If you are very familiar with local LLM, welcome to join our discussion! Discord: https://discord.gg/4AQuf2ctav
2024-2-24: Version 0.2 adds an introduction to the Gemma and Llava models, an introduction to the GPT4ALL software, and an introduction to LLM selection.
2024-2-17: Version 0.1.
LLMs, or Large Language Models, are advanced models built based on artificial intelligence and machine learning techniques to understand and generate natural language text. These models are able to perform a variety of language-related tasks by analyzing and learning from massive amounts of textual data and mastering the complex properties of language such as structure, syntax, semantics, and context. The capabilities of LLMs include, but are not limited to, text generation, question and answer, text summarization, translation, and sentiment analysis.
LLMs such as GPT, LLama, Mistral series, etc., enable these models to capture the deeper associations and meanings between texts by means of technical architectures for deep learning, such as Transformer. The models are first pre-trained on a wide range of datasets to learn the general features and patterns of the language, and can then be fine-tuned for specific tasks or domains to improve their performance in particular applications.
The pre-training phase equips the LLMs with a large amount of linguistic and world knowledge, while the fine-tuning phase enables the models to achieve higher performance on specific tasks. This training approach gives LLMs the flexibility and adaptability to handle a wide range of linguistic tasks, enabling them to provide accurate and diverse information and services to users.
LLMs: Through a process of deep learning pre-training and fine-tuning, LLMs acquire extensive knowledge gained from massive amounts of Internet text, enabling them to understand and generate a wide range of content types, including text, images, audio, video, and 3D material. This ability allows LLMs to demonstrate superior diverse information processing capabilities when dealing with a variety of topics and knowledge domains.
Applications: Applications, on the other hand, are designed to meet specific needs, such as social interaction, news access, e-commerce, etc., and are typically less open and diverse in content than LLMs. each application is built around its core functionality, providing a user interface and experience optimization, but the range of information and services that the user accesses is limited by the purpose for which the application was designed and the functionality for which it was defined.
LLMs: LLMs are capable of generating text on a wide range of topics and tasks by analyzing and learning from massive textual data, and mastering the structure, semantics, and context of language. However, the accuracy of these models not only relies on rich and diverse training data and advanced model architectures, but also faces the challenges of update lag and "illusion" problems. When dealing with specialized or up-to-date information, LLMs may produce unsubstantiated content, especially when there is a lack of sufficient context or when the information is rapidly changing. Therefore, when using information generated by these models for decision-making and analysis, additional validation is recommended to improve accuracy and reliability.
Applications: The accuracy of information in applications is highly dependent on the curation and management of content, which often involves the active selection and provision of specialized individuals or teams. For example, in specialized domains such as healthcare and financial investment apps, developers and specialists invest significant resources to ensure that the information provided is accurate, reliable, and up-to-date. While this approach improves the quality of information within a specific domain, it also means that the scope of information that users are exposed to is limited by the breadth of knowledge and choices made by these specialized teams. As a result, while applications may provide highly accurate information within a given domain, their content coverage and perspective is constrained by human choice and the limitations of specialized domains.
LLMs: LLMs are less predictable because the answers they generate may vary depending on the diversity of the training data and the complexity of the model's understanding. Users may receive multiple possible answers without explicit instructions, or unexpected responses in a given context, or worse, fail to proceed to the next round of interaction. This uncertainty stems from the design and operational mechanisms of the model, and is especially evident when dealing with fuzzy queries or complex problems.
Applications: Applications typically provide a higher degree of predictability because they are designed to meet specific needs and purposes, and their functionality, operational flow, and user interface are designed to provide a consistent and predictable user experience. Applications reduce uncertainty during operation through explicit user instructions and fixed interaction logic, allowing users to anticipate what their actions will result in.
LLMs: LLMs currently have a large number of usability issues, including and not limited to the following, in addition to the phantom issues mentioned above:
- Answer to the wrong question: LLMs, when dealing with complex or ambiguous queries, may sometimes provide answers that do not match the user's expectations. This phenomenon is usually due to the model's insufficient understanding of the question or misinterpretation of the intent of the query. Although model training covers a large amount of data to improve understanding of natural language, difficulties may still be encountered in understanding context-specific or domain-specific language.
- Response time: Users may encounter long response times when interacting with LLMs, especially when performing complex generative tasks or processing a large number of data requests. This not only affects user experience but also limits the application of LLMs in real-time interaction scenarios. The prolonged response time is mainly due to the high computational demands of the model and the high server load.
- Processing capacity constraints: Despite the theoretical capabilities of LLMs, in practice, their processing capacity is constrained by hardware resources, algorithmic efficiency and availability. For example, large-scale concurrent requests may lead to performance degradation, especially in resource-constrained environments. In addition, LLMs may be less efficient and accurate when processing long texts or complex tasks that require deeper understanding.
- Limitations of self-updating: LLMs are usually pre-trained on fixed datasets, which means that their knowledge after training is static. Although it is possible to update the model by periodic re-training, this approach may not be sufficient to capture the latest information or trends in real-time, thus limiting to some extent the effectiveness of the model's application in fast-changing domains (e.g., news, technology, etc.).
Applications: Thanks to a long history of accumulation and innovation in the field of software development and design, most applications have achieved a high degree of user-friendliness and stability. Designers and developers are able to build applications relying on proven platforms and frameworks, while widely adopted user experience design principles ensure that applications meet users' needs and expectations. In addition, through continuous user feedback and iterative development, apps are able to fix bugs and optimize performance in a timely manner, thus improving user satisfaction and overall app usability.
- Flexibility and adaptability: Open source LLMs provide models of different sizes, enabling them to be deployed on a wide range of devices, from small devices such as Raspberry Pi's and cell phones, to personal computers and even server clusters.
- Reducing dependencies: The use of open source LLMs can reduce dependency on specific vendors, such as OpenAI, to some extent. This not only increases the accessibility of the technology, but also promotes innovation and autonomy.
- Privacy protection: Open source LLMs allow users to deploy and use models in local or private cloud environments, which helps to minimize the risk of data leakage and provides a higher level of security for applications that handle sensitive or private data.
- Customizability: Open-source models can be fine-tuned to meet specific needs, enabling users to optimize the model for a particular task or data set, thus improving its effectiveness and accuracy.
- Community support: Open source LLMs often benefit from the support of an active developer and research community. Such communities not only provide technical support and shared solutions, but also facilitate rapid innovation of new features, optimizations and application scenarios.
- High Transparency: The open source model provides visibility into the algorithms and data processing flows, enabling technical users and developers to review how the model works.
- Limitations of underlying models and datasets: The upper and lower limits of performance of open source LLMs depend heavily on the underlying models and datasets behind them.The models provided by vendors such as Meta, Mistral, etc., while powerful, may not be suitable for all types of tasks, especially in those areas that require highly specialized knowledge.
- Resource and technical thresholds: While open source LLMs offer great flexibility, deploying and maintaining these models requires considerable hardware resources and technical expertise. This can be a challenge for individuals or small teams that lack these resources or technical skills.
- Lack of harmonized standards: There is a wide variety of LLMs in the open source community, which may use different architectures, training datasets and interfaces. While this diversity fosters innovation, it also creates complexity for users to select appropriate models and tools.
- Stability issues: Locally deployed open-source models may encounter hardware limitations and software compatibility issues, resulting in unstable operation. This instability may affect the reliability of the model and the user experience.
- Processing speed issues: Model inference can be very slow when using only the CPU, especially when processing large models or complex tasks. This not only extends the processing time, but may also limit the use of the model in real-time or application scenarios that require high responsiveness.
- Output quality fluctuations and controllability of content generation: Open-source LLMs may experience fluctuations in the quality of output when dealing with specific language types or complex, borderline cases, sometimes generating irrelevant or meaningless responses. At the same time, when sensitive or demanding highly accurate content needs to be generated, these models may have difficulty in precisely controlling the quality and direction of the output, especially in the absence of careful supervision and customized fine-tuning, which may result in substandard output content or failure to meet specific expectations.
LLLMs in this context refers specifically to open source models such as Llama, Mistral, GLM, etc.
Online LLMs: On-line deployed LLMs provide instant access and high availability thanks to the pre-configured LLM and RAG (Retrieval Augmented Generative Model) environments on cloud servers by SaaS (Software as a Service) providers. Users don't have to worry about hardware configuration or installation process and can start using these models immediately for text generation, Q&A and other tasks. This deployment method is particularly suitable for users without specialized technical backgrounds or for organizations that need to deploy solutions quickly.
Local LLMs: Locally deployed LLMs require a certain level of technical knowledge on the part of the user, including the ability to install, configure, and optimize the model.The inference performance and speed of LLMs is directly limited by an individual's or an organization's hardware configurations, such as processor, memory, and storage space. Additionally, while local deployment provides users with greater control, it lacks the encapsulation of advanced functionality like RAG and users may need to perform additional development work on their own.
Online LLMs: For individual users, the on-demand billing model of the online LLMs service offers great flexibility and the advantage of a lower entry barrier. Individual users can choose the appropriate service plan according to their actual needs and frequency of use, avoiding a high initial investment. This is especially beneficial for users who only occasionally need to use the language model for specific projects or research. However, if individual users frequently use these services for large amounts of data processing, the costs may accumulate gradually, especially when using advanced features or large-scale datasets. For those individual users who need to use language modeling services on a long-term, ongoing basis, it is important to periodically evaluate the total cost.
Local LLMs: For individual users, choosing to deploy LLMs locally means a one-time investment in high-performance computing hardware. While this may increase the financial cost for some users, it provides long-term cost-effectiveness, especially for those with sustained high-intensity usage requirements. Local deployment avoids duplicate service costs, and once the equipment is in use, the additional operating costs are relatively low, except for possible maintenance and upgrades. In addition, individual users are able to gain greater control and customization through local deployment, which may be particularly valuable to researchers or developers. However, it is important to note that local deployment also means that users must have some technical skills to configure and maintain the system.
Online LLMs: When using online LLMs, user data needs to be transferred to a cloud server for processing, which triggers considerations of data privacy and security. While many SaaS providers adopt strong data protection measures and promise to protect user data from misuse or disclosure, the process still requires a foundation of user trust in the provider's data handling and privacy policies.
Local LLMs: Compared to the online model, locally deployed LLMs provide a higher level of security in terms of privacy protection, mainly because data processing is done on the user's private devices or internal servers, eliminating the need for data to be outsourced. This deployment method gives the user much more control over the data and reduces the risk of data leakage.
Online LLMs: Using online services, users rely on the service provider to ensure the availability and performance of the service. This model simplifies the usage process by allowing the user to focus on the application of the model rather than its maintenance. However, it also means that the user's direct control is limited in terms of system prompting, context management, and model response customization. While online services offer some degree of configuration options, they may not be sufficient to meet all specific needs, especially in scenarios that require highly customized output.
Local LLMs: Locally deployed models allow users to enjoy a higher level of control, including management of data processing, model configuration and system security. Users can deeply customize system prompts and contextual processing policies as needed, which can be important in specific application scenarios. However, this increased control and flexibility comes with higher technical requirements and possible initial setup complexity. While local deployment allows for a high degree of customization, it also requires users to have the appropriate technical skills to implement these customized solutions.
Online LLMs: Online LLMs services are provided by third parties and may raise transparency concerns for some users in terms of how the models work and how the data is processed. Service providers typically strive to provide documentation on model training, data processing, and privacy policies, among other things, with the intent of increasing transparency. However, due to commercial confidentiality and operational complexity, users may not have access to full details of a model's internal mechanisms. This requires users to trust the service provider and rely on the information and controls it provides for data security and privacy.
Local LLMs: Locally deployed LLMs provide a higher degree of transparency by allowing users direct access to the model. Users can inspect, modify and optimize the models themselves, thereby gaining a deeper understanding of how they work and adapting their behavior to their needs. This direct control ensures complete understanding of the model and the ability to customize it, and is particularly suited to organizations that have high requirements for data security, privacy protection, or need to comply with specific regulations. However, it also means greater responsibility on the part of the user, including maintaining the transparency of the model and ensuring its compliance with ethical and legal standards.
Online LLMs: Unavailable
Local LLMs: It works
When using online LLMs, we face challenges on multiple levels, and these issues, ranging from personal data privacy to model performance and cost to content integrity and the selection and application of retrieval-enhanced generative modeling (RAG) strategies, constitute a set of critical issues that require the joint attention of users and service providers.
The privacy of personal data becomes a significant point of concern during the use of online LLMs. Users' interactions with LLMs, as well as uploaded documents, may be collected by service providers for model fine-tuning and optimization.
Service providers may use LLMs of different sizes in order to balance cost and performance. smaller models (e.g., 7B or 13B parameters), while reducing computational resource consumption and improving response speed, may not have sufficient inference power to handle complex queries or generate high-quality text. It may be difficult for users to be informed of the size and performance of the model used when choosing a service, leading to discrepancies between the results and expectations in real-world applications. This opacity may affect users' experience and satisfaction.
For processing long documents, there is a question of whether LLM is able to capture and understand the entire document content in its entirety. Due to technical limitations, some services may only process a part of the document, e.g., analyzing only the first few hundred words. This processing may cause the LLM to miss key information, which affects the accuracy and relevance of the generated content. Users may not be able to know whether their submission has been processed in its entirety, which in turn raises questions about the reliability of the results.
The cutting methods and callback strategies of RAGs directly affect the effectiveness of LLMs, especially when dealing with queries that require extensive knowledge retrieval. Different cutting methods and callback strategies determine the way LLM accesses and integrates information, which in turn affects the accuracy and completeness of the final generated answer. If these strategies are not properly selected or optimized, the LLM may not be able to see or utilize the relevant information to generate the best answer. Users typically have no control over or knowledge of these internal processing details, which increases outcome uncertainty.
- The theoretical scenarios are labeled here because there are more practical problems with current open source LLMs, but these problems will be gradually overcome. *
If you need to analyze and process a large number of documents every day, and a document requires about 4000 Token, LLM output 400 Token a round, then 10 rounds of interaction down to at least 5W Token, 20 that consumes 100W Token; if you need to cross-comparison and in-depth analysis of previous documents, assuming that there is a library of 1000 articles, that One day needs to consume 1 billion Token (provided that there is no other technology to add).
Theoretical Scenarios: Personal Knowledge Base Scenario, Multi-Document Automated Analysis Scenario ......
In the area of multitasking and multiple information processing, there is a great deal of complexity in the operations and processing logic involved, especially for activities performed on a computer. These activities are more than simply executing commands; they involve judging the user's intent, transferring and interacting between data, and how to respond based on the current context. The Token consumption involved here is mainly due to the fact that these operations require a lot of computational resources to process and respond to the user's needs.
In this process, the system prompts required at each step, the logical handling of contextual dialogues, etc., need to be personalized and differentiated according to the specific situation. In this case, "thousand faces" means that the system must be able to provide customized services according to the specific needs and context of each user. This is fundamentally different from a "thousand faces" based on recommendation algorithms. The essential difference is:
- Dynamic versus static processing: Processing in the area of multitasking and multiple information processing is dynamic, relying on the current context and the immediate needs of the user, whereas processing based on recommendation algorithms is more static, relying on the user's historical data.
2.** Degree of personalization:** Although both pursue "thousands of people, thousands of faces", multitasking is more focused on the precise response to user needs in a specific context, and recommendation algorithms are more based on historical data or general predictions based on the data of similar users. - Interactivity: Multitasking involves real-time interaction with the user, whereas recommendation algorithms are more of a one-way content push.
- Note that this essential difference dictates that native LLMs are the only solution to multiple information processing or even multitasking, but it is possible that it is a closed-source LLM.
Theoretical scenarios: report writing scenarios, interaction scenarios dependent on operating system capabilities ......
When exploring personalization domains such as goal setting, diary writing, financial management, emotional communication, etc., we have to face a real problem: these activities often involve the processing of a large amount of personal data, which contains sensitive information about the user. For example, in diary writing, users may record their private thoughts and feelings; in financial management, users need to process their income, expenditure and other financial information; in emotional communication, users may share their psychological state and emotional experience. The data generated and processed in these activities are highly sensitive personal information, which, once leaked, may cause irreparable harm to users. In such a context, the application of local open source LLMs becomes particularly important and necessary.
Theoretical Scenarios: Personal Goal Setting and Tracking Scenarios, Private Emotional Communication Scenarios, Journal Writing and Emotional Analysis Scenarios ......
In the current technological environment, online LLMs have to face various legal, regulatory and ethical constraints while providing services. These constraints are often enforced by adding "guardrails" to prevent models from generating inappropriate content, such as misleading information, invasion of privacy, and hate speech. However, these guardrails limit the functionality of LLMs and the complete use of knowledge to a certain extent, especially in application scenarios that require a high degree of freedom, such as role-playing, creative writing, etc. In these scenarios, content filtering can be used to prevent the model from generating inappropriate content. In these scenarios, content filtering and restriction may hinder creativity and deepen the user experience.
In this context, locally deployed LLMs offer a solution. With local deployment, users can adjust the criteria for content filtering according to their needs and scope of responsibility, avoiding legal risks while retaining a higher degree of creative freedom and personalized service. This flexibility is particularly important in certain business scenarios, providing users with a richer and deeper interactive experience.
Theoretical Scenarios: Counseling Scenarios, Role Play Scenarios in Selected Areas
Thanks to the open source LLMs provided by Meta, Mistral and many other developers, as well as the open source project Llama.cpp, we can now use open source LLMs at a very low cost, and I'd like to recommend some out-of-the-box backends and clients to help you start your journey with local LLMs.
We recommend using the GGUF version of the quantization model as it can be used alone or in a mix of CPU and consumer GPU environments. Feel free to share with us models that you have used well.
Introduction: Mixtral 8x7B is a high quality Sparse Model of Expertise (SMoE) blend with open weights. We recommend using the Q3 and higher versions of the quantization model.
Official website: https://mistral.ai/
Model size: 8x7B
Related languages: Multi-language
Context length: 32K
Applicable to: Computers with NVIDIA of 24GB VRAM or above, M1/M2/M3 Macs with 32GB of RAM or above
Downloaded at:
https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/tree/main
https://modelscope.cn/models/limoncc/Mixtral-8x7B-Instruct-v0.1-GGUF/files
Introduction: Qwen1.5-14B is a 14 billion parameter scale model of the Tongyi Qianwen large model series developed by Aliyun. We recommend using Q2 and above quantitative models.
Official website: https://github.com/QwenLM/Qwen1.5
Model size: 14B
Related languages: English, Chinese
Context length: 32K
Applicable to: Computers with NVIDIA of 12GB VRAM or above, M1/M2/M3 Macs with 16GB of RAM or above
Downloaded at:
https://huggingface.co/Qwen/Qwen1.5-14B-Chat-GGUF
https://modelscope.cn/models/qwen/Qwen1.5-14B-Chat-GGUF/summary
Introduction: Qwen1.5-7B is a 7 billion parameter scale model of the Tongyi Qianwen large model series developed by Aliyun. We recommend using Q2 and above quantitative models.
Official website: https://github.com/QwenLM/Qwen1.5
Model size: 7B
Related languages: English, Chinese
Context length: 32K
Applicable to: It is suitable for most computers, but it is recommended for computers with NVIDIA graphics cards of 12GB of video memory and above, and M1/M2/M3 Macs with 16GB of memory and above.
Downloaded at:
https://huggingface.co/Qwen/Qwen1.5-7B-Chat-GGUF
https://modelscope.cn/models/qwen/Qwen1.5-7B-Chat-GGUF/summary
Introduction: OpenChat's January '24 release, fine-tuned from Mistral 7B via C-RLFT, has better performance in inference and bilingual English/Chinese Q&A. We recommend using Q4 and above quantitative models.
Official website: https://github.com/imoneoi/openchat
Model size: 7B
Related languages: Chinese, English
Context length: 8K
Applicable to: It is suitable for most computers, but it is recommended for computers with NVIDIA graphics cards of 12GB of video memory and above, and M1/M2/M3 Macs with 16GB of memory and above.
Downloaded at:
https://huggingface.co/TheBloke/openchat-3.5-0106-GGUF
https://modelscope.cn/models/fivetwin/openchat-3.5-0106-GGUF/files
Introduction: OpenChat's December '23 release, fine-tuned from Mistral 7B via C-RLFT, has better performance in inference and bilingual English/Chinese Q&A. We recommend using Q4 and above quantitative models.
Official website: https://github.com/imoneoi/openchat
Model size: 7B
Related languages: Chinese, English
Context length: 16K
Applicable to: It is suitable for most computers, but it is recommended for computers with NVIDIA graphics cards of 12GB of video memory and above, and M1/M2/M3 Macs with 16GB of memory and above.
Downloaded at:
https://huggingface.co/TheBloke/openchat_3.5-16k-GGUF/tree/main
https://modelscope.cn/models/limoncc/OPENCHAT3.5-16K-GGUF/files
Introduction: LLaVA is a multimodal model for chatbots with computer vision and natural processing capabilities that can analyze images and provide feedback with text.
Model size: 7B
Related languages: English
Context length: 32K
Applicable to: It is suitable for most computers, but it is recommended for computers with NVIDIA graphics cards of 12GB of video memory and above, and M1/M2/M3 Macs with 16GB of memory and above.
Downloaded at:
https://huggingface.co/cmp-nct/llava-1.6-gguf/
https://modelscope.cn/models/mirror013/llava-1.6-mistral-7b-gguf/summary
Introduction: Gemma is a family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights, pre-trained variants, and instruction-tuned variants.
Official website: https://huggingface.co/google/gemma-7b-it
Model size: 7B
Related languages: Multi-language
Context length: 8K
Applicable to: It is suitable for most computers, but it is recommended for computers with NVIDIA graphics cards of 12GB of video memory and above, and M1/M2/M3 Macs with 16GB of memory and above.
Note: There will be bugs when using quantitative models below Q8 on llama.cpp.
Downloaded at:
https://huggingface.co/sayhan/gemma-7b-it-GGUF-quantized
https://modelscope.cn/models/fivetwin/gemma-7b-it-gguf/summary
Introduction: Gemma is a family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights, pre-trained variants, and instruction-tuned variants.
Official website: https://huggingface.co/google/gemma-2b-it
Model size: 2B
Related languages: Multi-language
Context length: 8K
Applicable to: It is suitable for most computers.
Note: There will be bugs when using quantitative models below Q8 on llama.cpp.
Downloaded at:
https://huggingface.co/lmstudio-ai/gemma-2b-it-GGUF
https://modelscope.cn/models/CruiseTian/gemma-2b-gguf-quantized/summary

Introduction: LM Studio develops a set of friendly user interfaces based on LLama.cpp, supports installation and use on Windows, Mac and Linux systems, provides models in multiple languages, and offers features such as model search, download and chat.
Official website and download url: https://lmstudio.ai/
Operating systems: Windows, Mac, Linux
Related languages: English
Steps for use:
- Download and install the software.
- Download the model in the application, if you can't download the model due to network or other circumstances, you can select the folder where the LLM is stored and create a new folder named "TheBloke" in the folder, then put the downloaded model into the "TheBloke" folder. Then put the downloaded models into "TheBloke" folder.
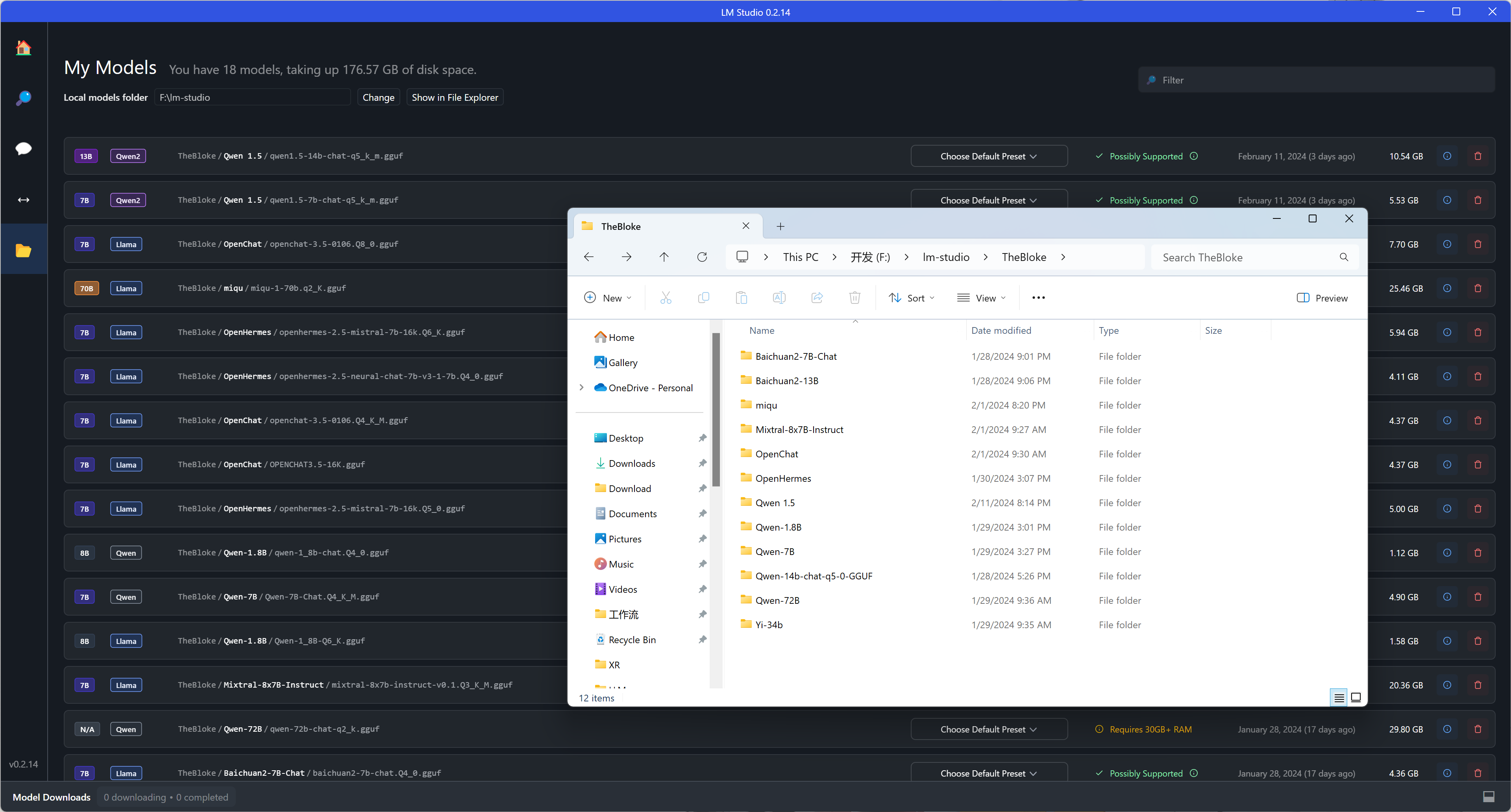
- Click "Select a model to load" to select a model to open the dialog mode, you can also select the corresponding "GPU Acceleration" and "Context Length" according to your own computer and model to reload the model. "Context Length" according to your computer and model to reload the model. (If your computer configuration is average, it is recommended to uncheck "GPU Offload", and the larger the "Context Length" setting, the longer the waiting time will be, please refer to the fourth part of the guide for a more detailed introduction.)
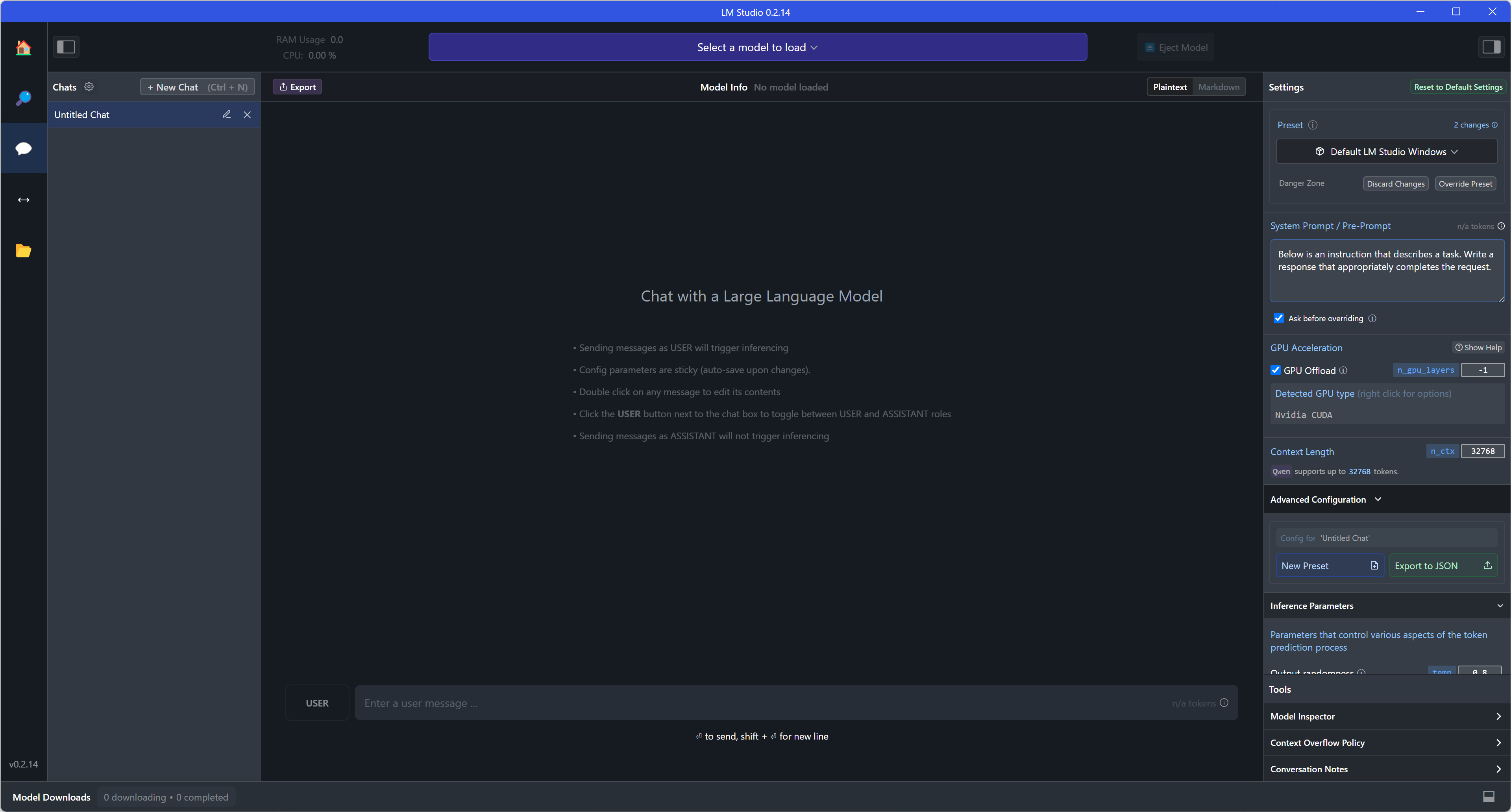
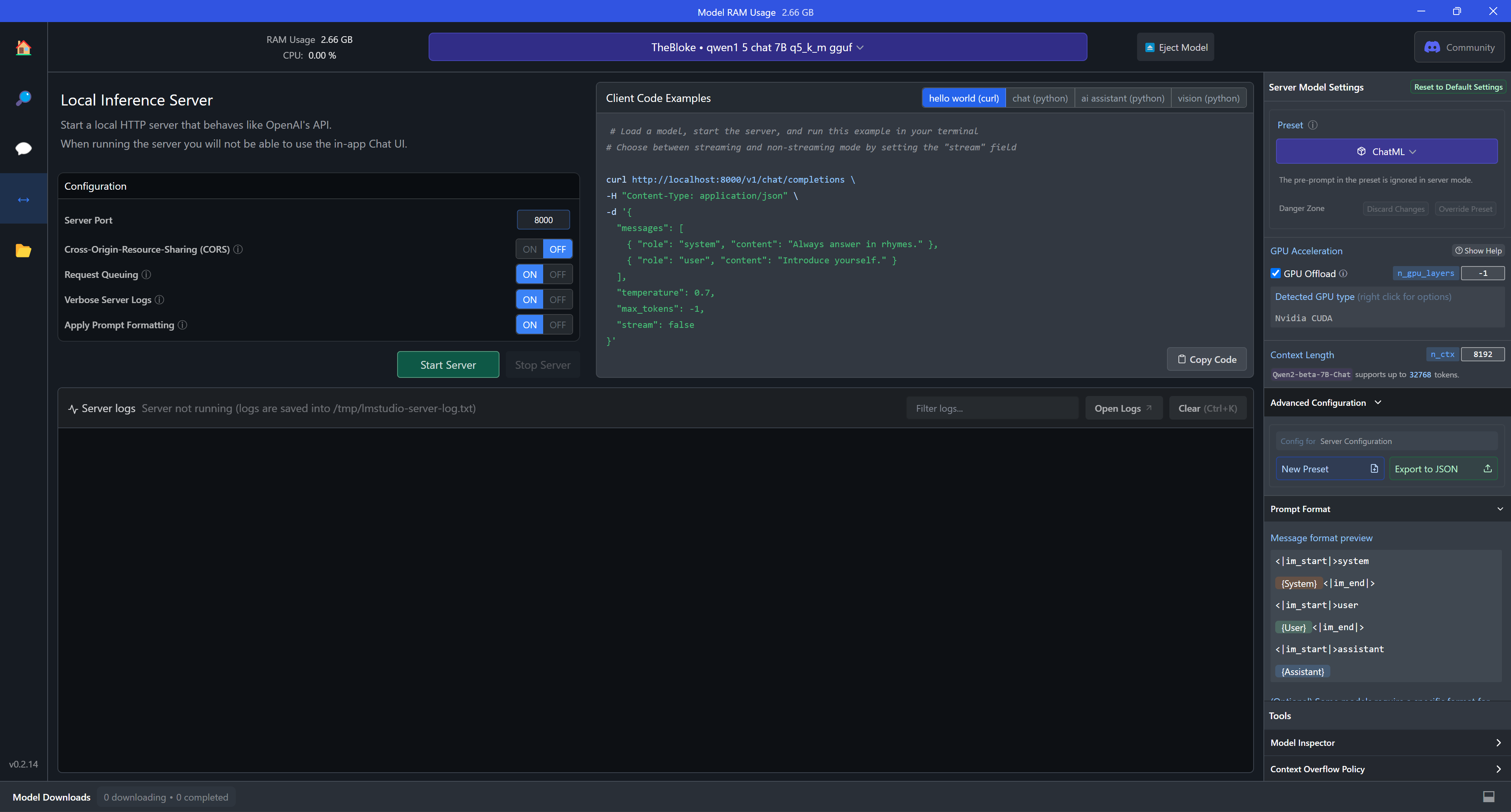
- If server-side mode is enabled, load the model and fill in the port (e.g. 8000) and click "Start Server" to run. Remember that client-server communication must be compatible with OpenAI API mode.



Advantage:
- The overall use process is friendly to the average user.
- Models can be easily switched.
- The degree of mixing of CPU and GPU can be easily selected.
- Preset can be easily switched.
- Compatible with multi-modal models, images can be queried directly in the interface.
Note:
- Always remember to reload the model manually after switching models or setting parameters.
- In server-side mode, it may be necessary to restart the server after changing models or setting parameters.
- Booting is not supported for the time being.
- Automatic entry into server-side mode is not supported for the time being.
- If your system is Windows/Linux, the processor needs to support AVX2.

Introduction: llamafile combines llama.cpp with Cosmopolitan Libc into a framework that compresses all the complexity of LLMs into a single file executable that runs locally on most computers.
Official website: https://github.com/Mozilla-Ocho/llamafile
Downloaded at: https://github.com/Mozilla-Ocho/llamafile/releases/
Operating systems: Windows, Mac, Linux
Related languages: English
Steps for use:
- Downloading file.
- If you are a macOS or Linux user, open a computer terminal and grant the computer permission to execute this new file
chmod +x llava-v1.5-7b-q4.llamafile, then run the llama file. /llava-v1.5-7b-q4.llamafile -ngl 9999. (Remember to enter the corresponding folder before typing the command, "llava-v1.5-7b-q4.llamafile" is the name of the file you downloaded) - If you are a Windows user, you can rename the file by adding ".exe" to the end of the file.
- Your browser should automatically open and display the chat screen. (If not, just open your browser and point it to http://127.0.0.1:8080/)
- When you have finished chatting, go back to your terminal and click
Control-Cto close llamafile, or just close the cmd window. - In addition, when you turn on llamafile, server-side mode is automatically enabled, so you can communicate with the client by filling in http://127.0.0.1:8080/. Remember that client-server communication must be compatible with OpenAI API mode.
Advantage:
- Download the file and use it directly.
- Directly enter server-side mode after opening the application.
- You can start the application and server mode at boot time by setting it from the command line.
Note:
- Currently part of llamafile's functionality relies on CLI (Command Line Interface), which is more suitable for users with programming skills.
- Since Windows has a 4GB limit on the size of executable files, most llamafiles downloaded from the Internet cannot be used, and you need to repackage and reset the llamafile yourself, for details, please see: https://github.com/Mozilla-Ocho/llamafile .
- Importing a model that has been downloaded locally requires repackaging another llamafile.
- Changing the model during use is equivalent to opening another file, which is not very convenient to operate.
- If your system is Windows/Linux, the processor needs to support AVX2.
 Introduction: A free-to-use, locally running, privacy-aware chatbot that requires no GPU or internet.
Introduction: A free-to-use, locally running, privacy-aware chatbot that requires no GPU or internet.
Official website and download url: https://gpt4all.io/
Operating System: Windows, Mac, Linux
Related languages: English
Steps for use:
- Download and install the software.
- Select the model storage path.
- Download LLMs and RAG models (if there are models in the model storage path, you can use them directly).
- Select the model at the top of the application to start the conversation.
- If you need to turn on the Server mode, just click the Wifi icon, but the port cannot be viewed or modified. The port in Server mode is 4891, and the complete URL is: http://127.0.0.1:4891.
Advantage:
- Support RAG function.
- You can choose the degree of mixing of CPU and GPU.
Precautions:
- The port (4891) in Server mode cannot be viewed and modified within the application.
- GPT4All may not be compatible with the complete OpenAI API mode, and some clients cannot receive data.
- It does not support startup at the moment.
- Automatically entering server mode is not supported for the time being.
- Automatic selection of RAG’s local folder is not supported for the time being.
- If your system is Windows/Linux, the processor needs to support AVX2.
- The user experience needs to be improved.
Introduction: Ollama is a lightweight, extensible framework based on LLama.cpp for building and running language models locally.
Official website and download url: https://ollama.com/
Operating system: Windows, Mac, Linux
Related languages: English
Steps for use:
- Download and open the implementation file.
- After successful installation you will be prompted to run the model within cmd, e.g.
ollama run mistral(if you have not downloaded the model it will be downloaded automatically).
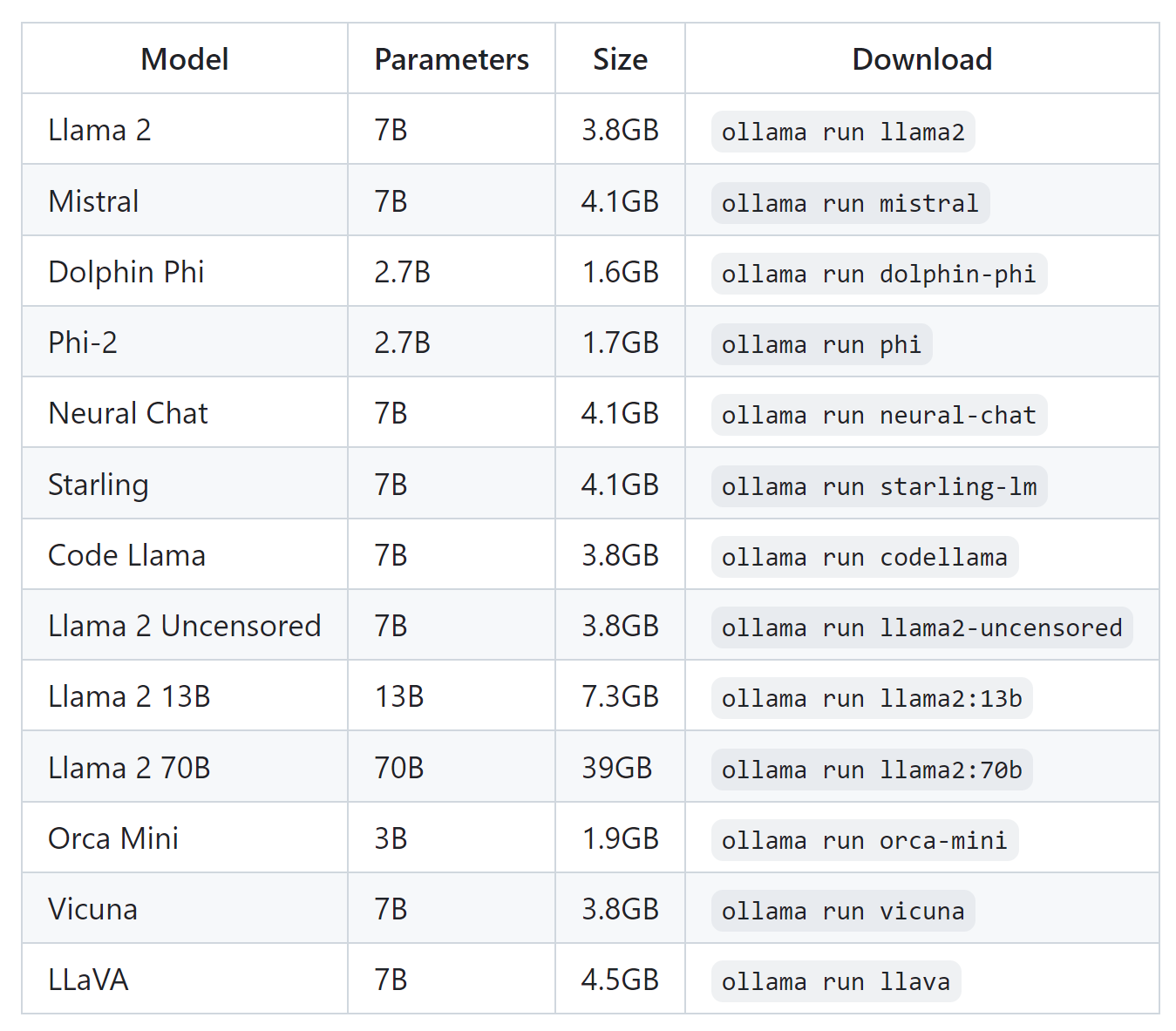
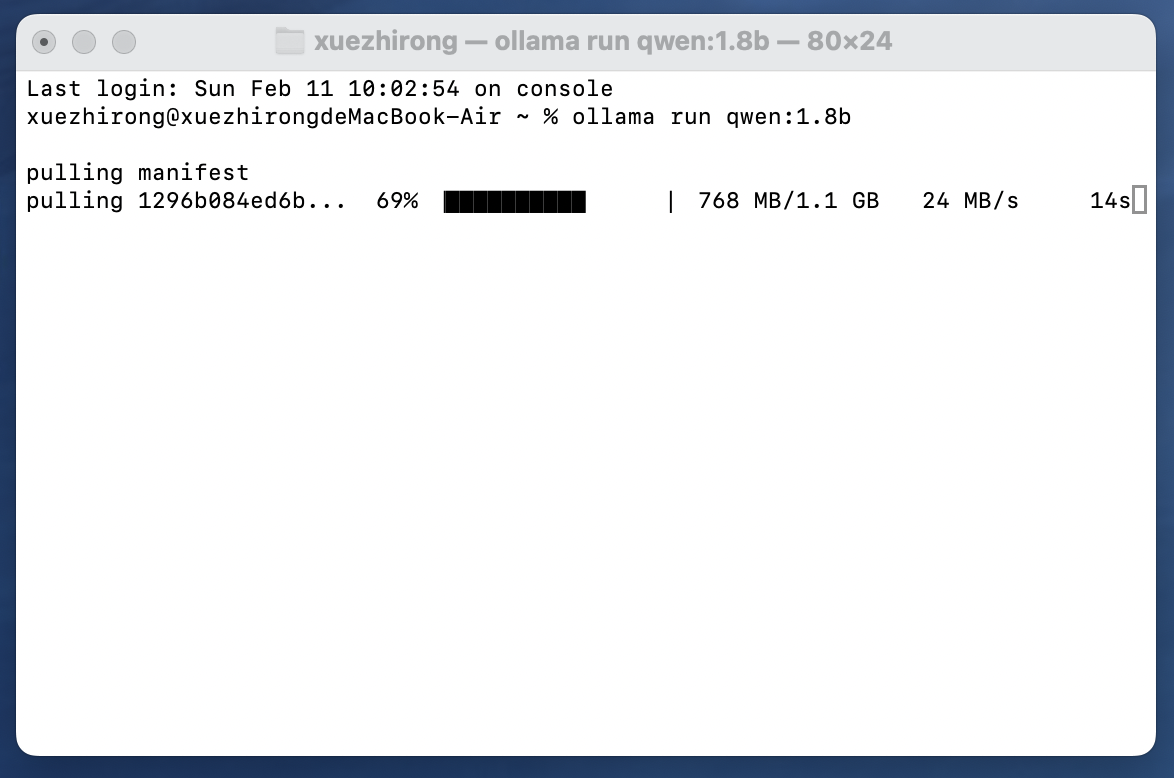
- Start a dialog in cmd


Advantage:
- Support for boot-up.
- Directly enter server-side mode after opening the application.
- Models can be downloaded directly from the command line.
- Models can be switched directly from the command line.
Note:
- Currently Ollama relies on CLI (Command Line Interface), which is more suitable for users with programming skills.
- Importing a model that has been downloaded locally requires a command line import, see https://github.com/ollama/ollama for details.
- The server-side model is not the same as the OpenAI API, which requires the client to be compatible and select the corresponding model.
- If your system is Windows/Linux, the processor needs to support AVX2.
*Feel free to share your own good LLM backends with us

Introduction: MiX Copilot is a PC client that supports OpenAI and local LLMs for automatically crawling, organizing and analyzing information (data are saved locally as Markdown to avoid privacy leakage), supporting multiple Chatbot conversations at the same time, browsing web pages + using LLMs, making LLM workflows (including customized Prompt, querying web pages) and other functions.
Official website and download url: https://www.mix-copilot.com/
Operating systems: Windows, Mac
Related languages: Chinese, English
Tutorial on use: https://hci-top.notion.site/MiX-Copilot-Tutorial-English-2c95481c5d4c4c818f40bd04c299b7ea
Steps for use:
- Download and install the software
- Go to "Settings - LLM Settings", fill in the server link in the Local Model Settings item (remember the port number should be the same), for example, http://127.0.0.1:8000, and click the "Update" button at the top, if the red If the red tag turns green, it means the connection with LLM server is successful.
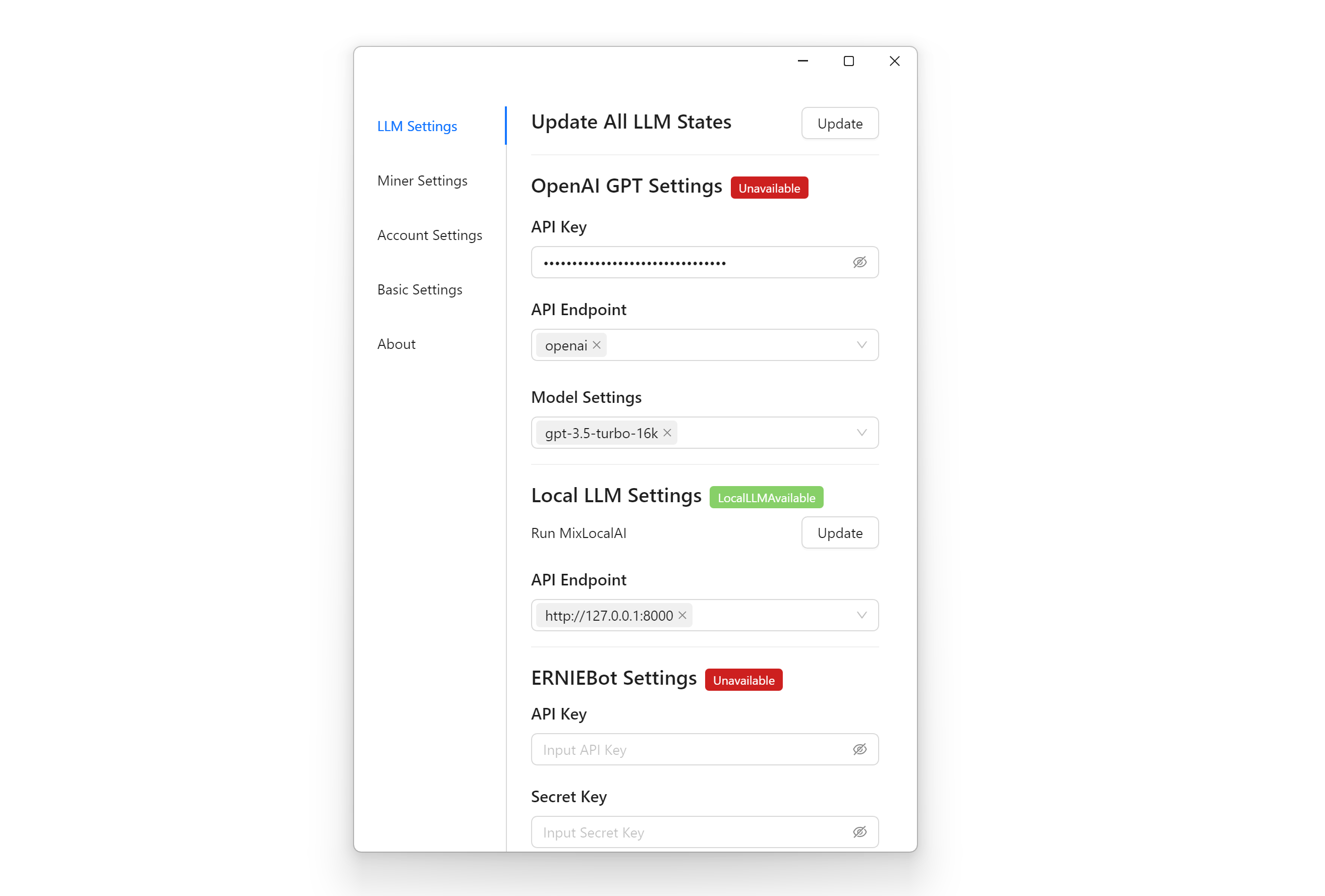
- Enable Chatbot by clicking the "+" sign in the top Tab or right clicking "Show Chatbot" while browsing the web.
- Select Local LLM in the lower left corner of the dialog panel!



 Introduction: AnythingLLM can be used for unlimited documents, completely private, can use GPT-4, custom models or open source models such as Llama, Mistral, etc., and supports multiple formats such as PDF, Word documents, etc.
Introduction: AnythingLLM can be used for unlimited documents, completely private, can use GPT-4, custom models or open source models such as Llama, Mistral, etc., and supports multiple formats such as PDF, Word documents, etc.
Official website and download url: https://useanything.com/
Operating System: Windows, Mac
Related languages: English
Steps for use:
- Download and install the software.
- Set up the model (you can set up OpenAI API, connect to LM-Studio, etc.), Embedding, and vector database respectively.
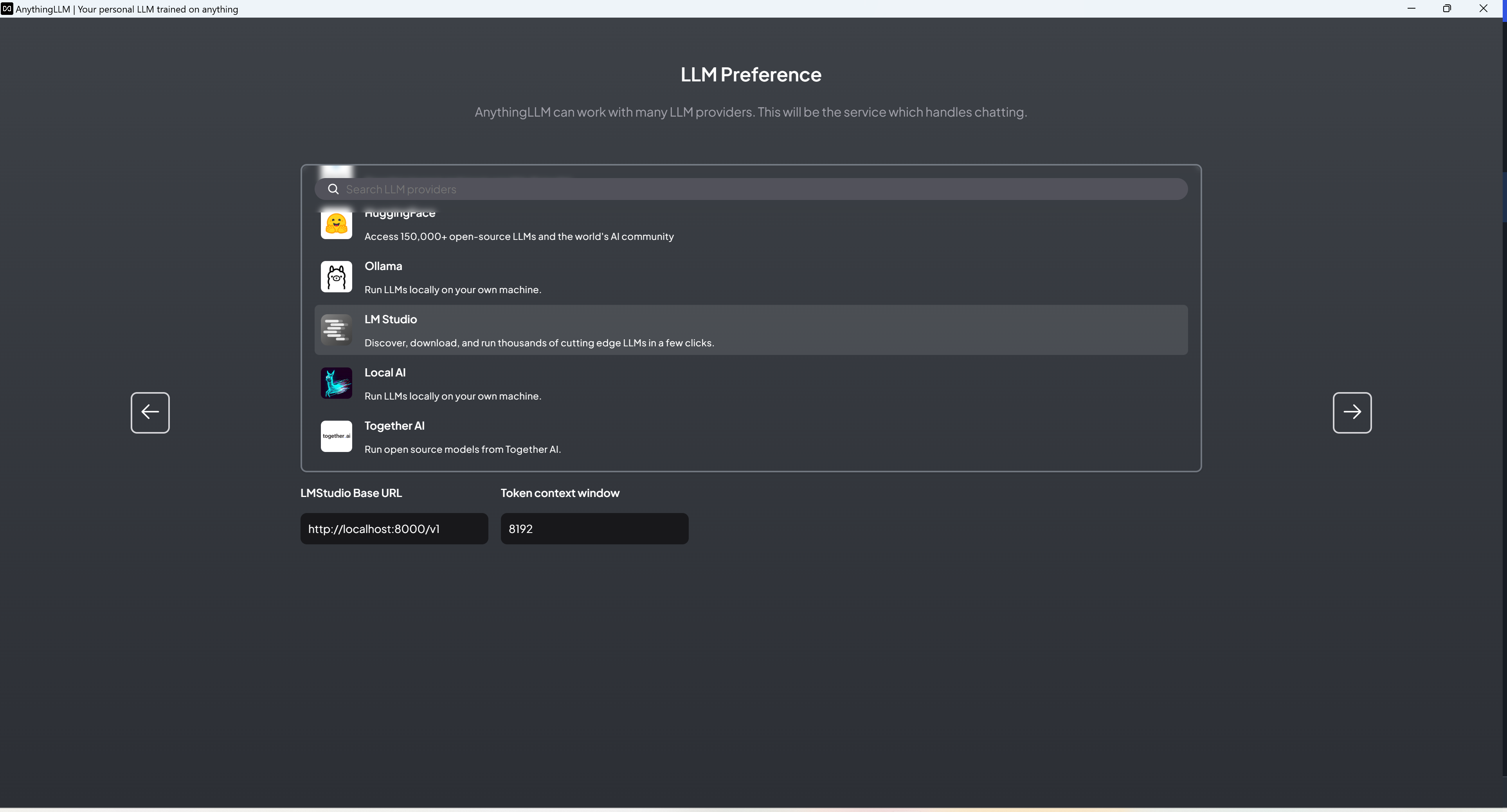
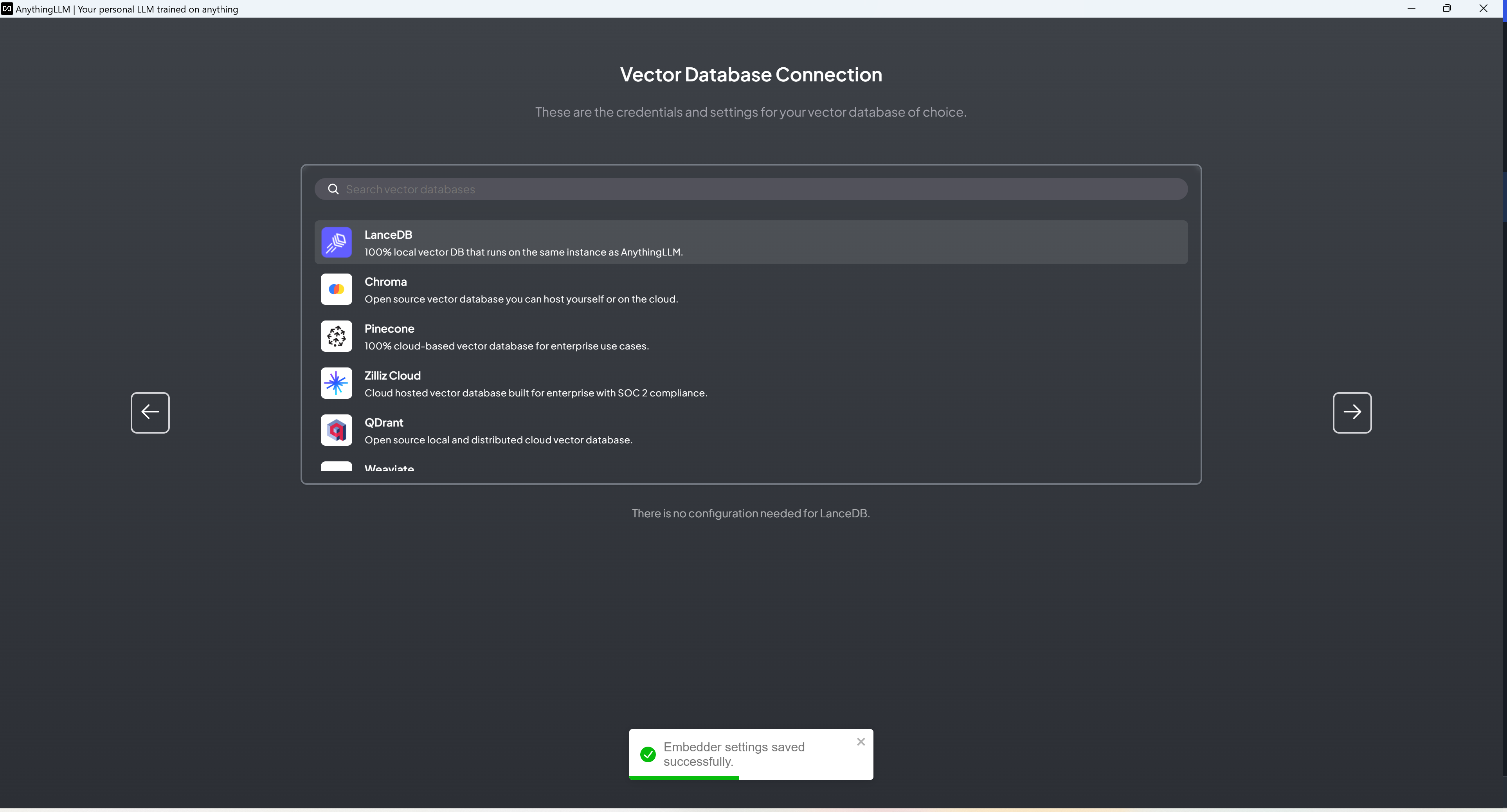
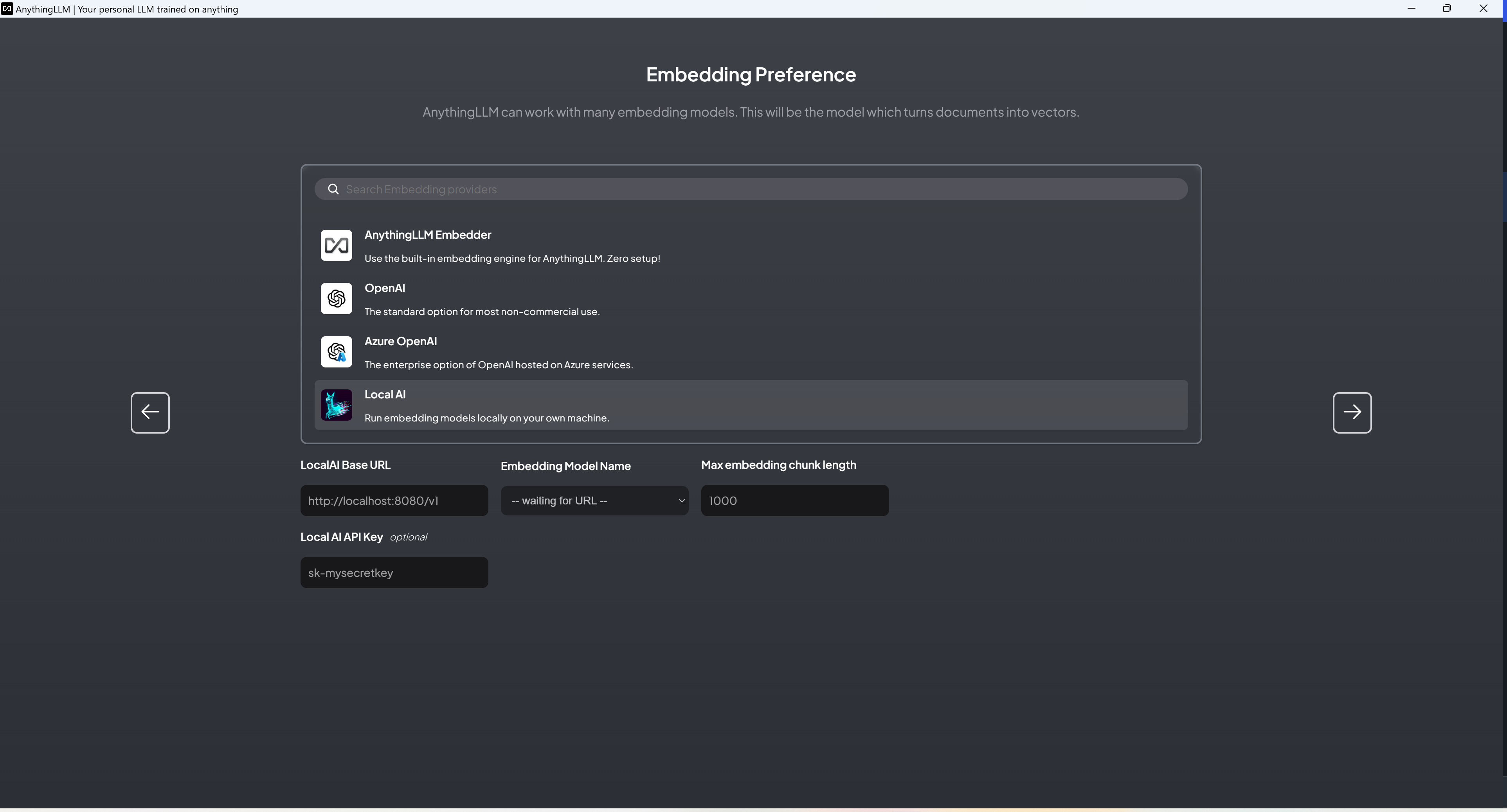
- Set up your workspace.
- Start a conversation.
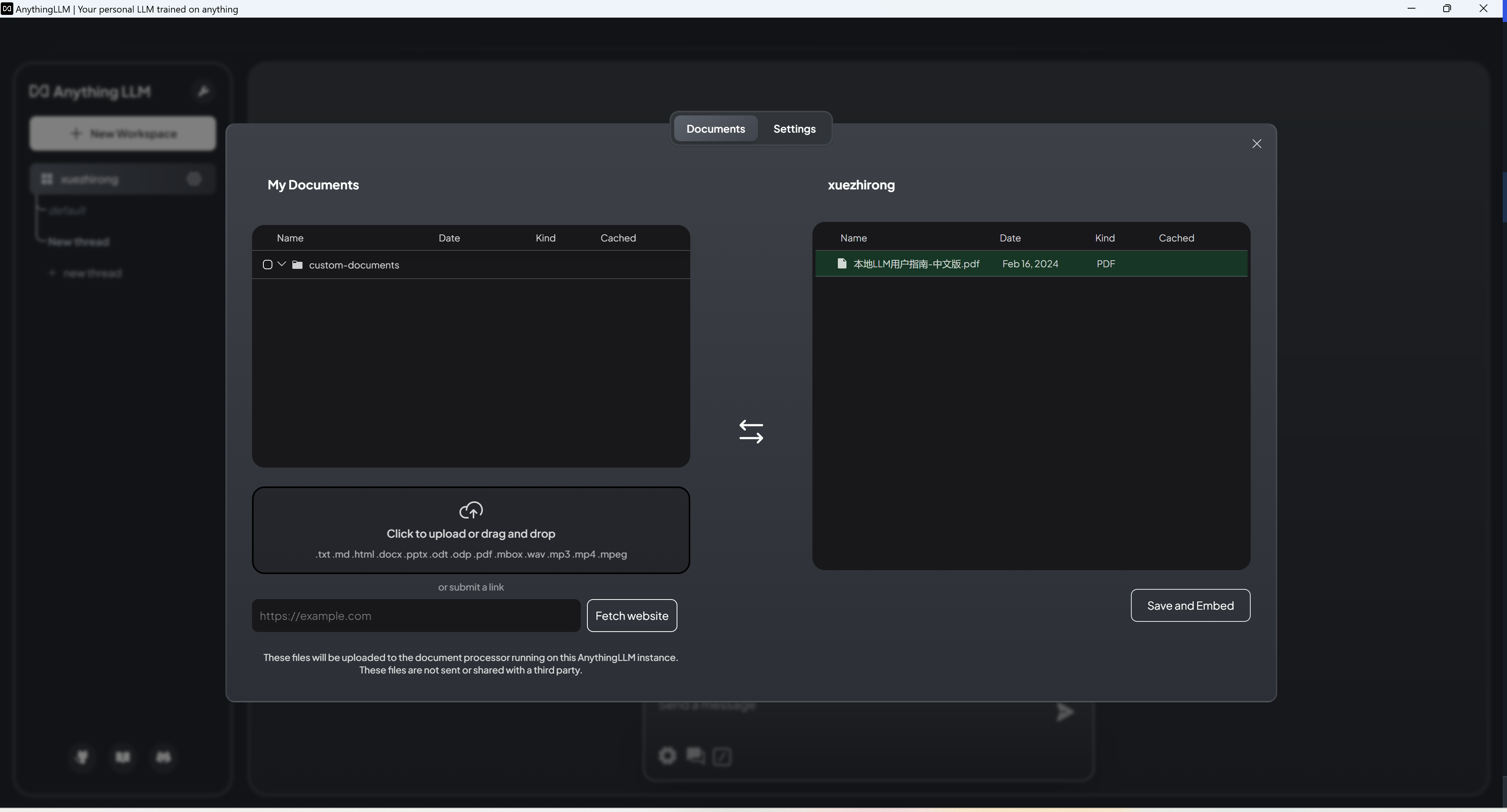
- You can add MD, PDF, MP4 and other files in the client, or directly add the website URL.
- Add the above document to the workspace to start Embedding and have a conversation.




 Introduction: Reor is a desktop note-taking app powered by artificial intelligence: it automatically links related ideas, answers questions in notes, and provides semantic search. All content is stored locally, and users can edit notes using a Markdown editor like Obsidian.
Introduction: Reor is a desktop note-taking app powered by artificial intelligence: it automatically links related ideas, answers questions in notes, and provides semantic search. All content is stored locally, and users can edit notes using a Markdown editor like Obsidian.
Official website and download url: https://www.reorproject.org/
Operating System: Windows, Mac
Related languages: English
Steps for use:
- Download and install the software.
- Select the folder where you store Markdown.
- On the settings page, select the quantization model you downloaded (GGUF format) and set the context length.
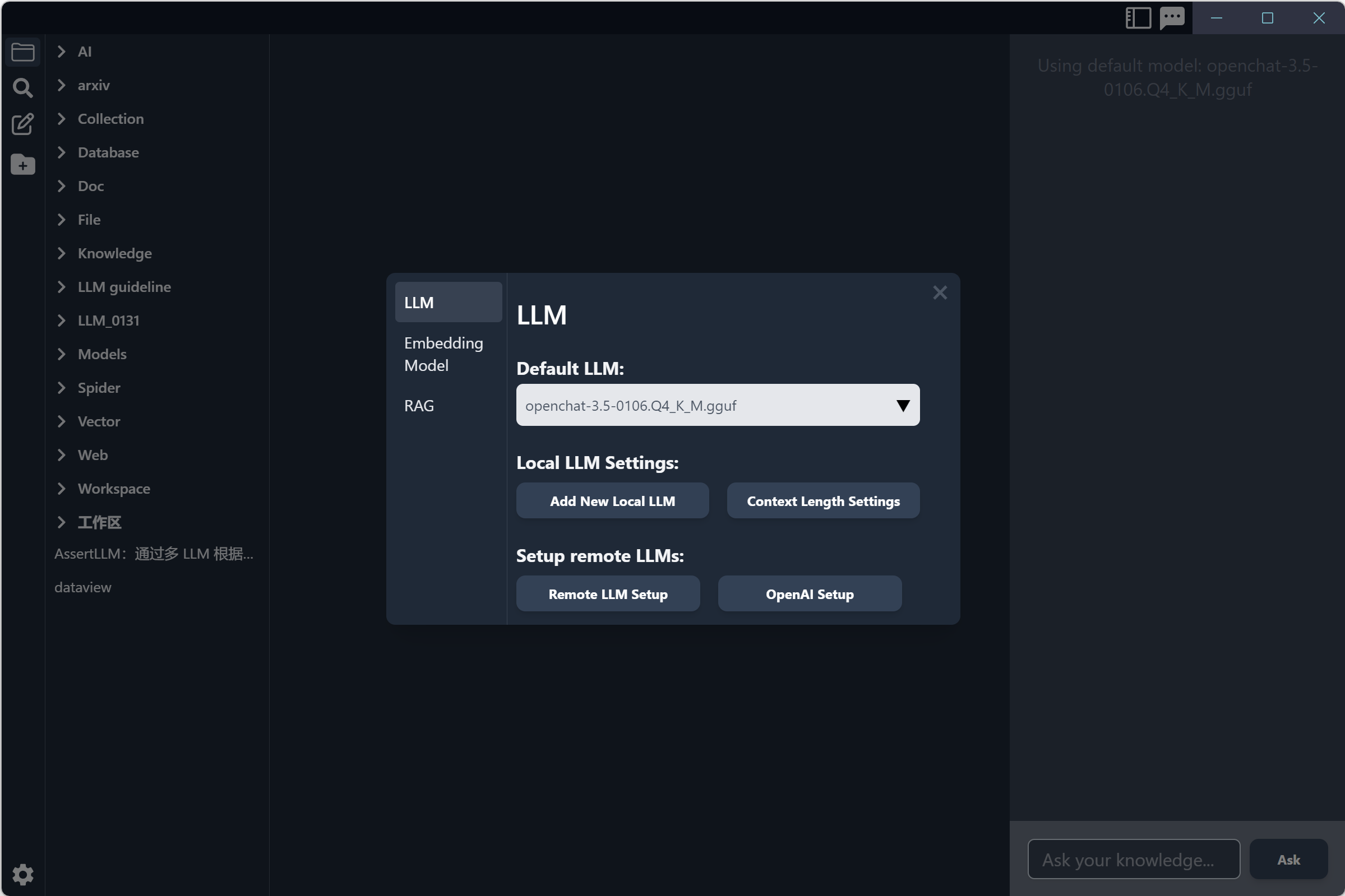
- Select the Embedding model you need. Note: Users in some areas may be unable to download the Embedding model due to network problems, resulting in the application becoming unusable. In addition, the Embedding model provided in the application is only good at processing English and may not be applicable to other languages.
- Set the return quantity of RAG.


Introduction:Chat With RTX is a demo application that allows you to interact your own content (documents, notes, videos, or other data) with native LLM.Chat With RTX integrates Retrieval Augmented Generation (RAG), TensorRT-LLM, and RTX Acceleration, which allows users to query a custom chatbot to quickly get Chat with RTX supports a variety of file formats including text, pdf, doc/docx, and xml. simply point the application to the folder containing the files and it will load them into the library in seconds. Additionally, users can provide the URL of a YouTube playlist and the application will load transcriptions of the videos in the playlist and then look up what they cover.
Official website and download url: https://www.nvidia.com/en-us/ai-on-rtx/chat-with-rtx-generative-ai/
Operating system: Windows
Related languages: English
Note:
- Currently Chat with RTX is a demo application.
- Currently Chat with RTX requires NVIDIA GeForce™ RTX 30 or 40 series GPUs or NVIDIA RTX™ Ampere or Ada Generation GPUs with at least 8GB of VRAM and 16GB of RAM.
- The size of the demo application installation package is up to 35GB.
*There are very few native LLM-compatible clients in the world, so we welcome your recommendations or self-recommendations.
- LLMs of different training sizes will make errors, even GPT-5.
- LLM with different training scales determines its own inference level. For example, the 13B LLM model is better than the 2B LLM model, but the quality of tasks completed by the small model can be improved through fine-tuning.
- After the LLM model is quantized, the smaller the volume, the worse the accuracy will be. For example, Q2 < Q8.
- Currently, the best devices for running LLM are NVIDIA GPUs or M1 and above Macs. If your computer has an AMD or Intel GPU, you can currently only use the CPU to run LLM.
- It is fastest to load all LLM models into the GPU and run them.
- 8G and below GPU: 2B-LLM + 4
8k Token or 7B-LLM + 24k Token. - 8-12GB GPU: 7B-LLM + 4k
6k Token or 14B-LLM + 24k Token. - 12-24GB GPU-: 7B-LLM + 8
12k Token or 14B-LLM + 48k Token.
Note: The final LLM model volume + the video memory occupied by the context < GPU video memory, otherwise the speed will be slower (for example, an 8k context will occupy 6~10G of video memory). You can choose different quantization models according to your needs to reduce the volume of the LLM model.
Finally, if you are very familiar with local LLM, welcome to join our discussion!
Github: https://github.com/xue160709/Local-LLM-User-Guideline
Discord: https://discord.gg/4AQuf2ctav
Twitter: https://twitter.com/XueZhirong