hate5sync
hate5sync is a dumb algorithm used to calculate the necessary offset for syncing separate audio/video sources in OBS. Play slate.mp4 on a device (ie your phone) pointed at the camera and microphone and record it within OBS. Let's call that recorded file claptest.mp4. For best results, cover the entire camera lens with the phone and minimize background noise. Any light leaks or things besides the full black screen will trip the visual peak detector. Run this script on claptest.mp4 and it will calculate the offset between the visual and acoustic peaks. The app uses OBS websockets to automatically update the offset field. Click the image above to watch a demo.
Installation:
The following dependencies are required:
- open-cv
- librosa
- ffmpeg
- numpy
- easygui
- obs-websocket server
- obs-websocket Python library
- matplotlib (for debug mode)
Or you can just use the requirements.txt file
pip install -r requirements.txt
or
conda create --name <env_name> --file requirements.txt
The latest version of the app automatically updates the sync offset field through OBS websockets. You will need to download OBS websockets from the link above and follow the installation instructions carefully. With OBS running, you can now run hate5sync and it will communicate directly with OBS. If you've installed it correctly, you should see this when you reboot OBS or by going to Tools>Websockets Server Settings.

You can leave the defaults but changing the password is recommended.
Running hate5sync:
OBS must be running first (with websockets enabled) before running hate5sync.
You can run hate5sync with the following arguments:
usage: hate5sync.py [-h] [--infile INFILE] [--dir DIR] [--host HOST] [--port PORT] [--pw PW] [--src SRC]
hate5sync
options:
-h, --help show this help message and exit
--infile INFILE path to file
--dir DIR path to directory
--host HOST OBS websocket host
--port PORT OBS websocket port
--pw PW OBS websocket password
--src SRC OBS source name to be offset
--debugger, --no-debugger
Debug mode to display relative peaks (default: False)
- Use --infile to pass in the video file recorded in OBS.
- or use --dir to pass in the video recording directory and the most recent file will be used.
- or if neither --infile or --dir are set the app will retrieve the default OBS recording directory.
- If you are not using the default host/port/password for OBS websockets, use the corresponding options to override the defaults.
- Use --src to specify the name of source in OBS that needs the offset applied. If this option is not set you will be presented with a dialog box asking you to choose.
- --debugger will display a plot of the brightness and peak audio to help analyze faulty sync attempts. No changes will be applied to OBS in this mode.

For example, running
python -i hate5sync.py --pw password --src "Mic/Aux"
will retrieve the latest file recorded in OBS using the default directory, compute the delay, then automatically set the offset to the Mic/Aux source.
Personally I save the latter line to a file called hate5sync.bat and assign to a button via StreamDeck:

How it works:
The algorithm is literally so stupid.First it loads claptest.mp4
video_stream = cv2.VideoCapture(video_file)
fps = video_stream.get(cv2.CAP_PROP_FPS)
Then it loops over the video frame by frame. We use open-cv to convert each frame to the LAB colorspace. All we care about the L channel, which captures lightness (intensity). L ends up being a matrix the size of the video frame (1920x1080). Then we compute the mean value of that matrix to get the average brightness of that image. Store that in a list called brightness and repeat the process on the next frame.
success,image = video_stream.read()
brightness = []
while success:
L, A, B = cv2.split(cv2.cvtColor(image, cv2.COLOR_BGR2LAB))
L_mean = np.mean(L)
brightness.append(L_mean)
success,image= video_stream.read()
If we plot the values stored in brightness we get something that looks like

Next, we find the frame with the maximum brightness, which should correspond to the moment the flash appears on screen:
peak_video = np.argmax(brightness)
The audio portion is even dumber. First we'll use ffmpeg to extract the audio from claptest.mp4 and store it to a temporary wav file:
audio_stream = str(os.path.splitext(video_file)[0]) + ".wav"
ffmpeg.input(video_file).output(audio_stream).run()
Then we'll use librosa to read in that wav file along with the sampling rate, which we'll need for finding the peak audio frame
y,sr = librosa.load(audio_stream, sr=None)
Plotting the waveform will look something like this

All we care about is the frame where the audio peaks. To get that we just need the time-series sampled wav data returned by librosa (y), and find the sample (position) with the highest value, divide it by the sampling rate (sr) to get the position in seconds, then mulitply that by the framerate (frames per second fps) to get its frame position:
peak_audio = fps*np.argmax(y)/sr
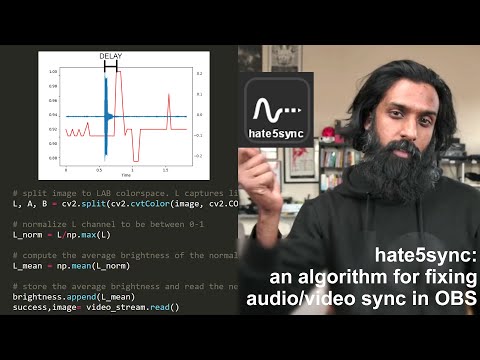
Overlaying the data we get something like this

Finally, we take the difference between the peaks (as frames), divide it by the framerate to get the difference in seconds:
delay = (peak_video - peak_audio)/fps
That delay is then automatically applied to the specified source in OBS.
Ways you can support my work: