Dean Wampler, Ph.D. Typesafe dean.wampler@typesafe.com @deanwampler
This workshop demonstrates how to write and run Apache Spark Big Data applications.
Apache Spark is a distributed computing system written in Scala and developed initially as a UC Berkeley research project for distributed data programming. It has grown in capabilities and it recently became a top-level Apache project.
Spark includes support for streaming, as well as more traditional batch-mode applications. There is a SparkSQL module for writing with data sets through SQL queries. It integrates embedded SQL queries and data schemas with the normal Spark API. It also offers Hive integration so you can query existing Hive tables, even create and delete them. Finally, it has JSON support, where records written in JSON can be parsed automatically with the schema inferred and RDDs can be written as JSON.
We'll run our exercises "locally" on our laptops, which is very convenient for learning, development, and "unit" testing. However, there are several ways to run Spark clusters.
There also several Spark Shells. One is an enhanced version of the Scala REPL (read, eval, print loop shell), for interactive use. SparkSQL adds a SQL-only REPL option. You can use a Python shell, since Spark has a Python API. A Java API is also supported and R support is coming soon.
By 2013, it became increasingly clear that a successor was needed for the venerable Hadoop MapReduce compute engine. MapReduce applications are difficult to write, but more importantly, MapReduce has significant performance limitations and it can't support event-streaming ("real-time") scenarios.
Spark was seen as the best, general-purpose alternative, so Cloudera led the way in embracing Spark as a replacement for MapReduce.
Spark is now officially supported in Cloudera CDH5 and MapR's distribution. Hortonworks has recent announced they will support Spark, too. See also this page in the Spark documentation for a general discussion about running Spark with different versions of Hadoop. It also discusses other deployment scenarios.
Let's briefly discuss the anatomy of a Spark standalone cluster, adapting this discussion (and diagram) from the Spark documentation. Consider the following diagram:
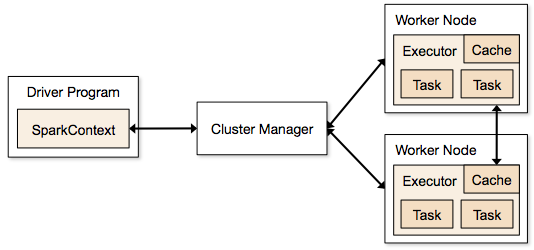
Each program we'll write is a Driver Program. It uses a SparkContext to communicate with the Cluster Manager, either Spark's own manager or the corresponding management services provided by Mesos or Hadoop's YARN. The Cluster Manager allocates resources. An Executor JVM process is created on each worker node per client application. It manages local resources, such as the cache (see below) and it runs tasks, which are provided by your program in the form of Java jar files or Python scripts.
Because each application has its own executor process per node, applications can't share data through the Spark Context. External storage has to be used (e.g., the file system, a database, a message queue, etc.)
When possible, run the driver locally on the cluster to reduce network IO as it creates and manages tasks.
Spark currently supports four deployment options for clusters:
- Standalone – A simple manager bundled with Spark for manual deployment and management of a cluster. It has some high-availability support, such as Zookeeper-based leader election of redundant master processes.
- Apache Mesos – Mesos is a general-purpose cluster management system that can also run Hadoop and other services.
- Hadoop YARN – YARN is the Hadoop v2 resource manager.
- [Amazon Web Services - EC2] - The Spark distribution includes scripts for launching Spark clusters on EC2.
You could run Spark processes on the same hardware as a Hadoop cluster using any of these approaches, but only YARN deployments truly integrate resource management between Spark and Hadoop jobs. Non-YARN deployments within a Hadoop cluster require that you statically configure some resources for Spark and some for Hadoop, because Spark and Hadoop are unaware of each other in these configurations.
For information on using YARN, see here.
For information on using Mesos, see here and here.
For information on using EC2, see here.
The data caching is one of the key reasons that Spark's performance is considerably better than the performance of MapReduce. Spark stores the data for the job in Resilient, Distributed Datasets (RDDs), where a logical data set is virtualized over the cluster.
The user can specify that data in an RDD should be cached in memory for subsequent reuse. In contrast, MapReduce has no such mechanism, so a complex job requiring a sequence of MapReduce jobs will be penalized by a complete flush to disk of intermediate data, followed by a subsequent reloading into memory by the next job.
RDDs support common data operations, such as map, flatmap, filter, fold/reduce, and groupby. RDDs are resilient in the sense that if a "partition" of data is lost on one node, it can be reconstructed from the original source without having to start the whole job over again.
The architecture of RDDs is described in the research paper Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing.
SparkSQL adds the ability to specify schema for RDDs, run SQL queries on them, and even create, delete, and query tables in Hive, the original SQL tool for Hadoop. Recently, support was added for parsing JSON records, inferring their schema, and writing RDDs in JSON format.
Several years ago, the Spark team ported the Hive frontend to Spark, calling it Shark. That port is now deprecated. SparkSQL will replace it once it is feature compatible with Hive. The new query planner is called Catalyst.
This workshop uses Spark 1.1.0.
The following documentation links provide more information about Spark:
The Documentation includes a getting-started guide and overviews. You'll find the Scaladocs API useful for the workshop.
If you're using the Typesafe Activator UI, search for activator-spark and install it in the UI. The code is built automatically.
If you grabbed this workshop from Github, you'll need to install sbt and use a command line to build and run the applications. In that case, see the sbt website for instructions on installing sbt.
To compile the code and run the tests, either use the Activator UI test link or start sbt and enter test at the prompt.
Either way, the code is compiled and the tests are executed. They should pass without error. Note that tests are provided for all the exercises, except the Spark Streaming exercise, which uses multiple processes.
Next, let's try running one of the exercises.
In Activator, use the run panel, select one of the bullet items under "Main Class", for example WordCount2, and click the "Start" button. The "Logs" panel shows some information. Note the output directories listed in the output. Use a file browser to find those directories to view the output written in those locations.
In sbt, enter run. It will present the same list of main classes. Enter one of the numbers to select the executable you want to run. Enter the number in the [...] brackets corresponding to WordCount2 to verify that everything works.
Note that the some exercises have package names with the word solns. They are solutions to the exercises. The other package has alternative implementations of some examples or exercises, for your consideration.
Here is a list of the exercises. In subsequent sections, we'll dive into the details for each one. Note that each name ends with a number, indicating the order in which we'll discuss and try them:
- Intro1: Actually, this isn't listed by the
runcommand, because it is a script we'll use with the interactive Spark Shell. - WordCount2: The Word Count algorithm: Read a corpus of documents, tokenize it into words, and count the occurrences of all the words. A classic, simple algorithm used to learn many Big Data APIs. By default, it uses a file containing the King James Version (KJV) of the Bible. (The
datadirectory has a README that discusses the sources of the data files.) - WordCount3: An alternative implementation of Word Count that uses a slightly different approach and also uses a library to handle input command-line arguments, demonstrating some idiomatic (but fairly advanced) Scala code.
- Matrix4: Demonstrates using explicit parallelism on a simplistic Matrix application.
- Crawl5a: Simulates a web crawler that builds an index of documents to words, the first step for computing the inverse index used by search engines. The documents "crawled" are sample emails from the Enron email dataset, each of which has been classified already as SPAM or HAM.
- InvertedIndex5b: Using the crawl data, compute the index of words to documents (emails).
- NGrams6: Find all N-word ("NGram") occurrences matching a pattern. In this case, the default is the 4-word phrases in the King James Version of the Bible of the form
% love % %, where the%are wild cards. In other words, all 4-grams are found withloveas the second word. The%are conveniences; the NGram Phrase can also be a regular expression, e.g.,% (hat|lov)ed? % %finds all the phrases withlove,loved,hate, andhated. - Joins7: Spark supports SQL-style joins and this exercise provides a simple example.
- SparkStreaming8: The streaming capability is relatively new and this exercise shows how it works to construct a simple "echo" server. Running it is a little more involved. See below.
- SparkSQL9: Uses the SQL API to run basic queries over structured data, in this case, the same King James Version (KJV) of the Bible used in the previous workshop.
- hadoop/SparkSQLParquet10: Demonstrates writing and reading Parquet-formatted data, namely the data written in the previous example. This example and the next one are in a
hadoopsubdirectory, because they uses features that require a Hadoop cluster (more details later on). - hadoop/HiveSQL11: A script that demonstrates interacting with Hive tables (we actually create one) in the Scala REPL!
Let's now work through these exercises...
Our first exercise demonstrates the useful Spark Shell, which is a customized version of Scala's REPL (read, eval, print, loop). We'll copy and paste some commands from the file Intro1.sc.
The comments in this and the subsequent files try to explain the API calls being made.
You'll note that the extension is .sc, not .scala. This is my convention to prevent the build from compiling this file, which won't compile because it's missing some definitions that the Spark Shell will define automatically.
Actually, we're not going to use the actual Spark Shell, because we just pull down the Spark JAR files as dependencies and not a full distribution. So, instead we'll just use the Scala REPL via the sbt console task. We'll discuss the differences of this approach.
You'll have to use a command window and sbt for this part of the workshop. If you're just interested in using Activator and not using sbt, then read through this section, but you can safely skip doing the exercise.
Change your working directory to where you installed this workshop and type sbt:
cd where_you_installed_the_workshop
sbt
At the sbt prompt, type console. You'll see a welcome message and a scala> prompt.
We're going to paste in the code from Intro1.sc . You could do it all at once, but we'll do it a few lines at a time and discuss each one. (It's harmless to paste comments from the source file.) Here is the content of the script without the comments, but broken into sections with discussions:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val sc = new SparkContext("local", "Intro (1)")
Import the SparkContext that drives everything.
Why are there two, very similar import statements? The first one imports the SparkContext type so we don't have to use a fully-qualified name in the new SparkContext statement. The second is analogous to a static import in Java, where we make some methods and values visible in the current scope, again without requiring qualification.
When you construct a SparkContext, there are several constructors you can use. This one takes a string for the "master" and a job name. The master must be one of the following:
local: Start the Spark job standalone and use a single thread to run the job.local[k]: Usekthreads instead. Should be less than the number of cores.mesos://host:port: Connect to a running, Mesos-managed Spark cluster.spark://host:port: Connect to a running, standalone Spark cluster.
You can also run Spark under Hadoop YARN, which we'll discuss at the end of the workshop.
val input = sc.textFile("data/kjvdat.txt").map(line => line.toLowerCase)
input.cache
Define a read-only variable input of type RDD (inferred) by loading the text of the King James Version of the Bible, which has each verse on a line, we then map over the lines converting the text to lower case.
The
datadirectory has a README that discusses the files present and where they came from.
Finally, we cache the data in memory for faster, repeated retrieval. You shouldn't always do this, as it consumes memory, but when your workflow will repeatedly reread the data, caching provides dramatic performance improvements.
val sins = input.filter(line => line.contains("sin"))
val count = sins.count() // How many sins?
val array = sins.collect() // Convert the RDD into a collection (array)
array.take(20) foreach println // Take the first 20, and print them 1/line.
Filter the input for just those verses that mention "sin" (recall that the text is now lower case). Then count how many found, convert the RDD to a collection. (What is the actual type??) and finally print the first twenty lines.
Note: in Scala, the () in method calls are actually optional for no-argument methods.
val filterFunc: String => Boolean =
(s:String) => s.contains("god") || s.contains("christ")
An alternative approach; create a separate filter function value instead and pass it as an argument to the filter method. Specifically, filterFunc is a value that's a function of type String to Boolean.
Actually, the following more concise form is equivalent, due to type inference:
val filterFunc: String => Boolean =
s => s.contains("god") || s.contains("christ")
val sinsPlusGodOrChrist = sins filter filterFunc
val countPlusGodOrChrist = sinsPlusGodOrChrist.count
Now use filterFunc with filter to find all the sins verses that mention God or Christ.
Then, count how many were found. Note that we dropped the parentheses after "count" in this case.
sc.stop()
Stop the session. If you exit the REPL immediately, this will happen implicitly, but as we'll see, it's a good practice to always do this in your scripts. You'll also don't typically do this when running the actual Spark Shell, as you'll usually want the context alive until you're finished completely.
Lastly, we need to run some unrelated code to setup the rest of the exercises. Namely, we need to create an output directory we'll use:
val output = new java.io.File("output")
if (output.exists == false) output.mkdir
Now, if we actually used the Spark Shell for this exercise, we would have omitted the two import statements and the statement where we created the ScalaContext value sc.
The shell automatically does these steps for us.
There are comments at the end of each source file, including this one, with suggested exercises to learn the API. Try them as time permits. Solutions for some of them are provided in the src/main/scala/com/typesafe/sparkworkshop/solns directory. Solutions aren't provided for all the suggested exercises, but I accept pull requests. ;)
All the solutions provided for the rest of the exercises are compiled by activator or sbt, so you'll be able to run them the same way.
Note: If you don't want to modify the original code when working on an exercise, just copy and edit the file, and give the
object(a singleton class) a new name.
You can exit the Scala "console" now. Type :quit or use ^d (control-d). You'll be back at the sbt prompt.
Before moving on, let's discuss how you would actually run the Spark Shell. When you download a full Spark distribution, it includes a bin directory with several Bach shell and Windows scripts. All you need to do from a command window is invoke the command bin/spark-shell (assuming your working directory is the root of the distribution).
The classic, simple Word Count algorithm is easy to understand and it's suitable for parallel computation, so it's a good vehicle when first learning a Big Data API.
In Word Count, you read a corpus of documents, tokenize each one into words, and count the occurrences of all the words globally. The initial reading, tokenization, and "local" counts can be done in parallel.
WordCount2.scala uses the same King James Version (KJV) of the Bible file we used in the first exercise. (Subsequent exercises will add the ability to override defaults with command-line arguments.)
If using the run panel, select scala.WordCount2 and click the "Start" button. The "Logs" panel shows some information. Note the "output" directories listed in the output. Use a file browser to find those directories (which have a timestamp) to view the output written in there.
If using sbt, enter run and then the number shown to the left to scala.WordCount2.
The reason the output directories have a timestamp in their name is so you can easily rerun the exercises repeatedly. Starting with v1.0.0, Spark follows the Hadoop convention of refusing to overwrite an existing directory. The timestamps keep them unique.
As before, here is the text of the script in sections, with code comments removed:
package com.typesafe.sparkworkshop
import com.typesafe.sparkworkshop.util.Timestamp // Simple date-time utility
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
We use a com.typesafe.sparkworkshop package for the compiled exercises. The Timestamp class is a simple utility class we implemented to create the timestamps we embed in put output file and directory names.
Even though our exercises from now on will be compiled classes, you could still use the Spark Shell to try out most constructs. This is especially useful when debugging and experimenting!
First, here is the outline of the script, demonstrating a pattern we'll use throughout.
object WordCount2 {
def main(args: Array[String]) = {
val sc = new SparkContext("local", "Word Count (2)")
try {
...
} finally {
sc.stop() // Stop (shut down) the context.
}
}
}
In case the script fails with an exception, putting the SparkContext.stop() inside a finally clause ensures that will get invoked no matter what happens.
The content of the try clause is the following:
val input = sc.textFile("data/kjvdat.txt").map(line => line.toLowerCase)
input.cache
val wc = input
.flatMap(line => line.split("""\W+"""))
.map(word => (word, 1))
.reduceByKey((count1, count2) => count1 + count2)
val now = Timestamp.now()
val out = s"output/kjv-wc2-$now"
println(s"Writing output to: $out")
wc.saveAsTextFile(out)
After the same loading and cache of the data we saw previously, we setup a pipeline of operations to perform the word count.
First the line is split into words using as the separator any run of characters that isn't alphanumeric (e.g., whitespace and punctuation). This also conveniently removes the trailing ~ characters at the end of each line (for some reason). input.flatMap(line => line.split(...)) maps over each line, expanding it into a collection of words, yielding a collection of collections of words. The flat part flattens those nested collections into a single, "flat" collection of words.
The next two lines convert the single word "records" into tuples with the word and a count of 1. In Shark, the first field in a tuple will be used as the default key for joins, group-bys, and the reduceByKey we use next. It effectively groups all the tuples together with the same word (the key) and then "reduces" the values using the passed in function. In this case, the two counts are added together.
The last sequence of statements creates a timestamp that can be used in a file or directory name, constructs the output path, and finally uses the saveAsTextFile method to write the final RDD to that location.
Spark follows Hadoop conventions. The out path is actually interpreted as a directory name. Here is its contents (for a run at a particular time...):
$ ls -Al output/kjv-wc2-2014.05.02-06.40.55
total 328
-rw-r--r-- 1 deanwampler staff 8 May 3 09:40 ._SUCCESS.crc
-rw-r--r-- 1 deanwampler staff 1248 May 3 09:40 .part-00000.crc
-rwxrwxrwx 1 deanwampler staff 0 May 3 09:40 _SUCCESS
-rwxrwxrwx 1 deanwampler staff 158620 May 3 09:40 part-00000
In a real cluster with lots of data and lots of concurrent processing, there would be many part-NNNNN files. They contain the actual data. The _SUCCESS file is a useful convention that signals the end of processing. It's useful because tools that are watching for the data to be written so they can perform subsequent processing will know the files are complete when they see this marker file. Finally, there are "hidden" CRC files for these other two files.
Quiz: If you look at the (unsorted) data, you'll find a lot of entries where the word is a number. (Try "grepping" to find them.) Are there really that many numbers in the bible? If not, where did the numbers come from?
There are exercises described in the source file. Solutions for some of them are implemented in the solns package. For example, solns/WordCount2GroupBy.scala
solves a "group by" exercise.
This exercise also implements Word Count, but it uses a slightly simpler approach. It also uses a utility library we added to handle input command-line arguments, demonstrating some idiomatic (but fairly advanced) Scala code.
Finally, it does some data cleansing to improve the results. The sacred text files included in the data directory, such as kjvdat.txt are actually formatted records of the form:
book|chapter#|verse#|text
That is, pipe-separated fields with the book of the Bible (e.g., Genesis, but abbreviated "Gen"), the chapter and verse numbers, and then the verse text. We just want to count words in the verses, although including the book names wouldn't change the results significantly. (Now you can figure out the answer to the "quiz" in the previous section...)
Command line options can be used to override the defaults. You'll have to use sbt from a command window to use this feature, and you'll have to use the run-main task, which lets us specify a particular main to run and optional arguments.
The "" characters in the following and subsequent command descriptions are used to indicate long lines that I wrapped to fit. Enter the commands on a single line without the "". I use [...] to indicate optional arguments, and | to indicate alternative flags:
run-main spark.WordCount3 [ -h | --help] \
[-i | --in | --inpath input] \
[-o | --out | --outpath output] \
[-m | --master master] \
[-q | --quiet]
Where the options have the following meanings:
-h | --help Show help and exit.
-i ... input Read this input source (default: data/kjvdat.txt).
-o ... output Write to this output location (default: output/kjvdat-wc3).
-m ... master local, local[k], etc. as discussed previously.
-q | --quiet Suppress some informational output.
Here is an example that simply specifies all the default values for the options (again, all on one line without the ""):
run-main spark.WordCount3 \
--inpath data/kjvdat.txt --output output/kjv-wc3 \
--master local
You can try different variants of local[k] for the master option, but keep k less than the number of cores in your machine.
The input and master arguments are basically the same things we discussed for WordCount2, but the output argument is used slightly differently. As we'll see, we'll output the results using a different mechanism than before, so the output/kjvdat-wc3 (or your alternative) will be converted to a simple file, not a Hadoop-style directory; output/kjvdat-wc3-${now}, where ${now} will be replaced with the current timestamp. The quiet option is mostly for the automated tests to use.
When you specify an input path for Spark, you can specify bash-style "globs" and even a list of them:
data/foo: Just the filefooor if it's a directory, all its files, one level deep (unless the program does some extra handling itself).data/foo*.txt: All files indatawhose names start withfooand end with the.txtextension.data/foo*.txt,data2/bar*.dat: A comma-separated list of globs.
Okay, with that out of the way, let's walk through the implementation of WordCount3, in sections:
package com.typesafe.sparkworkshop
import com.typesafe.sparkworkshop.util.{CommandLineOptions, Timestamp}
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
As before, but with our new CommandLineOptions and Timestamp utilities. (Note how Scala provides a concise syntax for selectively importing a few types in a package.)
object WordCount3 {
def main(args: Array[String]) = {
val options = CommandLineOptions(
this.getClass.getSimpleName,
CommandLineOptions.inputPath("data/kjvdat.txt"),
CommandLineOptions.outputPath("output/kjv-wc3"),
CommandLineOptions.master("local"),
CommandLineOptions.quiet)
val argz = options(args.toList)
I won't discuss the implementation of CommandLineOptions.scala except to say that it defines some methods that create instances of an Opt type, one for each of the options we discussed above. The single argument given to some of the methods (e.g., CommandLineOptions.inputPath("data/kjvdat.txt")) specifies the default value for that option.
val sc = new SparkContext(argz("master").toString, "Word Count (3)")
try {
val input = sc.textFile(argz("input-path").toString)
.map(line => line.toLowerCase.split("\\s*\\|\\s*").last)
input.cache
It starts out much like WordCount2, but it splits each line into fields, where the lines are of the form: book|chapter#|verse#|text. Only the text is kept. The input reference is an RDD that we then cache, as before. Note that calling last on the split array is robust even for lines that don't have the delimiter, if there are any; it simply returns the whole original string.
val wc2 = input
.flatMap(line => line.split("""\W+"""))
.countByValue() // Returns a Map[T, Long]
Take input and split on non-alphanumeric sequences of character as we did in WordCount2, but rather than map to (word, 1) tuples and use reduceByKey, we simply treat the words as values and call countByValue to count the unique occurrences. Hence, a simpler (and probably more efficient) approach.
val now = Timestamp.now()
val outpath = s"${argz("output-path")}-$now"
if (argz("quiet").toBoolean == false)
println(s"Writing output (${wc2.size} records) to: $outpath")
import java.io._
val out = new PrintWriter(outpath)
wc2 foreach {
case (word, count) => out.println("%20s\t%d".format(word, count))
}
// WARNING: Without this close statement, it appears the output stream is
// not completely flushed to disk!
out.close()
} finally {
sc.stop()
}
}
}
The result of countByValue is a Scala Map, not an RDD, so we use conventional Java I/O to write the output. Note the warning in the comment; failure to close the stream explicitly appears to cause data truncation when the SparkContext is stopped before the stream is flushed.
Don't forget the try the exercises at the end of the source file.
An early use for Spark was implementing Machine Learning algorithms. It has a built-in Matrix API that is useful for many such algorithms. This exercise briefly explores the Matrix API.
The sample data is generated internally; there is no input that is read. The output is written to the console.
Here is the run-main command with optional arguments:
run-main spark.Matrix4 [m [n]]
The supported options are:
m Number of rows (default: 5)
n Number of columns (default: 10)
Here is the code:
package com.typesafe.sparkworkshop
import com.typesafe.sparkworkshop.util.{Matrix, Timestamp}
import org.apache.spark.SparkContext
object Matrix4 {
// Override for tests.
var out = Console.out
def main(args: Array[String]) = {
case class Dimensions(m: Int, n: Int)
val dims = args match {
case Array(m, n) => Dimensions(m.toInt, n.toInt)
case Array(m) => Dimensions(m.toInt, 10)
case Array() => Dimensions(5, 10)
case _ =>
println("""Expected optional matrix dimensions, got this: ${args.mkString(" ")}""")
sys.exit(1)
}
Dimensions is a convenience class for capturing the default or user-specified matrix dimensions.
val sc = new SparkContext("local", "Matrix (4)")
try {
// Set up a mxn matrix of numbers.
val matrix = Matrix(dims.m, dims.n)
// Average rows of the matrix in parallel:
val sums_avgs = sc.parallelize(1 to dims.m).map { i =>
// Matrix indices count from 0.
// "_ + _" is the same as "(count1, count2) => count1 + count2".
val sum = matrix(i-1) reduce (_ + _)
(sum, sum/dims.n)
}.collect
out.println(s"${dims.m}x${dims.n} Matrix:")
sums_avgs.zipWithIndex foreach {
case ((sum, avg), index) =>
out.println(f"Row #${index}%2d: Sum = ${sum}%4d, Avg = ${avg}%3d")
}
} finally {
sc.stop()
}
}
}
The comments explain most of the steps. The crucial part is the call to parallelize that creates N parallel operations. If you have less than N cores available, some of the operations will have to wait for an available core.
The argument to parallelize is a sequence of "things" where each one will be passed to one of the operations. Here, we just use the literal syntax to construct a sequence of integers from 1 to the number of rows. When the anonymous function is called, one of those row numbers will get assigned to i. We then grab the i-1 row (because of zero indexing) and use the reduce method to sum the column elements. A final tuple with the sum and the average is returned.
The collect method is called to convert the RDD to an array, because we're just going to print results to the console. The expression sums_avgs.zipWithIndex creates a tuple with each sums_avgs value and it's index into the collection. We use that to print the row index.
This the first part of the fifth exercise. It simulates a web crawler that builds an index of documents to words, the first step for computing the inverse index used by search engines, from words to documents. The documents "crawled" are sample emails from the Enron email dataset, each of which has been previously classified already as SPAM or HAM.
Crawl5a supports the same command-line options as WordCount3:
run-main spark.Crawl5a [ -h | --help] \
[-i | --in | --inpath input] \
[-o | --out | --outpath output] \
[-m | --master master] \
[-q | --quiet]
In this case, no timestamp is appended to the output path, since it will be read by the next exercise InvertedIndex5b. So, if you rerun Crawl5a, you'll have to delete or rename the previous output manually.
Most of this code is straightforward. Its comments explain any complicated constructs used.
The output format is demonstrated with the following line from the output (email_file_name, text):
(0038.2001-08-05.SA_and_HP.spam.txt, Subject: free foreign currency newsletter ...)
The next step has to parse this format.
Using the crawl data just generated, compute the index of words to documents (emails).
InvertedIndex5b supports the same command-line options as WordCount3:
run-main spark.InvertedIndex5b [ -h | --help] \
[-i | --in | --inpath input] \
[-o | --out | --outpath output] \
[-m | --master master] \
[-q | --quiet]
Here is the code:
package com.typesafe.sparkworkshop
import com.typesafe.sparkworkshop.util.{CommandLineOptions, Timestamp}
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object InvertedIndex5b {
def main(args: Array[String]) = {
val options = CommandLineOptions(
this.getClass.getSimpleName,
CommandLineOptions.inputPath("output/crawl"),
CommandLineOptions.outputPath("output/inverted-index"),
CommandLineOptions.master("local"),
CommandLineOptions.quiet)
val argz = options(args.toList)
val sc = new SparkContext(argz("master").toString, "Inverted Index (5b)")
try {
val lineRE = """^\s*\(([^,]+),(.*)\)\s*$""".r
val input = sc.textFile(argz("input-path").toString) map {
case lineRE(name, text) => (name.trim, text.toLowerCase)
case badLine =>
Console.err.println("Unexpected line: $badLine")
("", "")
}
Inside the try expression, we load the "crawl" data, where each line was written by Crawl5a with the following format: (document_id, text) (including the parentheses). Hence, we use a regular expression with "capture groups" for the document and text.
Note the function passed to map. It has the form:
{
case lineRE(name, text) => ...
case line => ...
}
There is now explicit argument list like we've used before. This syntax is the literal syntax for a partial function, a mathematical concept for a function that is not defined at all of its inputs. It is implemented with Scala's PartialFunction type.
We have two case match clauses, one for when the regular expression successfully matches and returns the capture groups into variables name and text and the second which will match everything else, assigning the line to the variable badLine. (In fact, this catch-all clause makes the function total, not partial.) The function must return a two-element tuple, so the catch clause simply returns ("","").
Note that the specified or default input-path is a directory with Hadoop-style content, as discussed previously. Spark knows to ignore the "hidden" files.
val now = Timestamp.now()
val out = s"${argz("output-path")}-$now"
if (argz("quiet").toBoolean == false)
println(s"Writing output to: $out")
// Split on non-alphanumeric sequences of character as before.
// Rather than map to "(word, 1)" tuples, we treat the words by values
// and count the unique occurrences.
input
.flatMap {
case (path, text) => text.split("""\W+""") map (word => (word, path))
}
.map {
case (word, path) => ((word, path), 1)
}
.reduceByKey{
case (count1, count2) => count1 + count2
}
.map {
case ((word, path), n) => (word, (path, n))
}
.groupBy {
case (word, (path, n)) => word
}
.map {
case (word, seq) =>
val seq2 = seq map {
case (redundantWord, (path, n)) => (path, n)
}
(word, seq2.mkString(", "))
}
.saveAsTextFile(out)
} finally {
sc.stop()
}
}
}
See if you can understand what this sequence of transformations is doing. You could try reading a smaller input file (say the first "N" lines of the crawl output), then hack on the script to output some of the results from each step.
A few useful RDD methods include RDD.sample or RDD.take, to select a subset of elements. Use RDD.saveAsTextFile to write to a file or use RDD.collect to convert the RDD data into a "normal" collection and then use one of the print* methods to dump the contents.
The end goal is to output each record string in the following form: (word, (doc1, n1), (doc2, n2), ...). For example, the word "ability" appears twice in one email and once in another (both SPAM):
(ability,(0018.2003-12-18.GP.spam.txt,2), (0020.2001-07-28.SA_and_HP.spam.txt,1))
In Natural Language Processing, one goal is to determine the sentiment or meaning of text. One technique that helps do this is to locate the most frequently-occurring, N-word phrases, or NGrams. Longer NGrams can convey more meaning, but they occur less frequently so all of them appear important. Shorter NGrams have better statistics, but each one conveys less meaning. In most cases, N = 3-5 appears to provide the best balance.
This exercise finds all NGrams matching a user-specified pattern. The default is the 4-word phrases the form % love % %, where the % are wild cards. In other words, all 4-grams are found with love as the second word. The % are conveniences; the user can also specify an NGram Phrase that is a regular expression or a mixture, e.g., % (hat|lov)ed? % % finds all the phrases with love, loved, hate, or hated as the second word.
NGrams6 supports the same command-line options as WordCount3, except for the output path (it just writes to the console), plus two new options:
run-main spark.NGrams6 [ -h | --help] \
[-i | --in | --inpath input] \
[-m | --master master] \
[-c | --count N] \
[-n | --ngrams string] \
[-q | --quiet]
Where
-c | --count N List the N most frequently occurring NGrams (default: 100)
-n | --ngrams string Match string (default "% love % %"). Quote the string!
I'm in yür codez:
package com.typesafe.sparkworkshop
import com.typesafe.sparkworkshop.util.{CommandLineOptions, Timestamp}
import com.typesafe.sparkworkshop.util.CommandLineOptions.Opt
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object NGrams6 {
// Override for tests.
var out = Console.out
def main(args: Array[String]) = {
/** A function to generate an Opt for handling the count argument. */
def count(value: String): Opt = Opt(
name = "count",
value = value,
help = s"-c | --count N The number of NGrams to compute (default: $value)",
parser = {
case ("-c" | "--count") +: n +: tail => (("count", n), tail)
})
/**
* The NGram phrase to match, e.g., "I love % %" will find 4-grams that
* start with "I love", and "% love %" will find trigrams with "love" as the
* second word.
* The "%" are replaced by the regex "\w+" and whitespace runs are replaced
* with "\s+" to create a matcher regex.
*/
def ngrams(value: String): Opt = Opt(
name = "ngrams",
value = value,
help = s"-n | --ngrams S The NGrams match string (default: $value)",
parser = {
case ("-n" | "--ngrams") +: s +: tail => (("ngrams", s), tail)
})
val options = CommandLineOptions(
this.getClass.getSimpleName,
CommandLineOptions.inputPath("data/kjvdat.txt"),
CommandLineOptions.master("local"),
CommandLineOptions.quiet,
count("100"),
ngrams("% love % %"))
val argz = options(args.toList)
val sc = new SparkContext(argz("master").toString, "NGrams (6)")
val ngramsStr = argz("ngrams").toString.toLowerCase
// Note that the replacement strings use Scala's triple quotes; necessary
// to ensure that the final string is "\w+" and "\s+" for the reges.
val ngramsRE =
ngramsStr.replaceAll("%", """\\w+""").replaceAll("\\s+", """\\s+""").r
val n = argz("count").toInt
Without discussing the details, this example defines two new Opt instances for handling the NGram phrase and count options. Because we allow the user to mix % characters for word wildcards and regular expressions, we convert the % to regexs for words and also replace all runs of whitespace with a more flexible regex for whitespace.
try {
object CountOrdering extends Ordering[(String,Int)] {
def compare(a:(String,Int), b:(String,Int)) =
-(a._2 compare b._2) // - so that it sorts descending
}
val ngramz = sc.textFile(argz("input-path").toString)
.flatMap { line =>
val text = line.toLowerCase.split("\\s*\\|\\s*").last
ngramsRE.findAllMatchIn(text).map(_.toString)
}
.map(ngram => (ngram, 1))
.reduceByKey((count1, count2) => count1 + count2)
.takeOrdered(n)(CountOrdering)
out.println(s"Found ${ngramz.size} ngrams:")
ngramz foreach {
case (ngram, count) => out.println("%30s\t%d".format(ngram, count))
}
} finally {
sc.stop()
}
}
}
We need an implementation of Ordering to sort our found NGrams descending by count.
We read the data as before, but note that because of our line orientation, we won't find NGrams that cross line boundaries! This doesn't matter for our sacred text files, since it wouldn't make sense to find NGrams across verse boundaries, but a more flexible implementation should account for this. Note that we also look at just the verse text, as in WordCount3.
The map and reduceByKey calls are just like we used previously for WordCount2, but now we're counting found NGrams. The final takeOrdered call combines sorting with taking the top n found. This is more efficient than separate sort, then take operations. As a rule, when you see a method that does two things like this, it's usually there for efficiency reasons!
Joins are a familiar concept in databases and Spark supports them, too. Joins at very large scale can be quite expensive, although a number of optimizations have been developed, some of which require programmer intervention to use. We won't discuss the details here, but it's worth reading how joins are implemented in various Big Data systems, such as this discussion for Hive joins and the Joins section of Hadoop: The Definitive Guide.
Here, we will join the KJV Bible data with a small "table" that maps the book abbreviations to the full names, e.g., Gen to Genesis.
Joins7 supports the following command-line options:
run-main spark.Joins7 [ -h | --help] \
[-i | --in | --inpath input] \
[-o | --out | --outpath output] \
[-m | --master master] \
[-a | --abbreviations path] \
[-q | --quiet]
Where the --abbreviations is the path to the file with book abbreviations to book names. It defaults to data/abbrevs-to-names.tsv. Note that the format is tab-separated values, which the script must handle correctly.
Here r yur codez:
object Joins7 {
def main(args: Array[String]) = {
/** The "dictionary" of book abbreviations to full names */
val abbrevsFile = "data/abbrevs-to-names.tsv"
val abbrevs = Opt(
name = "abbreviations",
value = abbrevsFile,
help = s"-a | --abbreviations path The dictionary of book abbreviations to full names (default: $abbrevsFile)",
parser = {
case ("-a" | "--abbreviations") +: path +: tail => (("abbreviations", path), tail)
})
val options = CommandLineOptions(
this.getClass.getSimpleName,
CommandLineOptions.inputPath("data/kjvdat.txt"),
abbrevs,
CommandLineOptions.outputPath("output/kjv-joins"),
CommandLineOptions.master("local"),
CommandLineOptions.quiet)
val argz = options(args.toList)
val sc = new SparkContext(argz("master").toString, "Joins (7)")
The input sacred text (default: data/kjvdat.txt) is assumed to have the format book|chapter#|verse#|text:
try {
val input = sc.textFile(argz("input-path").toString)
.map { line =>
val ary = line.split("\\s*\\|\\s*")
(ary(0), (ary(1), ary(2), ary(3)))
}
Note the output tuple format from the map. For joins, Spark wants a (key,value) tuple, so we use a nested tuple for the chapter, verse, and text. The abbreviations file is handled similarly, but the delimiter is a tab:
val abbrevs = sc.textFile(argz("abbreviations").toString)
.map{ line =>
val ary = line.split("\\s+", 2)
(ary(0), ary(1).trim) // I've noticed trailing whitespace...
}
Note the second argument to split. Just in case a full book name has a nested tab, we explicitly only want to split on the first tab found, yielding two strings.
// Cache both RDDs in memory for fast, repeated access.
input.cache
abbrevs.cache
// Join on the key, the first field in the tuples; the book abbreviation.
val verses = input.join(abbrevs)
if (input.count != verses.count) {
println(s"input count != verses count (${input.count} != ${verses.count})")
}
We perform an inner join on the keys of each RDD and add a sanity check for the output. Since this is an inner join, the sanity check catches the case where an abbreviation wasn't found and the corresponding verses were dropped!
The schema of verses is this: (key, (value1, value2)), where value is (chapter, verse, text) from the KJV input and value is the full book name, the second "field" from the abbreviations file. We now flatten the records to the final desired form, fullBookName|chapter|verse|text:
val verses2 = verses map {
// Drop the key - the abbreviated book name
case (_, ((chapter, verse, text), fullBookName)) =>
(fullBookName, chapter, verse, text)
}
Lastly, we write the output:
val now = Timestamp.now()
val out = s"${argz("output-path")}-$now"
if (argz("quiet").toBoolean == false)
println(s"Writing output to: $out")
verses2.saveAsTextFile(out)
} finally {
sc.stop()
}
}
}
The join method we used is implemented by spark.rdd.PairRDDFunctions, with many other methods for computing "co-groups", outer joins, etc.
You can verify that the output file looks like the input KJV file with the book abbreviations replaced with the full names. However, as currently written, the books are not in the correct order! (See the exercises in the source file.)
The streaming capability is relatively new and our last exercise shows how it works to construct a simple "echo" server. It has two running modes. The default mode just reads the contents of a file (the KJV Bible file, by default). That works best in Activator using the "run" command.
In Activator or sbt, run SparkStreaming8 as we've done for the other exercises. It will read the KJV Bible text file, then terminate after 5 seconds, because otherwise the app will run forever, waiting for a changed text file to appear!
Alternatively, the app can receive text over a socket connection. We'll use a console network app to send data to the spark streaming process, either the nc console app that's part of NetCat or the NCat app that comes with NMap, which is available for more platforms, like Windows. If you're on a Mac or Linux machine, you probably already have nc installed.
To try the app with a socket connection, open a second console window to use nc or ncat. Then, run this nc command (or the equivalent for ncat):
nc -c -l -p 9999
The -c option (which could be omitted) tells it to terminate if the socket drops, the -l option puts nc into listen mode, and the -p option is used to specify the port.
If you've been using Activator, open another console/shell window and change to the project directory. If you've been using sbt, just use the same session. Run SparkStreaming8 with the following sbt command:
Note that it has default arguments for the host (localhost) and the port (9999), e.g., you could use this sbt command to override them:
run-main spark.SparkStreaming8 --socket localhost:9999
Back to the nc console, type (or copy and paste) text into the window. After each carriage return, the text is sent to the SparkStreaming8 app, where word count is performed on it and some output is written to that app's console window.
Once again, SparkStreaming8 will terminate after 5 seconds, because otherwise the app will try to run forever!
However, it does detect if the socket connection drops, e.g., you hit ^C in the nc window. It will take a few moments to shut itself down. The app has a "listener" that
will shutdown when the socket drops. However, by default, Spark Streaming will attempt to re-establish the connection, which is probably what you would want in a long-running system.
The 5-second timeout is still on in the streaming scenario, but you can disable it when using either input mode by also passing the argument --no-term ("no terminate"):
run-main spark.SparkStreaming8 --socket localhost:9999 --no-term
Restart nc in the other window and try this variant of run-main. After a few seconds, use ^C to kill nc and watch the error messages generated in the sbt window. Note how long it takes for the application to shutdown.
You can use any server:port combination you want, even on a remote machine.
To recap, SparkStreaming8 supports the following command-line options:
run-main spark.SparkStreaming8 [ -h | --help] \
[-i | --in | --inpath input] \
[-s | --socket server:port] \
[-n | --no | --no-term] \
[-q | --quiet]
Where the default is --inpath data/kjvdat.txt.
Spark Streaming uses a clever hack; it runs more or less the same Spark API (or code that at least looks conceptually the same) on deltas of data, say all the events received within 1-second intervals (which is what we used here). Those deltas are RDDs encapsulated in a DStream ("Discretized Stream").
A StreamingContext is used to wrap the normal SparkContext, too.
Here is the code for SparkStreaming8.scala:
object SparkStreaming8 {
// Override for tests, etc.
var out = Console.out
val timeout = 5 * 1000 // 5 seconds
/**
* Use "--socket host:port" to listen for events.
* To read "events" from a directory of files instead, e.g., for testing,
* use the "--inpath" argument.
*/
def socket(hostPort: String): Opt = Opt(
name = "socket",
value = hostPort,
help = s"-s | --socket host:port Listen to a socket for events (default: $hostPort unless --inpath used)",
parser = {
case ("-s" | "--socket") +: hp +: tail => (("socket", hp), tail)
})
/**
* Use "--no-term" to keep this process running "forever" (or until ^C).
*/
def noterm(): Opt = Opt(
name = "no-term",
value = "", // ignored
help = s"-n | --no | --no-term Run forever; don't terminate after $timeout seconds)",
parser = {
case ("-n" | "--no" | "--no-term") +: tail => (("no-term", "true"), tail)
})
case class EndOfStreamListener(sc: StreamingContext) extends StreamingListener {
override def onReceiverError(error: StreamingListenerReceiverError):Unit = {
out.println(s"Receiver Error: $error. Stopping...")
sc.stop()
}
override def onReceiverStopped(stopped: StreamingListenerReceiverStopped):Unit = {
out.println(s"Receiver Stopped: $stopped. Stopping...")
sc.stop()
}
}
We define Opt objects for the new command-line options --socket server:port and --no-term.
The EndOfStreamListener will be used to detect when a socket connection drops. It will start the exit process. Note that it is not triggered when the end of file is reached while reading directories of files. In this case, we have to rely on the 5-second timeout to quit.
def main(args: Array[String]) = {
val options = CommandLineOptions(
this.getClass.getSimpleName,
CommandLineOptions.inputPath("data/kjvdat.txt"),
// We write to "out" instead of to a directory:
// CommandLineOptions.outputPath("output/kjv-wc3"),
// For this process, use at least 2 cores!
CommandLineOptions.master("local[2]"),
socket(""), // empty default, so we know the user specified this option.
noterm(),
CommandLineOptions.quiet)
val argz = options(args.toList)
The usual command-line argument processing.
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("Spark Streaming (8)")
.set("spark.cleaner.ttl", "60")
.set("spark.files.overwrite", "true")
// If you need more memory:
// .set("spark.executor.memory", "1g")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(1))
ssc.addStreamingListener(EndOfStreamListener(ssc))
Construct the SparkContext a different way, by first defining a SparkConf (configuration) object. First, it is necessary to use 2 cores, which is specified using setMaster("local[2]") to avoid a problem discussed here.
Spark Streaming requires the TTL to be set, spark.cleaner.ttl, which defaults to infinite. This specifies the duration in seconds for how long Spark should remember any metadata, such as the stages and tasks generated, etc. Periodic clean-ups are necessary for long-running streaming jobs. Note that an RDD that persists in memory for more than this duration will be cleared as well. See Configuration for more details.
With the SparkContext, we create a StreamingContext, where we also specify the time interval. Finally, we add a listener for socket drops.
try {
val lines =
if (argz("socket") == "") useDirectory(ssc, argz("input-path"))
else useSocket(ssc, argz("socket"))
If a socket connection wasn't specified, then use the input-path to read from one or more files (the default case). Otherwise use a socket. An InputDStream is returned in either case as lines. The two methods useDirectory and useSocket are listed below.
From the DStream (Discretized Stream) that fronts either the socket or the files, an RDD will be periodically generated for each discrete chunk of (possibly empty) data in each 1-second interval.
Now we implement an incremental word count:
val words = lines.flatMap(line => line.split("""\W+"""))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.transform(rdd => rdd.reduceByKey(_ + _))
wordCounts.print() // print a few counts...
// Generates a separate directory inside "out" each interval!!
// val now = Timestamp.now()
// val out = s"output/streaming/kjv-wc-$now"
// println(s"Writing output to: $out")
// wordCounts.saveAsTextFiles(out, "txt")
ssc.start()
if (argz("no-term") == "") ssc.awaitTermination(timeout)
else ssc.awaitTermination()
} finally {
// Having the ssc.stop here is only needed when we use the timeout.
out.println("+++++++++++++ Stopping! +++++++++++++")
ssc.stop()
}
}
This works much like our previous word count logic, except for the use of transform, a DStream method for transforming the RDDs into new RDDs. In this case, we are performing "mini-word counts", within each RDD, but not across the whole DStream.
Note that we comment out writing the results to files, as it creates a separate output directory per interval (1 second), most of which are empty for this example. However, it's worth uncommenting these lines for one run to see what's produced.
Lastly, we wait for termination. By default, we set a timeout of 5 seconds.
The app ends with useSocket and useDirectory:
private def useSocket(sc: StreamingContext, serverPort: String): DStream[String] = {
try {
// Pattern match to extract the 0th, 1st array elements after the split.
val Array(server, port) = serverPort.split(":")
out.println(s"Connecting to $server:$port...")
sc.socketTextStream(server, port.toInt)
} catch {
case th: Throwable =>
sc.stop()
throw new RuntimeException(
s"Failed to initialize host:port socket with host:port string '$serverPort':",
th)
}
}
// Hadoop text file compatible.
private def useDirectory(sc: StreamingContext, dirName: String): DStream[String] = {
out.println(s"Reading 'events' from directory $dirName")
sc.textFileStream(dirName)
}
}
This is just the tip of the iceberg for Streaming. See the Streaming Programming Guide for more information.
When you use a closure (anonymous function), Spark will serialize it and send it around the cluster. This means that any captured variables must be serializable.
A common mistake is to capture a field in an object, which forces the whole object to be serialized. Sometimes it can't be. Consider this example adapted from this presentation.
class RDDApp {
val factor = 3.14159
val log = new Log(...)
def multiply(rdd: RDD[Int]) = {
rdd.map(x => x * factor).reduce(...)
}
}
The closure passed to map captures the field factor in the instance of RDDApp. However, the JVM must serialize the whole object, and a NotSerializableException will result when it attempts to serialize log.
Here is the work around; assign factor to a local field:
class RDDApp {
val factor = 3.14159
val log = new Log(...)
def multiply(rdd: RDD[Int]) = {
val factor2 = factor
rdd.map(x => x * factor2).reduce(...)
}
}
Now, only factor2 must be serialized.
The new SparkSQL API extends RDDs with a "schema" for records, defined using a Scala case class, and allows you to embed queries using a subset of SQL in strings, as a supplement to the regular manipulation methods on the RDD type; use the best tool for the job in the same application! There is also a builder DSL for constructing these queries, rather than using a string.
Furthermore, SparkSQL now supports parsing JSON-formatted records, inferring the schema, and writing RDDs in JSON.
Finally, SparkSQL embeds access to a Hive metastore, so you can create and delete tables, and run queries against them using Hive's query language, HiveQL.
This example treats the King James Bible text, kjvdat.txt, as a table with a schema. It runs several queries on the data.
As in the previous Spark Workshop, command line options can be used to override the defaults. We'll have to use sbt from a command window to use this feature (rather than the Activator UI), and we'll have to use the run-main task, which lets us specify a particular main to run and optional arguments.
The "" characters in the following and subsequent command descriptions are used to indicate long lines that I wrapped to fit. Enter the commands on a single line without the "". I use [...] to indicate optional arguments, and | to indicate alternative flags:
run-main spark.SparkSQL9 [ -h | --help] \
[-i | --in | --inpath input] \
[-m | --master master] \
[-q | --quiet]
Where the options have the following meanings:
-h | --help Show help and exit.
-i ... input Read this input source (default: data/kjvdat.txt).
-m ... master local, local[k], etc. as discussed previously.
-q | --quiet Suppress some informational output.
The options work the same as before, except we don't append a timestamp to the output path, because its contents will be read by the next exercise.
The codez!
val options = CommandLineOptions(...) // as before
val argz = options(args.toList)
val sc = new SparkContext(argz("master").toString, "Spark SQL (9)")
val sqlc = new SQLContext(sc)
import sqlc._
try {
...
} finally {
sc.stop()
}
After the typical options parsing and creating a SparkContext, we create a special SQLContext that wraps then. The import statement that follows pulls in some context objects and "implicit" conversations needed later. Implicit conversions are invoked by the compiler when an instance of one object needs to be wrapped in or converted to another one, e.g., to create the illusion that you can call new methods on the object that aren't defined for the original type! (If you don't know Scala and you didn't follow that explanation, it's not critical for what follows.)
Here is the contents of the try block:
val lineRE = """^\s*([^|]+)\s*\|\s*([\d]+)\s*\|...~?\s*$""".r
val verses = sc.textFile(argz("input-path").toString) flatMap {
case lineRE(book, chapter, verse, text) =>
Seq(Verse(book, chapter.toInt, verse.toInt, text))
case line =>
Console.err.println("Unexpected line: $line")
Seq.empty[Verse] // Will be eliminated by flattening.
}
...
Defines a regex to extract the fields on each line, separated by "|", and also removes the trailing "~" unique to this file. Then it invokes flatMap over the file lines (each considered a record) to extract each "good" lines and convert them into a Verse instances. Verse is defined in the util package. If a line is bad, a log message is written and an empty sequence is returned. Using flatMap and sequences means we'll effectively remove the bad lines.
verses.registerTempTable("kjv_bible")
verses.cache()
val godVerses = sql("SELECT * FROM kjv_bible WHERE text LIKE '%God%'")
println("Number of verses that mention God: "+godVerses.count())
godVerses
.collect() // convert to a regular in-memory collection
.foreach(println) // print the query results.
...
Registers the RDD as a temporary table in the Hive metadata store. A single process Derby SQL database is used. It writes its data to a metastore directory in the current directory. The data is also cached in memory.
Even though verses is an RDD, an "implicit" conversion imported from sqlc (SQLContext) converts it to a The actual method is defined on org.apache.spark.sql.SchemaRDD, which provides the registerTempTable method.
The call to sql was imported from the sqlc (SQLContext) instance. We can write a SQL query and the results are returned as a new RDD! We then collect it into an Array[Verse] and then print each line.
val counts = sql("SELECT book, COUNT(*) FROM kjv_bible GROUP BY book")
.coalesce(1)
println("Verses per book:")
counts
.collect() // Convert to a regular in-memory collection.
.foreach(println) // Print the query results.
...
Note that the SQL dialect currently supported by the sql method is a subset of HiveSQL. For example, it doesn't permit column aliasing, e.g., COUNT(*) AS count. Nor does it appear to support WHERE clauses in some situations.
Then take the RDD returned by the query and collect all partitions into 1 partition. Otherwise, there are hundreds of partitions output from the last query!
That's it. As before, there are suggested exercises at the end of the source file. Some solutions are provided in the solns source package.
This script demonstrates the methods for reading and writing files in the Parquet format. It reads in the same data as in the previous example, writes it to new files in Parquet format, then reads it back in and runs queries on it.
NOTE: Running this script requires a Hadoop installation, therefore it won't run in the SBT
consoleas configured for the project.
The key SchemaRDD methods are SchemaRDD.saveAsParquetFile(outpath) and SqlContext.parquetFile(inpath). The rest of the details are very similar to the previous exercise.
See the script for more details.
The previous examples used the new Catalyst query engine. However, SparkSQL also has an integration with Hive, so you can write HiveQL (HQL) queries, manipulate Hive tables, etc. This example demonstrates this feature. So, we're not using the Catalyst SQL library, but Hive's.
NOTE: Running this script requires a Hadoop installation, therefore it won't run in the SBT
consoleas configured for the project.
Note that the Hive "metadata" is stored in a megastore directory created in the current working directory. This is written and managed by Hive's embedded Derby SQL store, but it's not a production deployment option.
import org.apache.spark.SparkContext
import org.apache.spark.sql._
import org.apache.spark.sql.hive.LocalHiveContext
import com.typesafe.sparkworkshop.util.Verse
val sc = new SparkContext("local[2]", "Hive SQL (10)")
val hiveContext = new LocalHiveContext(sc)
import hiveContext._ // Make methods local, like for SQLContext
...
Analogous to the previous examples, but now we crate a LocalHiveContext.
println("Create the 'external' kjv Hive table:")
hql("""
CREATE EXTERNAL TABLE IF NOT EXISTS kjv (
book STRING,
chapter INT,
verse INT,
text STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
LOCATION '/tmp/data'""")
...
Here we use a triple-quoted string to specify a multi-line HiveQL statement to create a table. In this case, an EXTERNAL table is created, where we just tell it use data in a particular directory (LOCATION).
While we can't actually run this script, should you try it on a Hadoop installation, here are a few things to do first or to keep in mind:
- You must first copy
data/kjvdat.txtto an empty/tmp/kjvdirectory, because Hive expects theLOCATIONto be an absolute directory path. Also, Hive (like all Hadoop applications) will expect this path to be a directory and it will read all the files in it. If you are on Windows (and not running Cygwin), pick a suitable location on your hard drive and change theLOCATIONline to use the correct, absolute path. - Omit semicolons at the end of the HQL (Hive SQL) string. While those would be required in Hive's REPL or scripts, they cause errors here!
- The query results are returned in an RDD. To dump to the console, we use
collect.foreach(println), which converts the RDD to an in-memory array, then loops over each record and prints the results.
To learn more, see the following:
- The Apache Spark website.
- The Apache Spark Quick Start. See also the examples in the Spark distribution and be sure to study the Scaladoc pages for key types such as
RDDandSchemaRDD. - The SparkSQL Programmer's Guide
- Talks from Spark Summit 2013.
- Talks from Spark Summit 2014.
- Running Spark in EC2.
- Running Spark on Mesos.
Experience Reports:
Other Spark Based Libraries:
- See Typesafe Activator to find other Activator templates.
- See Typesafe for more information about our products and services.