![]()
![]()

First download and install the Nextcloud Workflow OCR app from the official Nexcloud-appstore or by downloading the appropriate tarball from the releases page.
cd /var/www/<NEXTCLOUD_INSTALL>/apps
wget https://github.com/R0Wi/workflow_ocr/releases/download/<VERSION>/workflow_ocr.tar.gz
tar -xzvf workflow_ocr.tar.gz
rm workflow_ocr.tar.gzSince the actual processing of the files is done asynchronously via Nextcloud's background job engine, make sure you've properly setup the cron functionallity as described here. If possible please use the crontab approach for more reliability.
⚠️ Sincev1.20.1you'll have to installOCRmyPDF.
In the backend OCRmyPDF is used for processing PDF files. Make sure you have this commandline tool installed. Make sure you have the appropriate version (see below, Used libraries').
apt-get install ocrmypdfThe ocrmypdf CLI can also convert single image files (jpg/png) to PDF before processing it via OCR. This mode is also supported by this app. You can read more about it in the official docs.
Also if you want to use specific language settings please install the corresponding tesseract packages.
# English
apt-get install tesseract-ocr-eng
# German
apt-get install tesseract-ocr-deu
# Chinese - Simplified
apt-get install tesseract-ocr-chi-simYou can configure the OCR processing via Nextcloud's workflow engine. Therefore configure a new flow via Settings → Flow → Add new flow (if you don't see OCR file here the app isn't installed properly or you forgot to activate it).

If you want a newly uploaded file to be processed via OCR or if you want to process a file which was updated, use the When-conditions File created or File updated or both.
A typical setup for processing incoming PDF-files and adding a text-layer to them might look like this:

⚠️ Please ensure to use theFile MIME type→is→PDF documentsoperator, otherwise you might not be able to save the workflow like discussed here.
If you have existing files which you want to process after they have been created, or if you want to filter manually which files are processed, you can use the Tag assigned event to trigger the OCR process if a user adds a specific tag to a file. Such a setup might look like this:

After that you should be able to add a file to the OCR processing queue by assigning the configured tag to a file:


Anyone who can create new workflows (admin or regular user) can configure settings for the OCR processing for a specific workflow. These settings are only applied to the specific workflow and do not affect other workflows.

Currently the following settings are available per workflow:
| Name | Description |
|---|---|
| Languages | The languages to be used for OCR processing. The languages can be choosen from a dropdown list. For PDF files this setting corresponds to the -l parameter of ocrmypdf. Please note that you'll have to install the appropriate languages like described in the ocrmypdf documentation. |
| Remove background | If the switch is set, the OCR processor will try to remove the background of the document before processing and instead set a white background. For PDF files this setting corresponds to the --remove-background parameter of ocrmypdf. |
As a Nextcloud administrator you're able to configure global settings which apply to all configured OCR-workflows on the current system.
Go to Settings → Flow and scroll down to Workflow OCR:

Currently the following settings can be applied globally:
| Name | Description |
|---|---|
| Processor cores | Defines the number of processor cores to use for OCR processing. When the input is a PDF file, this corresponds to the ocrmypdf CPU limit. This setting can be especially useful if you have a small backend system which has only limited power. |
To test if your file gets processed properly you can do the following steps:
- Upload a new file which meets the criteria you've recently defined in the workflow creation.
- Go to your servers console and change into the Nextcloud installation directory (e.g.
cd /var/www/html/nextcloud). - Execute the cronjob file manually e.g. by typing
sudo -u www-data php cron.php(this is the command you usually setup to be executed by linux crontab). - If everything went fine you should see that there was a new version of your file created. If you uploaded a PDF file you should now be able to select text in it if it contained at least one image with scanned text.


For processing PDF files, the external command line tool OCRmyPDF is used. The tool is always invoked with the --skip-text parameter so that it will skip pages which already contain text. Please note that with that parameter set, it's currently not possible to analize pages with mixed content (see R0Wi-DEV#113 for furhter information).
For processing single images (currently jpg and png are supported), ocrmypdf converts the image to a PDF. The converted PDF file will then be OCR processed and saved as a new file with the original filename and the extension .pdf (for example myImage.jpg will be saved to myImage.jpg.pdf). The original image fill will remain untouched.
Tools and packages you need for development:
makenodeandnpmcomposer(Will be automatically installed when runningmake build)- Properly setup
php-environment - Webserver (like
Apache) XDebugand aXDebug-connector for your IDE (for example https://marketplace.visualstudio.com/items?itemName=felixfbecker.php-debug) if you want to debug PHP code- PHP IDE (we recommend
VSCode)
You can then build and install the app by cloning this repository into the Nextcloud apps folder and running make build.
cd /var/www/<NEXTCLOUD_INSTALL>/apps
git clone https://github.com/R0Wi/workflow_ocr.git workflow_ocr
cd workflow_ocr
make buildDon't forget to activate the app via Nextcloud web-gui.
We provide a preconfigured debug configuration file for VSCode at .vscode/launch.json which will automatically be recognized when opening this
repository inside of VSCode. If you've properly installed and configured the XDebug-plugin you should be able to see it in the upper left corner
when being inside of the debug-tab.

To get the debugger profiles working you need to ensure that XDebug for Apache (or your preferred webserver) and XDebug for PHP CLI both connect to your machine at
port 9003. Depending on your system a possible configuration could
look like this:
; /etc/php/7.4/cli/php.ini
; ...
[Xdebug]
zend_extension=/usr/lib/php/20190902/xdebug.so
xdebug.remote_enable=1
xdebug.remote_host=127.0.0.1
xdebug.remote_port=9003
xdebug.remote_autostart=1; /etc/php/7.4/apache2/php.ini
; ...
[Xdebug]
zend_extension=/usr/lib/php/20190902/xdebug.so
xdebug.remote_enable=1
xdebug.remote_host=127.0.0.1
xdebug.remote_port=9003
xdebug.remote_autostart=1The following table lists the various debug profiles:
| Profile name | Use |
|---|---|
| Listen for XDebug | Starts XDebug listener for your webserver process. |
| Listen for XDebug (CLI) | Starts XDebug listener for your php cli process. |
| Run cron.php | Runs Nextcloud's cron.php with debugger attached. Useful for debugging OCR-processing jobs. |
| Debug Unittests | Start PHPUnit Unittests with debugger attached. |
| Debug Integrationtests | Start PHPUnit Integrationtests with debugger attached. |
If you're looking for some good sources on how to setup VSCode + XDebug we can recommend:
- https://tighten.co/blog/configure-vscode-to-debug-phpunit-tests-with-xdebug/
- https://code.visualstudio.com/docs/languages/php
If you're interested in a docker-based setup we can recommend
the images from https://github.com/thecodingmachine/docker-images-php which already come with Apache and
XDebug installed.
A working docker-compose.yml-file could look like this:
version: '3'
services:
apache_dev:
restart: always
container_name: apache_dev
image: ${IMAGE}-custom
build:
dockerfile: ./Dockerfile
args:
IMAGE: ${IMAGE}
environment:
- PHP_INI_MEMORY_LIMIT=1g
- PHP_INI_ERROR_REPORTING=E_ALL
- PHP_INI_XDEBUG__START_WITH_REQUEST=yes
- PHP_INI_XDEBUG__LOG_LEVEL=7
- PHP_EXTENSIONS=xdebug gd intl bcmath gmp imagick
volumes:
- ./html:/var/www/html
- ./000-default.conf:/etc/apache2/sites-enabled/000-default.conf
ports:
- 80:80
networks:
- web_devIMAGE could be set to IMAGE=thecodingmachine/php:7.4-v4-apache-node14 and the content of Dockerfile might
look like this:
ARG IMAGE
FROM $IMAGE
USER root
RUN apt-get update \
&& apt-get install -y make ocrmypdf tesseract-ocr-eng tesseract-ocr-deu smbclient \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
USER dockerℹ️ Please note that these are just working snippets which you might have to modify to fit your needs.
To execute the implemented PHPUnit tests you can use one of the following commands:
# Only run unittests
make unittest
# Only run integrationtests
make integrationtest
# Run all tests
make test
# Run all tests and create HTML coverage report
make html-coverage
# Run all tests and create XML coverage report
make coverage
⚠️ Make sure you activated the app before you run any tests (php occ app:enable workflow_ocr). Otherwise the initialization will fail.
To support a new mimetype for being processed with OCR you have to follow a few easy steps:
- Create a new class in
lib/OcrProcessorsand let the class implement the interfaceIOcrProcessor. - Register your implementation in
lib/OcrProcessors/OcrProcessorFactory.phpby adding it to the mapping.
private static $mapping = [
'application/pdf' => PdfOcrProcessor::class,
// Add your class here, for example:
'mymimetype' => MyOcrProcessor::class
];- Register a factory for creating your newly added processor in
lib/OcrProcessors/OcrProcessorFactory.phpby adding an appropriate function inside ofregisterOcrProcessors.
public static function registerOcrProcessors(IRegistrationContext $context) : void {
// [...]
$context->registerService(MyOcrProcessor::class, function(ContainerInterface $c) {
return new /* your factory goes here */
}, false);
}That's all. If you now create a new workflow based on your added mimetype, your implementation should be triggered by the app. The return value of ocrFile(string $fileContent, WorkflowSettings $settings, GlobalSettings $globalSettings) will be interpreted as the file content of the scanned file. This one is used to create a new file version in Nextcloud.
-
Currently only pdf documents (
application/pdf) and single images (image/jpegandimage/png) can be used as input. Other mimetypes are currently ignored but might be added in the future. -
All input file types currently produce a single
pdfoutput file. Currently there is no other output file format supported. -
Pdf metadata (like author, comments, ...) might not be available in the converted output pdf document. This is limited by the capabilities of
ocrmypdf(see ocrmypdf/OCRmyPDF#327). -
Currently files are only processed based on workflow-events so there is no batch-mechanism for applying OCR to already existing files. This is a feature which might be added in the future. For applying OCR to a single file, which already exist, one could use the "tag assigned" workflow trigger.
-
If you encounter any problems with the OCR processing, you can always restore the original file via Nextcloud's version history.
If you want to clean the files history for all files and only preserve the newest file version, you can use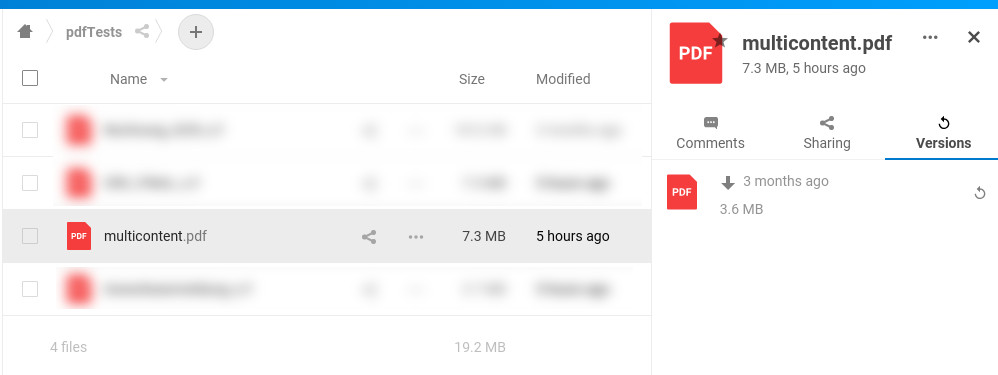
sudo -u www-data php occ versions:cleanup
Read more about this in the docs.
| Name | Version | Link |
|---|---|---|
| OCRmyPDF (commandline) | >= 9.6.0 | https://github.com/jbarlow83/OCRmyPDF On Debian, you might need to manually install a more recent version as described in https://ocrmypdf.readthedocs.io/en/latest/installation.html#ubuntu-18-04-lts; see R0Wi-DEV#46 |
| php-shellcommand | >= 1.6 | https://github.com/mikehaertl/php-shellcommand |
| chain | >= 0.9.0 | https://packagist.org/packages/cocur/chain |
| PHPUnit | >= 8.0 | https://phpunit.de/ |