Pada Proyek kali ini domain proyek yang penulis pilih adalah mengenai hiburan yaitu "Anime Recommendation system".
Latar Belakang Saat ini kartun jepang atau anime mengalami perkembangan yang sangat cepat dan penggemarnya tersebar diseluruh dunia. Terutama dengan merebaknya pandemi yang serba terbatas, membuat kebutuhan manusia akan hiburan semakin bertambah, salah satunya kartun jepang ini. Sudah banyak sekali platform yang menyediakan media hiburan seperti kartun jepang. Tentunya sebagai salah satu strategi marketing dalam dunia bisnis, UX atau user experience merupakan hal yang sangat penting bagi perkembangan platform tersebut. Maka salah satu strategi yang disiapkan perusahaan agar user betah dengan platform tersebut adalah sistem rekomendasi mengenai sesuatu atau apa saja yang mungkin disukai oleh user. Disinilah Machine learning akan bekerja, dengan mengumpulkan data dari user, perusahaan harus mampu membuat suatu sitem rekomendasi yang mungkin akan disukai oleh pengguna.
Terdapat cukup banyak pendekatan yang bisa digunakan dalam sistem rekomendasi diantaranya Content-Based-Filtering, Collaborative-Filtering, Multi-criteria, risk aware, hybrid-filtering dan lainnya. Badal Soni et al [1] dengan RikoNet-nya menggabungkan pendekatan content-based dan collaborative filtering dalam sistem rekomendasi yang dibuatnya. Begitu juga Sistem rekomendasi yang dirancang oleh Ramashini et al[2] yang juga menggunakan kombinasi antara content-base dan collaborative filtering. Kumar et al[3] dengan MOV REC-nya mengajukan sistem rekomendasi dengan pendekatan collaborative filtering yang menggunakan informasi yang disediakan oleh penguna, lalu menganalisanya dan mebuat list rekomendasi yang cocok untuk para pengguna.
Dalam dunia bisnis user experience sangat berperan penting dalam perkembangan produk milik perusahaan. Sehingga dibutuhkan strategi yang tepat untuk membuat pengguna nyaman dengan plaform tersebut. Jadi sistem rekomendasi akan membuat user experience menjadi lebih baik karena pengguna bisa menemukan rekomendasi tontonan yang tepat, dalam hal ini adalah kartun jepang atau anime.
Berdasarkan latar belakang yang disebutkan diatas, permasalahan yang dapat diselesaikan pada proyek ini adalah
-
Bagaimana cara pengolahan data yang tepat untuk digunakan dalam merancang suatu model machine learning
-
Bagaimana cara merancang model machine learning untuk sistem rekomendasi kartun jepang.
Tujuan dari dibuatnya proyek ini adalah:
-
Melakukan data pre-processing yang baik yang akan digunakan dalam merancang model machine learning
-
Merancang model machine learning untuk membuat sistem rekomendasi kartun jepang.
Untuk mencapai tujuan dari proyek ini maka penulis menggunakan 2 algoritma, yaitu content base filtering dan collaborative filtering.
- Content-base filtering merupakan cara untuk memberikan rekomendasi berdasarkan genre atau item pada fitur yang diminati pengguna. Ide dari sistem rekomendasi berbasis konten (content-based filtering) adalah merekomendasikan item yang mirip dengan item yang disukai pengguna di masa lalu.
- Collaborative Filtering merupakan cara untuk memberi rekomendasi bedasarkan penilaian komunitas pengguna atau biasa disebut dengan rating.
Terdapat dua sumber dataset yang penulis gunakan yaitu dataset anime dan dataset rating
| jenis | Keterangan |
|---|---|
| Sumber | Dataset: Kaggle |
| Dataset Owner | Hernan Valdivieso |
| lisensi | CC0: Public Domain |
| Usability | 10.00 |
| Jenis dan ukuran berkas | ZIP(693Mb) |
| Jumlah file dataset | 6 file(5 csv, 1 folder) |
Berikut ini file yang terdapat pada dataset:
- html folder
- anime.csv
- anime_with_synopsis.csv
- animelist.csv
- rating_complete.csv
- watching_status.csv
Dataset yang akan digunakan hanya dataset anime.csv lalu selanjutnya dataset rating yang diambil dari sumber berbeda, dengan sumber sebelumnya, karena dataset dari hernan terlalu besar. Berikut dataset yang akan digunakan:
| Jenis | Keterangan |
|---|---|
| Sumber | Dataset: Kaggle |
| Dataset Owner | Marlesson |
| lisensi | CC0: Public Domain |
| Usability | 10.00 |
| Jenis dan ukuran berkas | ZIP(227Mb) |
| Jumlah file dataset | 3 file csv |
Berikut file yang ada pada dataset
- animes.csv
- profiles.csv
- reviews.csv
Dataset yang akan digunakan hanya reviews.csv untuk mendapatkan user_id untuk Collaborative learning.
anime.csv
jumlah data 17.562
- MAL_ID: Id anime
- Name: Judul Anime
- Score: Rata rating user
- Genres: Genre-genre dari anime
- English name: Judul dalam bahasa ingris
- Japanese name: Judul dalam bahasa jepang
- Type: Tipe data TV ataukah Movie
- Episodes': Jumlah episode
- Aired: tanggal tanyangnya
- Premiered: season premiere
- Producers: list produser
- Licensors: list Lisensi
- Studios: Studio yang menggarap
- Source: Sumber anime
- Duration: Durasi dari anime
- Rating: age rate (e.g. R - 17+ (violence & profanity))
- Ranked: Rangking berdasarkan score
- Popularity: rangking berdasarkan user yang menambahkan ke list tonton
- Members: Jumlah pemain dalam anime
- Favorites: Jumlah User yang menambahkan sebagai favorite
- Watching: Jumlah user yang menonton anime
- Completed: Jumlah user yang selesai menonton
- On-Hold: Jumlah user yang hold anime
- Dropped: Jumlah user yabg drop anime
- Plan to Watch': Jumlah user yang berencana menonton
- Score-10': jumlah user yang memberi rating 10
- Score-9': jumlah user yang memberi rating 9
- Score-8': jumlah user yang memberi rating 8
- Score-7': jumlah user yang memberi rating 7
- Score-6': jumlah user yang memberi rating 6
- Score-5': jumlah user yang memberi rating 5
- Score-4': jumlah user yang memberi rating 4
- Score-3': jumlah user yang memberi rating 3
- Score-2': jumlah user yang memberi rating 2
- Score-1': jumlah user yang memberi rating 1
reviews.csv
Jumlah data 192112
- uid : ID User
- profile : User profile
- anime_uid : ID Anime
- text : Text review
- score : Rating
- scores : Semua rating
- link : Link review
- Sebaran data
Sebaran data genre anime
 terdapat 47 data genre dan dari data diatas dan genre paling banyak adalah Comedy
terdapat 47 data genre dan dari data diatas dan genre paling banyak adalah Comedy

sebaran 10 Anime dengan rating tertinggi

Terlihat pada gambar diatas anime dengan rating tertinggi dipegang oleh Death Note
- Content-Based-filtering
- Menghapus missing value Pada tahapan ini Penulis memeriksa apakah ada data kosong atau missing value, karena missing value ini akan mempengaruhi keakuratan rekomendasi karena terdapat banyak data yang kosong dan setelah diperiksa tidak ada missing value pada dataset. Jadi penulis tidak perlu melakukan drop data.
- Menghapus Duplikasi data Selanjutnya memeriksa data duplikat. Data duplikat juga akan memperlama pemrosesan data karena itu data duplikat harus kita hapus.
- Collaborative filtering
- Menggabungkan data anime dan rating Karena pada algoritma collaborative filtering kita membutuhkan data rating atau score, user id, serta anime_id, penulis harus menggabungkan data anime dan rating..
- Menghapus missing value Selanjutnya penanganan missing value pada data dengan melakukan drop data. Setelah diperiksa tidak ada missing value pada data gabungan.
- Menghapus duplikasi data Setelah diperiksa terdapat data duplikat pada dataset gabungan yaitu sebanyak 61584, jadi data ini harus dihapus.
- Melakukan Normalisasi Nilai Rating Untuk menghasilkan rekomendasi yang sesuai dan akurat maka pada tahap ini diperlukan sebuah normalisasi pada data nilai rating dengan menggunakan formula MinMax pada data rating sebelum memasuki tahap modelling.
- Melakukan Splitting Dataset Untuk melatih model maka penulis perlu melakukan pembagian dataset latih dan juga dataset validasi. Data set latih sebesar 80% dari total keseluruhan jumlah data sedangkan dataset validasi sebesar 20% dari keseluruhan data. Hal ini diperlukan untuk pengembangan pada model Collaborative Filtering nantinya.
Model yang penulis gunakan adalah deep learning dan cosine similarity. Deep learning untuk sistem rekomendasi dengan algoritma Collaborative learning dan cosine similarity untuk Conten-based-learning.
-
Content Based Filtering Pada model ini langkah pertama yang dilakukan ialah melakukan ekstraksi fitur pada genre. Fungsi digunakan adalah TfidfVectorizer() dari library sklearn. Setelah data diekstraksi tahapan selanjutnya adalah melakukan fit dan transformasi ke dalam bentuk matriks, outputnya adalah berupa matriks 17562 x 47 yang merupakan representasi jumlah data anime dan jumlah genre anime.
Untuk menghitung derajat kesamaan (similarity degree) antar anime, penulis menggunakan teknik cosine similarity dengan fungsi cosine_similarity dari library sklearn. Cara kerja cosine similarity adalah dengan mengukur kesamaan antara dua vektor dan menentukan apakah kedua vektor tersebut menunjuk ke arah yang sama. Ia menghitung sudut cosinus antara dua vektor. Semakin kecil sudut cosinus, semakin besar nilai cosine similarity. Data yang digunakan adalah data matriks yang sudah penulis dapatkan sebelumnya. Berikut Formula dari cosine similarity:
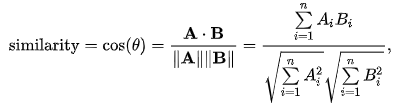 Langkah selanjutnya yaitu menggunakan argpartition untuk mengambil sejumlah nilai k tertinggi dari similarity data kemudian mengambil data dari bobot (tingkat kesamaan) tertinggi ke terendah. Kemudian menguji akurasi dari sistem rekomendasi ini untuk menemukan rekomendasi anime yang mirip dari anime yang ingin dicari.
Langkah selanjutnya yaitu menggunakan argpartition untuk mengambil sejumlah nilai k tertinggi dari similarity data kemudian mengambil data dari bobot (tingkat kesamaan) tertinggi ke terendah. Kemudian menguji akurasi dari sistem rekomendasi ini untuk menemukan rekomendasi anime yang mirip dari anime yang ingin dicari.-
Kelebihan
- Akurasi akan cukup bagus dengan banyaknya informasi yang diberikan pengguna.
-
Kekurangan
- Hanya dapat digunakan untuk fitur yang sesuai, seperti film, anime, buku, dan lain-lain.
- Tidak mampu menentukan profil dari user baru.
Berikut ini adalah konten yang dijadikan referensi untuk menentukan 10 rekomendasi anime tertinggi yang memiliki kesamaan genre yang sama:

Terlihat pada tabel diatas uji coba model akan dilakukan berdasarkan judul anime "Cowboy Bebop" dengan genre Action, Adventure, comedy, Drama, Sci-fi, dan Space.
Berikut ini adalah hasil rekomendasi tertinggi dari model Content Based Filtering berdasarkan referensi anime diatas:

-
-
Collaborative Filtering Pada Model ini data yang akan digunakan adalah data gabungan antara data anime dan data rating. User id dan anime_id akan diencode dan dimapping kedalam data dan data rating akan diubah menjadi float. Selanjutnya data akan displit menjadi data train dan data test sebesat 80% untuk data training dan 20% untuk data validasi.
Lalu penulis melakukan proses embedding terhadap data anime dan pengguna. Lalu lakukan operasi perkalian dot product antara embedding pengguna dan anime. Selain itu, penulis juga menambahkan bias untuk setiap pengguna dan anime. Skor kecocokan ditetapkan dalam skala [0,1] dengan fungsi aktivasi sigmoid. Untuk mendapatkan rekomendasi anime, data gabungan akan diacak terlebih dahulu dan mendefinisikan variabel movie_not_watched yang merupakan daftar anime yang belum pernah ditonton oleh pengguna. Berikut adalah kelebihan dan kekurangan dari algoritma collaborative filtering
- Kelebihan
- Tidak memerlukan atribut untuk setiap itemnya.
- Dapat membuat rekomendasi tanpa harus selalu menggunakan dataset yang lengkap.
- Unggul dari segi kecepatan dan skalabilitas.
- Rekomendasi akan tetap berjalan meski data sulit dianalisis
- Kekurangan
- Membutuhkan parameter rating, sehingga jika ada item baru sistem tidak akan merekomendasikan item tersebut.
Berikut ini adalah hasil rekomendasi anime tertinggi untuk user 10112:

- Kelebihan



Evaluasi yang akan penulis lakukan disini yaitu evaluasi dengan Mean Absolute Error (MAE) dan Root Mean Squared Error (RMSE) pada Collaborative Filtering dan Precision untuk Content Based Filtering
Pada evaluasi model ini penulis menggunakan metrik precision untuk menghitung keakuratan dari model yang telah dibuat sebelumnya.
Precision ini menghitung jumlah data relevan dibagi dengan jumlah item yang kita rekomendasikan.
rumus untuk precision adalah sebagai berikut

hasil dari tesnya adalah sebagai berikut:
 Data referensi kita yaitu Cowboy Bebop memiliki 6 genre yaitu Action, adventure, Comedy, Drama, Sci-fi, dan Space.
Lalu hasil rekomendasi yang relevan hanya 1 yang sama persis memiliki 6 genre yaitu anime dengan judul yang sama juga yaitu Cowboy Bebop: Yose Atsuma Blues. Akan tetapi terdapat 7 anime dengan genre yang sama sebanyak 5 genre, sehingga data ini juga relevan dengan anime referensi yang kita gunakan. Jadi Presisi sistem kita sebesar 8/10 atau 80%.
Data referensi kita yaitu Cowboy Bebop memiliki 6 genre yaitu Action, adventure, Comedy, Drama, Sci-fi, dan Space.
Lalu hasil rekomendasi yang relevan hanya 1 yang sama persis memiliki 6 genre yaitu anime dengan judul yang sama juga yaitu Cowboy Bebop: Yose Atsuma Blues. Akan tetapi terdapat 7 anime dengan genre yang sama sebanyak 5 genre, sehingga data ini juga relevan dengan anime referensi yang kita gunakan. Jadi Presisi sistem kita sebesar 8/10 atau 80%.
-
Mean Absolute Error (MAE) MAE mengukur berapa besar rata-rata kesalahan yang dilakukan oleh model yang sudah dilatih pada data tes, tampa mempertimbangkan arahnya. Semakin rendah nilai MAE maka akan semakin baik model yang sudah dirancang. Formula MAE:
Berikut hasil grafik MAE
 Berdasarkan fitting diatas nilai error model adalah dibawah 0.14, sedangkan nilai error untuk validasi diatas 0.200.
Berdasarkan fitting diatas nilai error model adalah dibawah 0.14, sedangkan nilai error untuk validasi diatas 0.200.
Nilai MAE yang baik seharusnya berada dibawah 0.1 atau 10%, jadi model bisa dikatan belum cukup baik
-
Root Mean Squared Error (RMSE) RMSE merupakan aturan penilaian kuadrat yang juga mengukur besarnya rata-rata error, semakin kecil errornya maka model semakin baik. Rumus RMSE adalah sebagai berikut:
 Berikut Grafik RMSE
Berikut Grafik RMSE
 Dari Grafik diatas dapat kita lihat bahwa niliai error RMSE adalah dibawah 0.17 pada data training, dan diatas 0.23 pada data tes.
Dari Grafik diatas dapat kita lihat bahwa niliai error RMSE adalah dibawah 0.17 pada data training, dan diatas 0.23 pada data tes.Nilai RMSE juga berada dibawah 10% skala data, jadi model bisa dikatakan belum cukup baik.




Nilai error dari hasil MAE dan RMSE mengalami overfitting pada data validasi, sehingga membuat score kualitas RMSE dan MAE kurang baik. Jadi pada collaborative learning model masih perlu pengembangan lebih banyak lagi, seperti menambahkan hyperparameter tuning untuk mengatasi overfitting pada data validasi. Namun karena keterbatasan waktu penulis belum bisa menambahkan hyperparameter tuning pada model tersebut.
Berdasarkan Tujuan dari proyek ini dan masalah yang dihadapi, yaitu pengolahan dari dataset yang penulis miliki dan evaluasi dari kedua model yang diajukan, dapat disimpulkan bahwa sistem rekomendasi sudah bisa berjalan, akan tetapi keakuratannya masih perlu ditingkatkan.