

Task queues backed by Elasticsearch (ES): Tasques
Pronounced: /tɑːsks/, like "tasks"
You know, for Background Tasks !
Why use ES as a Tasks data store? It's horizontally scalable, highly-available, and offers a lot of built-in ways to manage your data (lifecycle management, snapshots, etc).

- Easily scalable:
- Servers are stateless; just spin more up as needed
- The storage engine is Elasticsearch, nuff' said.
- Tasks are configurable:
- Priority
- Schedule to run later
- Retries with exponential increase in retry delays.
- Recurring Tasks that are repeatedly enqueued at configurable intervals (cron format with basic macro support à la
@every 1m) - Timeouts for Tasks that are picked up by Workers but either don't report in or finish on time.
- Archiving of completed Tasks (DONE or DEAD), also configurable
- If Index Lifecycle Management (ILM) is enabled (default), the archive index is set to roll over automatically for easy management of old data.
- Unclaiming allows Tasks that get picked up but can't be handled to be requeued without consequence.
- API is exposed as Swagger; easily generate clients in any language:
- Use the client to enqueue Tasks from your application
- Workers are just a loop around the client, then your own business logic to do the actual work.
- Pre-seeded Kibana Index Patterns and Dashboards for monitoring tasks.
- Simple configuration: use a config file, optionally override with environment variables (12 factor-ready).
- Application Performance monitoring: metrics are exported to APM and available again from Kibana (more below)
Tasques is available as a small Docker image, with images
published automatically by CI upon pushes/merges to master and tag pushes.
To get a quick idea of what is included and how to get up and running with Kubernetes:
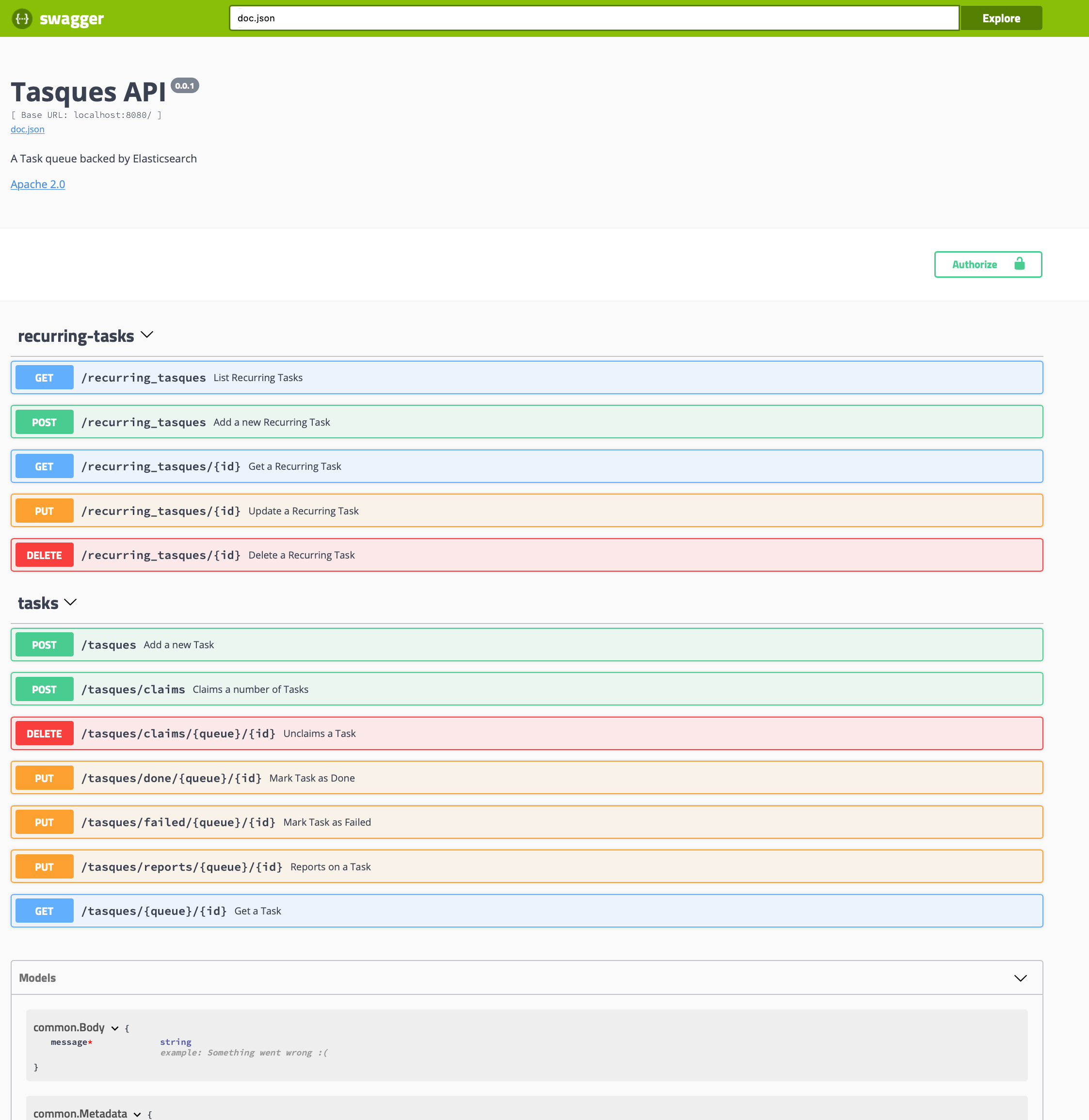
- Go to
docker/k8sand runmake install-eck deploy, and wait until the pods are all ready (kubectl get pods) - For Swagger, go to localhost:8080/swagger/index.html
- To log into Kibana for dashboards and APM stats, run
make show-credentialsto get theelasticuser password, and go to localhost:5601 to log in.

There is also an example project that demonstrates the application-tasques-worker relationship more thoroughly; please
see example/ciphers for more details.

The server supports APM, as configured according to the official docs.
The Tasque server is in principle stateless; but there are internal recurring jobs that need to be taken care off, like monitoring claimed Tasks and timing them out as needed, and scheduling recurring Tasks.
These internal jobs only occur on the Leader server, as determined by a leader lock. By spinning up more than one Tasque server, you not only gain the benefits of being able to handle more load, but also shield yourself from potential disruptions in the running of these internal Tasks, as a new Leader will be elected and take over if the current Leader loses connectivity or is terminated.
Running multiple servers also allows for zero-downtime rollouts of new versions of Tasques server.
Assuming there is no data loss at the ES level, Tasques provides at-least-once delivery, ensuring that it only allows a single Worker (identified by Id) to have claim on a Task at any given time.
If there is data loss/recovery (snapshot recovery, ES node loss), jobs might be handed out twice, so it's a good idea to make job handling idempotent.
Requires Go 1.13+.
- Install
Go - Use your favourite editor/IDE
- For updating Swagger docs:
- Install Swaggo
- Run
swag init -g app/main.gofrom the root project dir- Check that there are no
time.Timefields... there's a race condition in there somewhere
- Check that there are no
- Commit the generated files.
- For updating the Go Client:
- Install go-swagger
- Run
swagger generate client -f docs/swagger.yaml - Commit the generated files.
Unit tests: go test ./...
Integration tests: go test -tags=integration ./... (finds // +build integration at the top o IT files)
The code emphasises the following:
- Safety: the code needs to do the right thing. Use built-in features (locks, typed ids) and tests to help maximise safety.
- Efficiency: the server and its code should be reasonably efficient so that it can handle high loads.
- Observability: where reasonable, pass a
Contextaround so we can export performance metrics. This is a must when making any kind of IO call. - High availability: the server needs to be able to run in a highly available way to maximise robusness.
- Simplicity: the API needs to be simple and easy to use
- Maintainability: the internals need to be as simple as possible and invite contributions. Use the rule of 3 to know when something should be generalised. If in doubt, repeat yourself.
This project was inspired by the following, in no particular order