Note
This project is moved to https://github.com/egorsmkv/asr-cc
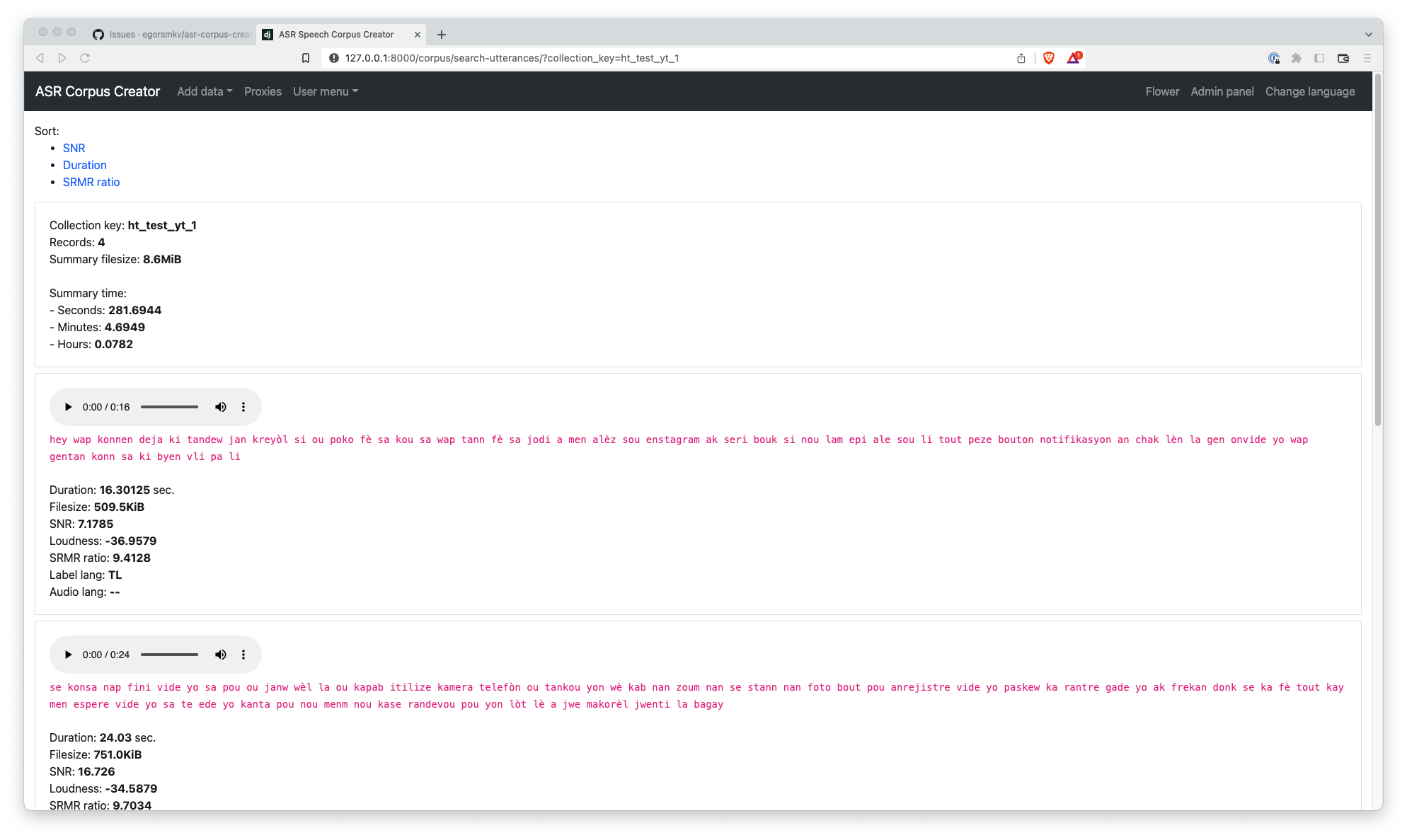
This app is intended to automatically create a corpus for ASR systems using pseudo-labeling.
- Send links of YouTube content or even an entire channel
- Send direct links to video/audio from remote servers
- Send local folders
- Collect metadata
- Loudness
- Label language detection
- Audio language detection
- SRMR ratio (measure reverberation)
- Audio type (Speech, Music, etc)
- Export labeled data using a console
whisper,wav2vec2, orNeMoas an ASR backend
- Rust compiler
- CMake
- Protobuf compiler
- Docker
- wget
- youtube-dl or yt-dlp
- ffmpeg
- Python >= 3.6
git clone https://github.com/egorsmkv/asr-corpus-creator
cd asr-corpus-creatorInstall grpcio like the following:
pip install https://github.com/pietrodn/grpcio-mac-arm-build/releases/download/1.50.0/grpcio-1.50.0-cp310-cp310-macosx_11_0_arm64.whlNOTE: Visit https://github.com/pietrodn/grpcio-mac-arm-build repository's releases to see different wheels for your Python version.
# install pipenv if you do not use it already
pip install pipenv
# activate virtual environment
pipenv shell
# install Cython first
pip install Cython==0.29.32
# install dependencies
pipenv install
# or install dependencies with ability to see the installation process
pip install Django==4.1.3 django-bootstrap4==22.2 celery==5.2.7 redis==4.3.3 librosa==0.9.1 torch==1.13.0 torchaudio==0.13.0 pyzmq==23.1.0 transformers==4.20.1 loguru==0.6.0 psutil==5.9.1 pyctcdecode==0.3.0 'nemo-toolkit[asr]==1.12.0' git+https://github.com/openai/whisper.git lingua-language-detector==1.1.3 git+https://github.com/csteinmetz1/pyloudnormpython source/manage.py migratepython source/manage.py createsuperuserpython source/manage.py runserverAfter starting the WebUI, open http://127.0.0.1:8000/ in your browser and log in with credentials you have created on the previous step.
Run Redis broker via docker:
docker run -d -p 6390:6379 redisRun the worker (with youtube-dl):
cd source
HF_TOKEN=xxxx WGET_PATH=/opt/homebrew/bin/wget YOUTUBE_DL=/opt/homebrew/bin/youtube-dl FFMPEG_PATH=/Users/yehorsmoliakov/opt/miniconda3/bin/ffmpeg celery -A app worker -l INFO --concurrency 1Run the worker (with yt-dlp):
cd source
HF_TOKEN=xxxx WGET_PATH=/opt/homebrew/bin/wget YT_DLP=/opt/homebrew/bin/yt-dlp FFMPEG_PATH=/Users/yehorsmoliakov/opt/miniconda3/bin/ffmpeg celery -A app worker -l INFO --concurrency 1Run the worker with audio language detection:
cd source
HF_TOKEN=xxxx DETECT_AUDIO_LANG=yes WGET_PATH=/opt/homebrew/bin/wget YOUTUBE_DL=/opt/homebrew/bin/youtube-dl FFMPEG_PATH=/Users/yehorsmoliakov/opt/miniconda3/bin/ffmpeg celery -A app worker -l INFO --concurrency 1You can set a higher value to the concurrency argument if you need the system to be more performant.
Choose one server.
WHISPER_LANG=en WHISPER_MODEL=base python zmq_server_whisper.pypython zmq_server_w2v2.pypython zmq_server_nemo.pyDownload unigrams.txt and lm.binary files.
Then, run as:
USE_LM=yes LM_UNIGRAMS_FILE=unigrams.txt LM_FILE=lm.binary NEMO_MODEL=theodotus/stt_uk_squeezeformer_ctc_ml python zmq_server_nemo.pyStructure of the command:
python source/manage.py push_to_processing <collection_key> <lang> <folder_path>Example:
python source/manage.py push_to_processing cv10 uk /Users/yehorsmoliakov/Downloads/test-folderYou can configure a CRON command to push new files with the above command.
If you want to monitor running tasks, then install Flower:
pip install flowerand run it like the following:
cd source
nohup celery -A app flower -l INFO --concurrency 1 --port=5566 > /tmp/flower.log 2> /tmp/flower_errors.log < /dev/null &then go to http://localhost:5566 to browse Flower.
FILES_DIR=/Users/yehorsmoliakov/Work/asr-corpus-creator/source/content/media/audios/ python source/manage.py export_utterances_as_jsonl test_it2 > records.jsonl- test_it2 is the collection_key argument.
python source/manage.py classify_utterances <collection_type> <device_id>
# for example:
python source/manage.py classify_utterances yt-split7 cpu
python source/manage.py classify_utterances yt-split7 cuda:0Or to classify all utterances:
python source/manage.py classify_all_utterances <device_id>
# for example:
python source/manage.py classify_all_utterances cpu
python source/manage.py classify_all_utterances cuda:0This command will classify utternaces using the AST model to get content type (Speech, Music, Bicycle bell, etc) from audio files.