This is an attempt to reproduce the Lottery Ticket Hypothesis (LTH) paper by Frankle and Carbin.
This paper in a few words: 1) Train network 2) Prune unecessary weights/connections. It would be great to figure out how to identify the subnetwork without having to build and train full network. This pruning method can reduce the number of parameters by 10x while maintaining the same performance. See this article for more.
- Open LTH Framework
- Re-implementation by original author at Google
- Pruning w/ PyTorch
- Sparse Transfer Learning code
- Uber paper code
Based on this paper
- Number of Tables: 1
- Number of Graphs/Plots: 25 (paper), 131 (appendix)
- Number of Equations: 7
- Proofs: 0
- Exact Compute Specified: NOT SPECIFIED
- Hyperparameters:
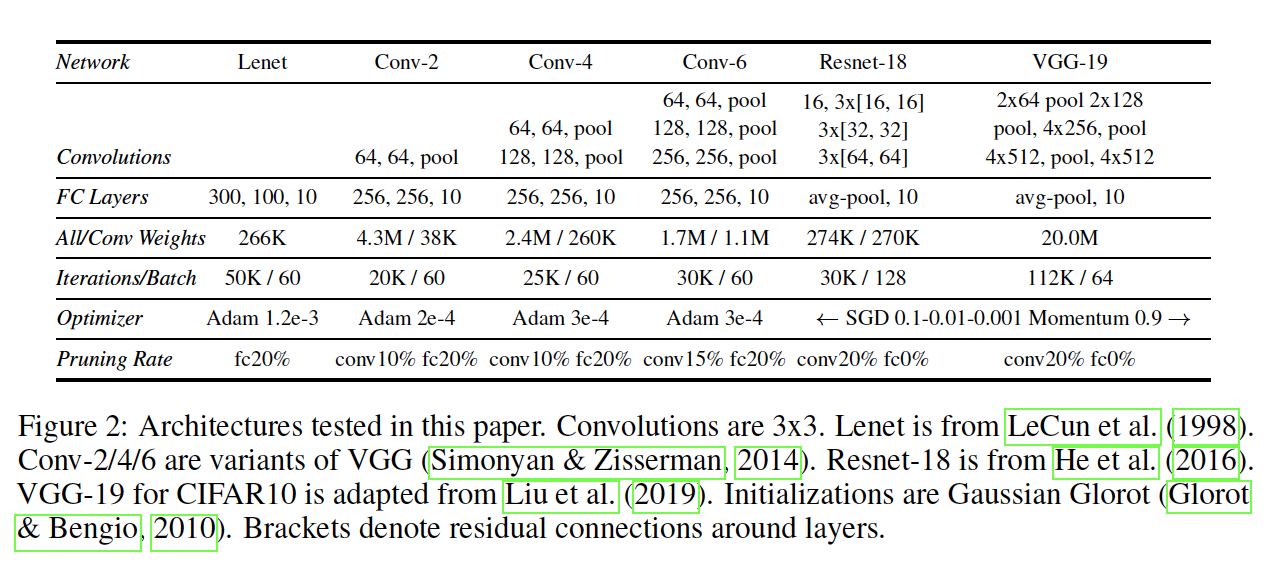
- Compute Needed: NOT SPECIFIED
- Data Available: CIFAR and MNIST
- Pseudo Code: Level 2 ("Step-Code", high level)

- Number of Conceptualization Figures: 0
- Uses Exemplar Toy Problem: No
- Number of Other Figures: 0
- Rigor vs Empirical: Empirical
- Paper Readability: Good
- Algorithm Difficulty: Medium
- Paper Topic: Experimental Results
- Intimidating: No
- Paperspace GPUs. Currently we are using the ML-in-a-box instance.
- Can't prune every layer equally, keep track of that stuff
- Learning rate matters for the bigger models but not as much for the smaller models
- Be careful using pytorch in-built pruning
- By iteration j, they mean one batch right?
- Yes.
- Do you know the details of early stopping? Min_delta? Patience? Min validation loss? And patience usually refers to epochs right?
- Not sure. Seems arbitrary.
- Is there a reason you didn't use pytorch pruning and implemented it yourself?
- Wasn't available at the time
- Separate train function for each epoch? So you can do per-batch and check early stop?
- If p = 20%, is that 20% globally? How do you prune layer-wise?
- Pruning rates specified in paper, different from % of weights remaining
- By test accuracy, are they referring to validation accuracy?
- No, actually test accuracy.
- Tips:
- Train/Valid/Test split
- Don't prune biases
- When early stopping would have occured, don't actually stop though
- Follow data augmentation steps in paper (pixel pads and crops)
- Lottery ticket sensitive to batch size
- Week 1: Reproduce MNIST ~98% in PyTorch
- Week 2: Reproduce Figure 1 from paper
- Week 4: Reproduce Section 2: Winning Tickets in Fully-Connected Networks
- Week 6-8: Reproduce Section 3: Winning Tickets in Convolutional Networks
CD into src/ and run python mnist_experiment.py
You can adjust parameters in config/mnist_config.gin.
Explanations of the parameters are in experiments/mnist_experiment.py.
Interestingly, the authors implemented a 300-100 LeNet architecture
without the convolutional layers, achieving performance around ~98%.
We were able to achieve similar results on a validation set after
5 epochs of 60K iterations: Accuracy: 9806/10000 (98.06%). We also reach
Accuracy: 9755/10000 (97.55%) with just one epoch or 60K iterations.
Some details on the architecture and hyperparameters:
- MNIST Images:
[1, 28, 28] - 3 Fully Connected Layers
- Batch Size:
60 - Optimizer: Adam
- Learning Rate:
1.2e-3 - StepLR Scheduler (not sure what the authors used)
Adam with lr=1.0 did not converge, though Adadelta with lr=1.0 did converge.
Ultimately, we used Adam and lr=1.2e-3.
- [Might skip] Refactor Train/Test using Ignite
- Early Stopping
- Implement iterative pruning on LeNetFC
- Similar to re-implementation
- May also try pytorch pruning
- Or pruning from OpenLTH
- Lenet model is without Conv layers, just (300-100-10 linear layers)
- Read the appendix for specifics on experiments
- Avoid
prunemodule in torch- good for one-shot pruning, not iterative pruning
- Iterative pruning rate:
- e.g. if paper says 7 rounds of pruning and fc20% (.002)
- that means: (.002)^(1/7) = .41, so prune 41% of the remaining weights at each step
0. 100% ((.002)^(1/7))^0
- 41.1% ((.002)^(1/7))^1
- 16.9% ((.002)^(1/7))^2
- 7.0% ((.002)^(1/7))^3
- 2.9% ((.002)^(1/7))^4
- 1.2% ((.002)^(1/7))^5
- 0.5% ((.002)^(1/7))^6
- 0.2% ((.002)^(1/7))^7
Our reproducibility efforts are ongoing. Setting up models was easy with torch.
The most difficult part is the implementation of iterative pruning.
We tried used torch's prune module, which looked very appealing
and simple but only worked well for one-shot pruning and failed for iterative pruning.
Iterative pruning is working in terms of how many weights are being pruned at each step and re-initializing to the weights of the original network. Despite this, test accuracy goes down significantly the more we prune. This may be because we are still have early stopping implemented (as opposed to just recording when it would have happened) or possibly because out validation data is a subset of our train data. This is due to to the fact that torch splits MNIST into train (60K) and test (10K) without a validation set. So those are two things to try first when debugging this.