![]()
![]()
- Problem Explanation
- Step by Step
- Enviroment
- Model: Classification model that predict if an employee is leaving the company.
- Tracking Experiment with Mlflow
- Orchestration of the project
- Deployment
- Monitoring
- Tests
- Linting and Formatting
- Git pre-commits hooks
- Install pre-commit
- See pre-commit hooks examples in the root of the project (Optional)
- Create a sample config file with pre-commit
- Create a yaml file with pre-commit settings
- Add pre-commit to the .git folder
- For one of my commits, I've got the following result:
- You can see all the hooks that pre-commit can run at the following link:
- Isort pre-commit hook
- Black pre-commit hook
- Pylint pre-commit hook
- Pytest pre-commit hook
- Makefiles and Make
- Flask app: Evidently
- Streamlit app
- CI/CD
Imagine that you're working on a company that want to predict if an employee is leaving or not the company based on several factors like age, salary, etc.
The main focus of this project is to build a model to predict it, register it in a register service and deploy it.

If you want to reproduce the results of this project, run the following commands:
Add a whylog_token.json to the root of the project with your token
pip install -r requirements.txt
python model.py
make build
make up
make build
make up
Follow the steps below to reproduce the problem and build the model.
conda create -n project_enviroment python=3.9conda activate project_enviromentpip install -r requirements.txtDownload dataset here
wget https://www.kaggle.com/datasets/pavansubhasht/ibm-hr-analytics-attrition-dataset?resource=download
Working on model.ipynb
conda install -n project_enviroment ipykernel --update-deps --force-reinstall
Run the following command in your terminal to track the experiment in your local machine:
mlflow ui --backend-store-uri sqlite:///mydb.sqliteThat command create a database file called mydb.sqlite in the current directory that'll be used to store the experiment data.
Add this code to your notebook to track the experiment in your local machine using a SQLite database:
import mlflow
mlflow.set_tracking_uri('sqlite:///mydb.sqlite')And start a run with:
mlflow.start_run()I'm using a sklearn library, mlflow provides a way to register the model with the following command:
#Model Register
mlflow.sklearn.log_model(
sk_model = logreg,
artifact_path='models/logreg',
registered_model_name='sk-learn-logreg-model'
)
I'm going to use Prefect==2.7.3 to orchestrate the project.
conda install prefect -c conda-forgeprefect cloud login -k YOUR_KEYGo to prefect-cloud-web
See the options wit the following command:
prefect deployment build --help
prefect deployment build .\model.py:applying_model --name Project-Deployment --tag MLOpsprefect deployment apply applying_model-deployment.yamlWe can't run the deployment from the UI yet. We nned a work queue and an agent to run the deployment.
Work queues and agents are the mechanisms by which the Prefect API orchestrates deployment flow runs in remote execution environments.
Work queues let you organize flow runs into queues for execution. Agents pick up work from queues and execute the flows

prefect agent start -t tag where tag is the tag you used to build the deployment.
Now, when you run a deployment with the -t tag option, the agent will pick up the work from the queue and execute the flows.
- Go to the UI
- Select
Add Schedule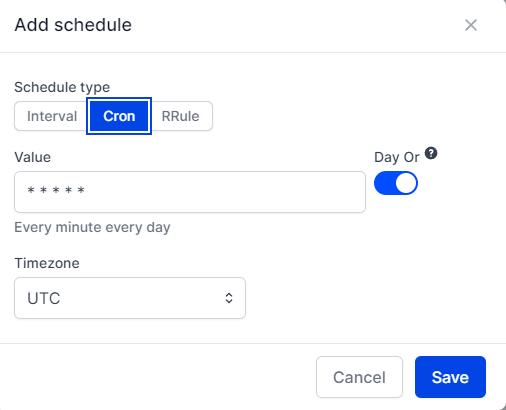
- I'm going to select
Cronwith a value of0 0 * * *that means every day at 12:00 AM. Timezoneis important, so, be sure to select the correct timezone.

I'm going to use Evidently and Whylogsto monitor the experiment.
You can install it with the following command:
pip install evidently
Classification Performance report evaluates the quality of a classification model. It works both for binary and multi-class classification. If you have a probabilistic classification, refer to a separate report. This report can be generated for a single model, or as a comparison. You can contrast your current production model performance against the past or an alternative model.
Using train data and valid data to evaluate the model I've created the following dashboard:
 You can see the resuls in the
You can see the resuls in the dashboard folder.
pip install "whylogs<1.0"
We're installing this version because the platform doesn't yet support v1.
Go to whylogs.com and create an account, then go to your profile and click on the API tab.
As a first approach, we can connect the dataset to the experiment.
I've used the following command to connect the dataset to the experiment:
import whylogs as why
from whylogs.app import Session
from whylogs.app.writers import WhyLabsWriter
writer = WhyLabsWriter("", formats=[])
session = Session(project="model-1", pipeline="mlops-project-pipeline", writers=[writer])
with session.logger(tags={"datasetId": "model-1"}) as ylog:
ylog.log_dataframe(df)

First: Make sure that you have selected Classification model in your Whylabs Project.

scores = [max(p) for p in logreg.predict_proba(X_val)]
with session.logger(tags={"datasetId": "model-1"}, dataset_timestamp = datetime.now()) as ylog:
ylog.log_metrics(
targets = list(y_val),
predictions = list(y_pred),
scores = scores,
model_type = ModelType.CLASSIFICATION,
target_field="Attrition",
prediction_field="prediction",
score_field = "Normalized Prediction Probability",
)

We can activate some Preset monitors to monitor different part of the experiment.
You can receive alerts from these Preset monitors, in my case I've enabled:

I'll use Pytest to test the model.
Install pytest with the following command:
pip install pytest
- Go to
testsextension in VS Code and select a folder that contains the tests, in this casetests/. - Select
Pytestas the test runner.
I'm going to use Pylint to lint and format the code.
Use this command to install pylint:
pip install pylint
You can lint your python file as follows:
pylint my_file.py
In my case, pylint model.py.
- In the first time I'd obtained a score 5.23/10 (very bad).
- Score of 5.88/10 (still bad).
- Score of 6.47/10 (quite good).
- After creating pyproject.toml my score raises to 8.35/10 (very good).
- Now my score is 9.76/10 (excellent).
- Press
Ctrl + Shift + Pand then typelintingand selectPylint. - Run linting with
Ctrl + Shift + PandRun linting.
You can add a .pylintrc file in the root of the project to configure pylint.
I'm going to use pyproject.toml instead.
Install black and isort with the following command:
pip install black isort
Before you run black, you can check the changes that will do with the following command:
black --diff my_file.py
After that, you can run black with the following command:
black my_file.py
You can add some configurations to pyproject.toml, in my case:
[tool.black]
line-length = 120
target-version = ['py39']
skip-string-normalization = true
where:
line-lengthis the maximum length of a line.target-versionis the version of python that you want to use.skip-string-normalizationis a boolean that indicates if you want to skip string normalization.
You can apply isort with the following command:
isort my_file.py
Add the following configurations to pyproject.toml:
multi_line_output = 3
length_sort = true
order_by_type = true
where:
multi_line_outputis the number of lines that will be used to output a multiline string.length_sortis a boolean that indicates if you want to sort by length.order_by_typeis a boolean that indicates if you want to order by type.
 I'm going to install
I'm going to install pre-commit library. More info here.
pip install pre-commit
- Go to
.git/hooksfolder and selectpre-commit. - Open
pre-commit.samplefile and see the examples. - Example content:
#!/bin/sh
#
# An example hook script to verify what is about to be committed.
# Called by "git commit" with no arguments. The hook should
# exit with non-zero status after issuing an appropriate message if
# it wants to stop the commit.
#
# To enable this hook, rename this file to "pre-commit".
if git rev-parse --verify HEAD >/dev/null 2>&1
then
against=HEAD
else
# Initial commit: diff against an empty tree object
against=$(git hash-object -t tree /dev/null)
fi
# If you want to allow non-ASCII filenames set this variable to true.
allownonascii=$(git config --type=bool hooks.allownonascii)
# Redirect output to stderr.
exec 1>&2
# Cross platform projects tend to avoid non-ASCII filenames; prevent
# them from being added to the repository. We exploit the fact that the
# printable range starts at the space character and ends with tilde.
if [ "$allownonascii" != "true" ] &&
# Note that the use of brackets around a tr range is ok here, (it's
# even required, for portability to Solaris 10's /usr/bin/tr), since
# the square bracket bytes happen to fall in the designated range.
test $(git diff --cached --name-only --diff-filter=A -z $against |
LC_ALL=C tr -d '[ -~]\0' | wc -c) != 0
then
cat <<\EOF
Error: Attempt to add a non-ASCII file name.
This can cause problems if you want to work with people on other platforms.
To be portable it is advisable to rename the file.
If you know what you are doing you can disable this check using:
git config hooks.allownonascii true
EOF
exit 1
fi
# If there are whitespace errors, print the offending file names and fail.
exec git diff-index --check --cached $against --
Type the following command to create a sample config file:
pre-commit sample-config
Type the following command to create a yaml file with pre-commit settings:
pre-commit sample-config >.pre-commit-config.yaml
Type the following command to add pre-commit to the .git folder:
pre-commit install

https://pre-commit.com/hooks.html
Add the following configuration to .pre-commit-config.yaml:
- repo: https://github.com/pycqa/isort
rev: 5.10.1
hooks:
- id: isort
name: isort (python)
Add the following configuration to .pre-commit-config.yaml:
repos:
- repo: https://github.com/psf/black
rev: stable
hooks:
- id: black
language_version: python3.9
Add the following configuration to .pre-commit-config.yaml:
- repo: local
hooks:
- id: pylint
name: pylint
entry: pylint
language: system
types: [python]
args:
[
"-rn", # Only display messages
"-sn", # Don't display the score
]
hooks:
- id: pytest-check
name: pytest-check
entry: pytest
language: system
pass_filenames: false
always_run: true
Make is a tool which controls the generation of executables and other non-source files of a program from the program's source files. Make gets its knowledge of how to build your program from a file called the makefile, which lists each of the non-source files and how to compute it from other files. When you write a program, you should write a makefile for it, so that it is possible to use Make to build and install the program.
sudo apt install make
or if you are using Windows, you can install make with the following command (as a administrator):
choco install make
where choco is the command to install chocolatey packages.
test:
echo test
other_thing:
echo other thing
run: test other_thing
echo run
make run
I'm going to put the html generated by Evidently in a Flask app.
Install Flask with the following command:
pip install flask
from flask import Flask, render_template
app = Flask (__name__, template_folder='dashboards')
@app.route('/')
def evidently():
return render_template('df_model_performance.html')
if __name__ == '__main__':
app.run(debug=True, host = '0.0.0.0', port = 9696)
where:
dashboardsis the folder where the html files are located.- render_template is a function that takes the name of the html file and returns the html code.
- I've selected port = 9696.
We can make a Streamlit app using our model.
Install Streamlit with the following command:
pip install streamlit
We'll use the last model we trained. This model will be at models folder.
Load the model with the following command:
def load_model():
model = 'models/pipeline.bin'
with open(model, 'rb') as f_in:
pipeline = pickle.load(f_in)
return pipeline
pipeline = load_model()
Run the app with the following command:
streamlit run streamlit/streamlit_app.py
where streamlit_app.py is the name of the file.
Github actions is a service that allows us to run our code in a virtual machine. We can use this service to run our code when we push our code to Github. We can also use this service to run our code when we create a pull request.
I've created a workflow to test the code. Basically, this workflow will run the following commands:
- Install the requirements.
- Run the tests.
This workflow will run the following commands:
- Install the requirements.
- Run the model
- Push the new model to the repository.
- This workflow will run every day (6 hours after the last run).