This project aims at importing a previous MongoDB NoSQL document-based database for the sentiment analysis of the Tweets in Neo4j. The main objective is to compare performances between the two different systems on the selected queries of interest.
The database module contains:
- the
CRUDfolder, containing the CRUD operations, - the
datafolder, containing the JSON files with the data to be loaded into the database, - the
queriesfolder containing the main operations to be performed in the database, - the
db_manager.pyfile which contains a manager class, with the aim of performing the main operations on the nodes and the relationships of the database, - the
model.pyfile.
In order to deal with the graph database in Neo4j in a simpler way, I decided to use neomodel as OGM (Object Graph Mapper), which is based on the neo4j python driver. This file contains the classes mapping the nodes and the reationships of the database.
The manager performs the connection to the database during the initialization and allows to perform the more general operations.
This file contains some functions to create trends, tweets, users or comments.
This file contains some functions to read trends for a given tweet, tweets for a given trend, the user who wrote a tweet, the tweets for a given user or the comments for a given tweet.
This file contains some functions to update trends, tweets, users or comments.
This file contains some functions to delete trends, tweets, users or comments.
This file contains a function for each of the 7 main queries performed by this database in its original version.
This file contains other simpler general functions to be performed in the database.
In the following figure are plotted the benchmarks of the queries in the file complex_queries.py in both the original document-based DMS and the graph-based one.
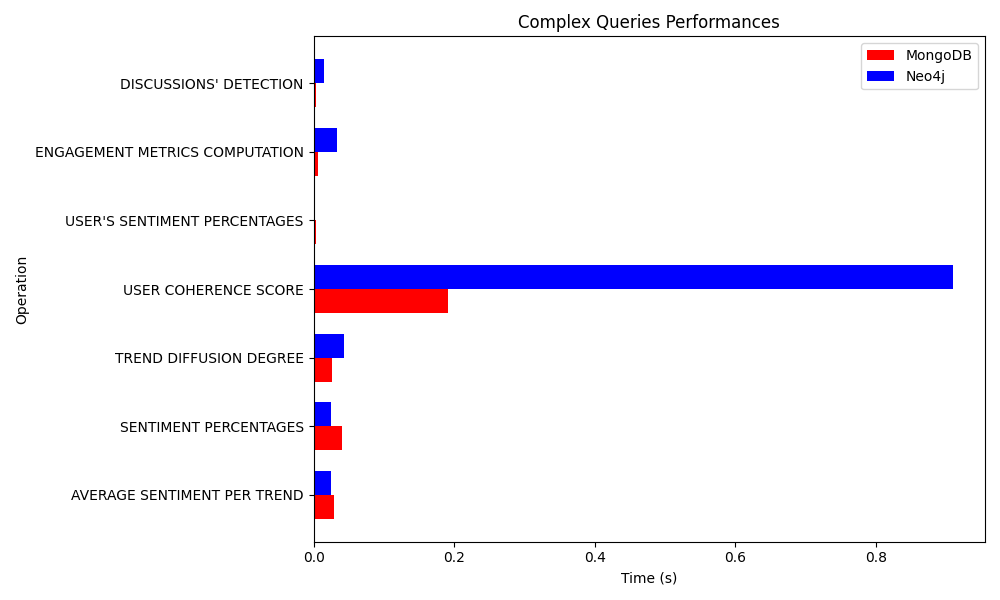
In the following figure are plotted the benchmarks of the queries in the file other_queries.py in both the original document-based DMS and the graph-based one.
