This code is dedicated to the task of citation matching in EXCITE. The aim of the EXCITE project is the extraction of references from PDF files, which will be done in three steps:
- Extraction of reference strings from PDFs
- Segmentation of each reference string
- Match each reference string against corresponding items in bibliographical databases
In the citation matching task, there are a set of extracted references from PDFs and this algorithm compares each reference with bibliographic records in a database to find corresponding items. For having good accuracy and at the same time, having fewer numbers of comparison, we use the combination SOLR indexing and a classifier (SVM/RFC). The algorithm generates a set of queries for each extracted reference and afterward sends these queries to SOLR for retrieving some blocks. In the next step, the algorithm generates some features out of retrieved items and the extracted reference (string and segments). In the final step, a trained classifier (SVM or RFC) will be applied on the extracted features to find out if a retrieved item is matched with the reference or not (and also a probability for each class (match or not_match)).
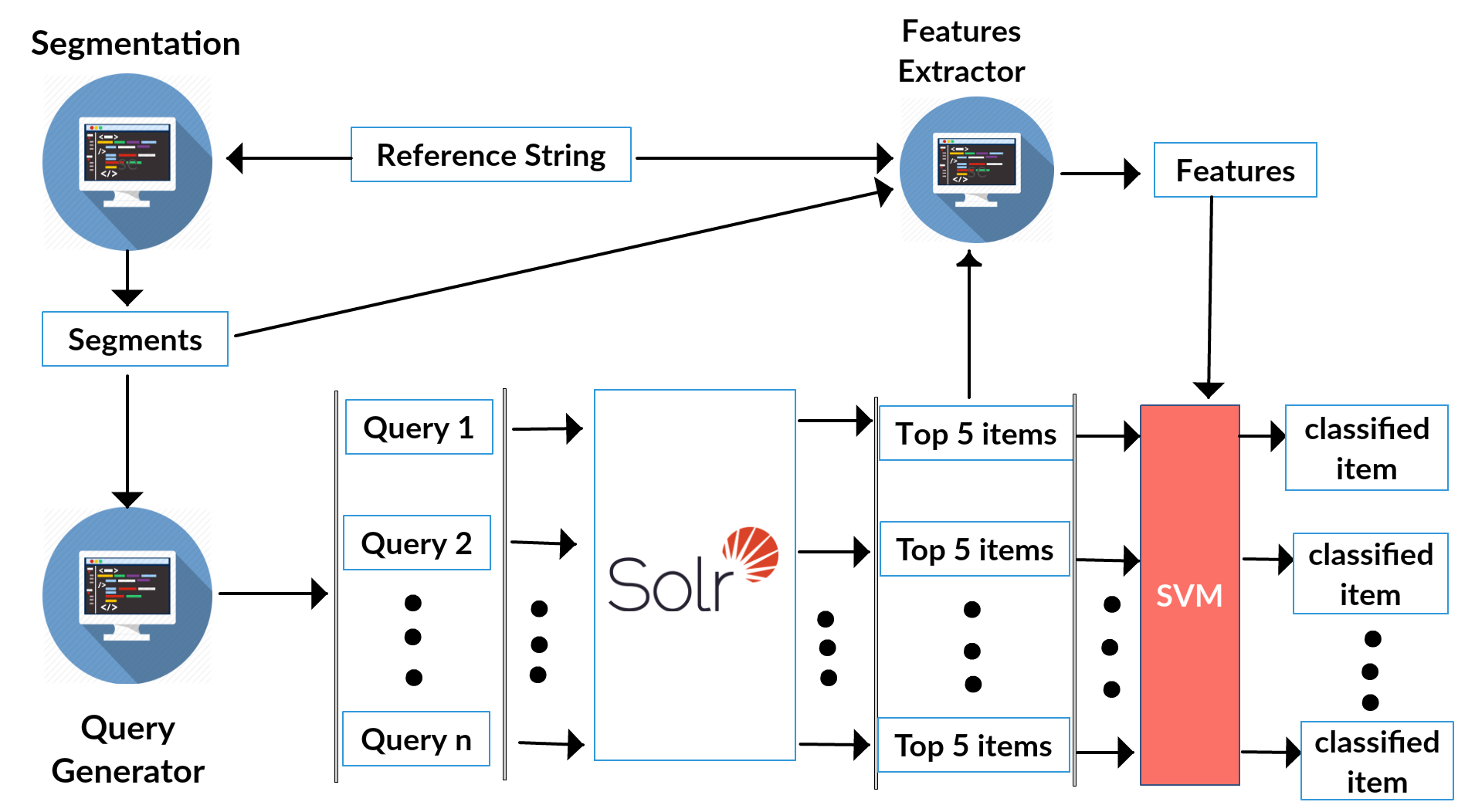
At first, please edit "configfile.json" file to define SOLR link and PSQl credential. After that, the code is ready to use. In the following, you can find that how "EXMATCHER" can be used:
#python 3.5
from 1_fiitabels import fill_tables_for_refiddict_refid_match
from 2_remove_dublicate import remove_dublicate
from 4_final_result_match import final_result
# 1.1-Generate different queres (which return result with presicion higher that 0.6) for each reference
#and
#1.2- send to SOLR api
fill_tables_for_refiddict_refid_match()
# 2- remove duplicates from retrieved items by SOLR
remove_dublicate()
# apply classifier on the retrieved items
final_result()The following code calls SOLR api for each reference in gold standard and after that extract features out of retrieved items and references:
from 3_1_features_extraction_for_train_model import featuers_labels_generator_for_training
featuers_labels_generator_for_training()The code saves a csv file for training a model. The file contains three columns: 1- ref_id, 2-feature, and 3. lable (match/not match)
from 3_2_train_model import train_model
train_model("svm")from 3_2_train_model import train_model
train_model("rfc")Please find the readme about the Crossref extension in the following link: https://github.com/exciteproject/EXmatcher/tree/master/Extension_for_matching