A pretrained word2vec embeddings for italian languages.
Unfortunately the file is too large. You can find the model available in free download on MegaShare here pretrained-italian-word2vec-emb downloader
This repositoy has one big purpose: in the last years I've had the possibility to work on NLP projects. I've spend a significant portion of my time looking for a decent pre-trained word vectors model for the Italian language. The faster solution I found was to make it on my own.
In this repository you can easily download (a not so light version of) a pre-trained 300-dimensional word vectors model (trained using word2vec) for Italian.
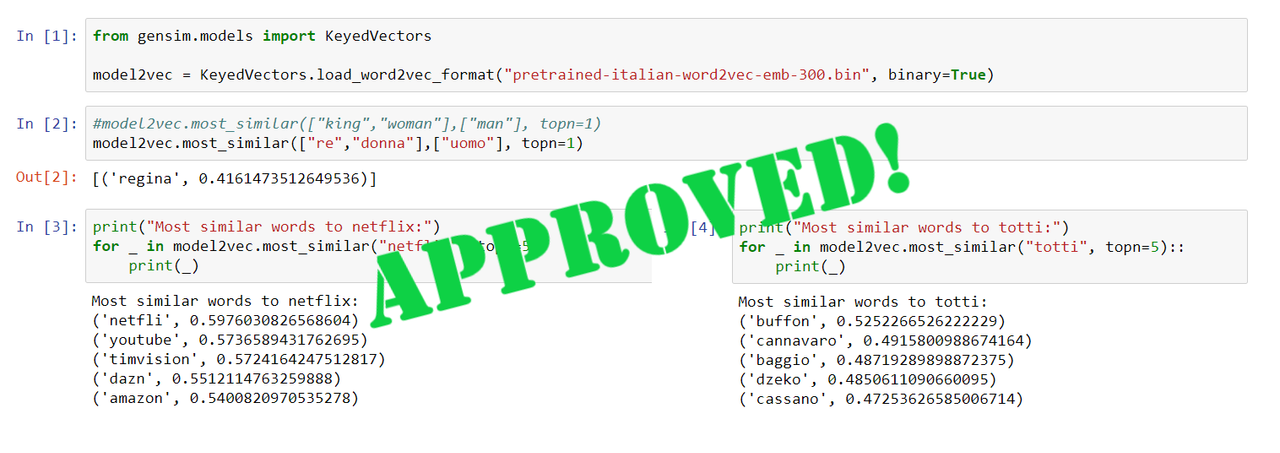
Vectors have been trained using almost 24 milion of unique sentences, collected during the last year, enconding almost 110K different words. Words with occurrences lower than 50 have been removed from the training. It's possible to see also extra-italian language words inside the vocabulary. This is because original texts may contain some foreign sentences. I hope you will find my job useful for your purpose as well.
I've decided to start with an easy cleaning:
- Words longer than 26 chars have been removed
- Words that start with "http" have been removed
- Words that contain "@" have been removed
- Words that contain "#" have been removed
- Words that contain "www" have been removed
- Words that end with ".ly" have been removed
- Words that contain digits have been removed
- All no-alphabetic chars have been removed
- Lower transformation has been applied
Loading model:
from gensim.models import KeyedVectors
model2vec = KeyedVectors.load_word2vec_format("./PATH_HERE/pretrained-italian-word2vec-emb-300.bin", binary = True)Comparable cleaning function:
def easy_cleaning(sentence):
sentence = " ".join([word for word in sentence.split() if not any(x in word for x in ["@","#","http",".ly","www"])])
sentence = re.sub(r"[^a-zA-Z\à\è\é\ì\ò\ù ]+", " ", sentence)
sentence = re.sub(r" +"," ",sentence).strip().lower()
return sentenceNew versions are going to be uploaded as soon as I can. Please feel free to contact me with suggestions regard cleaning rules or anything else.
- Gensim 3.3.0