Motivation and personal thoughts
Read it under your own liability
I have been doing a couple of online tutorials, and I have learned some stuff indeed, but after a couple of weeks if I don't use that knowledge it simply disappears. In order to really 'last', I came back to the roots, to the very beggining, a humble man with just a desire of learning, no prior experience, no degrees, no names.
I started the repos with ROS tutorials, it kinda worked, actually they are my legacy on robotics, but now I want something for myself. A couple of things:
- Why english?: The real answer should be why not?...I need to improve it.
- Why DB and SQL?: Because a do not know a dam* thing about it, so I am starting from scratch.
- Why a repo poorly coded and badly commented?: Well, there should be probably hundreds of books about these topics, but they are not mine, plus this is my way.
Disclaimer: I will never say that a random chick was right about this. It seems that I am recovering the licence to <insert some sh#t>.
-
MySQL: Made by oracle, it's probably the most extended in the community of DB.
Installation:
-
Windows: Probably the easiest, just go here download and make your custom install. I had some troubles with it, the login in procedure fails a lot, so I switch to linux.
-
Linux: I struggled a lot, but I found a good tutorial. Follow the steps as close as possible, I spent like 4 hours because I wannted to do it my way.
Pro tip: MySQL Workbench for linux coulb be buggy in terms of GUI, so try to find hidden panels.Linux
Install the required packages:
sudo apt install mysql-server
Check is the service is running:systemctl is-active mysql
Set password, this part is particularlly stressfull, so let's try...sudo mysql_secure_installation
Here, I recommed to use the strong type of password. I will fail trying to set the password, so close the shell, open a new one an type:mysql -u root
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password by 'New_password_0';
FLUSH PRIVILEGES;
By now all should be working, so next time you may want to log just type:mysql -u root -p
Finally the visual interface, **mysql_workbench**. Quite easy, just type:sudo snap install mysql-workbench-community
In the likely scenario where the localhost login fails, just type the following to change the way the credentials are used:sudo snap connect mysql-workbench-community:password-manager-service :password-manager-service
-
- PostgreSQL: Another GNU alternative, not much to say...I like the elephant.
Installation:- Windows: Pretty straightforward, just install the postgre engine download here and then the pgadmin here.
- Linux: Not equally esay than windows but follow the summary instructions.
Linux
Install the required packages:
sudo apt install postgre
Enable the service:sudo systemctl start postgresql.service
Install the graphical interface.curl -fsS https://www.pgadmin.org/static/packages_pgadmin_org.pub | sudo gpg --dearmor -o /usr/share/keyrings/packages-pgadmin-org.gpg
sudo sh -c 'echo "deb [signed-by=/usr/share/keyrings/packages-pgadmin-org.gpg] https://ftp.postgresql.org/pub/pgadmin/pgadmin4/apt/$(lsb_release -cs) pgadmin4 main" > /etc/apt/sources.list.d/pgadmin4.list && apt update'
sudo apt install pgadmin4
Here, I recommed to use the strong type of password. I will fail trying to set the password, so close the shell, open a new one and type:sudo -u postgres psql
\password postgres
\q
Time to setup the local server. Open the pgadmin4, create a nwe server (name it whatever you want), for address use either *localhost* or *127.0.0.1*, for **password** use the one yo defined in the previous step. And voila postgreSQL is set up.
- Squema: It is basically the DB, you can ddefine rules, filters, among others. A schema contains tables, views, functions and proceddures.
- Table: It is a matrix of information, it is comprisedd of colums that represent a certain type of data (INT, CHAR, TEXT, TIME) and rows, which are the actual data in the table.
- Queries: They are the core of SQL (Structured Query). They are a set of commads used to look up for certain info in the tables.
It is a set of commands to create and modify the objects of a DB. They are quite useful on the DB definition, but then they lose participation.
- CREATE: It creates a table or a schema
-- A schema named platziblog is created, utf8 is efine as default character set to store the information
CREATE SCHEMA `platziblog` DEFAULT CHARACTER SET utf8;-- A table named people is created in the platziblog schema. Five colums are created
-- person_id: integer, primary id, not null and auto increment
-- last_name: char of max 255 not null
-- first_name: char of max 255 not null
-- address: char of max 255 not null
-- city: char of max 255 not null
CREATE TABLE `platziblog`.`people` (
`person_id` INT NOT NULL AUTO_INCREMENT,
`last_name` VARCHAR(255) NOT NULL,
`first_name` VARCHAR(255) NOT NULL,
`address` VARCHAR(255) NOT NULL,
`city` VARCHAR(255) NOT NULL,
PRIMARY KEY (`person_id`));- ALTER: It modifies parameters inside table or a schema, such as name, columns.
-- Change the name of a table
ALTER TABLE `platziblog`.`people`
RENAME TO `platziblog`.`people_aux` ;-- Add a new column to a table
ALTER TABLE `platziblog`.`people`
ADD COLUMN `phone` INT NOT NULL AFTER `city`;- DROP: It deletes a DB, it must be used carefully.
It is a set of commands to manipulate de DB. Once the DDB has been created they are the innstructions to interact with the DB, mainly the tables.
- SELECT: Probably the most used command it returns data rom a source (normally a table) according to a defined criteria.
-- Projects all data contained in table people
SELECT * FROM `platziblog.pleople`-- Projects the column first_name as nombre
SELECT `first_name` AS `nombre` FROM `platziblog.pleople`-- Projects data from the column first_name that meet the criteria person_id = 1
SELECT first_name AS nombre FROM `platziblog.pleople` WHERE person_id = 1;- INSERT: It populates a table. Columns must be selected and data types must agree.
-- Populates 4 columns with values
INSERT INTO `platziblog.people` (last_name, first_name, address, city)
VALUES ('Hernandez','Monica','Pensilvania 1600', 'Aguascalientes'),
('Hernandez','Laura','Calle 21','Monterrey');- UPDATE
- DELETE
The idea is to create a DB for a blog. The variable types and their realationships are defined as follows:
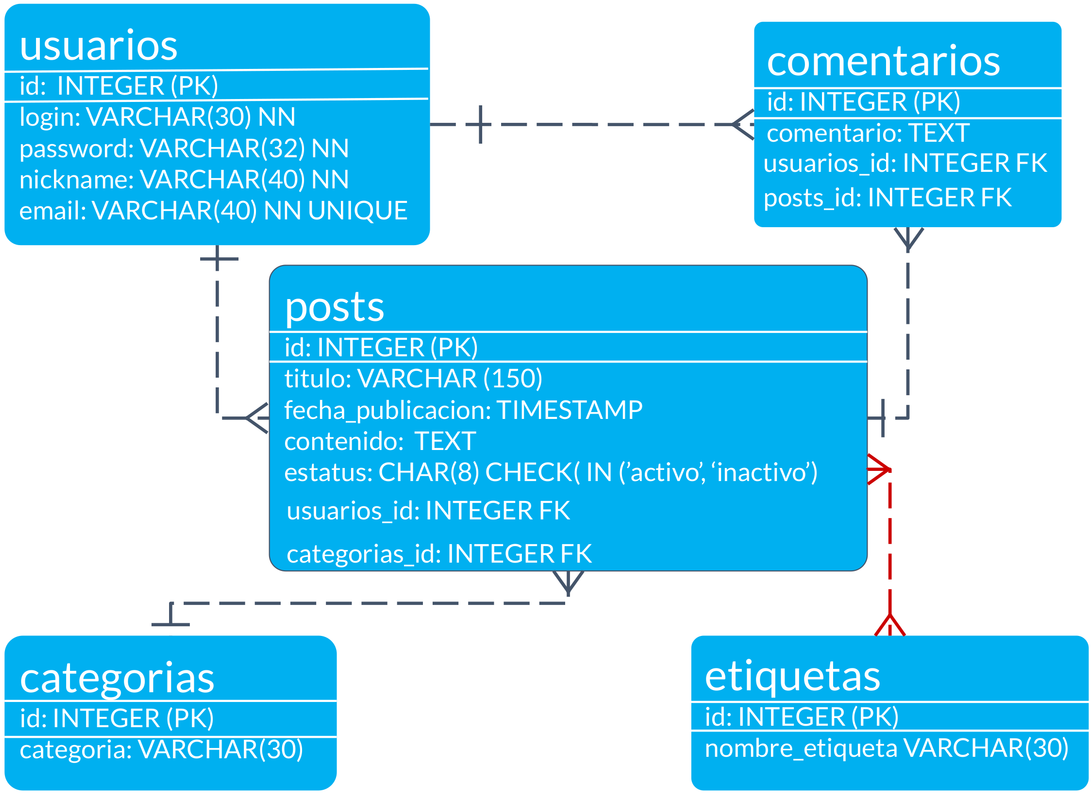
So get into the code:
-- Create the schema
CREATE SCHEMA `platziblog` DEFAULT CHARACTER SET utf8;
-- Create the tables
-- email column has to be unique (no repeated entries)
CREATE TABLE `platziblog`.`usuarios`(
`id` INT NOT NULL AUTO_INCREMENT,
`login` VARCHAR(30) NOT NULL,
`password` VARCHAR(32) NOT NULL,
`nickname` VARCHAR(40) NOT NULL,
`email` VARCHAR(40) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE INDEX `email_UNIQUE` (`email` ASC));
-- status can be null by default 'activo'
CREATE TABLE `platziblog`.`posts` (
`id` INT NOT NULL AUTO_INCREMENT,
`titulo` VARCHAR(130) NOT NULL,
`fecha_publicacion` TIMESTAMP NULL,
`contenido` TEXT NOT NULL,
`estatus` CHAR(8) NULL DEFAULT 'activo',
`usuario_id` INT NOT NULL,
`categoria_id` INT NOT NULL,
PRIMARY KEY (`id`));
CREATE TABLE `platziblog`.`categorias`(
`id` INT NOT NULL AUTO_INCREMENT,
`nombre_categoria` VARCHAR(30) NOT NULL,
PRIMARY KEY (`id`));
CREATE TABLE `platziblog`.`etiquetas`(
`id` INT NOT NULL AUTO_INCREMENT,
`nombre_etiqueta` VARCHAR(30) NOT NULL,
PRIMARY KEY (`id`));
CREATE TABLE `platziblog`.`comentarios`(
`id` INT NOT NULL AUTO_INCREMENT,
`cuerpo_comentario` TEXT NOT NULL,
`usuario_id` INT NOT NULL,
`post_id` INT NOT NULL,
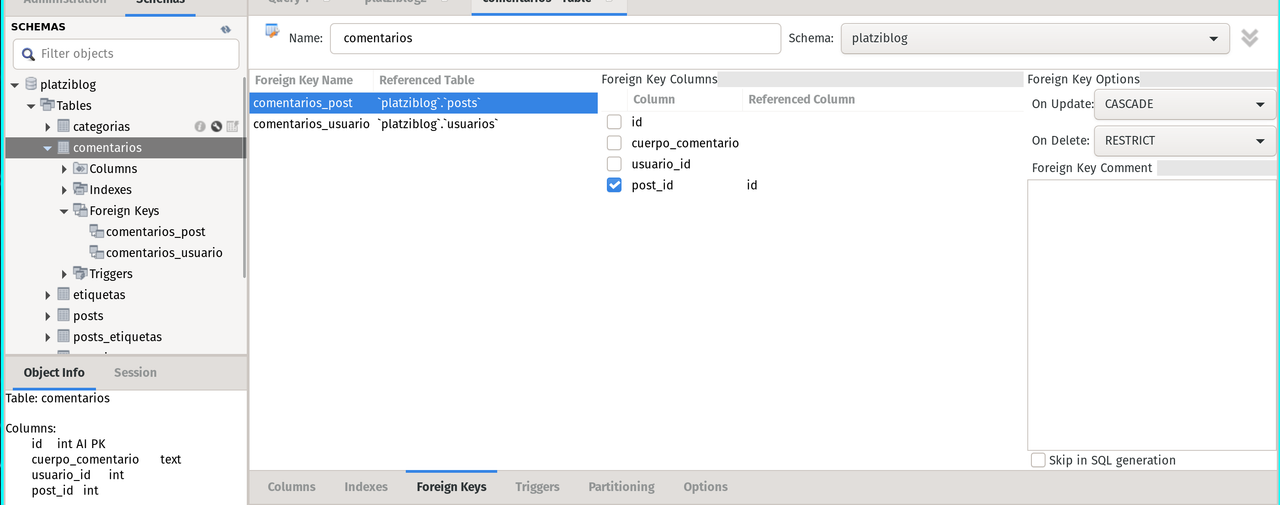
PRIMARY KEY (`id`));Now the tricky part, because there are multiple dependencies or 'relations' between comentarios and posts it is neccesary to insert a foreing key into table comentarios.
--- A new index is added
ALTER TABLE `platziblog`.`comentarios`
ADD INDEX `posts_post_idx` (`post_id` ASC);
--- column post_id is brought as a foreign key
ALTER TABLE `platziblog`.`comentarios`
ADD CONSTRAINT `comentarios_post`
FOREIGN KEY (`post_id`)
REFERENCES `platziblog`.`posts`(`id`)
ON DELETE NO ACTION
ON UPDATE CASCADE;Note: my_sql workbench on Linux is kinda buggy, so I could not make the process using the GUI, it was by code.
Proof
Time to populate the table, refer to populate_tables.sql
Let's try some queries:
--- projects 3 columns changing the name
SELECT titulo AS encabezado, fecha_publicacion AS publicado_en, estatus AS estado
FROM posts;result
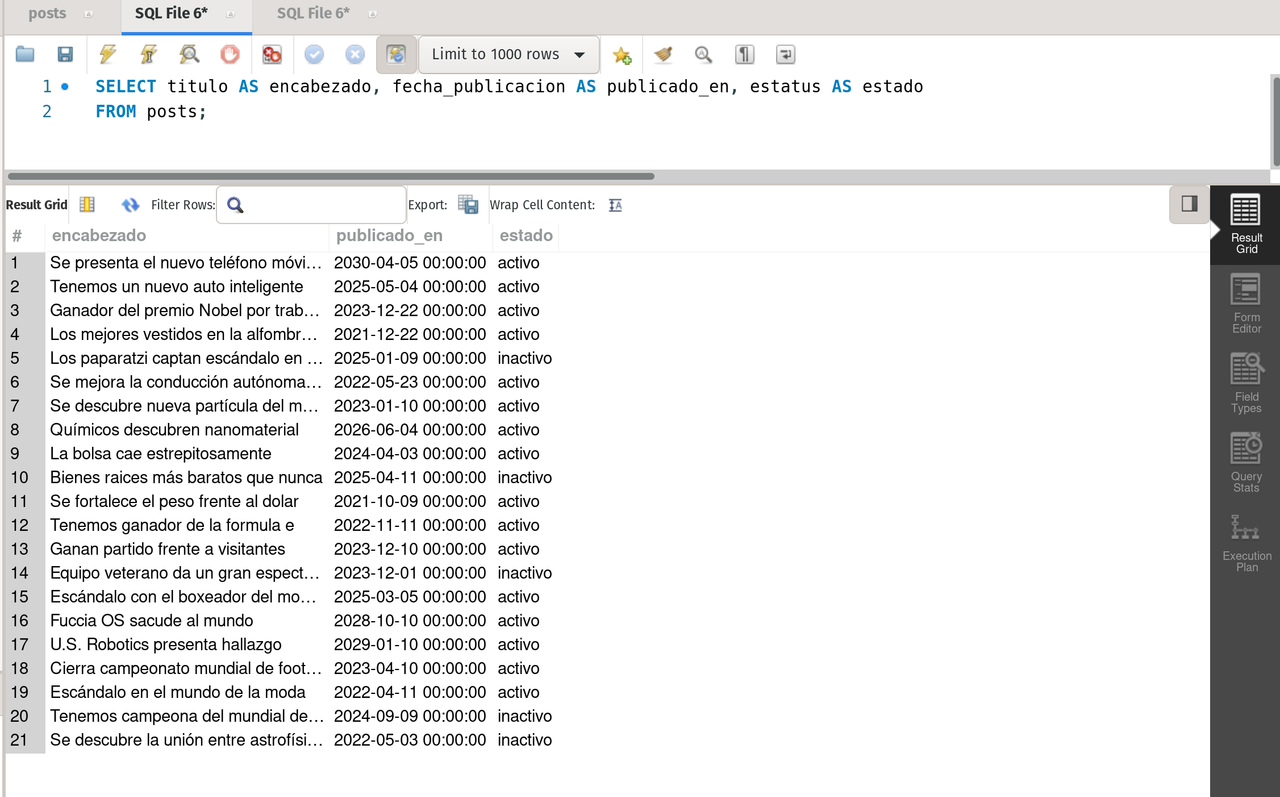
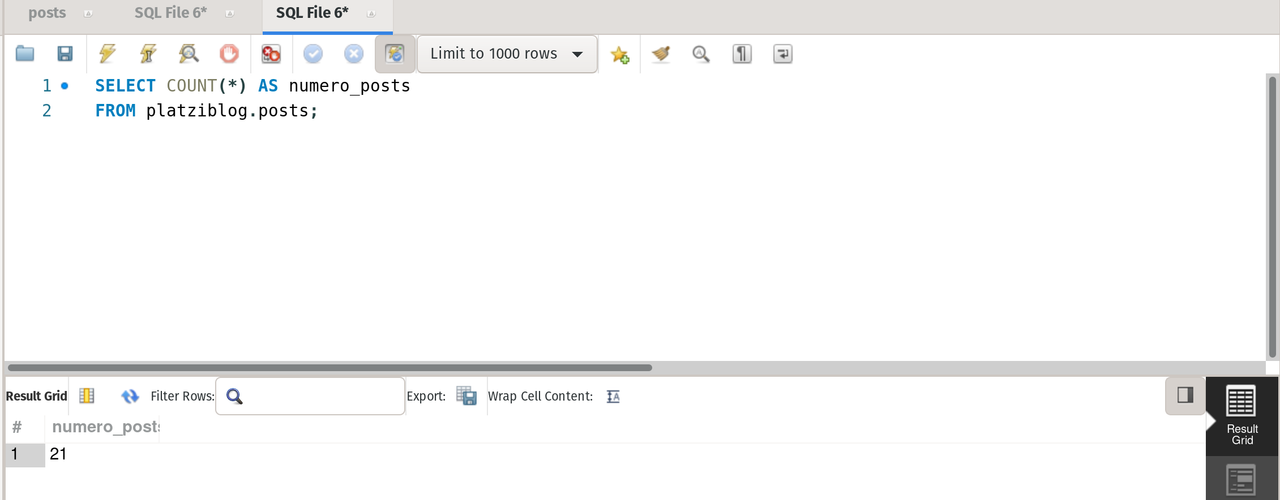
--- counts the number of entries of table posts
SELECT COUNT(*) AS numero_posts
FROM platziblog.posts;result
Well, it's time for Mr. Venn, now seriously, there are 4 operations widely used: joins, union, intersection and difference. For the sake of all examples 2 sets (tables) are gonna be used A (usuarios) and B (posts).
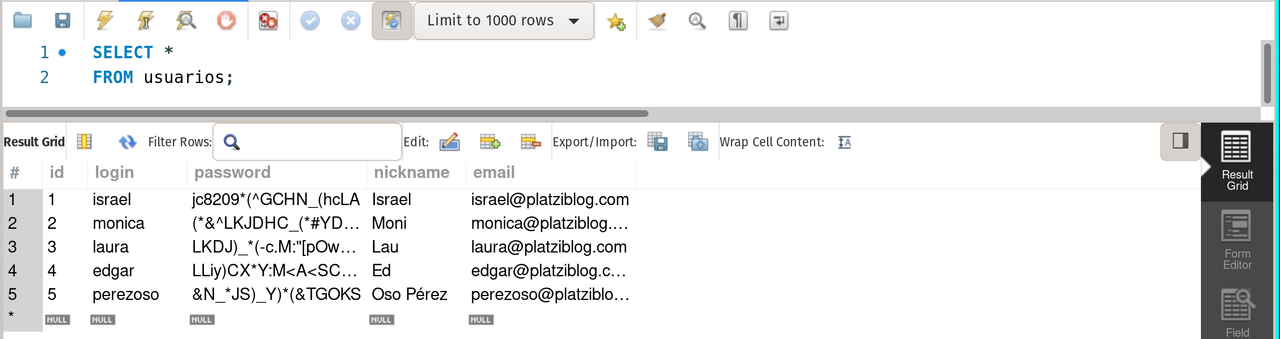
SELECT * FROM usuarios;usuarios
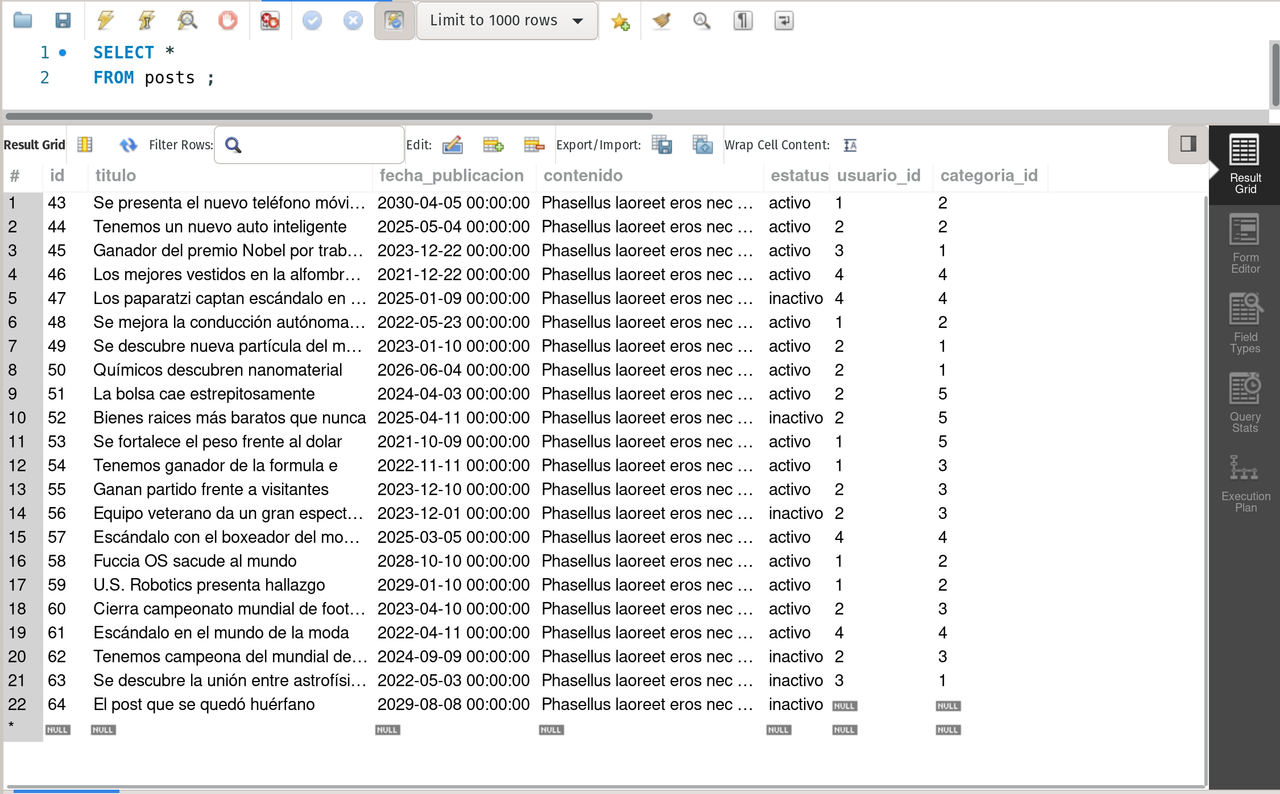
SELECT * FROM postsposts
- join: Operations in which the elements of a set are joined (redundancy). In general the rest of operators can be seen as joins with constrains.
- left join: It takes what is in A and what is shared with B,in esence, the set A plus the joined data from B.
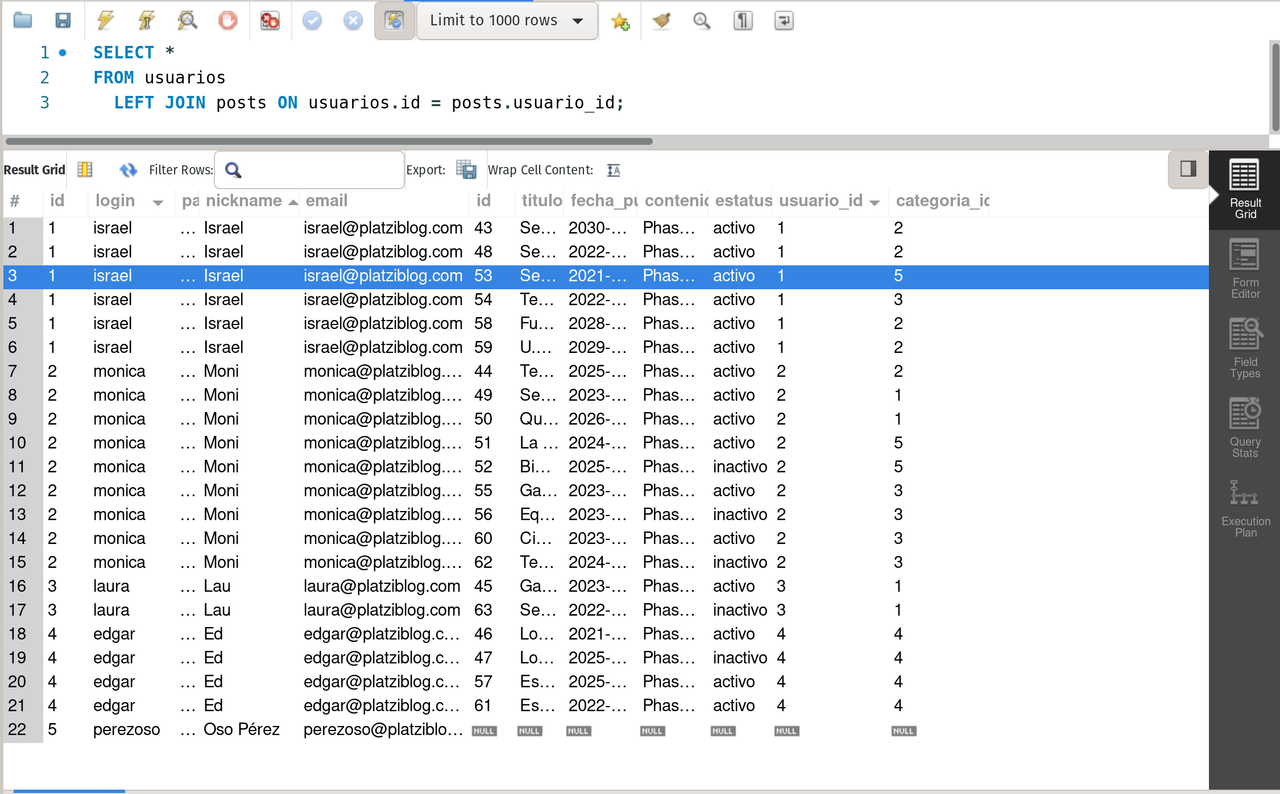
SELECT * FROM usuarios
LEFT JOIN posts ON usuarios.id = posts.usuario_id;Notice that usuarios is located at the left, all data related with the key usuarios_id is linked, but there is one user that has no post (the las one). So the join means all the users with o without a post.
left join usuarios and posts
- right join: It takes what is in B and what is shared with A, in esence, the set B plus the joined data from A.
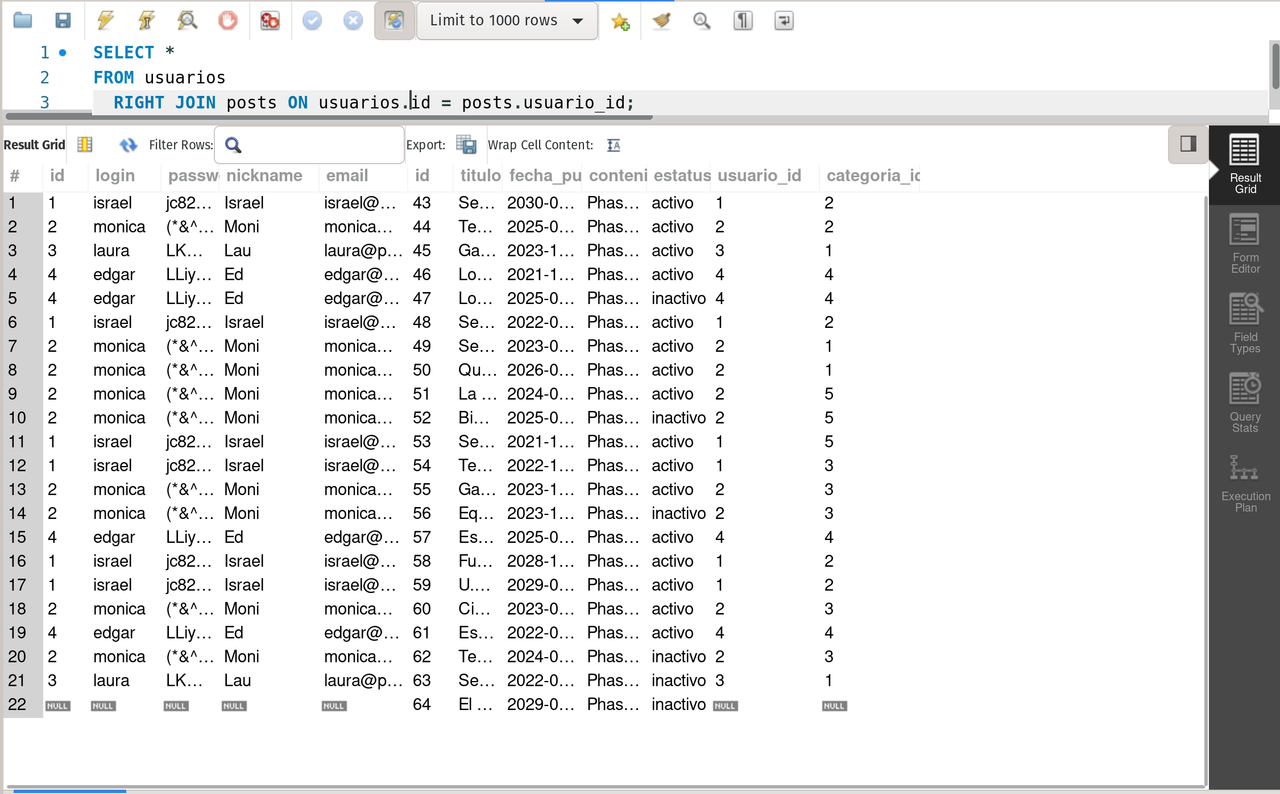
SELECT * FROM usuarios
RIGHT JOIN posts ON usuarios.id = posts.usuario_id;Notice that even though usuarios is at the left, the result is sorted by posts_id. Again the shared data is related by usuarios_id but this time the join means all the posts with or without user.
right join usuarios and posts
- join using where: It is an operation in which constrains or conditions can be added to the query, in escene, it is to filter even more the query. Two examples are the best way to represent it.
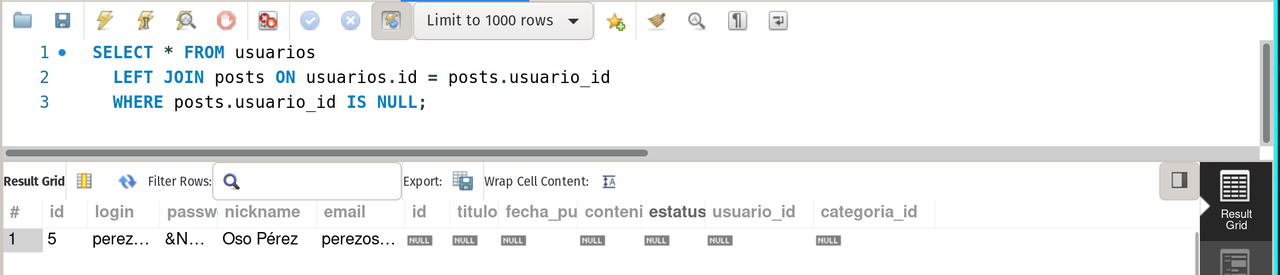
SELECT * FROM usuarios
LEFT JOIN posts ON usuarios.id = posts.usuario_id
WHERE posts.usuario_id IS NULL;It returns all the users without a post.
left join usuarios and posts + where
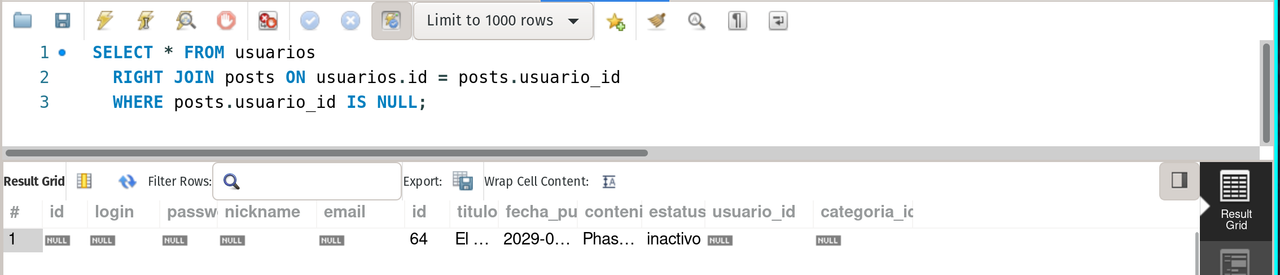
SELECT * FROM usuarios
RIGHT JOIN posts ON usuarios.id = posts.usuario_id
WHERE posts.usuario_id IS NULL;It returns all the posts without an user.
right join usuarios and posts + where
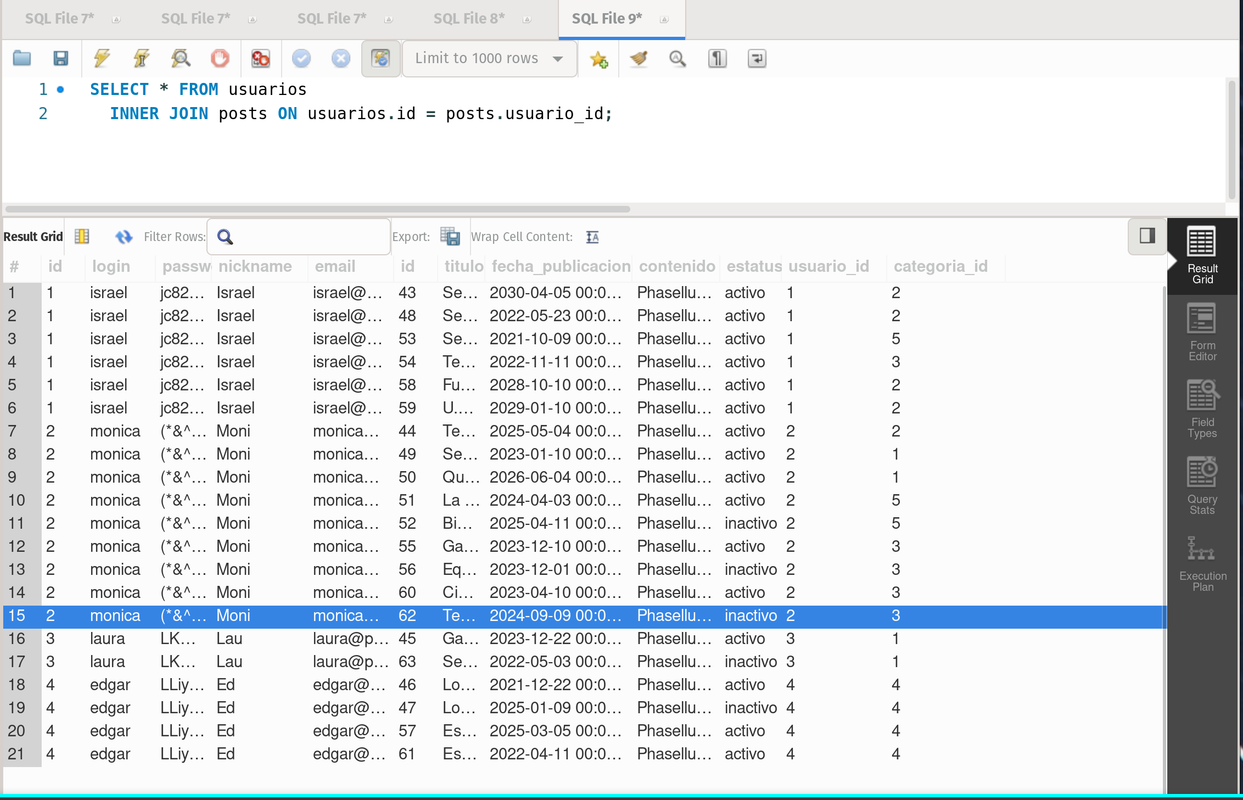
- intersection: It takes what is in A but also in B, basically the data sharedd by the two sets.
SELECT * FROM usuarios
INNER JOIN posts ON usuarios.id = posts.usuario_id;It returns all the posts that have an actual user.
inner join usuarios and posts
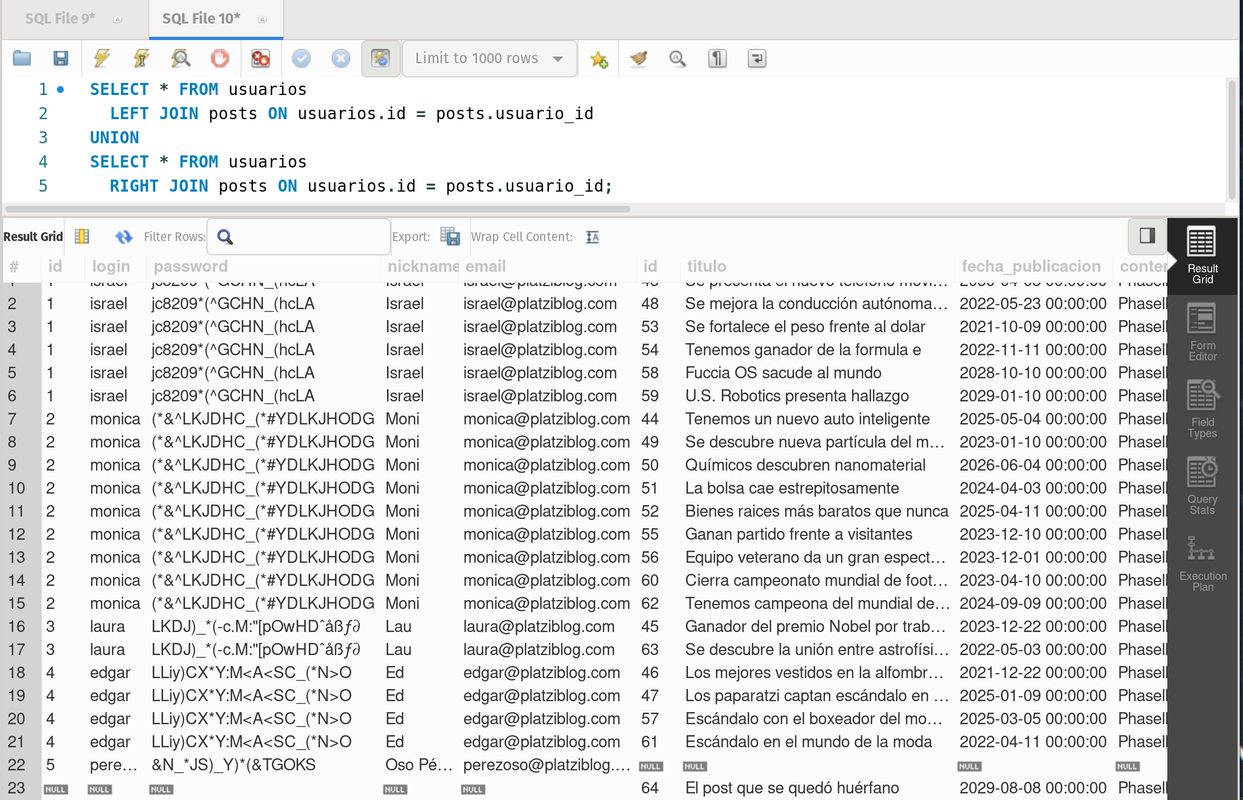
- union: It is the sum of the sets, in this case A and B. Mysql does not have a dedicated query for this, so a compound one is requiered, basically both joints, the left and the right.
SELECT * FROM usuarios
LEFT JOIN posts ON usuarios.id = posts.usuario_id
UNION
SELECT * FROM usuarios
RIGHT JOIN posts ON usuarios.id = posts.usuario_id;It returns all the posts with and without an user and all the users with and without a post.
outer join usuarios and posts
- simetrical difference: It takes what is in A but is not shared with B plus what is inn B but not in A, basically it is the complement of the intersection operation. Once again it is a compound operation of two joints using where.
SELECT * FROM usuarios
LEFT JOIN posts ON usuarios.id = posts.usuario_id
WHERE posts.usuario_id IS NULL
UNION
SELECT * FROM usuarios
RIGHT JOIN posts ON usuarios.id = posts.usuario_id
WHERE posts.usuario_id IS NULL;It returns the posts without an user and the users without a post.
outer join usuarios and posts
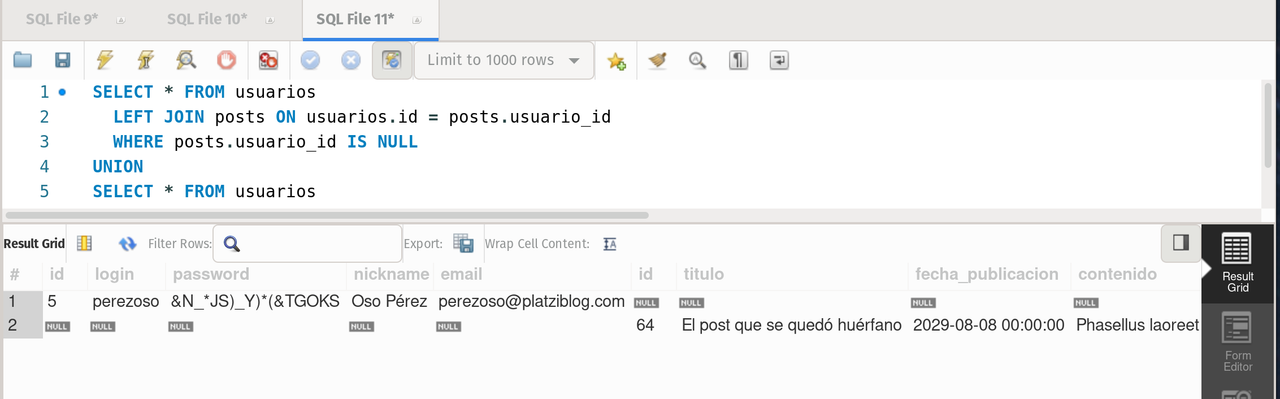
Where is my mind?.....pixies said. Well one of the most useful commands in a query. WHERE allows to filter the data contained in a table using math and relation expressions. Let's see a couple of examples:
-- three colums from posts where id equals 50
SELECT id, titulo, fecha_publicacion FROM posts WHERE id=50 -- three colums from posts where id is between 50 and 52 (included)
SELECT id, titulo, fecha_publicacion FROM posts WHERE id BETWEEN 50 AND 52-- three colums from posts where date of publication is before january the 1st of 2022
SELECT id, titulo, fecha_publicacion FROM posts WHERE fecha_publicacion<'2022-01-01' -- three colums from posts where date of publication is before 2022
SELECT id, titulo, fecha_publicacion FROM posts WHERE YEAR(fecha_publicacion)< '2022' -- three colums from posts where title contais the 'los' (before or after), you can play with the % indicating if there is something before or after, the compariso is ccase sensitive
SELECT id, titulo, fecha_publicacion FROM posts WHERE titulo LIKE '%los%'--- AND
--- returns all columns from posts that satisfy usuario_id not null, estatus activo and catedoria_id 2
SELECT * FROM posts WHERE usuario_id IS NOT NULL AND estatus='activo' AND categoria_id=2;--- OR
--- returns all columns from etiquetas inn which nombre etiqueta equals either Moda or Avances
SELECT * FROM etiquetas WHERE nombre_etiqueta IN ("Moda","Avances");When I was a young and silly I infravalorated the power of Excel, it was for Industriales...and how wrong I used to be. You have a table...boring, you can create 'dyamic tables', you got my attention, well basically that's what group by allows to do, filter and group information as you may need.
Most queries that use group by need a aggregation function suh as: COUNT SUM, AVG, MAX, MIN. As always a couple of examples would make this easier to undertand.
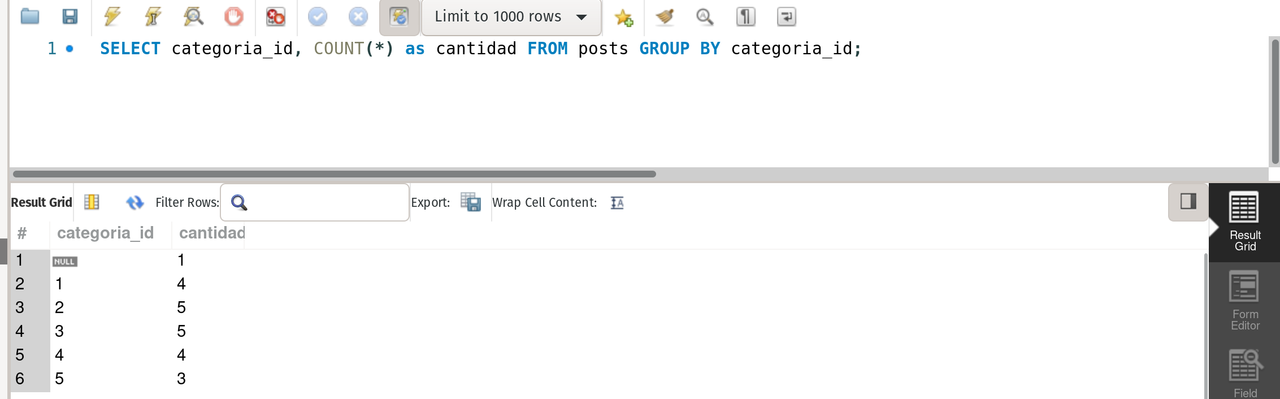
--- It returns a table that counts each appearance of categoria_id
SELECT categoria_id, COUNT(*) as cantidad FROM posts GROUP BY categoria_id;result
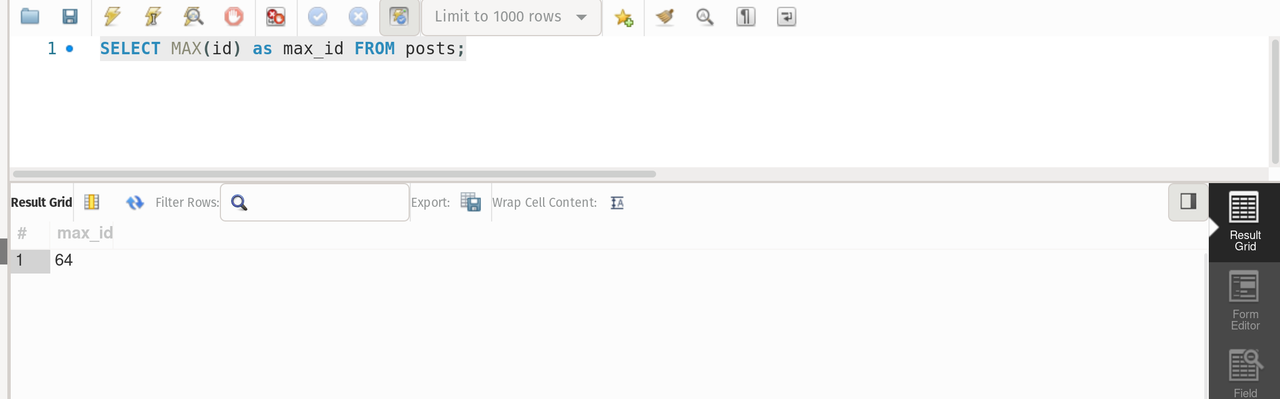
--- It returns the max id from the column id in posts
SELECT MAX(id) as max_id FROM posts;result
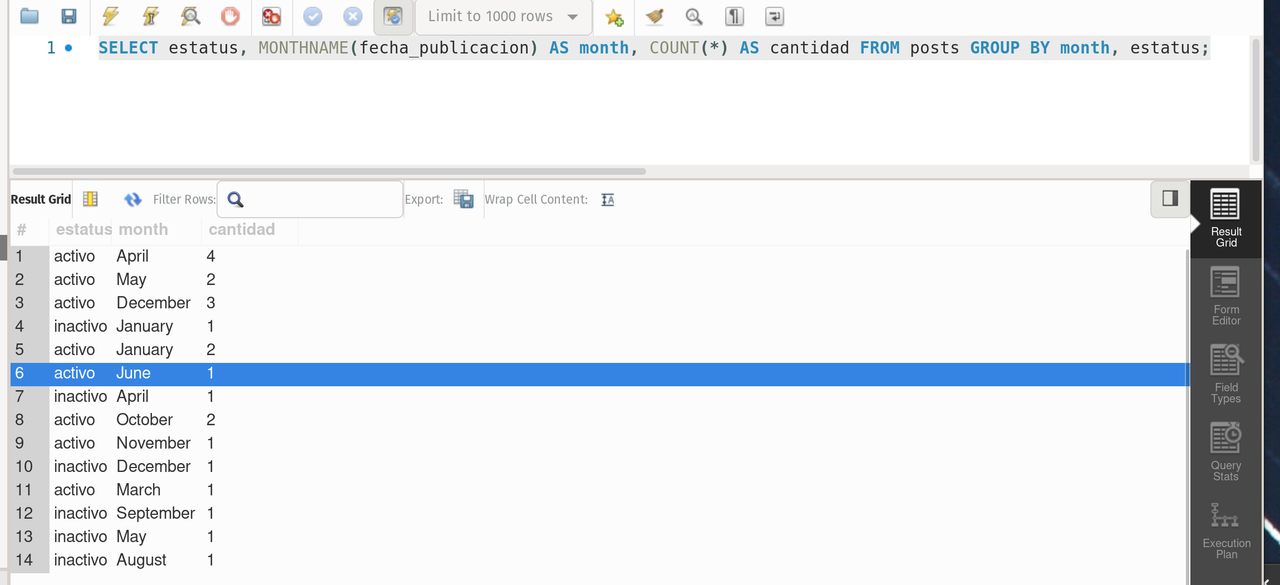
Now two queries related with dates (:disappointed::ok_hand:):
--- It returns the amount of posts per year
SELECT YEAR(fecha_publicacion) AS year, COUNT(*) AS cantidad FROM posts GROUP BY year;--- It returns the amount of posts per month and their status
SELECT estatus, MONTHNAME(fecha_publicacion) AS month, COUNT(*) AS cantidad FROM posts GROUP BY month, estatus;result
It allows to order the proyected info using columns as pivots. There are to ways, the classical ones, ascending (ASC) and descending (DESC). When a query brings a lot of info, it could be shortened by using the command LIMIT and the number of rows to display.
--- It returns the count of posts per year sorted in an ascending way and limited to show 5 rows
SELECT YEAR(fecha_publicacion) AS year, COUNT(*) AS cantidad
FROM posts
GROUP BY year
ORDER BY year ASC
LIMIT 5;result
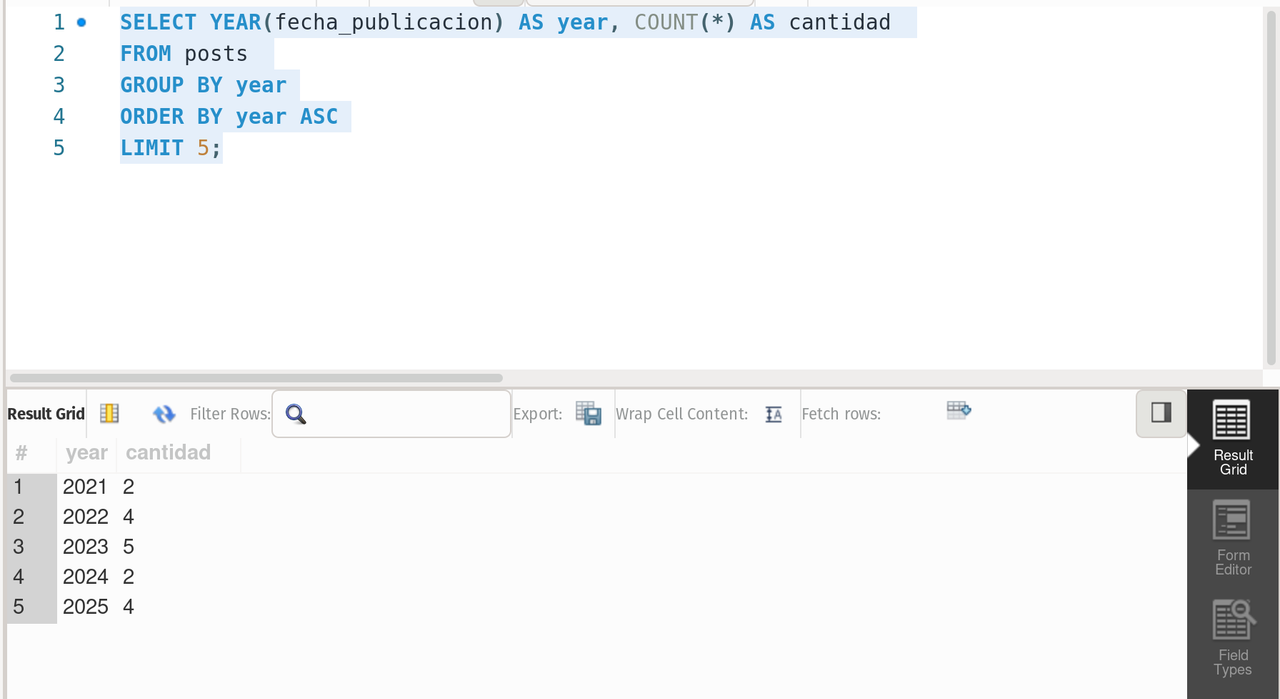
--- It returns the count of posts per year sorted in an descending way
SELECT YEAR(fecha_publicacion) AS year, COUNT(*) AS cantidad
FROM posts
GROUP BY year
ORDER BY year DESC;result
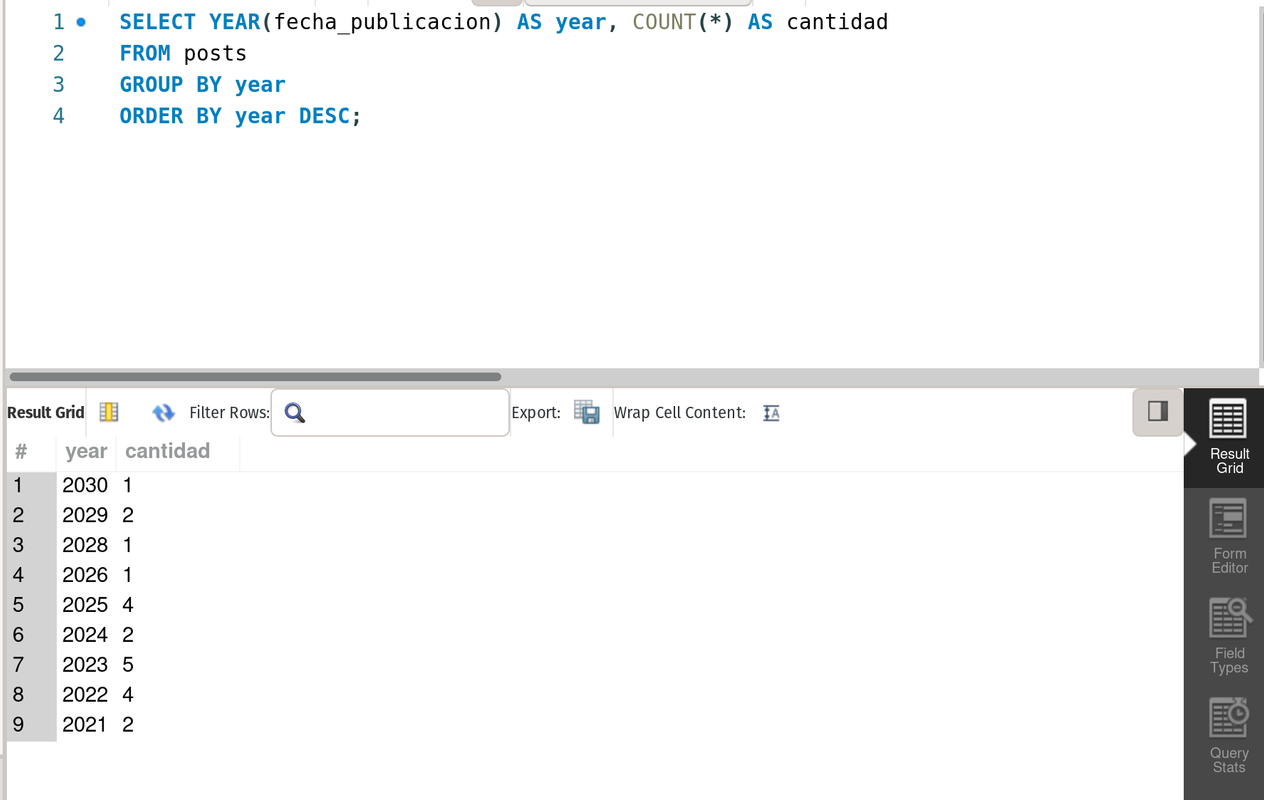
It is the WHERE when a GROUP BY is used...see the example.
--- It returns the count of posts per year after 2023 sorted in an ascending way
SELECT YEAR(fecha_publicacion) AS year, COUNT(*) AS cantidad
FROM posts
GROUP BY year HAVING year>2023
ORDER BY year DESC;result
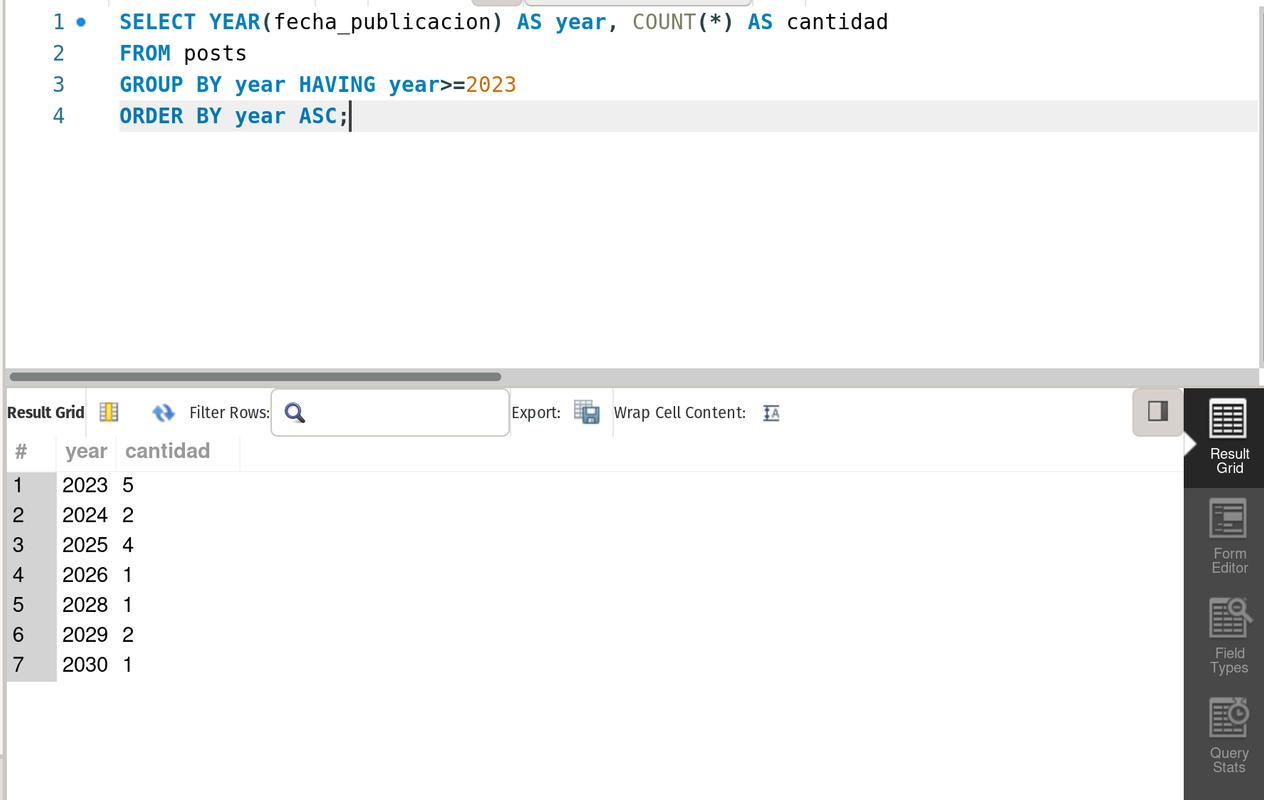
This second part will use Postgres SQL, yup another RDBMS, to create the tables just define a new schema platzi for ease and then execute alumnos table and carreras table.
Disclaimer: Notice thast the schema can be defined be code by doing:
CREATE SCHEMA `platzi` DEFAULT CHARACTER SET utf8;Some interesting queries:
--- the first 5 rows
SELECT *
FROM platzi.alumnos
LIMIT 5;
--- alternative
SELECT *
FROM platzi.alumnos
FETCH FIRST 5 ROWS ONLY;--- the second highst tuition
SELECT DISTINCT colegiatura --- Distinct selects unique values
FROM platzi.alumnos
ORDER BY colegiatura DESC
LIMIT 1 OFFSET 1; --- Offset selects the following result of limit