Whispering Tiger UI is a Native-UI that can be used to control the Whispering Tiger application.
Whispering Tiger is a free and Open-Source tool that can listen/watch to any audio stream or in-game image on your machine and prints out the transcription or translation to a web browser using Websockets or over OSC (examples are Streaming-overlays or VRChat).


- Features
- Download
- Tutorials
- Installation
- Setup
- Advanced Features
- Additional Help (Discord)
- Screenshots
- Native-UI for Windows (and possibly Linux in the future)
- Easy to use for both beginners and advanced users
- Access to all Whispering Tiger features, which includes:
- Transcription / Translation of audio streams
- Translation of Texts
- Text-to-Speech
- Recognition and Translation of in-game images
- Displaying the results in a web browser or VRChat, using Websockets or OSC
- Loopback audio device support to capture PC audio without additional tools
- Save and load configurations
- Preview if your selected Audio devices are working
- Plugin support for additional features (Find a list of Plugins here)
- Realtime Subtitles Plugin
- Many Text2Speech Plugins
- Emotion Prediction Plugin
- Currently Playing Song Plugin
- Subtitle Export Plugin
- Retrieval-based Voice Conversion (RVC) Plugin
- Large Language Models Plugin
- and more...
- Auto-Update to the latest version of Whispering Tiger.
Download Latest Version from the Releases Page.

-
Video Tutorial "Whispering Tiger - Live Translation and Transcription":

-
After downloading the latest version from the [Releases], extract it to a folder of your choice on a drive with enough free space.
(Do not run it directly from the zip file, do not run from external drive.)
-
Install CUDA for GPU Acceleration (Optional but recommended for NVIDIA GPUs).
-
Run the Whispering Tiger.exe file.
-
Let it download the latest version of Whispering Tiger. (It will ask to download the Platform.)
-
After the download is finished, you can create a Profile and start using the Whispering Tiger application.
- On the first start, it will start downloading the A.I. Models which can take a while depending on your selected Model size. (currently it does not show the status of the model downloads)
-
Create a Profile by entering a name and clicking on the New button.
-
Websocket IP + Portcan be kept at the default values "127.0.0.1" and "5000".- These are only useful if you want to run multiple instances or have the Backend Platform run on a separate PC.
- If you want to run multiple instances, you need to change the Port for each instance.
-
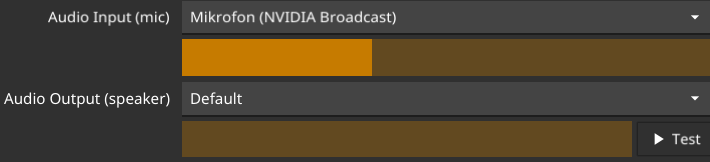
Select your Audio Input and Output devices. You can test them by speaking into your microphone and clicking on the Test button.
-
You should see the Audio Input bar move when you speak. and hear a test-audio and see the Audio Output bar move when you click on the Test button.
-
See also Audio configuration (TTS to Mic, Game Audio translation, etc.) for more information on specific Audio Setups.
(like when you want to translate Audio of Games, Videos or Streams that are played on your PC instead of using a Microphone as Input.).
-
-
(Optional) use Push to Talk Click into the field and press the keys you want to use for Push to Talk
(press each key separately to configure. When running the Profile, all keys will be required to be pressed at the same time when using Push to Talk)
- To disable autodetect of speech to only use Push to Talk, set
Speech volume LevelandSpeech pause detectionto 0.
- To disable autodetect of speech to only use Push to Talk, set
-
Keep an eye on the estimated Memory consumption in the lower right corner.
It is only a rough estimate and can vary, but it should give you an idea of how much (V-)RAM you need for your selected A.I. Models. and Options.

-
Select the A.I. Device for Speech-to-Text and Text Translation according to your Hardware.
- CUDA (requires an NVIDIA GPU) or CPU.
- CUDA will load the A.I. into V-RAM and will be faster than CPU.
-
Select the Speech-to-Text Size and Text Translation Size.
- The larger the size, the more accurate but also slower the transcription will be.
- The larger the size, the more (V-)RAM it will use.
- Note: The A.I. Model of the selected size and precision will be downloaded automatically when you start the application for the first time.
-
Select the Speech-to-Text Precision and Text Translation Precision
- The higher the precision, the more accurate and the more (V-)RAM is used. (However the accuracy differences are almost negligible).
- Modern GPU's have a better acceleration for
float16. - CPU's only support
float32,int16orint8precision.


Note:
- You can play with the values until you get your desired results.
- If something does not work, check the Log under the Advanced tab. And check for any error.
- Enable Write log to file to save the log to a file.
- Install Plugins using the UI directly, or..
- Install Plugins manually.
- Select your desired Plugin from the list of Plugins here.
- Download the
*.pyfile and place it in the Plugins folder. - Restart the application.
- The Plugin should now be available in the Plugins tab.
Note:
Most Plugins have specific settings that can be configured in the textboxes of the Plugin in the Plugins tab.
See also Example Setup of Plugin VoiceVox (Japanese TTS) As example how to setup the VoiceVox Plugin.
- Audio configuration (TTS to Mic, Game Audio translation, etc.)
- Realtime Configuration and speed improvements
For additional Help, you can join






