![]()
Awesome Domain Adaptation Python Toolbox
ADAPT is an open source library providing numerous tools to perform Transfer Learning and Domain Adaptation.
The purpose of the ADAPT library is to facilitate the access to transfer learning algorithms for a large public, including industrial players. ADAPT is specifically designed for Scikit-learn and Tensorflow users with a "user-friendly" approach. All objects in ADAPT implement the fit, predict and score methods like any scikit-learn object. A very detailed documentation with several examples is provided:
|
Sample bias correction 
|
Model-based Transfer 
|
|
Deep Domain Adaptation 
|
Multi-Fidelity Transfer 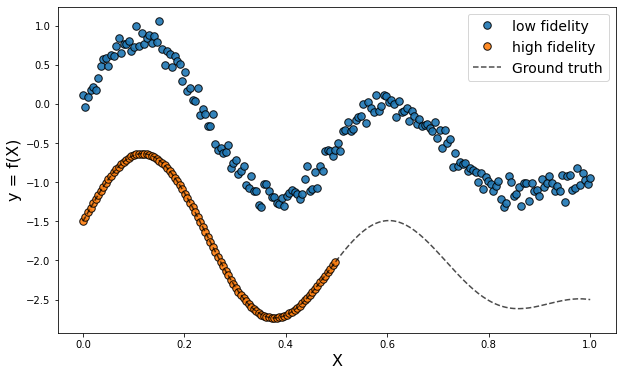
|
This package is available on Pypi and can be installed with the following command line:
pip install adapt
The following dependencies are required and will be installed with the library:
numpyscipytensorflow(>= 2.0)scikit-learncvxopt
If for some reason, these packages failed to install, you can do it manually with:
pip install numpy scipy tensorflow scikit-learn cvxopt
Finally import the module in your python scripts with:
import adaptA simple example of usage is given in the Quick-Start below.
The transfer learning methods implemented in ADAPT can be seen as scikit-learn "Meta-estimators" or tensorflow "Custom Model":
|
Adapt Estimator AdaptEstimator(
estimator = """A scikit-learn estimator
(like Ridge(alpha=1.) for example)
or a Tensorflow Model""",
Xt = "The target input features",
yt = "The target output labels (if any)",
**params = "Hyper-parameters of the AdaptEstimator"
) |
Deep Adapt Estimator DeepAdaptEstimator(
encoder = "A Tensorflow Model (if required)",
task = "A Tensorflow Model (if required)",
discriminator = "A Tensorflow Model (if required)",
Xt = "The target input features",
yt = "The target output labels (if any)",
**params = """Hyper-parameters of the DeepAdaptEstimator and
the compile and fit params (optimizer, epochs...)"""
) |
Scikit-learn Meta-Estimator SklearnMetaEstimator(
base_estimator = """A scikit-learn estimator
(like Ridge(alpha=1.) for example)""",
**params = "Hyper-parameters of the SklearnMetaEstimator"
) |
As you can see, the main difference between ADAPT models and scikit-learn and tensorflow objects is the two arguments Xt, yt which refer to the target data. Indeed, in classical machine learning, one assumes that the fitted model is applied on data distributed according to the training distribution. This is why, in this setting, one performs cross-validation and splits uniformly the training set to evaluate a model.
In the transfer learning framework, however, one assumes that the target data (on which the model will be used at the end) are not distributed like the source training data. Moreover, one assumes that the target distribution can be estimated and compared to the training distribution. Either because a small sample of labeled target data Xt, yt is available or because a large sample of unlabeled target data Xt is at one's disposal.
Thus, the transfer learning models from the ADAPT library can be seen as machine learning models that are fitted with a specific target in mind. This target is different but somewhat related to the training data. This is generally achieved by a transformation of the input features (see feature-based transfer) or by importance weighting (see instance-based transfer). In some cases, the training data are no more available but one aims at fine-tuning a pre-trained source model on a new target dataset (see parameter-based transfer).
The ADAPT library proposes numerous transfer algorithms and it can be hard to know which algorithm is best suited for a particular problem. If you do not know which algorithm to choose, this flowchart may help you:

Here is a simple usage example of the ADAPT library. This is a simulation of a 1D sample bias problem with binary classification task. The source input data are distributed according to a Gaussian distribution centered in -1 with standard deviation of 2. The target data are drawn from Gaussian distribution centered in 1 with standard deviation of 2. The output labels are equal to 1 in the interval [-1, 1] and 0 elsewhere. We apply the transfer method KMM which is an unsupervised instance-based algorithm.
# Import standard libraries
import numpy as np
from sklearn.linear_model import LogisticRegression
# Import KMM method form adapt.instance_based module
from adapt.instance_based import KMM
np.random.seed(0)
# Create source dataset (Xs ~ N(-1, 2))
# ys = 1 for ys in [-1, 1] else, ys = 0
Xs = np.random.randn(1000, 1)*2-1
ys = (Xs[:, 0] > -1.) & (Xs[:, 0] < 1.)
# Create target dataset (Xt ~ N(1, 2)), yt ~ ys
Xt = np.random.randn(1000, 1)*2+1
yt = (Xt[:, 0] > -1.) & (Xt[:, 0] < 1.)
# Instantiate and fit a source only model for comparison
src_only = LogisticRegression(penalty="none")
src_only.fit(Xs, ys)
# Instantiate a KMM model : estimator and target input
# data Xt are given as parameters with the kernel parameters
adapt_model = KMM(
estimator=LogisticRegression(penalty="none"),
Xt=Xt,
kernel="rbf", # Gaussian kernel
gamma=1., # Bandwidth of the kernel
verbose=0,
random_state=0
)
# Fit the model.
adapt_model.fit(Xs, ys);
# Get the score on target data
adapt_model.score(Xt, yt)>>> 0.574 |
|---|
| Quick-Start Plotting Results. The dotted and dashed lines are respectively the class separation of the "source only" and KMM models. Note that the predicted positive class is on the right of the dotted line for the "source only" model but on the left of the dashed line for KMM. (The code for plotting the Figure is available here) |
ADAPT package is divided in three sub-modules containing the following domain adaptation methods:
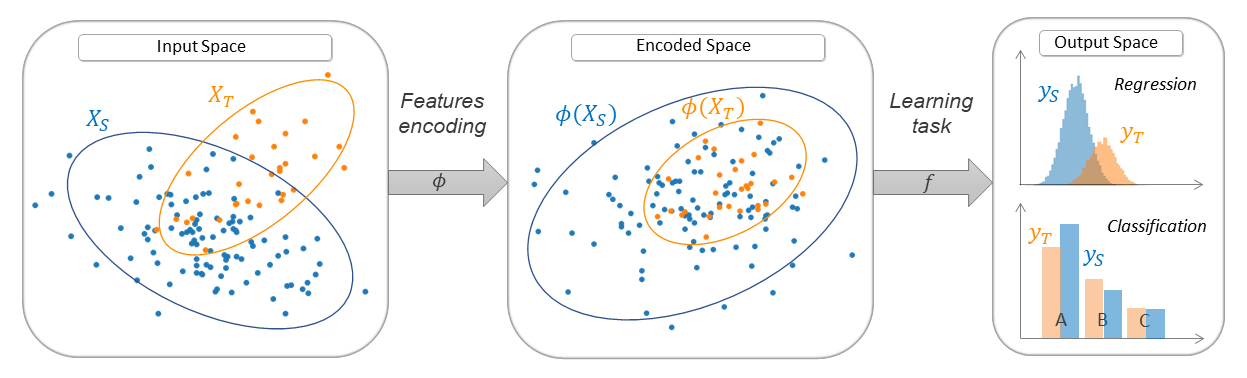
- FA (Frustratingly Easy Domain Adaptation) [paper]
- SA (Subspace Alignment) [paper]
- fMMD (feature Selection with MMD) [paper]
- DANN (Discriminative Adversarial Neural Network) [paper]
- ADDA (Adversarial Discriminative Domain Adaptation) [paper]
- CORAL (CORrelation ALignment) [paper]
- DeepCORAL (Deep CORrelation ALignment) [paper]
- MCD (Maximum Classifier Discrepancy) [paper]
- MDD (Margin Disparity Discrepancy) [paper]
- WDGRL (Wasserstein Distance Guided Representation Learning) [paper]
- CDAN (Conditional Adversarial Domain Adaptation) [paper]
- CCSA (Classification and Contrastive Semantic Alignment) [paper]
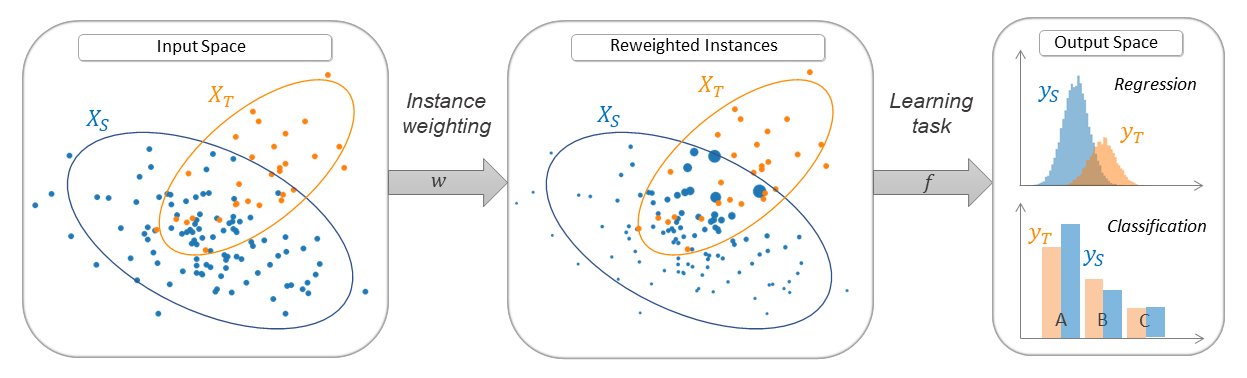
- LDM (Linear Discrepancy Minimization) [paper]
- KMM (Kernel Mean Matching) [paper]
- KLIEP (Kullback–Leibler Importance Estimation Procedure) [paper]
- TrAdaBoost (Transfer AdaBoost) [paper]
- TrAdaBoostR2 (Transfer AdaBoost for Regression) [paper]
- TwoStageTrAdaBoostR2 (Two Stage Transfer AdaBoost for Regression) [paper]
- NearestNeighborsWeighting (Nearest Neighbors Weighting) [paper]
- WANN (Weighting Adversarial Neural Network) [paper]
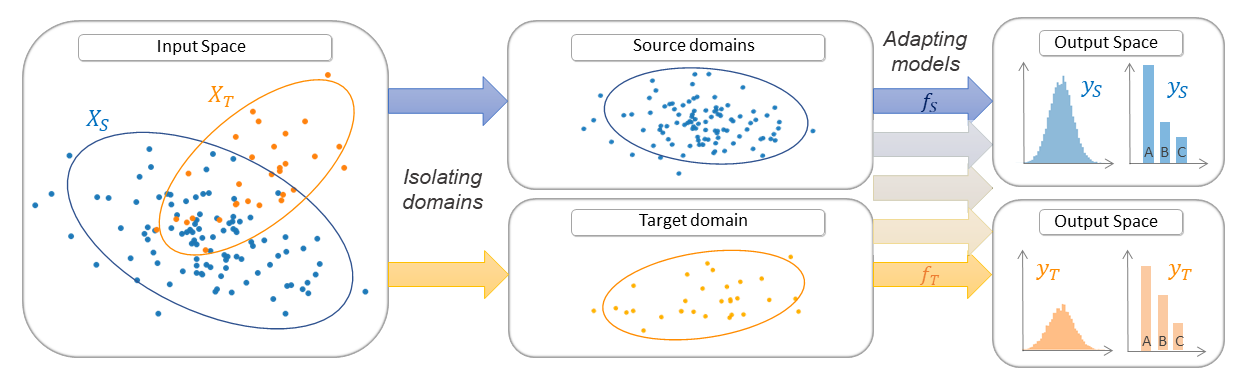
- RegularTransferLR (Regular Transfer with Linear Regression) [paper]
- RegularTransferLC (Regular Transfer with Linear Classification) [paper]
- RegularTransferNN (Regular Transfer with Neural Network) [paper]
- FineTuning (Fine-Tuning) [paper]
- TransferTreeClassifier (Transfer Tree Classifier) [paper]
- TransferTreeForest (Transfer Tree Forest) [paper]
If you use this library in your research, please cite ADAPT using the following reference: https://arxiv.org/pdf/2107.03049.pdf
@article{de2021adapt,
title={ADAPT: Awesome Domain Adaptation Python Toolbox},
author={de Mathelin, Antoine and Deheeger, Fran{\c{c}}ois and Richard, Guillaume and Mougeot, Mathilde and Vayatis, Nicolas},
journal={arXiv preprint arXiv:2107.03049},
year={2021}
}
This work has been funded by Michelin and the Industrial Data Analytics and Machine Learning chair from ENS Paris-Saclay, Borelli center.


