Comprehensive, on-demand open source intelligence for any website
🌐 web-check.xyz
Get an insight into the inner-workings of a given website: uncover potential attack vectors, analyse server architecture, view security configurations, and learn what technologies a site is using.
Currently the dashboard will show: IP info, SSL chain, DNS records, cookies, headers, domain info, search crawl rules, page map, server location, redirect ledger, open ports, traceroute, DNS security extensions, site performance, trackers, associated hostnames, carbon footprint. Stay tuned, as I'll add more soon!
The aim is to help you easily understand, optimize and secure your website.
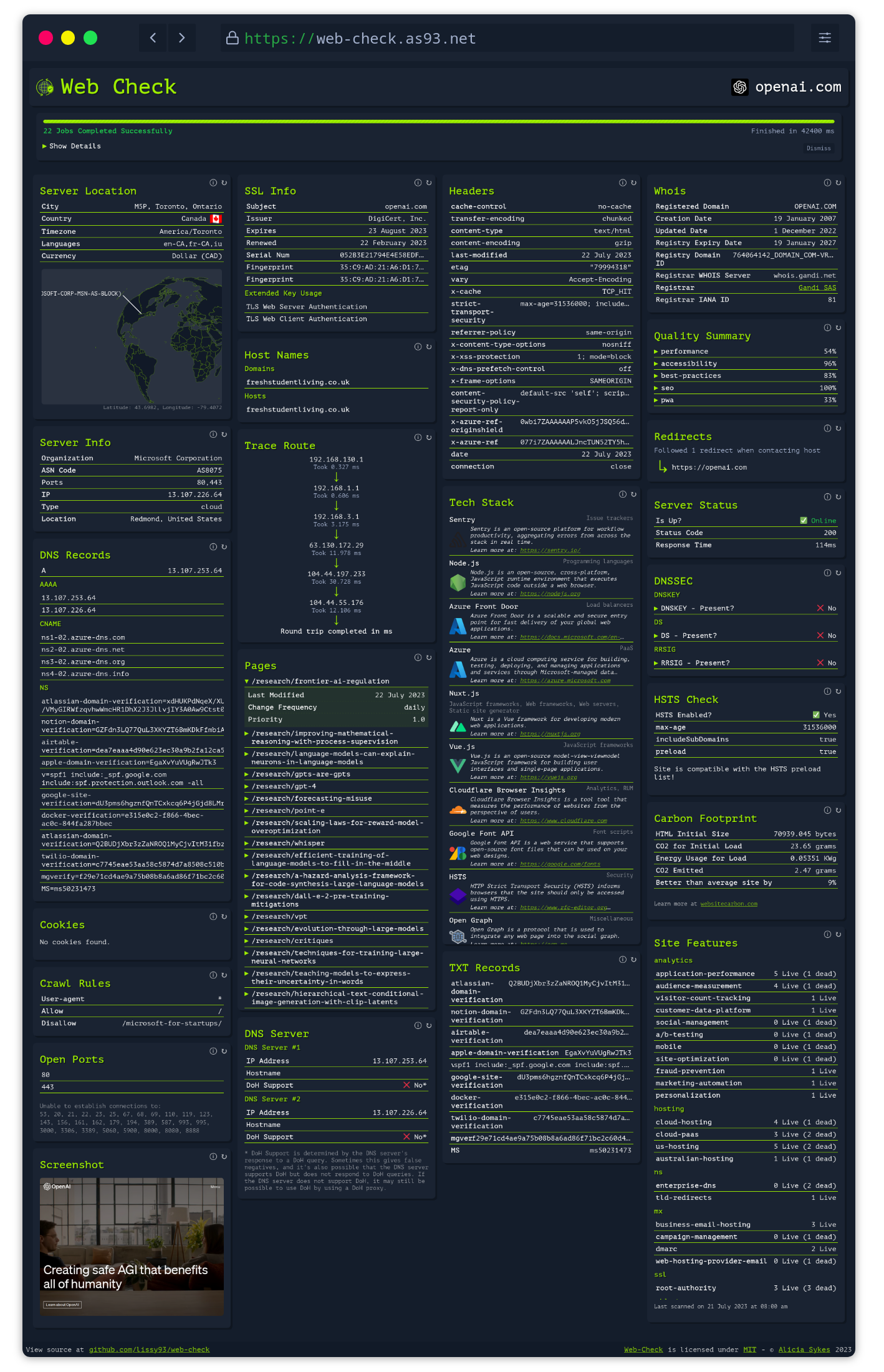
A hosted version can be accessed at: web-check.as93.net
The source for this repo is mirrored to CodeBerg, available at: codeberg.org/alicia/web-check
Often when you're looking into a website, there's several things you always initially check. Think: Whois, SSL chain, DNS records, tech stack, security protocols, crawl rules, sitemap, redirects, basic performance, open ports, server info, etc. None of this is hard to find with a series of basic curl commands, or a combination of online tools. But it's just so much easier to have everything presented clearly and visible in one place :)
Note this list needs updating, many more jobs have been added since...
IP Address
The IP Address task involves mapping the user provided URL to its corresponding IP address through a process known as Domain Name System (DNS) resolution. An IP address is a unique identifier given to every device on the Internet, and when paired with a domain name, it allows for accurate routing of online requests and responses.
Identifying the IP address of a domain can be incredibly valuable for OSINT purposes. This information can aid in creating a detailed map of a target's network infrastructure, pinpointing the physical location of a server, identifying the hosting service, and even discovering other domains that are hosted on the same IP address. In cybersecurity, it's also useful for tracking the sources of attacks or malicious activities.
SSL

The SSL task involves checking if the site has a valid Secure Sockets Layer (SSL) certificate. SSL is a protocol for establishing authenticated and encrypted links between networked computers. It's commonly used for securing communications over the internet, such as web browsing sessions, email transmissions, and more. In this task, we reach out to the server and initiate a SSL handshake. If successful, we gather details about the SSL certificate presented by the server.
SSL certificates not only provide the assurance that data transmission to and from the website is secure, but they also provide valuable OSINT data. Information from an SSL certificate can include the issuing authority, the domain name, its validity period, and sometimes even organization details. This can be useful for verifying the authenticity of a website, understanding its security setup, or even for discovering associated subdomains or other services.
DNS Records

The DNS Records task involves querying the Domain Name System (DNS) for records associated with the target domain. DNS is a system that translates human-readable domain names into IP addresses that computers use to communicate. Various types of DNS records exist, including A (address), MX (mail exchange), NS (name server), CNAME (canonical name), and TXT (text), among others.
Extracting DNS records can provide a wealth of information in an OSINT investigation. For example, A and AAAA records can disclose IP addresses associated with a domain, potentially revealing the location of servers. MX records can give clues about a domain's email provider. TXT records are often used for various administrative purposes and can sometimes inadvertently leak internal information. Understanding a domain's DNS setup can also be useful in understanding how its online infrastructure is built and managed.
Cookies

The Cookies task involves examining the HTTP cookies set by the target website. Cookies are small pieces of data stored on the user's computer by the web browser while browsing a website. They hold a modest amount of data specific to a particular client and website, such as site preferences, the state of the user's session, or tracking information.
Cookies provide a wealth of information in an OSINT investigation. They can disclose information about how the website tracks and interacts with its users. For instance, session cookies can reveal how user sessions are managed, and tracking cookies can hint at what kind of tracking or analytics frameworks are being used. Additionally, examining cookie policies and practices can offer insights into the site's security settings and compliance with privacy regulations.
Crawl Rules

The Crawl Rules task is focused on retrieving and interpreting the 'robots.txt' file from the target website. This text file is part of the Robots Exclusion Protocol (REP), a group of web standards that regulate how robots crawl the web, access and index content, and serve that content up to users. The file indicates which parts of the site the website owner doesn't want to be accessed by web crawler bots.
The 'robots.txt' file can provide valuable information for an OSINT investigation. It often discloses the directories and pages that the site owner doesn't want to be indexed, potentially because they contain sensitive information. Moreover, it might reveal the existence of otherwise hidden or unlinked directories. Additionally, understanding crawl rules may offer insights into a website's SEO strategies.
Headers

The Headers task involves extracting and interpreting the HTTP headers sent by the target website during the request-response cycle. HTTP headers are key-value pairs sent at the start of an HTTP response, or before the actual data. Headers contain important directives for how to handle the data being transferred, including cache policies, content types, encoding, server information, security policies, and more.
Analyzing HTTP headers can provide significant insights in an OSINT investigation. Headers can reveal specific server configurations, chosen technologies, caching directives, and various security settings. This information can help to determine a website's underlying technology stack, server-side security measures, potential vulnerabilities, and general operational practices.
Quality Report

The Headers task involves extracting and interpreting the HTTP headers sent by the target website during the request-response cycle. HTTP headers are key-value pairs sent at the start of an HTTP response, or before the actual data. Headers contain important directives for how to handle the data being transferred, including cache policies, content types, encoding, server information, security policies, and more.
Analyzing HTTP headers can provide significant insights in an OSINT investigation. Headers can reveal specific server configurations, chosen technologies, caching directives, and various security settings. This information can help to determine a website's underlying technology stack, server-side security measures, potential vulnerabilities, and general operational practices.
Server Location

The Server Location task determines the physical location of a server hosting a website based on its IP address. The geolocation data typically includes the country, region, and often city where the server is located. The task also provides additional contextual information such as the official language, currency, and flag of the server's location country.
In the realm of OSINT, server location information can be very valuable. It can give an indication of the possible jurisdiction that laws the data on the server falls under, which can be important in legal or investigative contexts. The server location can also hint at the target audience of a website and reveal inconsistencies that could suggest the use of hosting or proxy services to disguise the actual location.
Associated Domains and Hostnames

This task involves identifying and listing all domains and subdomains (hostnames) that are associated with the website's primary domain. This process often involves DNS enumeration to discover any linked domains and hostnames.
In OSINT investigations, understanding the full scope of a target's web presence is critical. Associated domains could lead to uncovering related projects, backup sites, development/test sites, or services linked to the main site. These can sometimes provide additional information or potential security vulnerabilities. A comprehensive list of associated domains and hostnames can also give an overview of the organization's structure and online footprint.
Redirect Chain

This task traces the sequence of HTTP redirects that occur from the original URL to the final destination URL. An HTTP redirect is a response with a status code that advises the client to go to another URL. Redirects can occur for several reasons, such as URL normalization (directing to the www version of the site), enforcing HTTPS, URL shorteners, or forwarding users to a new site location.
Understanding the redirect chain can be crucial for several reasons. From a security perspective, long or complicated redirect chains can be a sign of potential security risks, such as unencrypted redirects in the chain. Additionally, redirects can impact website performance and SEO, as each redirect introduces additional round-trip-time (RTT). For OSINT, understanding the redirect chain can help identify relationships between different domains or reveal the use of certain technologies or hosting providers.
TXT Records

TXT records are a type of Domain Name Service (DNS) record that provides text information to sources outside your domain. They can be used for a variety of purposes, such as verifying domain ownership, ensuring email security, and even preventing unauthorized changes to your website.
In the context of OSINT, TXT records can be a valuable source of information. They may reveal details about the domain's email configuration, the use of specific services like Google Workspace or Microsoft 365, or security measures in place such as SPF and DKIM. Understanding these details can give an insight into the technologies used by the organization, their email security practices, and potential vulnerabilities.
Server Status

Open Ports

Open ports on a server are endpoints of communication which are available for establishing connections with clients. Each port corresponds to a specific service or protocol, such as HTTP (port 80), HTTPS (port 443), FTP (port 21), etc. The open ports on a server can be determined using techniques such as port scanning.
In the context of OSINT, knowing which ports are open on a server can provide valuable information about the services running on that server. This information can be useful for understanding the potential vulnerabilities of the system, or for understanding the nature of the services the server is providing. For example, a server with port 22 open (SSH) might be used for remote administration, while a server with port 443 open is serving HTTPS traffic.
Traceroute

Traceroute is a network diagnostic tool used to track in real-time the pathway taken by a packet of information from one system to another. It records each hop along the route, providing details about the IPs of routers and the delay at each point.
In OSINT investigations, traceroute can provide insights about the routing paths and geography of the network infrastructure supporting a website or service. This can help to identify network bottlenecks, potential censorship or manipulation of network traffic, and give an overall sense of the network's structure and efficiency. Additionally, the IP addresses collected during the traceroute may provide additional points of inquiry for further OSINT investigation.
Carbon Footprint

This task calculates the estimated carbon footprint of a website. It's based on the amount of data being transferred and processed, and the energy usage of the servers that host and deliver the website. The larger the website and the more complex its features, the higher its carbon footprint is likely to be.
From an OSINT perspective, understanding a website's carbon footprint doesn't directly provide insights into its internal workings or the organization behind it. However, it can still be valuable data in broader analyses, especially in contexts where environmental impact is a consideration. For example, it can be useful for activists, researchers, or ethical hackers who are interested in the sustainability of digital infrastructure, and who want to hold organizations accountable for their environmental impact.
Server Info

This task retrieves various pieces of information about the server hosting the target website. This can include the server type (e.g., Apache, Nginx), the hosting provider, the Autonomous System Number (ASN), and more. The information is usually obtained through a combination of IP address lookups and analysis of HTTP response headers.
In an OSINT context, server information can provide valuable clues about the organization behind a website. For instance, the choice of hosting provider could suggest the geographical region in which the organization operates, while the server type could hint at the technologies used by the organization. The ASN could also be used to find other domains hosted by the same organization.
Domain Info

This task retrieves Whois records for the target domain. Whois records are a rich source of information, including the name and contact information of the domain registrant, the domain's creation and expiration dates, the domain's nameservers, and more. The information is usually obtained through a query to a Whois database server.
In an OSINT context, Whois records can provide valuable clues about the entity behind a website. They can show when the domain was first registered and when it's set to expire, which could provide insights into the operational timeline of the entity. The contact information, though often redacted or anonymized, can sometimes lead to additional avenues of investigation. The nameservers could also be used to link together multiple domains owned by the same entity.
DNS Security Extensions

Without DNSSEC, it's possible for MITM attackers to spoof records and lead users to phishing sites. This is because the DNS system includes no built-in methods to verify that the response to the request was not forged, or that any other part of the process wasn’t interrupted by an attacker. The DNS Security Extensions (DNSSEC) secures DNS lookups by signing your DNS records using public keys, so browsers can detect if the response has been tampered with. Another solution to this issue is DoH (DNS over HTTPS) and DoT (DNS over TLD).
DNSSEC information provides insight into an organization's level of cybersecurity maturity and potential vulnerabilities, particularly around DNS spoofing and cache poisoning. If no DNS secururity (DNSSEC, DoH, DoT, etc) is implemented, this may provide an entry point for an attacker.
- https://dnssec-analyzer.verisignlabs.com/
- https://www.cloudflare.com/dns/dnssec/how-dnssec-works/
- https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions
- https://www.icann.org/resources/pages/dnssec-what-is-it-why-important-2019-03-05-en
- https://support.google.com/domains/answer/6147083
- https://www.internetsociety.org/resources/deploy360/2013/dnssec-test-sites/
Read more here: web-check.as93.net/about
Note that not all checks will work for all sites. Sometimes it's not possible to determine some information, and the demo instance has some limitations imposed by Netlify for the lambda functions.
- Clone the repo,
git clone git@github.com:Lissy93/web-check.git - Cd into it,
cd web-check - Install dependencies:
yarn - Start the dev server, with
yarn dev
You'll need Node.js (V 18.16.1 or later) installed, as well as git.
Some checks also require chromium, traceroute and dns to be installed within your environment. These jobs will just be skipped if those packages arn't present.
Click the button below, to deploy to Netlify 👇
Run docker run -p 8888:3000 lissy93/web-check, then open http://localhost:3000
You can get the Docker image from:
- DockerHub:
lissy93/web-check - GHCR:
ghcr.io/lissy93/web-check - Or build the image yourself by cloning the repo and running
docker build -t web-check .
Follow the instructions in the Developing section above, then run yarn build && yarn start to build and serve the application.
By default, no configuration is needed. But there are some optional environmental variables that you can set to give you access to some additional checks
GOOGLE_CLOUD_API_KEY- A Google API key (get here). This can be used to return quality metrics for a siteTORRENT_IP_API_KEY- A torrent API key (get here). This will show torrents downloaded by an IPREACT_APP_SHODAN_API_KEY- A Shodan API key (get here). This will show associated host names for a given domainREACT_APP_WHO_API_KEY- A WhoAPI key (get here). This will show more comprehensive WhoIs records than the default jobSECURITY_TRAILS_API_KEY- A Security Trails API key (get here). This will show org info associated with the IPBUILT_WITH_API_KEY- A BuiltWith API key (get here). This will show the main features of a site
The above keys can be added into an .env file in the projects root, or via the Netlify UI, or by passing directly to the Docker container.
Contributions of any kind are very welcome, and would be much appreciated. For Code of Conduct, see Contributor Convent.
To get started, fork the repo, make your changes, add, commit and push the code, then come back here to open a pull request. If you're new to GitHub or open source, this guide or the git docs may help you get started, but feel free to reach out if you need any support.
If you've found something that doesn't work as it should, or would like to suggest a new feature, then go ahead and raise a ticket on GitHub. For bugs, please outline the steps needed to reproduce, and include relevant info like system info and resulting logs.
Lissy93/Web-Check is licensed under MIT © Alicia Sykes 2023.
For information, see TLDR Legal > MIT
Expand License
The MIT License (MIT)
Copyright (c) Alicia Sykes <alicia@omg.com>
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sub-license, and/or sell
copies of the Software, and to permit persons to whom the Software is furnished
to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included install
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANT ABILITY, FITNESS FOR A
PARTICULAR PURPOSE AND NON INFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
© Alicia Sykes 2023
Licensed under MIT
Thanks for visiting :)
