MongoDB Atlas Full-Text Search Demo
MongoDB Atlas Search makes it easy to build fast, relevant, full-text search capabilities on top of your data in the cloud. Available exclusively with MongoDB Atlas. Try MongoDB Atlas
This tutorial has been built based on another repo: https://github.com/esteininger/mongodb-full-text-search-app
In this tutorial we'll walk through to demonstrate the some capabilities of MongoDB Atlas Search.
This tutorial demonstrates the following capabilities of MongoDB Atlas Search:
-
Fuzzy Search
-
Highlighting
-
Different Language (arabic)
-
Used Operators
- text
- phrase
- autocomplete
- compound
- span
- phrase
- wildcard
- regex
- queryString
-
geoWithin
- near
-
Below operators have not been implemented in this tutorial, yet.
- equals
- exists
- geoShape
Prerequisites
This demo toolkit has been tested on the following environment successfully.
- Server: MongoDB Atlas Cluster v4.4.4
- Client:
- MacOS 11.2.2
- Python 3.9.2
- Flask 1.1.2
- Pymongo 3.11.3
- Dnspython 1.16.0
1) Loading the sample dataset into Atlas Cluster
Load the default MongoDB Atlas Sample Dataset into a MongoDB Atlas Cluster. Follow the tutorial on the link: https://docs.atlas.mongodb.com/sample-data/
2) Verification of the load
After the load is completed, please check the following collection that has the movie data.
sample_mflix.movies
Check example records and have a look at the following fields: title, fullplot, plot, cast, year, imdb.rating, runtime .
3) Creating Default Search Index
Choose the collection sample_mflix.movies and click the Search Indexes pane.
Create the search index with the following JSON:
{
"mappings": {
"dynamic": true
}
}Dynamic index
Make sure that the search index has been built, as shown in the below.

4) Testing the search index through Atlas UI - Aggregation Builder
Following queries can be executed with Aggregation Pipeline Builder in either MongoDB Compass or MongoDB Atlas User Interface.
Find the collection sample_mflix.movies and import the following aggregation query with the option New Pipeline from Text as shown in the below.

5) Executing Sample Queries
5.1) Executing a single word search in one particular field, fullplot
[
{
$search: {
index: "default",
text: {
query: "crime",
path: "fullplot",
}
}
}
]Output should look like as shown in the below.

5.2) Executing a single word (crime) search in another field (title)
[
{
$search: {
index: "default",
text: {
query: "crime",
path: "title",
}
}
}
]5.3) Executing a single word (crime) search in one single field (title) and limit the number of results to 3:
[
{
$search: {
index: "default",
text: {
query: "crime",
path: "title",
}
}
},
{
$limit : 3
}
]5.4) Executing a single word (crime) search in one single field (title) and limiting the number of results to 3 and bringing back only some of the fields (title,fullplot,plot) not all of them
[
{
$search: {
index: "default",
text: {
query: "crime",
path: "title",
}
}
},
{
$limit : 3
},
{
$project: {
"_id": 0,
"title": 1,
"fullplot": 1,
"plot":1
}
}
]5.5) On top of what Query 4 does, bring also the search score along with the results:
[
{
$search: {
index: "default",
text: {
query: "crime",
path: "title",
}
}
},
{
$limit : 3
},
{
$project: {
"_id": 0,
"title": 1,
"fullplot": 1,
"plot":1,
"score": { "$meta": "searchScore" }
}
}
]These are only a few initial examples of search. Let's go through with real-life application.
6) Configure Atlas connection for the Flask Application
Edit the file config.py in the root folder of the project with the full connection string of Atlas. Therefore, flask application can access the Atlas database.
7) Start the Flask App
$ python3 server.pyCheck the server started correctly:
fuat.sungur@Fuats-MacBook-Pro:~/projects/mongodb-atlas-fts
└─ $ ▶ python3 server.py
* Serving Flask app "server" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://localhost:5010/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 145-086-476Open the browser and access to the following url: http://localhost:5010/
8) Analyze the server.py
server.py starts the web server and renders the index.html file with the proper parameters when you access the page http://localhost:5010/
server.py initially has one HTTP GET endpoint, /search.
- This
/searchendpoint is called by frontend application (HTML/JAVASCRIPT). - This endpoint accepts the parameter
queryas HTTP GET request parameter and it is filled by user in the frontend. - When enduser clicks the search button, this
searchendpoint will get triggered. - Whenever endpoint is called, the necessary file will be opened, and the placeholder will be replaced by the query parameter. In production environment, it should not open a file for every HTTP call.
- Aggregation query with the
$searchstage is executed and results are sent back to the caller / frontend.
Whenever you make a change in the server.py file, you don't need to restart the server. Automatically, changes will be reflected.
9) First Atlas Search Query in Flask Application
- Check the content of the file
queries/query01.json. server.pyopens this file in the/searchendpoint (search()function ) and replaces the placeholder with the query parameters.- What does this query do?
- This search query, makes a single word search operation on the field
titleby using the search indexdefault.
- This search query, makes a single word search operation on the field
- Observation
- Search the words in the below and observe the results:
- "crime"
- "god"
- "battle"
- "hwayi"
- Search the words in the below and observe the results:
- You also check the "Developer Tools > Console" in the browser to see the returned data from backend:

10) Searching multiple words in one single field
10.1 - Observe
- Check the content of the file
queries/query02.json.
10.2 - Modify server.py file
-
Change the accessed filename in
server.pytoqueries/query02.json(line 18). And save the fileserver.py, it triggers flask server to reload the content automatically. -
What does this query do?
- This query almost same with the query
query01.json. The only difference is that, inquery02.jsonwe are targeting another field to search data.
- This query almost same with the query
10.3 - Test the changes
- Now, we also pass two different words to the search engine.
- Make a two search operation with the following inputs and observe the results
- "crime battle war"
- "battle war"
10.4 - Screenshot

10.5 - Interpretation of the results
The words we typed in the search field will be searched seperately in the field fullplot. Those words don't have to be exist completely. If one of the words matched then movie will be shown however score will be lesser than the movie which has all the words.
11) Searching one word in multiple fields (fullplot, plot)
11.1 - Observe
- Check the content of the file
queries/query03.json. - Observe the array field of
path. We do search on multiple fields now.
11.2 - Modify server.py file
- Change the accessed filename in
server.pytoqueries/query03.json. And save the fileserver.py, it triggers servers to reload the files automatically.
11.3 - Test the changes
- Make a search with the following parameter, it will search for the given word only on two fields (fullplot, plot)
- "immigrant"
12) Searching one word in any field
12.1 - �Observe
- Check the content of the file
queries/query04.json. - Observe the
wildcardoption. - It executes search on any proper fields
12.2 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query04.json. And save the fileserver.py, it triggers servers to reload the files automatically.
12.3 - Test the changes
- Make search operation with the following words
- "immigrant"
13) Searching one word in any field that ends with 'plot'
13.1 - Observe
- Check the content of the file
queries/query05.json. - Observe the
wildcardoption with the parameter*plot - It will allow search operation to be done on any proper fields that ends with
plot. For the collectionsample_mflix.moviesit is going to befullplotandplotfields.
13.2 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query05.json. And save the fileserver.py, it triggers servers to reload the files automatically.
13.3 - Test the changes
- Make two search operations with the following words
- "police"
- "fire"
14) Phrase Search
14.1 - Scenario Definition
- Let's try to bring movies related to "Jimmie Shannon".
14.2 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query02.json. It will execute search operations in the fieldfullplot. Save theserver.py.
14.3 - Test the changes
- Come back to browser and put the words in the text field, "Jimmie Shannon".
- The problem here is that, search engine brings the data which even doesn't have the word "Jimmie". Please have a look at the browser and use the browser search (find) function to search the words in the browser separately "Jimmie" and "Shannon . There are some records other than the first one, even they didn't have the word "Jimmie" , those records were listed because those only includes "Shannon".

But our intention was to search two words ("Jimmie" and "Shannon") together. We can use phrase operator to achieve this.
Let's fix the problem.
14.4 - Observe
- Check the content of the file
queries/query06.json. - Observe the
phraseoption.
14.5 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query06.json. And save the fileserver.py, it triggers servers to reload the files automatically.
14.6 - Test the changes
- Do the following search again: "Jimmie Shannon", and you'll see only one record now.

- Do another search: "al pacino" and observe the results.
- The words "al pacino" should exist together in any field and they have to be matched exactly as query, since the parameter
slopis0in thephraseoperator. - Search in the browser the words "al pacino" together, every record on the screen should have these words together.
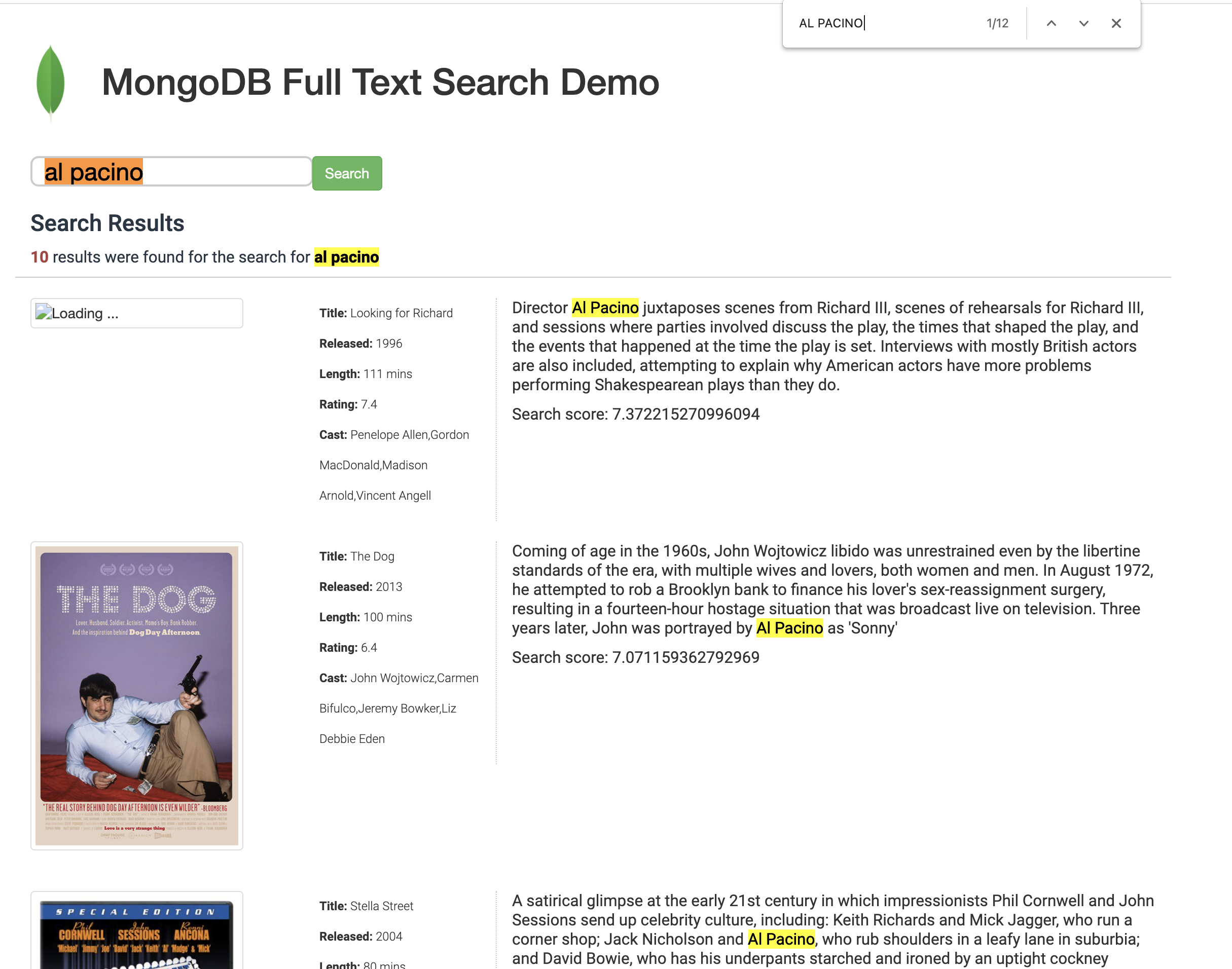
- The words "al pacino" should exist together in any field and they have to be matched exactly as query, since the parameter

15) �Different Slop Value in Phrase Search
15.1 - Test a query
- Let's make a search with the words "man woman" with the same search query
query06.jsonas Step 14. - It will return a few records and the words "man woman" should be next to each other and should be matched exactly as query.
- Search in the browser the words "man woman" , the results will be as shown in the below, only 3 records will be matched.
- 2nd record is matched because between the words "man" and "woman" there is
,(comma) and default analyzer already discards it.
- 2nd record is matched because between the words "man" and "woman" there is

15.2 - What we want to achieve
- How we can modify our query to be tolerant in the existence of some words between the words "man" and "woman".
- It can be done with
slopparameter.
15.3 - Observe
- Check the content of the file
queries/query07.json. - Observe the
phraseoption with theslopparameter.
15.4 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query07.json. And save the fileserver.py, it triggers servers to reload the files automatically.
15.5 - Test the changes
- Make the following search again: "man woman"
- You'll see 15 records, it was 4 before.
- Search in the browser, e.g. "man and woman" and you'll see that it matches with many records
- Search in the browser, e.g. "man or woman" and you'll see that it matches with many records
- Search in the browser, the words "man" and "woman" separately

15.6 - Another test
- Change the
slopvalue to 2 and try it again. You will see more matched results.
16) Fuzzy Search
16.1 - Observe
- Check the content of the file
queries/query08.json.
16.2 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query08.json. And save the fileserver.py, it triggers servers to reload the files automatically.
16.3 - Test
- Let's assume that we made a typo error and a search with the following words exactly: "nrw yprk", instead of "new york"
- There will be no match
16.4 - What we want to achieve
Let's fix the problem.
We want our search engine to be tolerant with certain limits, in the case if we made typo error
16.5 - Observe
- Check the content of the file
queries/query09.json.- Observe the
fuzzyoperator with themaxEditsandmaxExpansionsparameters.
- Observe the
16.6 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query09.json. And save the fileserver.py, it triggers servers to reload the files automatically.
16.7 - Test the changes
- Observation
- Do the same search again: "nrw yprk".
- What does query do? Every single word in the search can have maximum one character change (
maxEdits) and it is evaluated under certain number of possibilities (maxExpansions).
- It will now return the relevant records as shown in the below.

16.8 - Another tests
- Extra
- Do another search: "goodfather". It should match with 4 results. In order to match exact movie "godfather", there has to be only one character removal therefore search engine brings the movies related to "Godfather"
- But, what if we write "foodfather"? There will be no match. In order to allow 2 character change, change the parameter
maxEditsfrom1to2. And search again. Results should look like below:

17) Auto Complete
We'd like to help our customers to find the movies quickly even they don't know the exact spelling.
Firstly, our frontend should support proper rendering as long as we type the characters. Therefore we need to use proper HTML/CSS/Javascript combination. Luckily, it's already been embedded in index.html , therefore you don't need to have big changes. Only a few changes we'll do in index.html
17.1 - Creating AutoComplete Index on the field title in the sample_mflix.movies collection
Create the autocomplete search index on the field title in the collection sample_mflix.movies with the following configuration:
{
"mappings": {
"dynamic": false,
"fields": {
"title": [
{
"type": "autocomplete",
"tokenization": "edgeGram",
"minGrams": 3,
"maxGrams": 7,
"foldDiacritics": false
}
]
}
}
}
17.1 - Locate the TypeAhead CSS Section in templates/index.html
There is one CSS library TypeAhead which allows to render an HTML section as you type.
Please locate the following block in the index.html file.
$('#custom-search-input .typeahead').typeahead({
hint: true,
highlight: true,
minLength: 3
},
{
source: function () {}
});When you type something and the length of the word is at least 3 (minLength) , the function in the source parameter is called. Since there is an empty function, nothing has happened so far.
17.2 Action: Change the source function to findMovieTitles(). And refresh the HTML page. Therefore this section will look like as shown in the below:
$('#custom-search-input .typeahead').typeahead({
hint: true,
highlight: true,
minLength: 3
},
{
source: findMovieTitles()
});Don't forget to refresh HTML page.
17.3 - Understand the Javascript function findMovieTitles()
In the index.html file, locate the javascript function findMovieTitles(). This function makes an HTTP GET call to the backend endpoint /autocomplete with the given parameter. We will analyze this backend endpoint later. As you type some characters and if the length of the characters is 3 or more, then this backend endpoint is called.
No need to change anything here.
17.4 - Understand the Backend Function autocomplete()
In the server.py, locate the endpoint /autocomplete. Whenever user types 3 or more characters, this backend is called and the search aggregation query is executed.
- Observe the following parameters.
- We didn't use
defaultsearch index, rather we create dedicated search index forautocompleteoperation in Step 17.1. - This autocomplete index a bit customized for
autocompleteoperation. Check the parametersminGramsandmaxGrams.- We specify the index name in the
indexfield. e.g."index" : "title_autocomplete"
- We specify the index name in the
- We use the operator
autocompleterather thantextorphrase. - We can even specify the
pathandfuzzyoption forautocomplete.fuzzyoption is similar as we did before in Step 16.
- We didn't use
17.5 - Test the changes
Please make sure you've already changed the index.html (for triggering the necessary JS function as you type) and refresh the page.
Observation:
- Write "scar" into the search field and wait. It will populate 5 records just under the text field as shown in the below.

For more details about the autocomplete operator, please check this link.
18) Highlighting the Title
18.1 - What do we need
We'd like to make a search on any field, however we'd like terms to be more visible if the term appears in the title field. For this purpose, we can use highlight operator that lets search engine to calculate which words are going to be highlighted. Our aggregation query results will include one more array field highlights and in frontend we can consume this data.
18.1 - How it works
- Check the content of the file
queries/query10.jsonand observe the parameterstextandhighlightin the$searchstage. While we let search engine to search the words in any field in the default index, we inform that we want to get highlighted data on thetitlefield. After this query gets executed, it will populate one more array fieldhighlightsin the return document, which includes the words which needs to be highlighted. An example is in the below:

We searched the term "Godfather" in any field, and we spesified that if the searched term appears in the title field it should be highlighted. Now, we have highlights array field for the movies where title field includes the matched term and this highlights array field has array field texts and this array field has elements.
- If the term inside the collection matches with the searchted term (e.g. Godfather) then the value of the field
typeis going to behitand we can consume this data in the frontend.
18.2 - Locate where the title field is rendered in frontend
Open the index.html and look for the following html section:
<li>Title: <span>${doc.title}</span></li>This function is under render() javascript function and basically it is rendering the title information as it renders the other fields, without any extra CSS options.
But, we'd like to make it more visible. So, we've already added following CSS block in the index.html page:
.highlight {
background-color: #a94442;
color: white;
padding-left: 5px;
padding-right: 5px;
}We'll use this CSS block to highlight relevant data.
Locate the javascript function function highlightTitle(highlights_arr, title). This function gets two paremeters, highlights_arr and title. We will execute this javascript function for every record which returned from search engine. If there is an array field highlights returned from the search engine, and if this highlighted term is for the field title then, we will add CSS class highlight while rendering title information as shown in the below:
<span class="highlight"><b>${item.value}</b></span>If there is not highlights array field, we will render as we render other field.
18.3 - Action: We have to change how title field is rendered
Open the index.html and look for the following html section:
<li>Title: <span>${doc.title}</span></li>Change that line with the following:
${highlightTitle(doc.highlights, doc.title)}Refresh the HTML page in the browser.
18.4 - Modify the server.py file
Open the server.py and update the query file location to queries/query10.json.
18.5 - Test the changes
- Make a search with the following word: "godfather"
- Make a search with the following word: "goodfather" . Since
fuzzysearch is also enabled, you can still see the results.
You should see the results as shown in the below:

19) Highlighting the Fullplot
We've already highlighted the field title. Let's do it for fullplot field as well.
We've already have a javascript function for rendering fullplot field.
19.1 - Action: Change rendering javascript function of fullplot field
Locate the following section in the index.html page.
<p>${doc.fullplot}</p>Change it to the following:
<p>${highlightFullplot(doc.highlights, doc.fullplot)}</p>19.2 - Observe
- Check the content of the file
queries/query11.json. - Observe the
highlightoperator, now it is going to be highlighted bothtitleandfullplotfields.
19.2 - Modify the server.py file
- We'll change the backend aggregation query to highlight both
titleandfullplotfield - Change the accessed filename in
server.pytoqueries/query11.json. And save the fileserver.py, it triggers servers to reload the files automatically.
19.3 - Test
Make a search with the word "Godfather" again. Now, you'll see that fullplot field is also highlighted as title field.

For more details about highlighting, visit this link https://docs.atlas.mongodb.com/reference/atlas-search/highlighting/.
20) Compound Queries
The compound operator allows to combine multiple operators into one single query.
20.1 - Scenario
Our scenario is searching on different words/phrases on multiple fields. We want to search for the word "crime" in any field and it must match. On top of that, we would like to search on other fields as well. At least one of the filters in the below should match:
- Search the word "kill" in the
titlefield - Search the word "detective" in the
fullplotfield - Search the word "ruthless" in the
plotfield - Search the word "Donnie Yen" in the
castfield
We can merge this kind of multiple different queries into one single query with the compound operator.
20.2 - Observe the query
- Check the content of the file
queries/query12.json
20.3 - Observe the backend
- Check the backend endpoint
/searchCompoundin theserver.pyfile. It consumes multiple parameters and replaces the placeholder in the filequery12.json.
20.4 - Observe the frontend
- Check the
templates/compound.htmlfile. We have now multiple text fields then user can accordingly fill out the form with relevant inputs. When user makes a search, all the inputs of the 5 text fields will be passed to the backend endpoint/searchCompoundand it will executecompoundsearch query.
20.5 - Test this
- Open the web page: http://{serverhost:port}/compound
- Fill out the forms with the below input:
- Search in all fields: "crime"
- Search in
title: "kill" - Search in
fullplot: "detective" - Search in
plot: "ruthless" - Search in
cast: "Donnie Yen" - Hit the
Searchbutton
You should see the movie "SPL: Kill Zone" as first, because it matches "crime" and it matches more than one clause in the should section of the $search query. The given words don't have to match with the fields title, fullplot, plot. cast but one of them should match. If it matches more than one field, score will be higher.

21) Score Boosting
21.1 - Observe
- Check the content of the file
queries/query13.json. - Observe the query.
21.2 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query13.json. And save the fileserver.py, it triggers servers to reload the files automatically. - Open the browser and visit the page http://{serverhost:serverport}/
- Make a search with the word : "godfather"
Interpretation of the results: The problem here is that, our intention was to search the movie 'The Godfather' or 'Godfather' and we were expecting this movies should be listed in the top. However, in the top, you see another movie, "C(r)ook" and it has the word "Godfather" in the fullplot field.
21.3 - What we want to do
How we can customize our search that if the word appears in the field title it should have much higher score than the records those have the word in another fields?
We can use score boosting.
21.4 - Observe
- Check the content of the file
queries/query14.json - Observe the
compoundoperator and check thescoreparameters. - If the term appears in the field
titlewe boost the score of that record by15. If the term appears in the fieldplotthen we boost the score of that record by3and so on. And there is another parameterminimumShouldMatchwhich forces one of the fields (title,plot,fullplot) should have the searched term.
21.5 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query14.json. And save the fileserver.py, it triggers servers to reload the files automatically.
21.6 - Test the changes
- Open the browser and visit the page: http://{serverhost:serverport}/
- Search the term: "Godfather"
Now you'll see the movies in the top if they have the word "Godfather" in the title field.

22) Loading the Arabic dataset into Atlas Cluster
Load the Arabic poem dataset through the mongoimport utility. Don't forget to change connection string of the database.
$ cd data
$ unzip arabic_poem.json.zip
$ mongoimport --uri mongodb+srv://main_user:*******@fuattest2.5tka5.mongodb.net/arabic --collection poem --file arabic_poem.json --drop22.1 - Verification of the Arabic dataset
After the Arabic dataset is loaded, please check the following collection: arabic.poem
You should be able to see Arabic characters as shown in the below:

22.2 - Create a search index in Arabic language
Create a search index with the name arabic_text_title on the fields poem_text and poem_title for the collection arabic.poem
{
"analyzer": "lucene.arabic",
"searchAnalyzer": "lucene.arabic",
"mappings": {
"dynamic": false,
"fields": {
"poem_text": {
"analyzer": "lucene.arabic",
"searchAnalyzer": "lucene.arabic",
"type": "string"
},
"poem_title": {
"analyzer": "lucene.arabic",
"searchAnalyzer": "lucene.arabic",
"type": "string"
}
}
}
}
22.3: Test
Open the Aggregation Builder in either MongoDB Compass or Atlas UI and import the following query:
[
{
$search: {
index: "arabic_text_title",
text: {
query: "الأرض",
path: { "wildcard" : "*"}
}
}
},
{
$limit : 3
},
{
$project: {
_id: 0,
poem_title: 1,
poem_text: 1,
score: {
$meta: 'searchScore'
}
}
}
]
23) Span Operator
We can use span operator to search words in a specific location of the document.
23.1 - Observe
- Check the content of the file
queries/query15.json. - Observe the query. Look at the operator
spanand parameterendPositionLte.
23.2 - Modify the server.py file
- Change the accessed filename in
server.pytoqueries/query15.json. And save the fileserver.py, it triggers servers to reload the files automatically.
23.1 - Test the changes
- Open the main page
- Make a search on the word:
- "american"
- Interpretation of the results: It will show the movies where title of the movie starts with the word
american 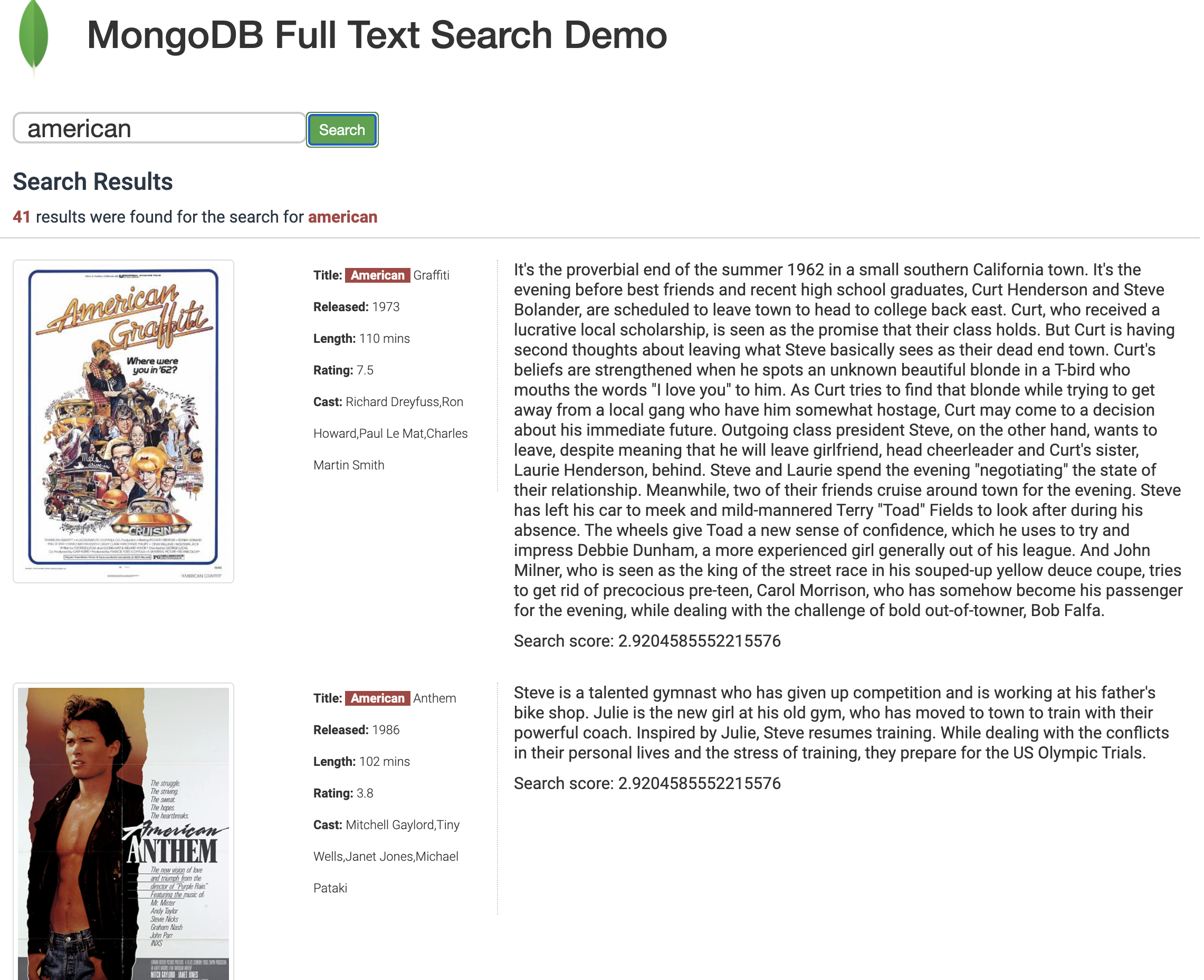
- Interpretation of the results: It will show the movies where title of the movie starts with the word
- "player"
- Interpretation of the results: There will be no results because there is not any movie where
titleof the movie starts with the wordplayer
- Interpretation of the results: There will be no results because there is not any movie where
- "american"

23.2 - Changing the endPositionLte parameter to 2
Change the parameter endPositionLte from 1 to 2 in the file queries/query15.json.
- Make a search for the word "player" again
- Interpretation of the results: There will be 1 result because we let search engine to bring the movies where
titlefield matches the word "player" either 1st or 2nd term in thetitlefield
- Interpretation of the results: There will be 1 result because we let search engine to bring the movies where
23.3 - Changing the endPositionLte parameter to 3
Change the parameter endPositionLte from 2 to 3 in the file queries/query15.json.
- Make a search for the word "player" again
- Interpretation of the results: There will be 2 results because we let search engine to bring the movies where
titlefield matches the word "player" with 1st or 2nd or 3rd term in thetitlefield 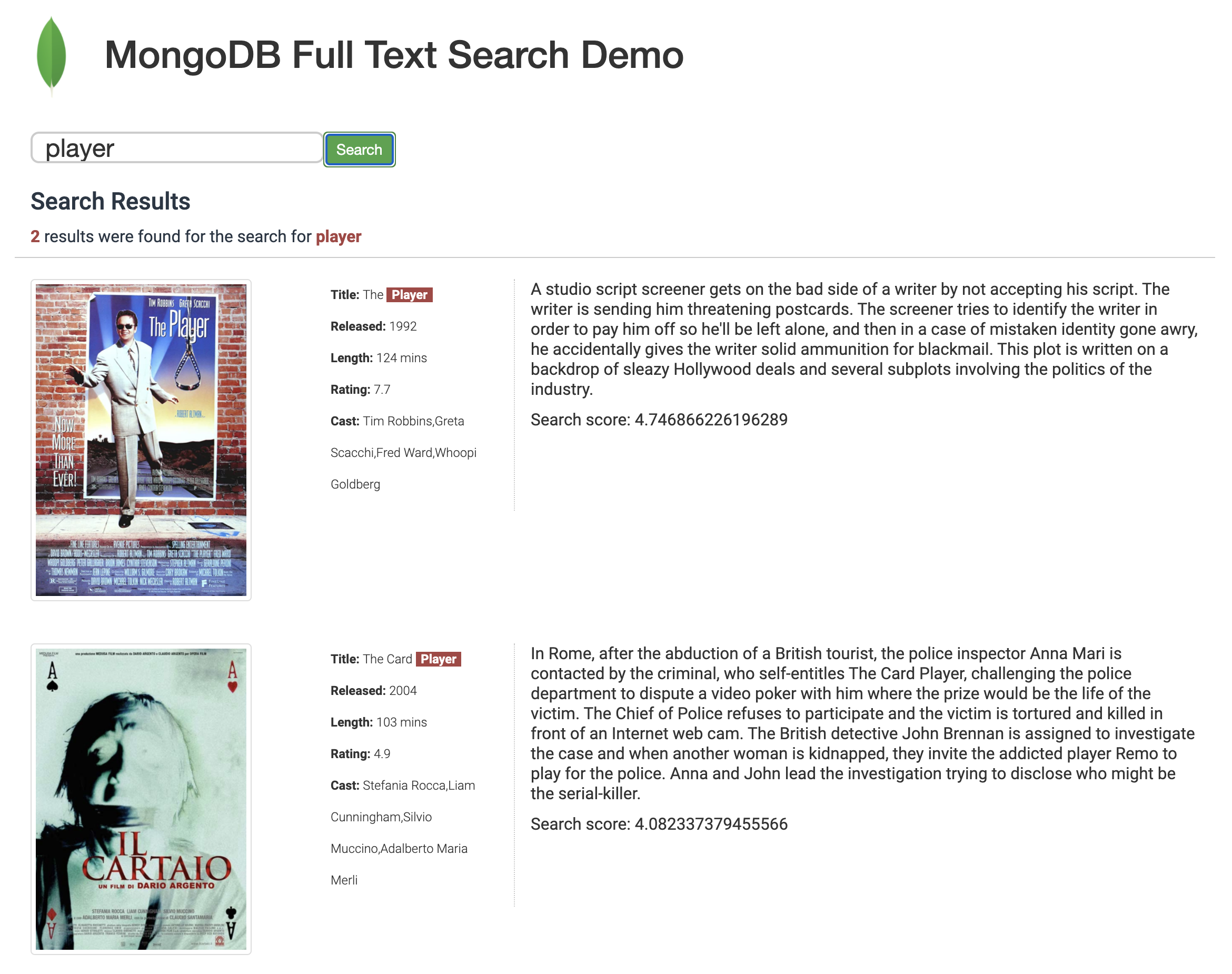
- Interpretation of the results: There will be 2 results because we let search engine to bring the movies where

24) Wildcard Search in the title field
We'd like to execute wildcard search on the title and/or fullplot fields.
24.1 - Create Keyword Analyzer Index
Wildcard operation like regex works well with not the analyzed fields with the Standard or similar analyzer. Therefore, we use Keyword Analyzer to index data exactly what shape it is already.
Create a new search index with the name "keyword_title_fullplot" and below mappings:
{
"mappings": {
"fields": {
"title": {
"analyzer": "lucene.keyword",
"type": "string"
},
"fullplot": {
"analyzer": "lucene.keyword",
"type": "string"
}
}
}
}24.2 - Observe
- Check the content of the file
queries/query16.json. - Observe the
wildcardoperator.
24.3 - Modify the server.py file
Change the accessed filename in server.py to queries/query16.json. And save the file server.py, it triggers servers to reload the files automatically.
24.4 - Test the changes
Open the search page and search with the following clause to retrieve the movies where title starts with the letters "Ca" , follows with any character ("?") , follows with the letter "e" , and follows with any character set with any length. For example, "Cafe", "Careless", "Cage" should be matched.
Notice the search score, it is all 1 for every record.
- Ca?e*

25) Wildcard Search in the title and fullplot field
If you haven't created the search index with Keyword Analyzer in Step 24, you should create it.
25.1 - Observe
- Check the content of the file
queries/query17.json. - Observe the
wildcardoperator andpathparameter.
25.2 - Modify the server.py file
Change the accessed filename in server.py to queries/query17.json. And save the file server.py, it triggers servers to reload the files automatically.
25.3 - Test the changes
Search with the followings :
- exp?nsive
It will bring the movies where title or fullplot matches the wildcard option above, e.g. "expensive", "expansive". Search in the browser to find out these words.
Notice that not individual words are highlighted, entire field is highlighted since the words are not analyzed.

26) Regex Search in the title field
In order to apply regular expression based search, we can use Keyword Analyzed index, as we used in Step 24 and Step 25.
26.1 - Observe
- Check the content of the file
queries/query18.json. - Observe the
regexoperator andpathparameter.
26.2 - Modify the server.py file
Change the accessed filename in server.py to queries/query18.json. And save the file server.py, it triggers servers to reload the files automatically.
26.3 - Test the changes
Search with the following clause:
- (.*) Italy|(.*) London|(.*) Germany
- It will search the movie titles where it ends with one of the country names given above

26.4 - Another Test
- Look for the movie titles it starts with anything and with the following 2 digits sequentially with the numbers between 0-4 and then ends with anything
- (.*) [0-4]{2} (.*)

26.5 - Another Test
- Look for the movie titles which starts with anything and with the following 4 digits sequentially and then ends with anything
- (.*) [0-9]{4} (.*)

26.6 - Another Test
- Look for the movie titles it starts with "The L", and then
- any number of characters, and then
- 2 digits sequentially between 0 and 4, and then
- any number of characters, and then
- either uppercase H or lowercase h, and then
- any number of characters, and then
- sequential two "o" characters, and then
- any number of characters, and finally
- "a" as last letter
- The L(.*)[0-4]{2}(.*)(H|h)(.*)(o{2})(.*)a

27) Querystring
We'd like to build a search query with multiple conditions on multiple indexed fields.
27.1 - Observe
- Check the content of the file
queries/query19.json. - Observe the
regexoperator andpathparameter.
27.2 - Modify the server.py file
Change the accessed filename in server.py to queries/query19.json. And save the file server.py, it triggers servers to reload the files automatically.
27.3 - Test the changes
Search with the following clause:
- (title: Italian OR fullplot: dream) AND cast: Clara
- It will search the movies where
titlehas the word "Italian" OR the fieldfullplothas the word "dream" ANDcastarray field should have the value "Clara" - See the output as shown in the below.
- It will search the movies where

27) GeoSpatial Queries
In this demo, we're using Mapbox API to visualize map information. If you'd like to test the GeoSpatial capabilities of Atlas Search in this demo toolkit, you'll need to obtain an access token. For more information, please check this: https://docs.mapbox.com/help/getting-started/access-tokens/.
After you've got the token, please set the token value to the variable accessTokenMapBox in the templates/static/maphelper.js file, in the 1st line.
var accessTokenMapBox = 'pk.*****************uSA'27.1 - Creating the Geospatial Search Index
We'll have a new search index in different collection, sample_airbnb.listingsAndReviews on the field address.location.
In order to execute GeoSpatial queries in Atlas Search, we need to have specify the fields for Geo objects while creating index.

{
"mappings": {
"fields": {
"address": {
"fields": {
"location": {
"type": "geo"
}
},
"type": "document"
}
}
}
}Verification of index creation:

27.2 - Search Properties in a Circle Object
27.2.1 - Scenario
- We'd like to find the properties in a radius of 1000 meters of the specified location
27.2.2 - Observe
- Open the file
queries/query30.jsonand observe the fieldgeoWithin,circle,center,radiusfields under$search
27.2.3 - Backend
- Open the file
server.py - Find the function
geo_within() - Analyze the
ifblock starts with:if ( query_parameter_shape == "circle" ):
- Frontend sends the following parameter:
- radius
- Latitude and longtitude of the center
- Then backend executes the
$searchaggregation query.
27.2.4 - Test
-
Open the browser and access to the following url:
http://localhost:5010/geoWithin -
Zoom-in enough to the city Barcelona to reach below level:

- Put the marker with one click on an area as shown in the below:

- Specify the radius as 5000 as shown in the below. As long as you change the radius parameter, the shape will be redrawn.

- Hit the
Searchbutton - And, 10 records within the Circle will be retrieved from the search index and the
locationof the propery (address.location.coordinatesin the document) will be drawn on the map. - On top of that,
streetandnameinformation (respectively in theaddress.streetandnamefields in the record) will be shown as you click on the marker.

- Click the
Clearbutton and do a search on another location with different radius parameter.
27.3 - Search Properties in a Box Object
27.3.1 - Scenario
- We'd like to find properties in a box (rectangle, square) shape.
27.2.2 - Observe
- Open the file
queries/query31.jsonand observe the fieldgeoWithin,box,bottomLeft,topRightfields under$search
27.2.3 - Backend
- Open the file
server.py - Find the function
geo_within() - Analyze the
ifblock starts with:if ( query_parameter_shape == "box" ):
- Frontend sends the following parameter:
- Latitude and longtitude of the bottom left point
- Latitude and longtitude of the bottom top right
- Then backend executes the
$searchaggregation query. - Bottom left point must located in lower location of the top right point (Atlas search requirement)
27.2.4 - Test
- Open the browser and access to the following url:
http://localhost:5010/geoWithin - In the top dropdown menu choose
Boxrather thanCircle - Automatically Box related settings will be shown as shown in the below.

- Zoom in enough to the center of the city Barcelona.
- Find a location to position
Bottom Leftpoint and click on the map. - Then find another location to position
Top Rightpoint and click on the map. Box shape will be automatically drawn (just after second marker). Don't forget,Top Rightposition must be position than theBottom Left.

- Hit the
Searchbutton - And, 10 records within the Box will be retrieved from the search index and the
locationof the propery (address.location.coordinatesin the document) will be drawn on the map. - On top of that,
streetandnameinformation (respectively in theaddress.streetandnamefields in the record) will be shown as you click on the marker.

- Click the
Clearbutton and do a search on another locations.
27.4 - Search Properties in a Polygon Object
27.4.1 - Scenario
- We'd like to find properties in a polygon shape.
27.4.2 - Observe
- Open the file
queries/query32.jsonand observe the fieldgeoWithinfield under$search
27.4.3 - Backend
- Open the file
server.py - Find the function
geo_within() - Analyze the
ifblock starts with:elif ( query_parameter_shape in ["polygon","multipolygon"] ):
- Frontend sends the following parameter:
- Latitude and longtitude of multiple points which forms the polygon shape
- If there are 2 polygons then frontend sends all the points of 2 polygons
- Then backend executes the
$searchaggregation query.
27.4.4 - Test
- Open the browser and access to the following url:
http://localhost:5010/geoWithin - In the top dropdown menu choose
Polygonrather thanCircle - Automatically Polygon related settings will be shown as shown in the below.

- Zoom in enough to the center of the city Barcelona.
- Start to add points by clicking on the map. If you mistakenly add a point, then hit the
Clearbutton to start over. - After you add the 3rd point, the polygon will be drawn automatically. You can add more points.
- After you add some points, you will end up a polygon as shown in the below.

- Hit the
Searchbutton. - And, 20 records within the shape will be retrieved from the search index and the
locationof the propery (address.location.coordinatesin the document) will be drawn on the map. - On top of that,
streetandnameinformation (respectively in theaddress.streetandnamefields in the record) will be shown as you click on the marker.

- Click the
Clearbutton and do a search on another locations.
27.5 - Search Properties in Multi Polygon Object
- First, please review the section 27.4.
27.5.1 - Test
- Open the browser and access to the following url:
http://localhost:5010/geoWithin - In the top dropdown menu choose Polygon rather than
Circle - Automatically Polygon related settings will be shown as shown in the below.
- Zoom in enough to the center of the city Barcelona.
- Start to add points by clicking on the map. If you mistakenly add a point, then hit the
Clearbutton to start over. - After you add the 3rd point, the polygon will be drawn automatically.
- After you add some points, you will end up a polygon as shown in the below.

- Hit the
Switch to New Polygonbutton. - Start to add points by clicking on the map and it will add points for the second polygon.
- After you add some points, you will end up two polygons as shown in the below.
- This demo toolkit only supports 2 polygons as Multi-Polygon.

- Hit the
Searchbutton.- And the points in these 2 polygons up to total 20 records will be retrieved as shown in the below.

28) GeoSpatial and Compound
28.1 - Scenario
We'd like to find the properties around a point where the type of the property (property_type field in the document) should be "apartment" with up to 1 character mistake (fuzzy), and the description (description field in the document) might include the following words "duplex air conditioner kitchen public transportation".
We'd like to boost the records if it is close to the point which we specified.
28.2 - Index Creation
We'll create an index where has Geolocation field ( address.location ) indexed and the other fields property_type and description indexed as shown in the below.

{
"mappings": {
"fields": {
"address": {
"fields": {
"location": {
"type": "geo"
}
},
"type": "document"
},
"description": {
"type": "string"
},
"property_type": {
"type": "string"
}
}
}
}Verification of index creation:

28.3 - Observe
- Open the file
queries/query34.jsonand observe the fieldcompound,should,must,nearfield under$search
27.4.3 - Backend
- Open the file
server.py - Find the function
geo_near() - Frontend sends the following parameter:
- Latitude and longtitude of the center point
- Pivot parameter
- Property type
- Description Keyword
- Then backend executes the
$searchaggregation query.
27.4.4 - Test
- Open the browser and access to the following url:
http://localhost:5010/geoNear - Find the center of the city Barcelona and click on the map, it will drop a marker on the map.
- You should see the below screen.

-
Then fill out the form with the following parameters:
- Pivot value: 10000
- Property type: "aparment" (we'll test fuzzy too)
- Keyword (Description) : "duplex air conditioner kitchen public transportation"
-
And then hit the
Searchbutton and you'll see the below screen.

As you click on a marker, in just below of the map, you'll see the description of the property (description field in the document).