
carrier of tricks for image classification tutorials using pytorch. Based on "Bag of Tricks for Image Classification with Convolutional Neural Networks", 2019 CVPR Paper, implement classification codebase using custom dataset.
- author: hoya012
- last update: 2020.08.06
- supplementary materials (blog post written in Korean)
pip install -r requirements.txtThis Data contains around 25k images of size 150x150 distributed under 6 categories. {'buildings' -> 0, 'forest' -> 1, 'glacier' -> 2, 'mountain' -> 3, 'sea' -> 4, 'street' -> 5 }
- facebook_research_pycls
- download RegNetY-1.6GF and EfficientNet-B2 weights
- ImageNet Pretrained ResNet-50 from torchvision.models
- 1080 Ti 1 GPU / Batch Size 64 / Epochs 120 / Initial Learning Rate 0.1
- Training Augmentation: Resize((256, 256)), RandomHorizontalFlip()
- SGD + Momentum(0.9) + learning rate step decay (x0.1 at 30, 60, 90 epoch)
python main.py --checkpoint_name baseline;- Random Initialized ResNet-50 (from scratch)
python main.py --checkpoint_name baseline_scratch --pretrained 0;- Adam Optimizer with small learning rate(1e-4 is best!)
python main.py --checkpoint_name baseline_Adam --optimizer ADAM --learning_rate 0.0001Before start, i didn't try No bias decay, Low-precision Training, ResNet Model Tweaks, Knowledge Distillation.
- first 5 epochs to warmup
python main.py --checkpoint_name baseline_warmup --decay_type step_warmup;
python main.py --checkpoint_name baseline_Adam_warmup --optimizer ADAM --learning_rate 0.0001 --decay_type step_warmup;- zero-initialize the last BN in each residual branch
python main.py --checkpoint_name baseline_zerogamma --zero_gamma ;
python main.py --checkpoint_name baseline_warmup_zerogamma --decay_type step_warmup --zero_gamma;
python main.py --checkpoint_name baseline_Adam_warmup_cosine --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup;
- In paper, use smoothing coefficient as 0.1. I will use same value.
- The number of classes in imagenet (1000) is different from the number of classes in our dataset (6), but i didn't tune them.
python main.py --checkpoint_name baseline_Adam_warmup_cosine_labelsmooth --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1;
python main.py --checkpoint_name baseline_Adam_warmup_labelsmooth --optimizer ADAM --learning_rate 0.0001 --decay_type step_warmup --label_smooth 0.1;- MixUp paper link
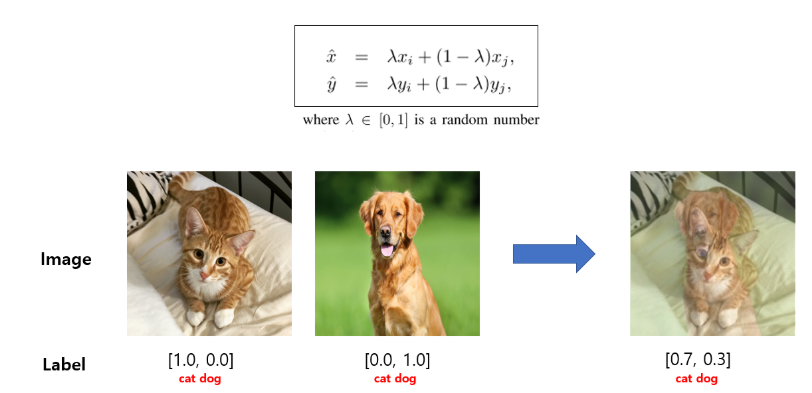
- lambda is a random number drawn from Beta(alpha, alpha) distribution.
- I will use alpha=0.2 like paper.

python main.py --checkpoint_name baseline_Adam_warmup_mixup --optimizer ADAM --learning_rate 0.0001 --decay_type step_warmup --mixup 0.2;
python main.py --checkpoint_name baseline_Adam_warmup_cosine_mixup --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --mixup 0.2;
python main.py --checkpoint_name baseline_Adam_warmup_labelsmooth_mixup --optimizer ADAM --learning_rate 0.0001 --decay_type step_warmup --label_smooth 0.1 --mixup 0.2;
python main.py --checkpoint_name baseline_Adam_warmup_cosine_labelsmooth_mixup --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1 --mixup 0.2;- CutMix paper link
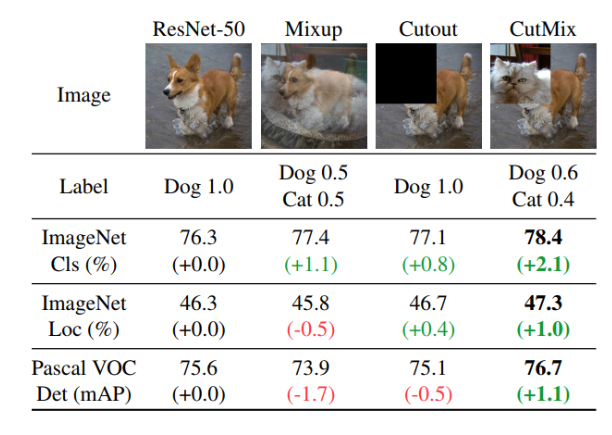
- I will use same hyper-parameter (cutmix alpha=1.0, cutmix prob=1.0) with ImageNet-Experimental Setting

python main.py --checkpoint_name baseline_Adam_warmup_cosine_cutmix --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --cutmix_alpha 1.0 --cutmix_prob 1.0;
python main.py --checkpoint_name baseline_RAdam_warmup_cosine_labelsmooth --optimizer RADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1;
python main.py --checkpoint_name baseline_RAdam_warmup_cosine_cutmix --optimizer RADAM --learning_rate 0.0001 --decay_type cosine_warmup --cutmix_alpha 1.0 --cutmix_prob 1.0;- RandAugment paper link
- I will use N=3, M=15.

python main.py --checkpoint_name baseline_Adam_warmup_cosine_labelsmooth_randaug --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1 --randaugment;python main.py --checkpoint_name baseline_Adam_warmup_cosine_labelsmmoth_evonorm --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1 --norm evonorm;


- I will use EfficientNet-B2 which has similar acts with ResNet-50
- But, because of GPU Memory, i will use small batch size (48)...
- I will use RegNetY-1.6GF which has similar FLOPS and acts with ResNet-50
python main.py --checkpoint_name efficientnet_Adam_warmup_cosine_labelsmooth --model EfficientNet --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1;
python main.py --checkpoint_name efficientnet_Adam_warmup_cosine_labelsmooth_mixup --model EfficientNet --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1 --mixup 0.2;
python main.py --checkpoint_name efficientnet_Adam_warmup_cosine_cutmix --model EfficientNet --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --cutmix_alpha 1.0 --cutmix_prob 1.0;
python main.py --checkpoint_name efficientnet_RAdam_warmup_cosine_labelsmooth --model EfficientNet --optimizer RADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1;
python main.py --checkpoint_name efficientnet_RAdam_warmup_cosine_cutmix --model EfficientNet --optimizer RADAM --learning_rate 0.0001 --decay_type cosine_warmup --cutmix_alpha 1.0 --cutmix_prob 1.0;python main.py --checkpoint_name regnet_Adam_warmup_cosine_labelsmooth --model RegNet --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1;
python main.py --checkpoint_name regnet_Adam_warmup_cosine_labelsmooth_mixup --model RegNet --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1 --mixup 0.2;
python main.py --checkpoint_name regnet_Adam_warmup_cosine_cutmix --model RegNet --optimizer ADAM --learning_rate 0.0001 --decay_type cosine_warmup --cutmix_alpha 1.0 --cutmix_prob 1.0;
python main.py --checkpoint_name regnet_RAdam_warmup_cosine_labelsmooth --model RegNet --optimizer RADAM --learning_rate 0.0001 --decay_type cosine_warmup --label_smooth 0.1;
python main.py --checkpoint_name regnet_RAdam_warmup_cosine_cutmix --model RegNet --optimizer RADAM --learning_rate 0.0001 --decay_type cosine_warmup --cutmix_alpha 1.0 --cutmix_prob 1.0;-
B : Baseline
-
A : Adam Optimizer
-
W : Warm up
-
C : Cosine Annealing
-
S : Label Smoothing
-
M : MixUp Augmentation
-
CM: CutMix Augmentation
-
R : RAdam Optimizer
-
RA : RandAugment
-
E : EvoNorm
-
EN : EfficientNet
-
RN : RegNet
| Algorithm | Test Accuracy |
|---|---|
| B from scratch | 86.47 |
| B | 89.07 |
| B + A | 94.13 |
| B + A + W | 94.57 |
| B + A + W + C | 94.20 |
| B + A + W + S | 93.67 |
| B + A + W + C + S | 93.67 |
| B + A + W + M | 94.03 |
| B + A + W + S + M | 94.27 |
| B + A + W + C + S + M | 93.73 |
| :------------: | :------------: |
| BAWC + CM | 94.20 |
| BWCS + R | 93.97 |
| BAWCS + RA | 93.93 |
| BAWCS + E | 93.53 |
| BWC + CM + R | 94.27 |
| :------------: | :------------: |
| EN + AWCSM | 94.07 |
| EN + AWC + CM | 94.33 |
| EN + WCS + R | 94.50 |
| EN + WC + CM + R | 94.33 |
| :------------: | :------------: |
| RN + AWCSM | 94.57 |
| RN + AWC + CM | 94.83 |
| RN + WCS + R | 94.37 |
| RN + WC + CM + R | 94.90 |
- Tip: I recommend long training epoch if you use many regularization techniques (Label Smoothing, MixUp, RandAugment, CutMix, etc). Remember that i use just 120 epoch.

- see
gpu_history.sh
- Gradual Warmup Scheduler: https://github.com/ildoonet/pytorch-gradual-warmup-lr
- Label Smoothing: https://github.com/NVIDIA/DeepLearningExamples/blob/master/PyTorch/Classification/ConvNets/image_classification/smoothing.py
- MixUp Augmentation: https://github.com/NVIDIA/DeepLearningExamples/blob/master/PyTorch/Classification/ConvNets/image_classification/mixup.py
- CutMix Augmentation:https://github.com/clovaai/CutMix-PyTorch
- RAdam Optimizer: https://github.com/LiyuanLucasLiu/RAdam
- RandAugment: https://github.com/ildoonet/pytorch-randaugment
- EvoNorm: https://github.com/digantamisra98/EvoNorm
- ImageNet-Pretrained EfficientNet, RegNet: https://github.com/facebookresearch/pycls