This is the official github repo of the MaxEVA paper published at FPT 2023 Conference.
Paper available on arxiv and IEEE Xplore.
If you find this repo useful, please consider citing our work:
@inproceedings{Taka2023MaxEVA,
title={Max{EVA}: {Maximizing the Efficiency of Matrix Multiplication on Versal AI Engine}},
author={Taka, Endri and Arora, Aman and Wu, Kai Chiang and Marculescu, Diana},
booktitle={2023 International Conference on Field Programmable Technology (ICFPT)},
year={2023},
pages={96-105},
organization={IEEE},
doi={10.1109/ICFPT59805.2023.00016}
}The increasing computational and memory requirements of Deep Learning (DL) workloads has led to outstanding innovations in hardware architectures. An archetype of such architectures is the novel Versal AI Engine (AIE) by AMD/Xilinx. The AIE comprises multiple programmable processors optimized for vector-based algorithms. In this work, we propose MaxEVA: a novel framework to efficiently map Matrix Multiplication (MatMul) workloads on Versal AIE devices. Our framework maximizes the performance and energy efficiency of MatMul applications by efficiently exploiting features of the AIE architecture and resolving performance bottlenecks from multiple angles. When demonstrating on the VC1902 device of the VCK190 board, MaxEVA accomplishes up to 5.44 TFLOPs and 77.01 TOPs throughput for fp32 and int8 precisions, respectively. In terms of energy efficiency, MaxEVA attains up to 124.16 GFLOPs/W for fp32, and 1.16 TOPs/W for int8. Our proposed method substantially outperforms the state-of-the-art approach by exhibiting up to 2.19× throughput gain and 20.4% higher energy efficiency.
MaxEVA constitutes a systematic methodology to maximize the performance and energy efficiency of Matrix Multiplication (MatMul) on Versal AI Engines (AIEs). The main contributions are:
- An optimization methodology based on analytical modelling to maximize the performance of MatMul on Versal AIE.
- MaxEVA efficiently exploits features of the AIE architecture and addresses various performance bottlenecks, leading to maximal utilization of the AIE resources (up to 100% AIE cores, 99.8% AIE memory and 82.1% PLIOs).
- A sophisticated AIE kernel placement strategy to effectively leverage the most efficient data movement mechanisms of the Versal AIE architecture.
- Generalizability of MaxEVA to any Versal AIE device and MatMul-based DL workloads.
Briefly, the novel design characteristics of MaxEVA are the following:
-
The proposed tiling scheme comprises the integer parameters
X,Y,Z, andM,K,N(Fig. 3 on manuscript). The tiling sizeMxKxNis determined by the single MatMul kernel mapped to one AIE core, while the parametersX,Y,Zdenote the multiple mapping of kernels to the AIE array.- Matrix size running on AIE array:
X*MxY*KxZ*N
- Matrix size running on AIE array:

- Fig. 4 presents a high-level mapping diagram of MatMul and Add kernels on the AIE array. MaxEVA utilizes only the most efficient static circuit-switching capability of the AIE (Section III-B). To overcome the major bottleneck of limited PLIO bandwidth, MaxEVA utilizes input broadcasting and output adder-tree reduction (Section IV-B).

-
Optimization of
M,K,NandX,Y,Zparameters through analytical modelling as shown at Section IV-C. -
Fig. 7 depicts the two proposed placement patterns to leverage the most efficient local data sharing mechanism of the AIE array, and thus eliminate/minimize DMA usage (Section IV-D).

This tutorial requires the following:
- The Vitis 2022.1 software platform installed on a supported Linux OS.
- A valid license for the AI Engine tools (licenses can be generated from AMD user account).
- The VCK190 base platform downloaded from the following link.
It is recommended to review the AMD/Xilinx AI Engine blog series before running this tutorial.
-
Create a new application project (e.g., named
<project_name_dir>) as shown here. -
Replace the contents of
<project_name_dir>/dataand<project_name_dir>/srcdirectories with a MaxEVA configuration, e.g.,Pattern1_int8/dataandPattern1_int8/src, respectively, for patternP1int8MaxEVA configuration. -
Right click on
<project_name_dir> [ aiengine ]and selectC/C++ Build Settingsas shown in the figure below: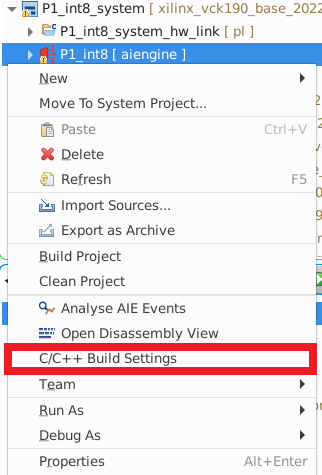
At
CompilerSettings >Mapper Optionsinvoke buffer optimizations level 8, i.e.,BufferOptLevel8: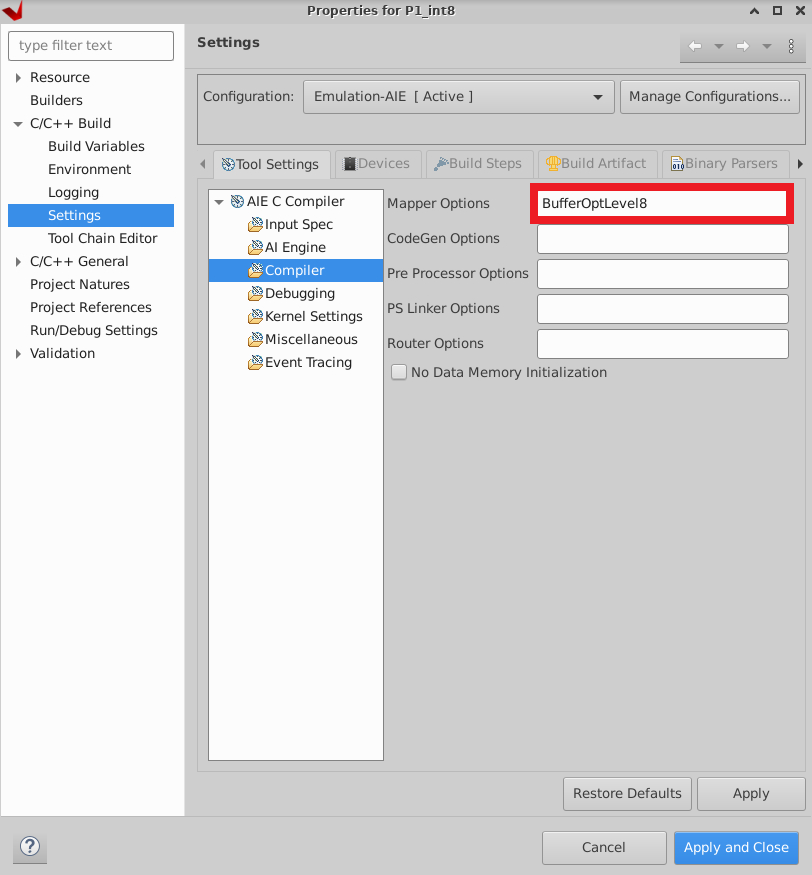
This flag will optimize buffer placement and will prevent buffer conflicts where possible, leading to higher performance. More details can be found at AMD documentation UG1076.
-
Right click on
<project_name_dir> [ aiengine ]and selectBuild Project. This step will build the project for HW Emulation. Make sure the Active build Configuration is set toEmulation-AIEas shown here. -
Generate input and golden data utilizing the
generate_golden_{int8, fp32}.cppC++ script (example below shows theint8case):cd <project_name_dir>/data g++ -o generate_golden_int8 generate_golden_int8.cpp ./generate_golden_int8
Note: This script was tested with g++ 9.4.0 compiler version.
-
When build is finished, right click on
<project_name_dir> [ aiengine ]>Run As>Launch AIE Simulatorto simulate the project. -
When emulation is finished, run the
performance_calc.pyPython script to calculate the MaxEVA throughput. Below is an example ofP1int8:python3 performance_calc.py --project_dir=<absolute_path_to_project_name_dir> --single_M=32 --single_K=128 --single_N=32 --mult_X=13 --mult_Y=4 --mult_Z=6 --precision=int8
In this example the
int8X x Y x Z = 13 x 4 x 6 MaxEVA configuration has been compiled (Table II on manuscript), with single AIE kernel size M x K x N = 32 x 128 x 32 (Table I).Note: To compile and run a new MaxEVA configuration of the same pattern, e.g., 11 x 4 x 7, modify the parameters
mult_{X, Y, Z}atPattern1_int8/src/kernels/include.haccordingly (see Section V-B for more details), and repeat steps 4-7.

