- We propose a novel image-to-3D pipeline called Isotropic3D that takes only an image CLIP embedding as input. Isotropic3D aims to give full play to 2D diffusion model priors without requiring the target view to be utterly consistent with the input view
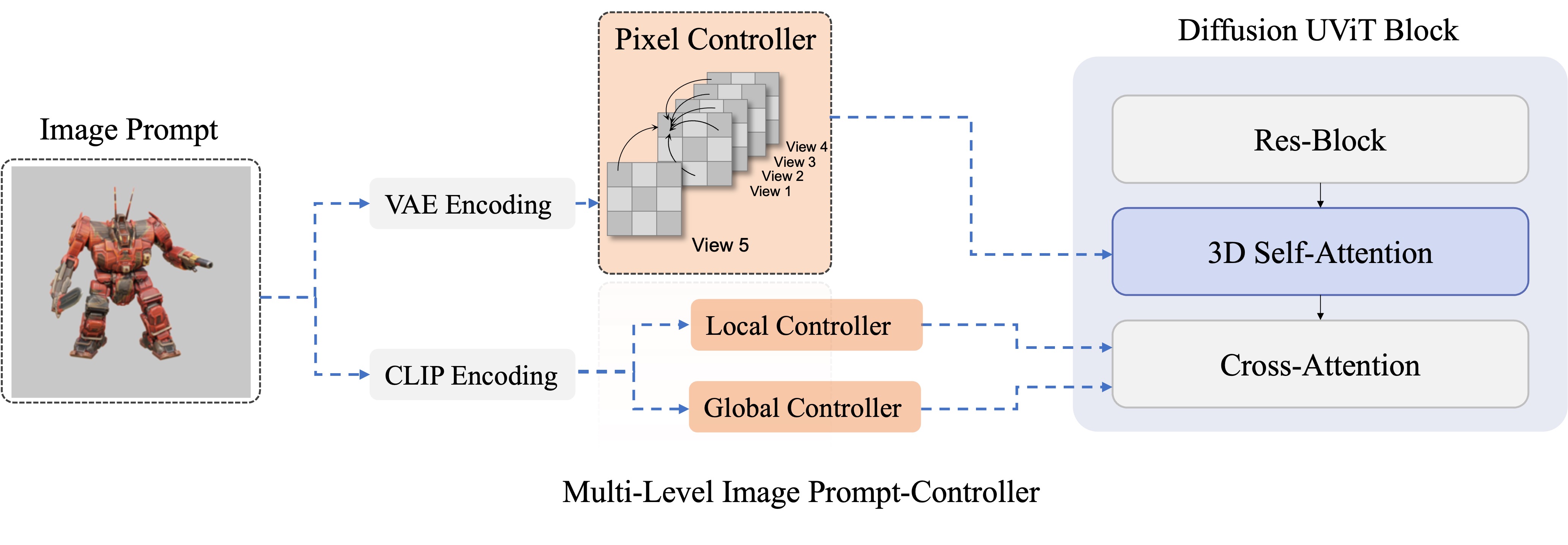
- We introduce a view-conditioned multi-view diffusion model that integrates Explicit Multi-view Attention (EMA), aimed at enhancing view generation through fine-tuning. EMA combines noisy multi-view images with the noisefree reference image as an explicit condition. Such a design allows the reference image to be discarded from the whole network during the SDS-based 3D generation process
- Experiments demonstrate that with a single CLIP embedding, Isotropic3D can generate promising 3D assets while still showing similarity to the reference image.
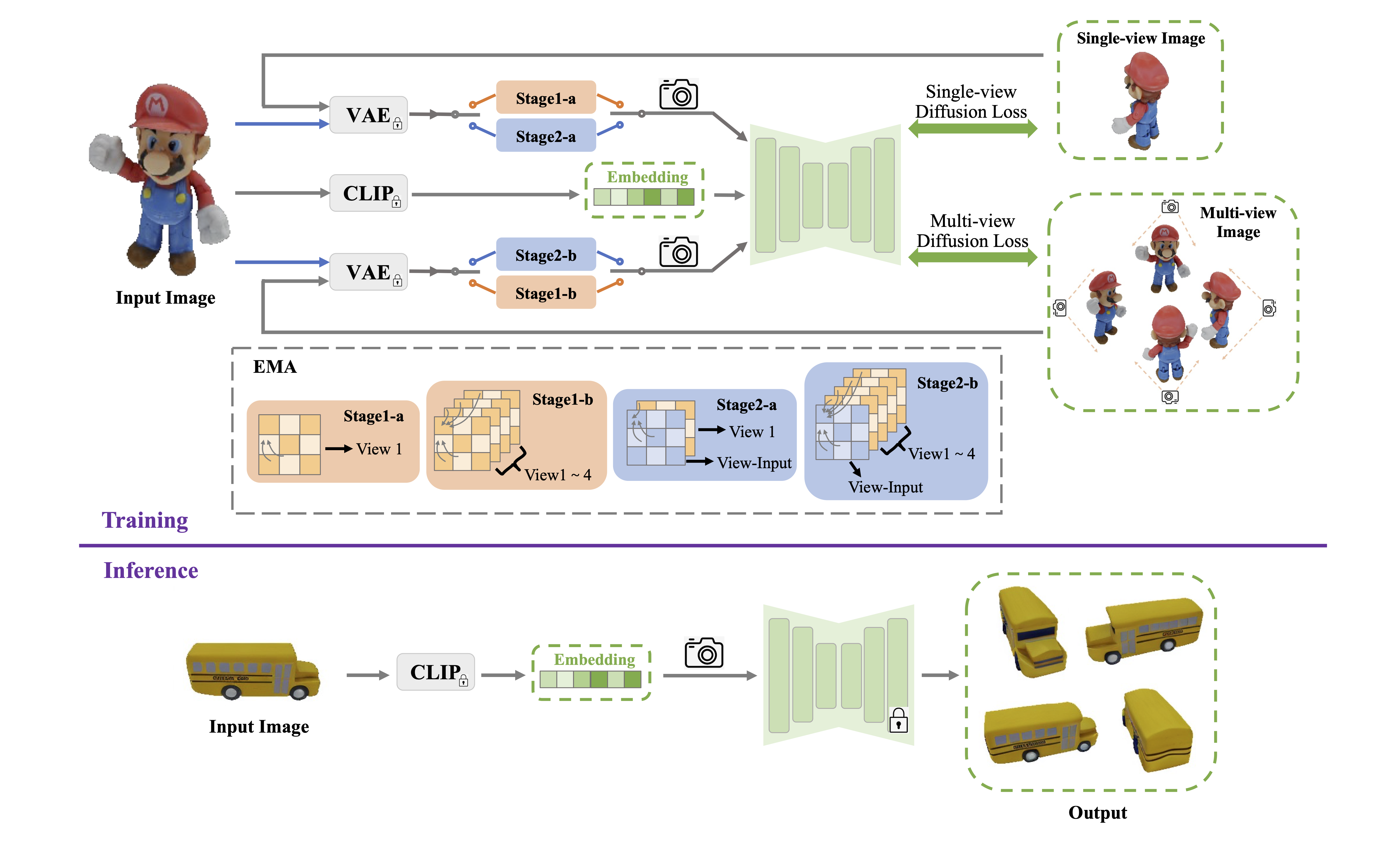


- Single CLIP embedding to entire 3D generation
- Mulitview Diffusion model what takes the reference image and the noisy rendered 2D images
- A single loop to actually make the generation better
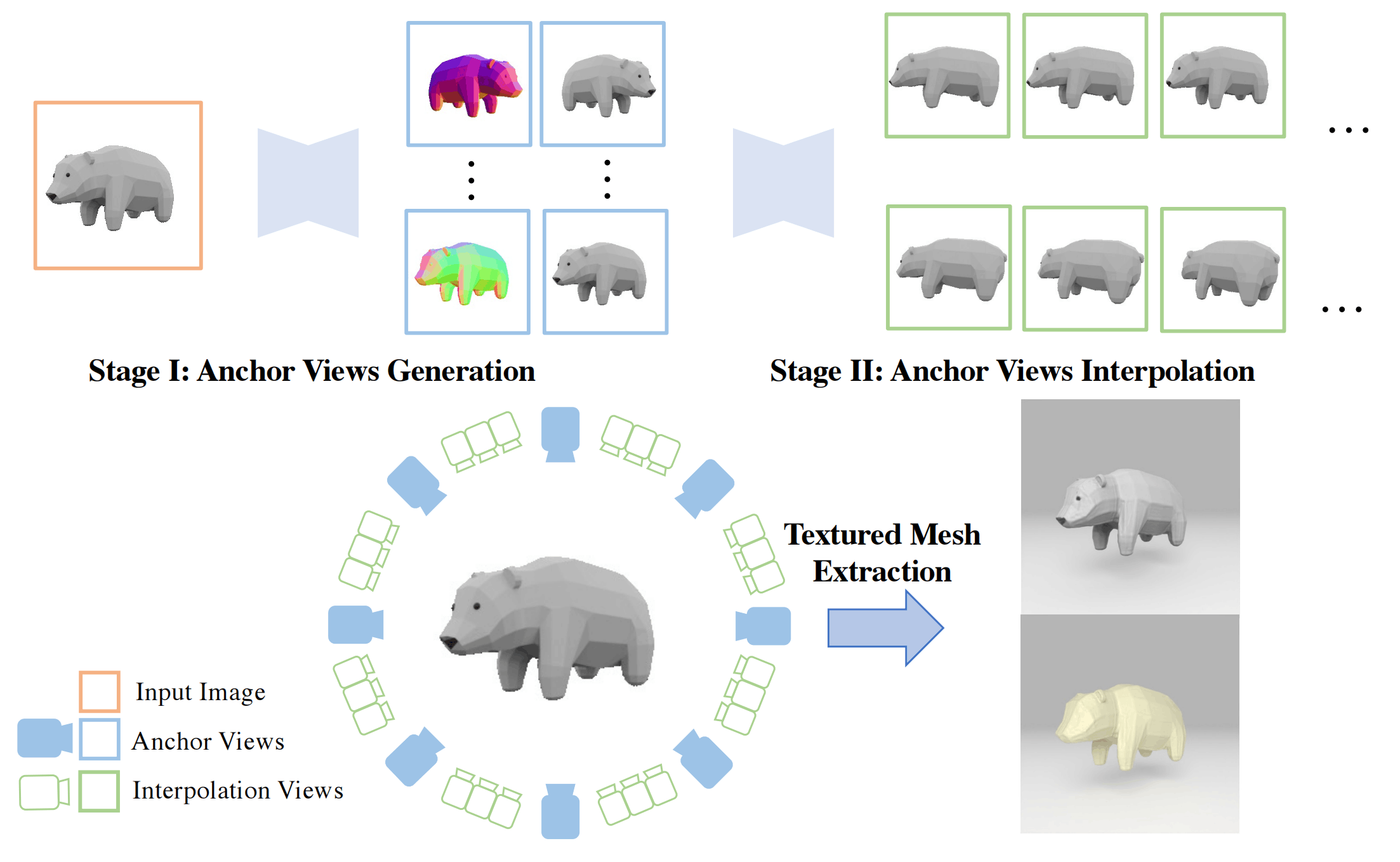
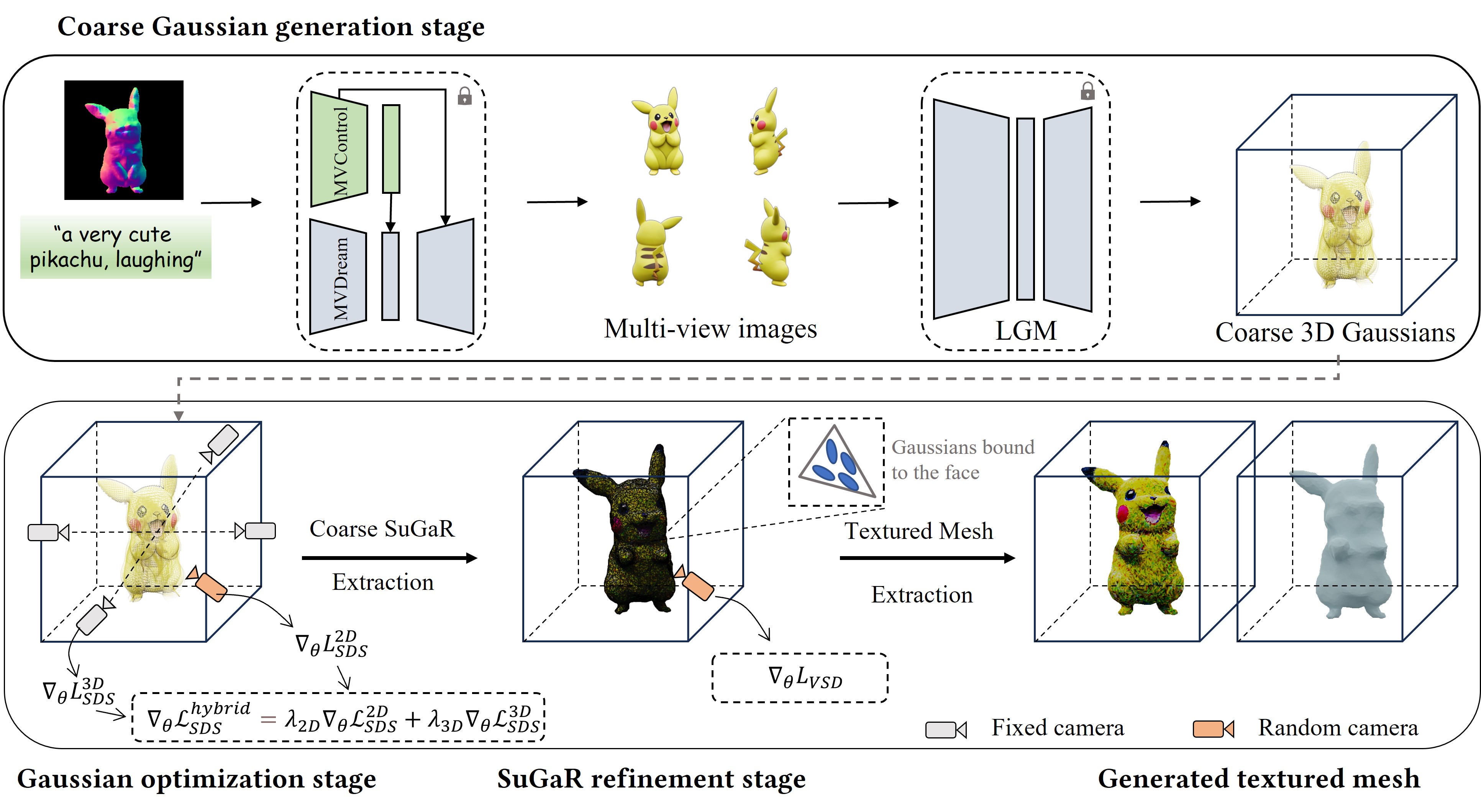
- We propose to optimize 3D Gaussians from highly sparse views with explicit structure priors, where several techniques are designed, including the visual hull for initialization and floater elimination for training.
- A Gaussian repair model based on diffusion models is proposed to remove artifacts caused by omitted or highly compressed object information, where the rendering quality can be further improved.
- The overall framework GaussianObject shows strong performance on several challenging real-world datasets, consistently outperforming previous state-of-the-art methods for both qualitative and quantitative evaluation.


- Propose visual hull for coarse point cloud generation from 4 reference images
- Gaussian repair module and distance aware sampling
- 2D diffusion model and SDS loss to refine the initialized gaussians using gaussian rasterization for 2D rendering



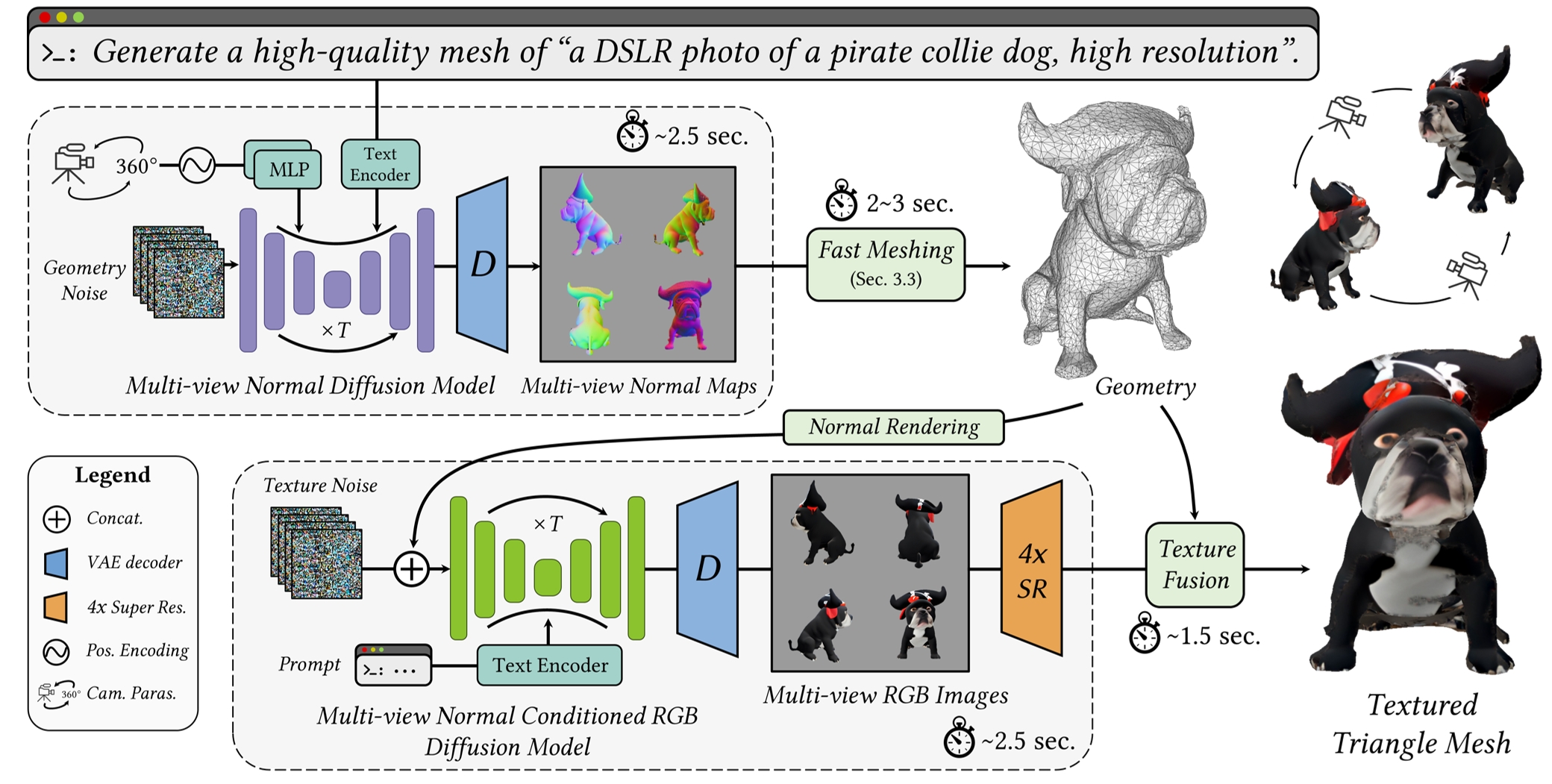
- EXTREMELY FAST (5 second for single image to 3D generation)

- EXTREMELY FAST (<1 second for single image to 3D generation)


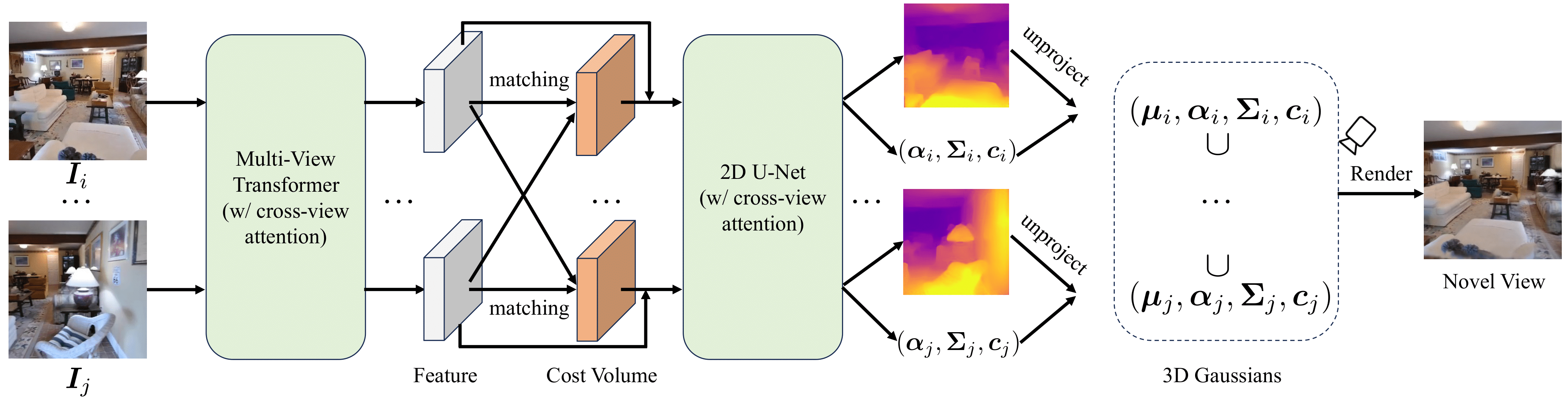




Triplane Meets Gaussian Splatting: Fast and Generalizable Single-View 3D Reconstruction with Transformers