![]()
Kafka Replicator Exactly-Once - the tool to replicate data with exactly-once guarantee between different clusters of Apache Kafka.
See launch options below for quick start.
- Making a copy of data for disaster recovery purposes.
- Gathering data from different regions to the central one for aggregation.
- Data sharing between organizations.
- ...
More in Confluent docs.
- MirrorMaker from Apache Kafka.
- Replicator from Confluent.
- Simple self-made "consume-produce in the loop" application.
These tools provide either at-most-once or at-least-once delivery.
Apache Kafka has transactional API, which can be used for exactly-once delivery. The fundamental idea is to commit consumer offset and producer records in a single transaction. Kafka Streams uses it to provide high-level abstraction and easy access to exactly-once benefits. It may be enabled literally without code change, with one config option.
This works only within the same Kafka cluster.
Replication tools from the list above are not compatible with exactly-once delivery. The reason is in such case consumer offsets and producer records live in different clusters. Apache Kafka can't wrap operations with different clusters in one transaction. There is Kafka Improvement Proposal how to make it possible and good reading about it, but it exists from 2020 and nothing of it is implemented in 2023.
- Replicate messages to destination cluster with at-least-once guarantee. Wrap the messages with some metadata and apply repartitioning.
- Apply deduplication, unwrap and restore initial partitioning, using exactly-once delivery within the destination cluster.
As a drawback, it requires about 2 times more processing as compared with usual at-least-once replication.
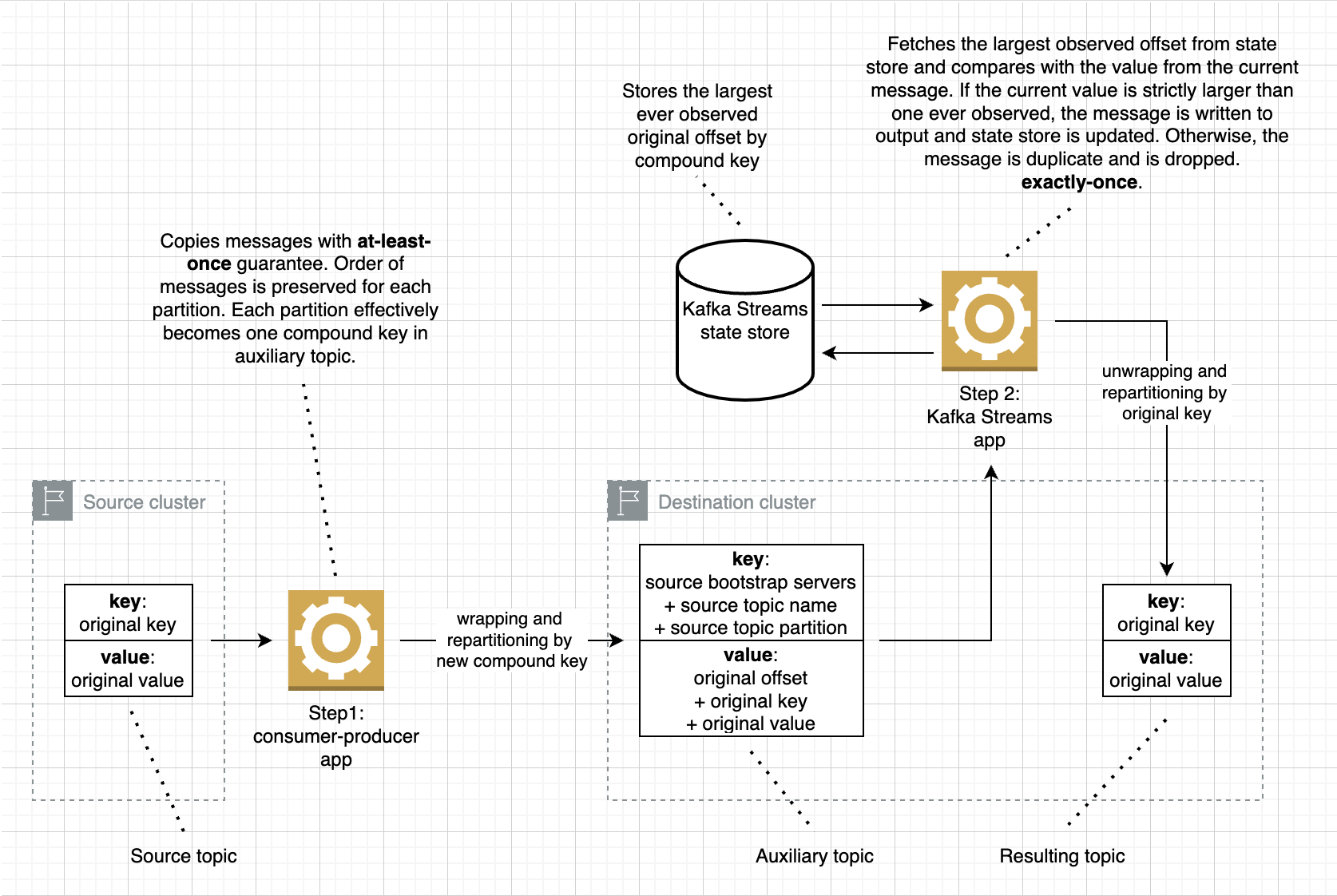
This is screenshot of design-schema.drawio from the project root.
Set your bootstrap servers and topic name for both clusters and run:
docker run \
-e KAFKA_CLUSTERS_SOURCE_BOOTSTRAP_SERVERS=source-kafka-cluster:9092 \
-e KAFKA_CLUSTERS_SOURCE_TOPIC=source-topic \
-e KAFKA_CLUSTERS_DESTINATION_BOOTSTRAP_SERVERS=destination-kafka-cluster:9092 \
-e KAFKA_CLUSTERS_DESTINATION_TOPIC=destination-topic \
emitskevich/kafka-reo
Or firstly build it from sources:
./gradlew check installDist
docker build . -t emitskevich/kafka-reo --build-arg MODULE=replicator
docker run \
-e KAFKA_CLUSTERS_SOURCE_BOOTSTRAP_SERVERS=source-kafka-cluster:9092 \
-e KAFKA_CLUSTERS_SOURCE_TOPIC=source-topic \
-e KAFKA_CLUSTERS_DESTINATION_BOOTSTRAP_SERVERS=destination-kafka-cluster:9092 \
-e KAFKA_CLUSTERS_DESTINATION_TOPIC=destination-topic \
emitskevich/kafka-reo
Replace env vars in docker-compose.yml, then run:
docker-compose up
Or firstly build it from sources:
./gradlew check installDist
docker-compose build
docker-compose up
Replace env vars in k8s-deployment.yml, then run:
kubectl apply -f k8s-deployment.yml
Launch as close to destination cluster as possible. It has notable performance boost, since the step of deduplication uses transactional API of destination cluster and is latency-sensible.