values, the second right value is paired with the first 4 left values, the third with 6 and so on.
Lets change the example and see what happens when left and right emit every 100ms and left windows close after 150ms. What happens then is that every left window remains open long enough to catch two right values: one that is emitted at the same time and another after 100ms.
Observable<String> left =
Observable.interval(100, TimeUnit.MILLISECONDS)
.map(i -> "L" + i);
Observable<String> right =
Observable.interval(100, TimeUnit.MILLISECONDS)
.map(i -> "R" + i);
left
.join(
right,
i -> Observable.timer(150, TimeUnit.MILLISECONDS),
i -> Observable.timer(0, TimeUnit.MILLISECONDS),
(l,r) -> l + " - " + r
)
.take(10)
.subscribe(System.out::println);L0 - R0
L0 - R1
L1 - R1
L1 - R2
L2 - R2
L2 - R3
L3 - R3
L3 - R4
L4 - R4
L4 - R5
Both sequences have windows. Every value of a sequence is paired with:
- Any older value of the opposite sequence, if the window of the older value is still open
- Any newer value of the opposite sequence, if the window for this value is still open
As soon as it detected a pair, join passed the two values to the result selector and emitted the result. groupJoin takes it one step further. Let's start with the signature
public final <T2,D1,D2,R> Observable<R> groupJoin(
Observable<T2> right,
Func1<? super T,? extends Observable<D1>> leftDuration,
Func1<? super T2,? extends Observable<D2>> rightDuration,
Func2<? super T,? super Observable<T2>,? extends R> resultSelector)The signature is the same as join exept for the resultSelector. Now the result selector takes an item from the left sequence and an observable of values from the right sequence. That observable will emit every right value that the left value is paired with. The pairing in groupJoin is symmetrical, just like join, but the contruction of results isn't. An alternative implementation of this method could have been if the argument of the resultSelect was a single GroupedObservable, where the left value is the key and the right values are being emitted.
Lets revisit our example from join where the windows on the left never close.
Observable<String> left =
Observable.interval(100, TimeUnit.MILLISECONDS)
.map(i -> "L" + i)
.take(6);
Observable<String> right =
Observable.interval(200, TimeUnit.MILLISECONDS)
.map(i -> "R" + i)
.take(3);
left
.groupJoin(
right,
i -> Observable.never(),
i -> Observable.timer(0, TimeUnit.MILLISECONDS),
(l, rs) -> rs.toList().subscribe(list -> System.out.println(l + ": " + list))
)
.subscribe();L0: [R0, R1, R2]
L1: [R0, R1, R2]
L2: [R1, R2]
L3: [R1, R2]
L4: [R2]
L5: [R2]
In the result selector, we have a left value and an observable of right values. We used that to print all the values from the right that were paired to each left value. If you go back to the example which used join, you'll see that the pairs are the same. What is changes is how they are made available to us in the resultSelector.
You can implement join with groupJoin and flatMap
.join(
right,
leftDuration
rightDuration,
(l,r) -> joinResultSelector(l,r)
)
// same as
.groupJoin(
right,
leftDuration
rightDuration,
(l, rs) -> rs.map(r -> joinResultSelector(l,r))
)
.flatMap(i -> i)You can also implement groupJoin with join and groupBy. Doing so would require you to contruct tuples as a result and do groupBy on the left part of the tuple. We will leave the code for this example to the reader's appetite for hands-on.
Rx leads events from one end of a pipeline to the other. The actions which take place on each end can be very dissimilar. What happens when the producer and the consumer require different amounts of time to process a value? In a synchronous model, this question isn't an issue. Consider the following example:
// Produce
Observable<Integer> producer = Observable.create(o -> {
o.onNext(1);
o.onNext(2);
o.onCompleted();
});
// Consume
producer.subscribe(i -> {
try {
Thread.sleep(1000);
System.out.println(i);
} catch (Exception e) { }
});Here, the producer has its values ready and can emit them with no delay. The consumer is very slow by comparison, but this isn't going to cause problems, because the synchronous nature of the code above automatically regulates the rates of the producer and consumer. When o.onNext(1); is called, execution for the producer is blocked until the entire Rx chain completes. Only when that expression returns can the execution proceed to o.onNext(2);.
This works like that only for synchronous execution. It is very common for the producer and the consumer to be asynchronous. So, what happens when a producer and a consumer operate asynchronously at different speeds?
Let's first consider the traditional pull-based model, such as an iterator. In a pull-based model, the consumer requests the values. If the producer is slower, the consumer will block on request and resume when the next value arrives. If the procuder is faster, then the producer will have idle time waiting for the consumer to request the next value.
Rx push-based, not pull-based. In Rx, it is the producer that pushes values to the consumer when the values are ready. If the producer is slower, then the consumer will have idle time waiting for the next value to arrive. If the producer is faster, without any provisions, it will keep force-feeding data to consumer without ever knowing about the consumer's difficulties.
Observable.interval(1, TimeUnit.MILLISECONDS)
.observeOn(Schedulers.newThread())
.subscribe(
i -> {
System.out.println(i);
try {
Thread.sleep(100);
} catch (Exception e) { }
},
System.out::println);0
1
rx.exceptions.MissingBackpressureException
Here, the MissingBackpressureException is letting us know that the producer is too fast and the operators that we chained together can't deal with it.
Some of the operators we've seen in previous chapters can help the consumer lessen the stress caused by too much input.
The [sample](/Part 3 - Taming the sequence/5. Time-shifted sequences.md#sample) operator naturally allows you to specify a maximum rate of input, leaving out any excess data.
Observable.interval(1, TimeUnit.MILLISECONDS)
.observeOn(Schedulers.newThread())
.sample(100, TimeUnit.MILLISECONDS)
.subscribe(
i -> {
System.out.println(i);
try {
Thread.sleep(100);
} catch (Exception e) { }
},
System.out::println);82
182
283
...
The are similar operators that can serve the same purpose.
- The [throttle](/Part 3 - Taming the sequence/5. Time-shifted sequences.md#throttling) family of operators also filters on rate, but allows you to speficy in a diffent way which element to let through when stressed.
- [Debounce](/Part 3 - Taming the sequence/5. Time-shifted sequences.md#debouncing) does not cut the rate to a fixed maximum. Instead, it will completely remove every burst of information and replace it with a single value.
Instead of sampling the data, you can use buffer and window to collect overflowing data while the consumer is busy. This is useful if processing items in batches is faster. Alternatively, you can inspect the buffer to manually decide how many and which of the buffered items to process.
In the example that we saw previously, the consumer processes single items and bulks at practically the same speed. Here we slowed down the producer to make the batches fit a line, but the principle remains the same.
Observable.interval(10, TimeUnit.MILLISECONDS)
.observeOn(Schedulers.newThread())
.buffer(100, TimeUnit.MILLISECONDS)
.subscribe(
i -> {
System.out.println(i);
try {
Thread.sleep(100);
} catch (Exception e) { }
},
System.out::println);[0, 1, 2, 3, 4, 5, 6, 7]
[8, 9, 10, 11, 12, 13, 14, 15, 16, 17]
[18, 19, 20, 21, 22, 23, 24, 25, 26, 27]
...
The above remedies are legitimate solutions to the problem. However, they aren't always the best way to deal with an overproducing observable. Sometimes the problem can be better handled on the side of the producer. Backpressure is a way for the pipeline to resist the emission of values.
Back pressure refers to pressure opposed to the desired flow of a fluid in a confined place such as a pipe. It is often caused by obstructions or tight bends in the confinement vessel along which it is moving, such as piping or air vents. - Wikipedia
RxJava has implemented a way for a subscriber to regulate the rate of an observable. The Subscriber has a request(n) method, with which it notifies the observable that it is ready to accept n more values. By calling request on the onStart method of your Subscriber, you establish reactive pull backpressure. This isn't a pull in the sense of a pull-based model: it doesn't return any values and will not block if values are not ready. Instead, it merely notifies the observable of how many values the Subscriber is ready to accept and to hold the rest. Subsequent calls to request will allow more values through.
This is a Subscriber that takes values one at a time:
class MySubscriber extends Subscriber<T> {
@Override
public void onStart() {
request(1);
}
@Override
public void onCompleted() {
...
}
@Override
public void onError(Throwable e) {
...
}
@Override
public void onNext(T n) {
...
request(1);
}
}The request(1) in onStart establishes backpressure and informs the observable that it should only emit the first value. After processing the value in onNext, we request the next item to be sent, if and when it is available. Calling request(Long.MAX_VALUE) disables backpressure.
Back when we were discussing the doOn_ operators for side effects, we left out doOnRequested.
public final Observable<T> doOnRequest(Action1<java.lang.Long> onRequest)The doOnRequested meta-event happens when a subscriber requests for more items. The value supplied to the action is the number of items requested.
At this moment, doOnRequest is in beta. In this book, we have been avoiding beta operators. We're making an exception here, because it enables us to peek into stable backpressure functionality that is otherwise hidden. Let's see what happens in a simple observable:
Observable.range(0, 3)
.doOnRequest(i -> System.out.println("Requested " + i))
.subscribe(System.out::println);Requested 9223372036854775807
0
1
2
We see that subscribe requests the maximum number of items from the beginning. This means that subscribe doesn't resist values at all. Subscribe will only use backpressure if we provide a subscriber that implements backpressure. Here is a complete example for a subscriber, which will allow us to control backpressure from the outside.
public class ControlledPullSubscriber<T> extends Subscriber<T> {
private final Action1<T> onNextAction;
private final Action1<Throwable> onErrorAction;
private final Action0 onCompletedAction;
public ControlledPullSubscriber(
Action1<T> onNextAction,
Action1<Throwable> onErrorAction,
Action0 onCompletedAction) {
this.onNextAction = onNextAction;
this.onErrorAction = onErrorAction;
this.onCompletedAction = onCompletedAction;
}
public ControlledPullSubscriber(
Action1<T> onNextAction,
Action1<Throwable> onErrorAction) {
this(onNextAction, onErrorAction, () -> {});
}
public ControlledPullSubscriber(Action1<T> onNextAction) {
this(onNextAction, e -> {}, () -> {});
}
@Override
public void onStart() {
request(0);
}
@Override
public void onCompleted() {
onCompletedAction.call();
}
@Override
public void onError(Throwable e) {
onErrorAction.call(e);
}
@Override
public void onNext(T t) {
onNextAction.call(t);
}
public void requestMore(int n) {
request(n);
}
}This simple implementation will not request values unless we manually make it do so with requestMore.
ControlledPullSubscriber<Integer> puller =
new ControlledPullSubscriber<Integer>(System.out::println);
Observable.range(0, 3)
.doOnRequest(i -> System.out.println("Requested " + i))
.subscribe(puller);
puller.requestMore(2);
puller.requestMore(1);Requested 0
Requested 2
0
1
Requested 1
2
First we requested no emissions (our ControlledPullSubscriber does this in onStart). Then we requested 2 and we got 2 values, then we requested 1 and we got 1.
Rx operators that use queues and buffers internally should use backpressure to avoid storing an infinite amount of values. Large-scale buffering should be left to operators that explicitly serve this purpose, such as cache, buffer etc. An example of an operator that needs to buffer items is zip: the first observable might emit two or more values before the second observable emits its next value. Such small asymmetries are expected even when the two sequences are supposed to have the same frequency. Needing to buffer a couple of items shouldn't cause the operator to fail. For that reason, zip has a small buffer of 128 items.
Observable.range(0, 300)
.doOnRequest(i -> System.out.println("Requested " + i))
.zipWith(
Observable.range(10, 300),
(i1, i2) -> i1 + " - " + i2)
.take(300)
.subscribe();Requested 128
Requested 90
Requested 90
Requested 90
The zip operator starts by requesting enough items to fill its buffer, and requests more when it consumes them. The details of how many items zip requests isn't interesting. What the reader should take away is the realisation that some buffering and backpressure exist in Rx whether the developer requests for it or not. This gives an Rx pipeline some flexibility, where you might expect none. It might trick you into thinking that your code is solid, by silently saving small tests from failing, but you're not safe until you have explicitly declared behaviour with regard to backpressure.
Many Rx operators use backpressure internally to avoid overfilling their internal queues. This way, the problem of a slow consumer is propagated backwards in the chain of operators: if an operator stops accepting values, then the previous operator will fill its buffers until it stops accepting values too, and so on. Backpressure doesn't make the problem go away. It merely moves it where it may be handled better. We still need to decide what to do with the values of an overproducing observable.
There are Rx operators that declare how you want to deal with situations where a subscriber cannot accept the values that are being emitted.
The onBackpressureBuffer operator with cause every value that can't be consumed to be stored until the observer can consume it.
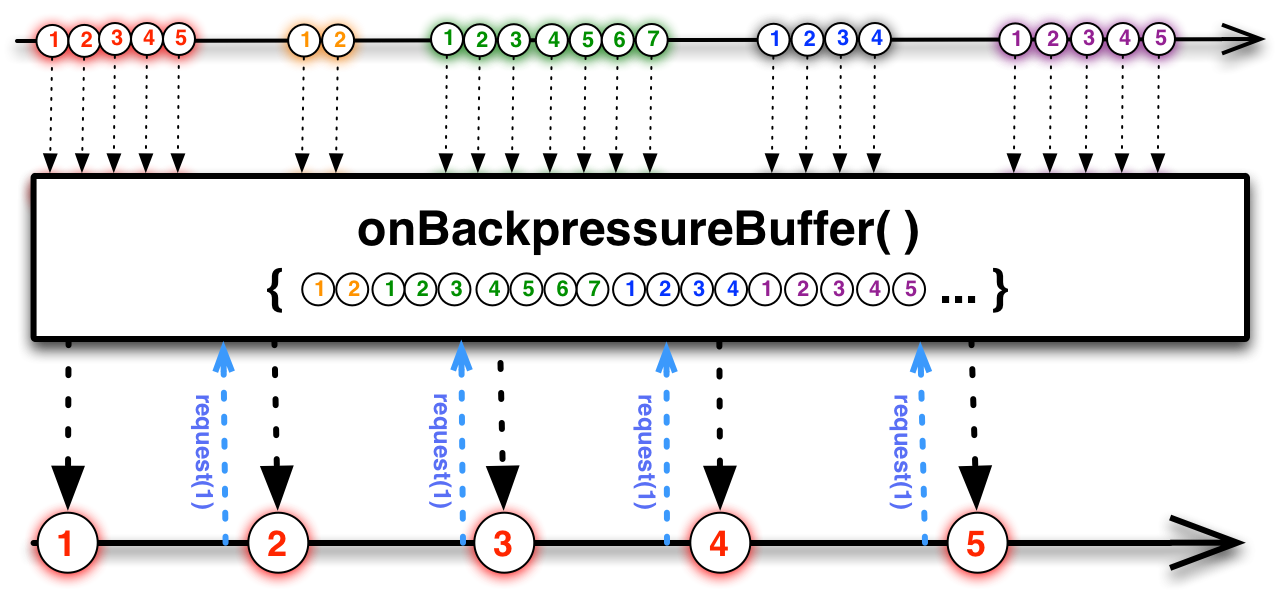
You can have a buffer of infinite size or a buffer with a maximum capacity. If the buffer overflows, the observable will fail.
Observable.interval(1, TimeUnit.MILLISECONDS)
.onBackpressureBuffer(1000)
.observeOn(Schedulers.newThread())
.subscribe(
i -> {
System.out.println(i);
try {
Thread.sleep(100);
} catch (Exception e) { }
},
System.out::println
);0
1
2
3
4
5
6
7
8
9
10
11
rx.exceptions.MissingBackpressureException: Overflowed buffer of 1000
What happens here is that the producer is 100 times faster than the consumer. We try to deal with that by buffering up to 1000 items. It is easy to calculate that, by the time that the consumer consumes the 11th item, the producer has produced 1100 items, well over our buffer's capacity. The sequence then fails, as it can't deal with the backpressure.
The onBackpressureDrop operator discards items if they can't be received.
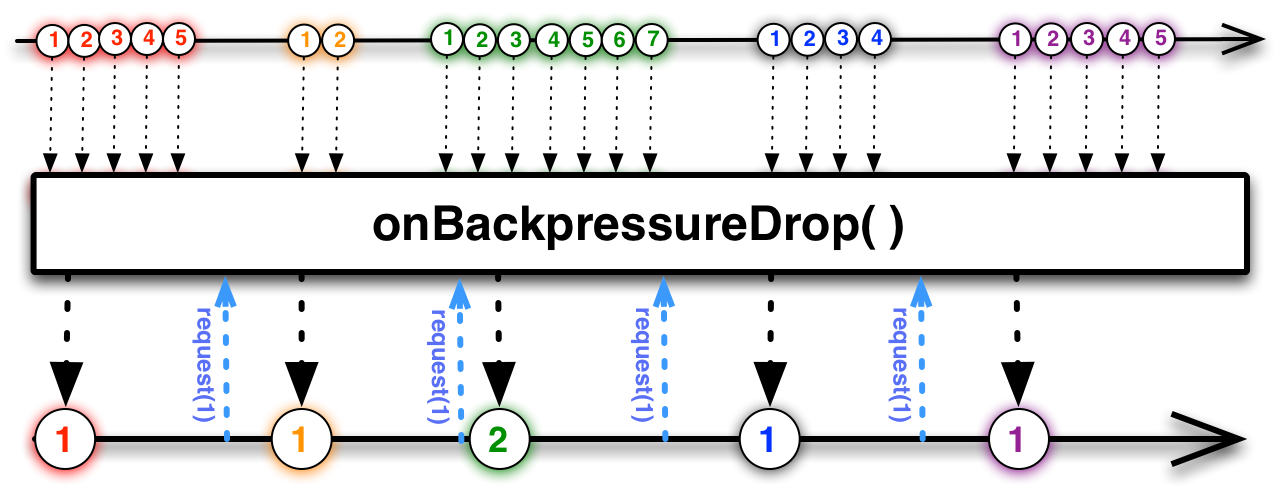
Observable.interval(1, TimeUnit.MILLISECONDS)
.onBackpressureDrop()
.observeOn(Schedulers.newThread())
.subscribe(
i -> {
System.out.println(i);
try {
Thread.sleep(100);
} catch (Exception e) { }
},
System.out::println);0
1
2
...
126
127
12861
12862
...
What we see here is that the first 128 items where consumed normally, but then we jumped forward. The items inbetween were dropped by onBackPressureDrop. Even though we did not request it, the first 128 items were still buffered, since observeOn uses a small buffer between switching threads.