This code pattern is in continuation of the composite pattern - build knowledge-base with domain-specific documents. We saw how we can extract entities and relations from a word document that contains information in tables and text to build a knowledge graph.
After building the knowledge graph, the next step is fetch the required facts. Take the example of a document that contains details of the history of a cancer patient. We could then need the answer to the below questions and more:
- When was the cancer diagnosed?
- What were the early symptoms of the cancer?
- What is the history of the patient’s family?
- What are the treatments given to the patient?
- List of all the things patient is allergic to?
- Which Oncologist is in charge of that patient?
The problem lies in finding the context of the entities in the text string used for search, resolve the ambiguity of the text, formulating the query accordingly and provide the relevant query results fetched from the domain-specific Knowledge base. For instance, In a New York Times article there is a mention of former US President Barack Obama as just 'OBAMA', how to make the algorithm understand it’s referring to the US president and not any other person.
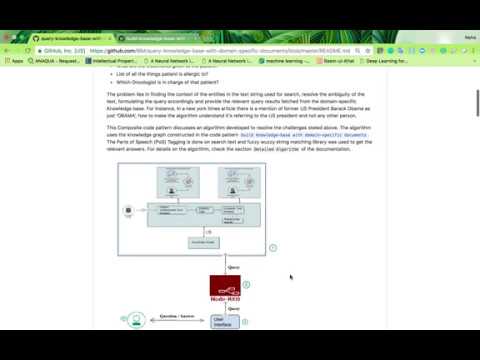
This Composite code pattern discusses an algorithm developed to resolve the challenges stated above. The algorithm uses the knowledge graph constructed in the code pattern build knowledge-base with domain-specific documents. The Parts of Speech (PoS) Tagging is done on search text and fuzzy wuzzy string matching library was used to get the relevant answers. For details on the algorithm, check the section Detailed Algorithm of the documentation.

- The unstructured data is brought into a 3-tuple of entity-relationship-entity
- A knowledge graph is built out of the obtained entities and relationship
- A question is entered by the user on the UI.
- The question asked by the user through the UI is sent to the notebook through the Node Red. Node red helps in integrating the UI with notebook.
- The question gets queried and a suitable response is sent back.
- The user receives the answer on the UI.
-
IBM Watson Studio: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
-
IBM Cloud Object Storage: An IBM Cloud service that provides an unstructured cloud data store to build and deliver cost effective apps and services with high reliability and fast speed to market.
-
Watson Natural Language Understanding: An IBM Cloud service that can analyze text to extract meta-data from content such as concepts, entities, keywords, categories, sentiment, emotion, relations, semantic roles, using natural language understanding.
-
Node-RED: Node-RED is a programming tool for wiring together APIs and online services.
- Data Science: Systems and scientific methods to analyze structured and unstructured data in order to extract knowledge and insights.
Follow these steps to setup and run this developer journey. The steps are described in detail below.
- Sign up for Watson Studio
- Create IBM Cloud services
- Import the Node-RED flow
- Note the websocket URL
- Update the websocket URL
- Update the websocket URL in Notebook
- Accessing the user interface
- Set up the Notebook
- Detailed Algortihm
Sign up for IBM's Watson Studio. By creating a project in Watson Studio a free tier Object Storage service will be created in your IBM Cloud account
Create the IBM Cloud services required for the individual code patterns:
- Clone this repo.
- Navigate to the knowledge_graph_insights.json.
- Open the file with a text editor and copy the contents to Clipboard.
- On the Node-RED flow editor, click the Menu and select
Import->Clipboardand paste the contents.



The websocket URL is ws://<NODERED_BASE_URL>/ws/abc where the NODERED_BASE_URL is the marked portion of the URL in the above image.
An example websocket URL for a Node-RED app with name myApp is ws://myApp.mybluemix.net/ws/abc, where myApp.mybluemix.net is the NODERED_BASE_URL.
The NODERED_BASE_URL may have additional region information i.e. eu-gb for the UK region. In this case NODERED_BASE_URL would be: myApp.eu-gb.mybluemix.net.
In this Code pattern, we address the problem of extracting knowledge out of text and tables in word documents. A knowledge graph is built from the knowledge extracted making the knowledge queryable.
This pattern demonstrates a methodology to derive insights with IBM Cloud, Watson services, Python NLTK and IBM Data Science experience.
Click on the node named HTML.

Click on the HTML area and search for ws: to locate the line where the websocket URL is specified.
Update the websocket URL with the base URL that was noted in the Section 4:
var websocketURL = "ws://" + NODERED_BASE_URL + NODERED_websocket_path;

Click on Done and re-deploy the flow.
Update your NODERED BASE URL in the notebook, as shown below.

Add your NODERED BASE URL as shown below:
"ws://" + NODERED_BASE_URL + "/ws/abc"
Open a new tab and enter the following url with your NODERED_BASE_URL:
http://NODERED_BASE_URL/dsxinsights

Now you are ready to search in the search text area.
Follow the instructions given in the build knowledge-base with domain-specific documents to set-up the Notebook on IBM Data Science Experience. The only change is use this updated Notebook.
Problem Statement: Given an unstructured document, the system must be able to answer questions based on this document. This code pattern solves this problem using the following methodology:
-
Data Conversion: The given unstructured data maybe of the form of free floating text or in the form of a table. The algorithm extract raw text from the doc file and converts table contents to HTML and further a json, to extract information. Python mammoth was the library used to perform all the data conversions.
-
Building a Knowledge Graph: After all the information has been processed and extracted we require to identify the important entities and their relations. This is required so as to represent the obtained the information as a graph. The Entities and Relations are extracted using Watson NLU API along with augmented rules provided by the user. This graph will represent the important entities as nodes and the relationship between these nodes as relation edges. It is also known as a knowledge graph.
-
Extraction of Entities and Relationships: The problem is now reduced to the system being able to answer questions by querying the knowledge graph built in the previous step. When the user poses a question the questions is first represented in the form of POS tags. Using chunking we extract the nouns as entities and the verbs as relations.
-
Querying Knowledge Graph for Answers: The obtained knowledge graph is made a table of triplets- (node1, node2, relations). Using fuzzy logic techniques the entities and relations obtained from the question is searched for in the knowledge graph table. Thus, if a question is contains either one of the nodes and the relation, the answer to the question is bound to the other node. This way we can answer questions from any given document.
This code pattern is licensed under the Apache Software License, Version 2. Separate third party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 (DCO) and the Apache Software License, Version 2.