Welcome to the Zeitghost - Build Your Own News & Media Listening Platform with a Conversational Agent
Update - 7.20.23 - Streamlit UI
A hardcoded example of running a UI application with Streamlight is now found in notebooks/07-streamlit-ui-plan-and-execute.py
pip install streamlit
Also, upgrade langchain and sqlalchemy-bigquery:
pip install -U langchain
pip install -U sqlalchemy-bigquery
To run the UI:
cd notebooks
streamlit 07-streamlit-ui-plan-and-execute.py
Your browser will pop up with with the UI

The repo contains a set of notebooks and helper classes to enable you to create a conversational agent with access to a variety of datasets and APIs (tools) to answer end-user questions.
By the final notebook, you'll have created an agent with access to the following tools:
- News and media dataset (GDELT) index comprised of global news related to your
ACTOR - The Google Trends public dataset. This data source helps us understand what people are searching for, in real time. We can use this data to measure search interest in a particular topic, in a particular place, and at a particular time
- Google Search API Wrapper - to retrieve and display search results from web searches
- A calculator to help the LLM with math
- An SQL Database Agent for interacting with SQL databases (e.g., BigQuery). As an example, an agent's plan may require it to search for trends in the Google Trends BigQuery table
Below is an image showing the user flow interacting with the multi-tool agent using a plan-execute strategy:

Here's an example of what the user output will look like in a notebook:

GDELT: A global database of society
Google's mission is to organise the world's information and make it universally accessible and useful. Supported by Google Jigsaw, the GDELT Project monitors the world's broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organizations, themes, sources, emotions, counts, quotes, images and events driving our global society every second of every day, creating a free open platform for computing on the entire world.
Monitoring nearly the entire world's news media is only the beginning - even the largest team of humans could not begin to read and analyze the billions upon billions of words and images published each day. GDELT uses some of the world's most sophisticated computer algorithms, custom-designed for global news media, running on "one of the most powerful server networks in the known Universe", together with some of the world's most powerful deep learning algorithms, to create a realtime computable record of global society that can be visualized, analyzed, modeled, examined and even forecasted. A huge array of datasets totaling trillions of datapoints are available. Three primary data streams are created, one codifying physical activities around the world in over 300 categories, one recording the people, places, organizations, millions of themes and thousands of emotions underlying those events and their interconnections and one codifying the visual narratives of the world's news imagery.
All three streams update every 15 minutes, offering near-realtime insights into the world around us. Underlying the streams are a vast array of sources, from hundreds of thousands of global media outlets to special collections like 215 years of digitized books, 21 billion words of academic literature spanning 70 years, human rights archives and even saturation processing of the raw closed captioning stream of almost 100 television stations across the US in collaboration with the Internet Archive's Television News Archive. Finally, also in collaboration with the Internet Archive, the Archive captures nearly all worldwide online news coverage monitored by GDELT each day into its permanent archive to ensure its availability for future generations even in the face of repressive forces that continue to erode press freedoms around the world.
For more information on how to navigate the datasets - see the GDELT 2.0 Data format codebook
** How to add GDELT 2.0 to your Google Cloud Project **

Large Data from GDELT needs Effective and Efficient Knowledge Retrieval
Simply accessing and storing the data isn't enough. Processing large queries of news sources from GDELT is easy to do with BigQuery, however to accelerate exploration and discovery of the information, tools are needed to provide semantic search on the contents of the global news and media dataset.
Vertex AI Matching Engine provides the industry's leading high-scale low latency vector database. These vector databases are commonly referred to as vector similarity-matching or an approximate nearest neighbor (ANN) service. Vertex AI Matching Engine provides the ability to scale knowledge retrieval paired with our new Vertex Embeddings Text Embeddings. We use document chunking and newspaper3k to pull down the articles and convert the document passages into embeddings with the Vertex Embeddings API (via Python SDK).
Below is an example depiction of the information architecture, utilizing Matching Engine and the text embeddings model.

Leveraging GenAI Language Models to get Relevant & Real-time Information Using Conversational Agents
More than ever, access to relevant and real-time information to make decisions and understand changing patterns and trends critical. Whilst GDELT contains a massive amount of relevant and real-time (up to every 15 min) data, it can be challenging and overwhelming to make sense of it and extract what is most important for specific areas of interest, topics, events, entities. This project, the Zeitghost, provides a reference solution for how you can specify your entities and events of interest to extract from GDELT, index and load them into a vector database, and leverage the Vertex AI Generative Language models with Langchain Agents to interact in a Q&A style with the information. We also show how you can orchestrate and schedule ongoing refreshes of the data to keep the system up to date with the latest information.
For more information about getting started with Langchain Agents, see Langchain Examples
Finally, to go beyond an agent with one chain of thought along with one tool, we explore how you can start to combine plan-and-execute agents together. Plan-and-execute Agents accomplish an objective by first planning what to do, then executing the sub tasks
- This idea is largely inspired by BabyAGI and the Plan-and-Solve paper.
- The planning is almost always done by an LLM.
- The execution is usually done by a separate agent (equipped with tools) By allowing agents with access to different source data to interact with each other, we can uncover new insights that may not have been obvious by examining each of the datasets in isolation.
Solution Overview
Architecture

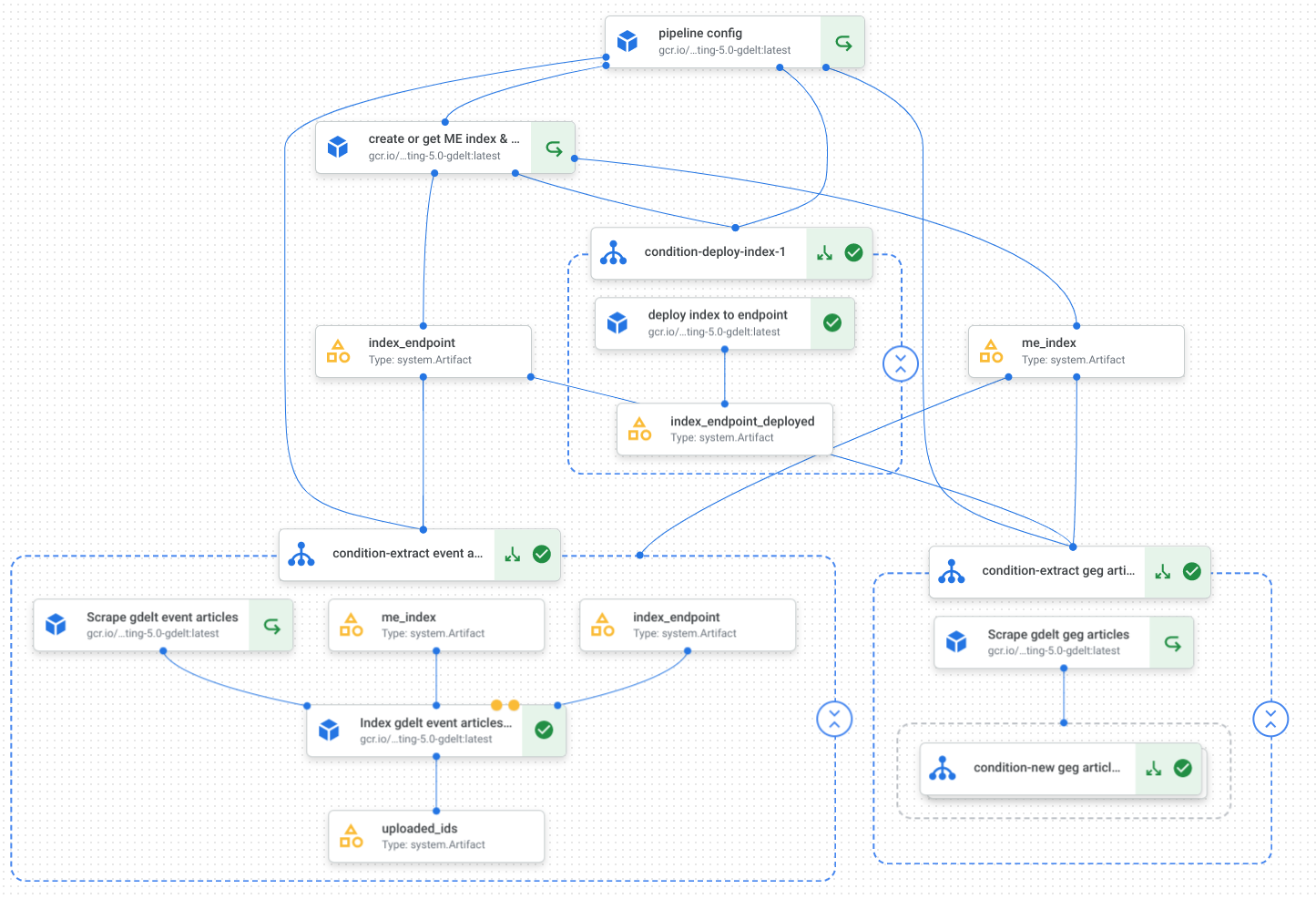
Component Flow
This project consists of a series of notebooks leveraging a customized code base to:
- Filter and extract all of the relevant web URLs for a given entity from the GDELT global entity graph or a type of global event for a specified time period leveraging the GDELT data that is publicly available natively in BigQuery. An example could be an ACTOR='World Health Organization', for the time period of March 2020 to Present, including events about COVID lockdown.
- Extract the full article and news content from every URL that is returned from the GDELT datasets and generate text embeddings using the Vertex AI Embeddings Model
- Create a Vertex AI Matching Engine Vector Database Index deploy it to an Index Endpoint
- Stream update generated embeddings into the Matching Engine Vector Database Index
- Create a managed pipeline to orchestrate the ongoing refresh of the GDELT data into the Matching Engine Vector DB
- Test the generic semantic search capabilities of the Vector DB, and test using a Langchain Agent with one chain of thought along with one tool
- Create a plan-and-execute agent framework where different agents (the GDELT Langchain agent, a BigQuery public trends agent, and a Google Search API agent) are able to talk to each other to answer questions

Next, we are currently working on adding:
- An application to build and deploy the conversational agent as an API on Google Cloud Run - where it can then be integrated into any application.
- A customizable front end reference architecture that uses the agents once , which can be used to showcase the art of the possible when working
- Incorporating future enhancements to the embedding techniques used to improve the relevancy and performance of retrieval
How to use this repo
- Setup VPC Peering
- Create a Vertex AI Workbench Instance
- Run the notebooks
Important: be sure to create Vertex AI notebook instance within the same VPC Network used for Vertex AI Matching Engine deployment
If you don't use the same VPC network, you will not be able to make calls to the matching engine vector store database
Step 1: Setup VPC Peering using the following gcloud commands in Cloud Shell
- Similar to the setup instructions for Vertex AI Matching Engine in this Sample Notebook, there are a few permissions needed in order to create the VPC network and set up VPC peering
- Run the following
gcloudcommands in Cloud Shell to create the network and VPC peering needed for deploying Matching Engine indexes to Private Endpoints:
VPC_NETWORK="YOUR_NETWORK_NAME"
PROJECT_ID="YOUR_PROJECT_ID"
PEERING_RANGE_NAME="PEERINGRANGENAME"
# Create a VPC network
gcloud compute networks create $VPC_NETWORK --bgp-routing-mode=regional --subnet-mode=auto --project=$PROJECT_ID
# Add necessary firewall rules
gcloud compute firewall-rules create $VPC_NETWORK-allow-icmp --network $VPC_NETWORK --priority 65534 --project $PROJECT_ID --allow icmp
gcloud compute firewall-rules create $VPC_NETWORK-allow-internal --network $VPC_NETWORK --priority 65534 --project $PROJECT_ID --allow all --source-ranges 10.128.0.0/9
gcloud compute firewall-rules create $VPC_NETWORK-allow-rdp --network $VPC_NETWORK --priority 65534 --project $PROJECT_ID --allow tcp:3389
gcloud compute firewall-rules create $VPC_NETWORK-allow-ssh --network $VPC_NETWORK --priority 65534 --project $PROJECT_ID --allow tcp:22
# Reserve IP range
gcloud compute addresses create $PEERING_RANGE_NAME --global --prefix-length=16 --network=$VPC_NETWORK --purpose=VPC_PEERING --project=$PROJECT_ID --description="peering range"
# Set up peering with service networking
# Your account must have the "Compute Network Admin" role to run the following.
gcloud services vpc-peerings connect --service=servicenetworking.googleapis.com --network=$VPC_NETWORK --ranges=$PEERING_RANGE_NAME --project=$PROJECT_ID
Step 2: Create Vertex AI Workbench notebook using the following gcloud command in Cloud Shell:
- Using this base image will ensure you have the proper starting environment to use these notebooks
- You can optionally remove the GPU-related flags
INSTANCE_NAME='your-instance-name'
gcloud notebooks instances create $INSTANCE_NAME \
--vm-image-project=deeplearning-platform-release \
--vm-image-family=tf-ent-2-11-cu113-notebooks-debian-11-py39 \
--vm-image-family=tf-latest-cu113-debian-11-py39 \
--machine-type=n1-standard-8 \
--location=us-central1-a \
--network=$VPC_NETWORKStep 3: Clone this repo
- Once the Vertex AI Workbench instance is created, open a terminal via the file menu: File > New > Terminal
- Run the following code to clone this repo:
git clone https://github.com/hello-d-lee/conversational-agents-zeitghost.gitStep 4: Go to the first notebook (00-env-setup.ipynb), follow the instructions, and continue through the remaining notebooks
- Environment Setup - used to create configurations once that can be used for the rest of the notebooks
- Setup Vertex Vector Store - create the Vertex AI Matching Engine Vector Store Index, deploy it to an endpoint. This can take 40-50 min, so whilst waiting the next notebook can be run.
- GDELT DataOps - parameterize the topics and time period of interest, run the extraction against GDELT for article and news content
- Vector Store Index Loader - create embeddings and load the vectors into the Matching Engine Vector Store. Test the semantic search capabilities and langchain agent using the Vector Store.
- Build Zeitghost Image - create a custom container to be used to create the GDELT pipeline for ongoing data updates
- GDELT Pipelines - create the pipeline to orchestrate and automatically refresh the data and update the new vectors into the matching engine index
- Plan and Execute Agents - create new agents using the BigQuery public trends dataset, and the Google Search API, and use the agents together to uncover new insights