Economic Development not only improves people’s living standards but also changes people’s consumption concept and consumption mode. People are more and more inclined to spend ahead of time and mortgage their “credit” to the bank to enjoy certain things in advance. However, when consuming, people often lack rational thinking and overestimate their ability to repay loans to banks in time. On the one hand, it increases the loan risk of banks; on the other hand, it increases the credit crisis of consumers themselves . With a large number of banks selling credit cards, the phenomenon of credit card default emerges one after another. It is very important for banks to effectively identify high-risk credit card default users.
In our dataset we have 25 columns which reflect various attributes of the customer. The target column is default.payment.next.month , which reflects whether the customer defaulted or not. Our aim is to predict the probability of default given the payment history of the customer. I have built my model using a public dataset available on kaggle.
https://www.kaggle.com/datasets/uciml/default-of-credit-card-clients-dataset
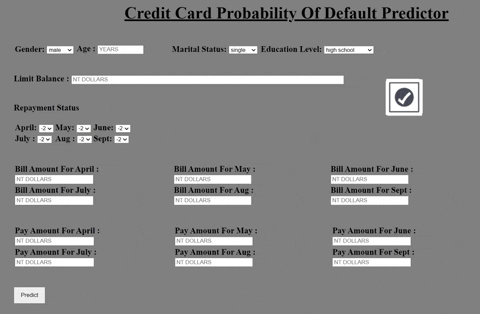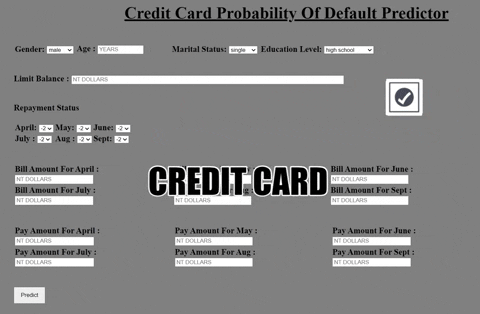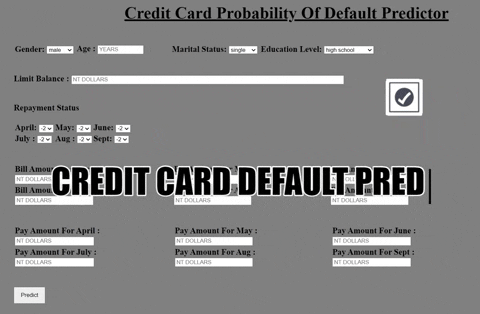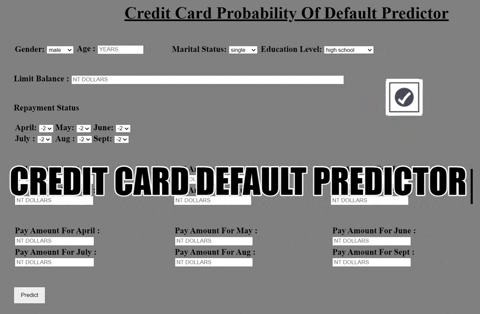
• General Data Visualisation, Analysing relation between features and target. • Using Boxplots to visualize outliers. • Data Sanity Checks.
• Load and pre-process the data using custom-defined module. • This module performs data sanity checks, replaces unknowns,removes outliers and balances the data. • To handle our categoric features I created a basic random forest model. I tried one-hot encoding, count encoding, target mean encoding and leaving the categories as discrete ordinal features. • The best results were obtained by target mean encoding. • Hence the categoric features have been target mean encoded. • For logistic regression we have scaled the data. • The pre-processed data has been saved as train.csv and test.csv
• We have built logistic regression , random forest,balanced random forest , xgboost and adaboost classifier models. • To build each of the model we hae used a custom defined module Build_Evaluate_Model. • For each of the model we start by building a base model which is based on default parameters of the model. • We then perform hyperparameter tuning and find the best model. • We save the train and test score for model comparison. • Model Evaluation : For every model built we record the train and test roc_auc score • We choose the best model based on train and test roc_auc score and difference between train and test score to ensure that there is no overfitting.
- Final Model is stored as pickle file Final_Model.pkl.
- Data_Ingestion_And_Preprocessing- Data loading and Preprocessing.
- Build_Evaluate_Model - Used in building classifiers and evaluating model performance.
- Deployment_inputs-transforming inputs from user to Features of our model.
- app.py- Used for building and deploying app.
- requirements.txt
- Procfile
- app.py
Deployed on web using Heroku url : https://credit-default-prob.herokuapp.com/