Github: https://github.com/GoogleCloudPlatform
Medium: https://medium.com/google-cloud
Preços:
https://cloud.google.com/pricing
Calculadora de consumo:
https://cloud.google.com/products/calculator https://console.cloud.google.com/billing/
Limite de cotas: Configura email ou número de celular no console caso chegue ao valor estipulado.
Doc: https://cloud.google.com/compute/quotas Console: https://console.cloud.google.com/iam-admin/quotas
Develop Tools: https://cloud.google.com/products/tools
Install: https://cloud.google.com/sdk/docs/quickstart
Exemplos:
$ gcloud version
$ gcloud auth login
$ gcloud info --show-log
$ gcloud config set project <my-id>
$ gcloud init <my-project>
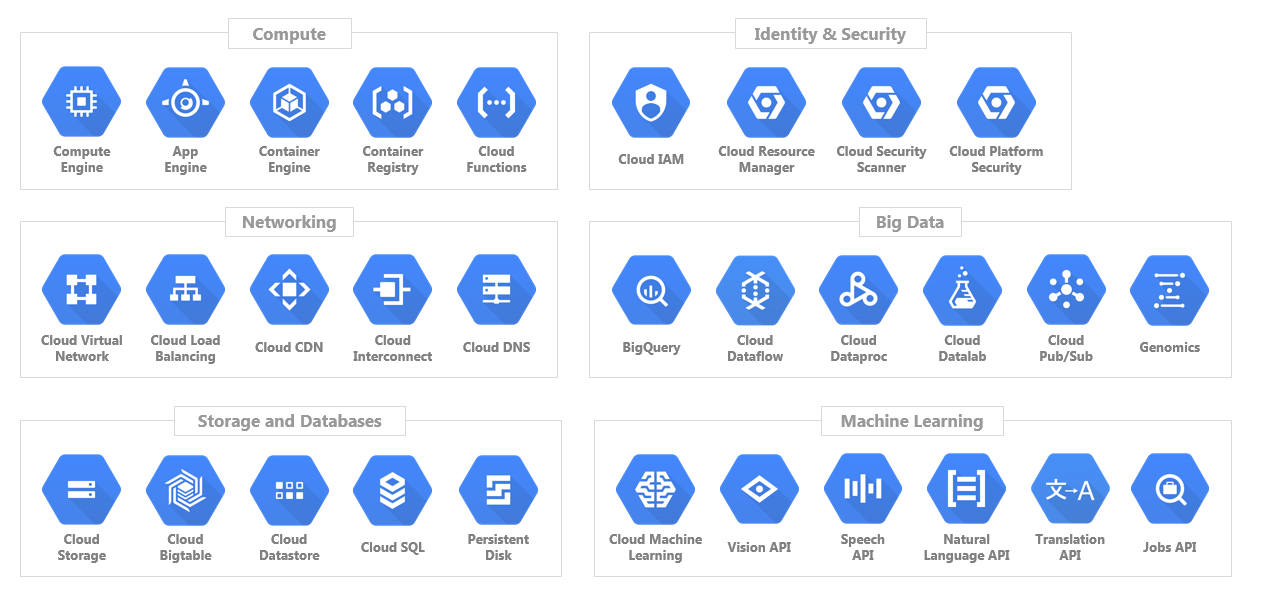
Projects


Região

Usando API
1º Criar VM

No lado direito, vai aparecendo os valores conforme troca de máquina

É possível acessar SSH pelo navegador nas opções abaxio.

Vá em painel do API e Serviços e Ativar APIS e Serviços




GKE [Google Kubernetes Engine cluster]



scale

Stackdriver Monitoring
do que quando você está apenas aprendendo, mas acho muito importante que você perceba o que está disponível. Assim, você pode ver que tem uma visão geral do monitoramento de verificações de tempo, incidentes, gráficos, eventos e grupos. E você tem recursos. E você pode ver que tem um explorador de métricas, você tem infraestrutura, observe que temos infraestrutura em torno do Kubernetes Engine. E temos trabalhado bastante neste curso com o Kubernetes. Você deve se lembrar de um filme anterior que atualmente temos um cluster executando o banco de dados Aerospike NoSQL. E aqui está o monitoramento que você obtém, basicamente apenas por padrão no Kubernetes, onde pode ver o uso da CPU, a E / S do disco, a integridade do pod, a E / S do disco, a integridade do pod, o tráfego de rede e vários métricas-chave. Agora temos alguns outros serviços aqui Agora temos alguns outros serviços aqui porque fiz alguns outros trabalhos com o Kubernetes ao longo deste curso. Portanto, seu painel pode ser um pouco diferente. Mas oferece muitos detalhes ricos, na verdade apenas por padrão. Como fizemos com nossas métricas de log apenas no filme anterior, você pode configurar o alerta de uma forma muito sofisticada aqui, usando políticas, incidentes e eventos. usando políticas, incidentes e eventos. Também temos verificações de tempo de atividade. Também temos verificações de tempo de atividade. Você pode ter grupos e configurar painéis. Você pode ter grupos e configurar painéis. Portanto, esta é uma interface realmente rica. Esta é uma interface realmente rica em termos de gerenciamento e monitoramento de seus projetos do GCP. em termos de gerenciamento e monitoramento de seus projetos do GCP. E no curso GCP Enterprise Essentials, e no curso GCP Enterprise Essentials, vamos mergulhar um pouco mais fundo, vamos nos aprofundar um pouco mais, mas eu só queria apresentar a você, mas eu só queria apresentá-lo para o conjunto de ferramentas que está disponível para o conjunto de ferramentas que está disponível como parte do pacote de produtos GCP. como parte do pacote de produtos GCP.
Google Cloud Platform architecture concepts

Agora que examinamos uma grande parte, vamos examinar alguns padrões arquitetônicos. Vejo em meu trabalho em todas as nuvens de fornecedores uma grande mudança no mundo das arquiteturas de aplicativos em nuvem. De uma forma sucinta, é chamada sem servidor. chamadas de arquiteturas sem servidor. de novos serviços disponíveis. O grande diferencial entre o GCP O grande diferencial entre o GCP e os outros concorrentes da nuvem é que eles habilitaram, por meio de serviços como a execução da nuvem, por meio de serviços como a execução da nuvem, a capacidade de trazer seu próprio contêiner, mas não gerenciá-lo. a capacidade de trazer seu próprio contêiner, mas não gerenciá-lo. Qual é o principal diferencial do ecossistema da nuvem. No nível de contêineres, é claro que o Google é realmente o autor principal, claro que o Google é realmente o autor principal do ecossistema de gerenciamento de contêineres Kubernetes e isso mostra no polonês suas ofertas de serviço. e isso aparece no polimento em torno de suas ofertas de serviço. Além disso, nos últimos 12 meses, eles adicionaram várias bibliotecas importantes, como Knative e Kubeflow, que ajudam na implementação do Kubernetes. que ajudam na implementação do Kubernetes. Na minha experiência profissional, é extremamente importante usar o Kubernetes no nível de abstração correto e agradeço essas bibliotecas. e eu dou as boas-vindas a essas bibliotecas. O que acho que permitirá implantações de aplicativos Kubernetes para mais de meus clientes. É claro que as máquinas virtuais ainda são uma opção muito viável e necessária em alguns cenários de aplicativos. Principalmente os que exigem que os clientes mantenham o controle e a gestão. Uma dica que eu teria para você e tentei incorporá-la neste curso é aproveitar demais o mercado do GCP para que você possa começar a trabalhar rapidamente com imagens de VM pré-criadas. A arquitetura costuma ser conhecida como lift and shift. Quando você está simplesmente movendo aplicativos existentes para a nuvem. E é muito viável para muitos cenários de clientes. E é muito viável para muitos cenários de clientes. Alguns outros pontos críticos. Neste curso, tocamos levemente nas linhas básicas de segurança e rede. No próximo curso Fundamentos corporativos do GCP, No próximo curso fundamentos corporativos do GCP, estarei focando muito mais profundamente nessas áreas de aspectos principais. Vou me concentrar muito mais profundamente nessas áreas-chave. Eu apresentei a você ferramentas como driver de pilha que podem ajudá-lo com seu gerenciamento e monitoramento do dia-a-dia. E, por fim, seria remissivo se não desse orientações sobre o aprendizado de máquina no GCP. Mais uma vez, o Google se diferencia de seus concorrentes por ter uma oferta de produtos muito completa. por ter uma oferta de produtos muito completa. Selecionar o nível de abstração apropriado para o aprendizado de máquina é um aspecto importante do sucesso. Em alguns cenários, o nível de API, como trabalhar com API de divisão, o nível de API, como trabalhar com API de divisão, será apropriado. será apropriado. Enquanto em outros você precisará de uma máquina virtual nativa como a que vimos (indistinta). Tem sido interessante ver o crescimento de serviços sem servidor com o tempo no ecossistema GCP. Você sabia que o primeiro serviço sem servidor foi, na verdade, o App Engine em 2008? Meu favorito pessoal é claro Big Query, que já existe desde esta gravação há quase 10 anos. O armazenamento em nuvem foi introduzido em 2011 e, em seguida, uma infinidade de outros serviços a partir de 2013 e ainda mais agora na época desta gravação. Na verdade, existem tantos serviços sem servidor do GCP disponíveis no ecossistema que eles não cabem em um único diagrama. Esta é apenas uma abstração de alto nível. E esse padrão para o desenvolvimento de aplicativos sem servidor é realmente um impulsionador chave nas arquiteturas que estou construindo com meus clientes. Como mencionei anteriormente, eu tenho um curso sobre arquitetura de aplicativo sem servidor de biblioteca que você pode querer dar uma olhada se for um cenário de seu interesse.
Web single-page and API-based architectures



são realmente simples. Mas, simples é bom. Portanto, para hospedagem estática na web, como acontece com os outros concorrentes, você pode hospedar fora de um depósito de armazenamento em nuvem. Agora, se você quiser um domínio personalizado, precisará do Cloud DNS antes disso. É realmente tão simples quanto usar esses dois serviços. Um cenário igualmente simples é a hospedagem de conteúdo. Nesse caso, em vez de usar um intervalo, você pode usar instâncias do GCE ou pode usar Kubernetes Container Clusters. O principal componente aqui para servir este conteúdo, se você estiver trabalhando globalmente, isso permite que o conteúdo seja armazenado em cache para o cliente específico em todo o mundo. Outra variante desse tipo de site simples ou hospedagem de API é mostrada neste diagrama arquitetônico. Aqui, temos alguns serviços que hospedam APIs. Agora, em uma arquitetura ambulatorial moderna, ou você não pode escolher usar o serviço de funções de nuvem mais recente que se tornou GA desde que este diagrama foi feito. Você também pode usar o Compute Engine ou o Kubernetes Engine, dependendo se você precisa ou não trazer seu próprio contêiner, você precisa trazer seu próprio contêiner ou máquina virtual. ou máquina virtual. Agora, se você fosse usar qualquer um desses grupos Agora, se você fosse usar qualquer um desses grupos de máquinas virtuais ou contêineres, você teria algum tipo de mecanismo de balanceamento de carga, então você teria algum tipo de mecanismo de balanceamento de carga na frente deles para tornar sua API altamente disponível. na frente deles para tornar sua API altamente disponível.
Web blog and managed databases

A próxima arquitetura é novamente um site. E isso é para hospedagem de conteúdo dinâmico. Portanto, você realmente tem dois, possivelmente três, componentes principais em seu plano arquitetônico. Você servirá seu Compute com instâncias do Compute Engine, então VMs, ou você pode usar Kubernetes Engine, contêineres Docker. Geralmente, você terá balanceamento de carga da nuvem antes disso. em um banco de dados gerenciado, geralmente relacional. Houve um motivo pelo qual mostrei o GCP Cloud SQL que a maioria dos meus clientes o usa. Observe, você pode facilmente ter uma réplica de leitura do serviço, o aspecto de gerenciamento é, se desejar, o Google pode fazer os backups para você e manter a alta disponibilidade para você. Em geral, é preferível ter o seu próprio. Além disso, se esse tipo de site fosse um tipo padrão, como o WordPress, você poderia ignorar a configuração do mercado de implantação pré-criada, sem ter que fazer nada sem ter fazer qualquer coisa diferente de configurar a implantação. além de configurar a implantação. Então, novamente, quando você estiver configurando Então, novamente, quando você estiver configurando arquiteturas de aplicativo básicas, arquiteturas de aplicativo básicas, eu recomendo que você sempre dê uma olhada Eu recomendo que você sempre dê uma olhada no mercado para veja se o padrão já existe no mercado para ver se o padrão já existe, porque ele pode fazer com que você comece a trabalhar muito mais rapidamente, porque pode fazer com que você comece a trabalhar muito mais rapidamente e com as melhores práticas.
Web application on GAE

O próximo padrão de arquitetura de aplicativo é novamente em torno de um aplicativo da Web dinâmico. Como você deve se lembrar do filme anterior, o Google App Engine é o serviço sem servidor mais antigo disponível no GCP. É uma boa opção para esse tipo de arquitetura de aplicativo. Geralmente, você começaria com o App Engine no front-end e isso vem com o Cloud Load Balancing. Então, para um URL personalizado, você usaria o Cloud DNS. Agora você pode escolher usar serviços como Memcached ou Filas de tarefas para colocar dados que são acessados com frequência na memória para recuperação mais rápida para que as páginas do seu site retornem mais rapidamente. Como você fornecerá conteúdo estático e dinâmico, o típico nesta arquitetura é usar os intervalos do Google Cloud Storage junto com o Cloud SQL. Agora, em algumas arquiteturas, também vejo o uso de bancos de dados NoSQL. Nesta arquitetura, o Cloud Datastore é mostrado e você deve se lembrar que o Cloud DataStore agora tem uma opção de ser convertido para Firestore para recursos adicionais. Se houver escalonamento nesses bancos de dados, você poderá aplicá-lo por meio de vários recursos diferentes. Este diagrama mostra aplicativos em lote por meio do App Engine com escalonamento automático. Trabalhei com isso, mas também trabalhei com os recursos de dimensionamento disponíveis por meio do Cloud SQL e do Cloud Datastore.
Mobile development with AI

Esta arquitetura de referência gira em torno de aplicativos móveis. O Google teve um forte conjunto de ofertas de produtos por muitos anos em torno do Firebase. Portanto, você pode ver que o aplicativo móvel está funcionando com um conjunto de serviços que estão na família Firebase e Firestore. Então, primeiro, Cloud Storage for Firebase, que é apenas uma versão do Cloud Storage projetada para funcionar com Firebase, e Cloud Firestore, que, como aprendemos neste curso, é a próxima versão do banco de dados Firebase e tem mais recursos e está realmente se fundindo com o Datastore. É um banco de dados NoSQL. O Cloud Functions para Firebase é uma versão do Google Cloud Functions, portanto, não tem servidor. Na verdade, toda essa arquitetura não tem servidor e é muito, muito moderna e normalmente usada para o desenvolvimento de aplicativos móveis. Agora, além do Cloud Functions para Firebase, um aspecto interessante dessa arquitetura de aplicativo é a API Cloud Vision. Portanto, o caso de uso aqui pode ser que o modelo treinado que o Google fornece, que fornece rotulagem para objetos, como vimos neste curso em imagens, seja usado como parte de um aplicativo personalizado. Então, você deve se lembrar, testamos a API e retornamos rótulos para uma imagem de um gato, e ela tinha diferentes aspectos de nossa imagem. Tinha que ser um gato, que estava sorrindo, que tinha bigodes, e assim por diante. E tudo o que precisávamos fazer era fornecer a imagem. A seleção do algoritmo do modelo, o treinamento, o ajuste do hiperparâmetro, a veiculação e a manutenção do modelo foram gerenciados pelo Google. Pagamos apenas quando chamamos o endpoint da API. É realmente uma maneira muito moderna de trabalhar com aprendizado de máquina e um grande diferencial entre o Google e alguns de seus outros concorrentes. Ele permite que você adicione funcionalidades complexas de aprendizado de máquina aos seus aplicativos de maneira muito simples, rápida e fácil, sejam eles móveis, baseados na web ou qualquer outro tipo de arquitetura em que você possa integrar APIs.
Big Data log processing

Esta próxima arquitetura de aplicativo de referência está no mundo do big data. É aqui que realizo grande parte do meu trabalho profissional. Esse cenário específico acontece em torno do processamento de logs e mostra um conjunto comum de padrões algumas vezes com clientes em torno dos logs. Portanto, a primeira seção é a ingestão. E estamos começando com microsserviços em um Kubernetes Engine. Talvez estejamos usando o Cloud Run recém-introduzido, para que possamos trabalhar em um nível mais alto de abstração. Em seguida, a coleta de registros será monitorada por meio do Cloud Logging no Stackdriver. O próximo nível da arquitetura é olhar para o Lote e o Fluxo. Para lote, vamos usar armazenamento de log em intervalos de armazenamento em nuvem. Para streaming, usaremos o Cloud Pub / Sub, com o qual trabalhamos neste curso. Um serviço sobre o qual ouvimos falar, mas ainda não funcionamos, é o Cloud Dataflow. no ecossistema GCP. Vimos isso em um nível superior usando um serviço chamado Cloud Dataprep, que implementa jobs do Cloud Dataflow. E veremos isso no curso GCP Enterprise Essentials com mais detalhes, porque normalmente está associado a cargas de trabalho corporativas. E, uma vez que os logs são processados, então analítica. Agora, um aspecto que eu não adicionei a este diagrama que normalmente é adicionado é algum tipo de visualização. Você se lembra das opções em torno das ferramentas de visualização que examinamos? O GCP tem o Cloud Data Studio incorporado. Existem também vários fornecedores parceiros. O que é interessante sobre essa arquitetura é que ela pode ser construída inteiramente sem servidor. Se, como disse no início, em vez de usar o Kubernetes Engine, abstrairmos mais alto o Cloud Run com Knative e as outras bibliotecas integradas, o Cloud Run com Knative e as outras bibliotecas integradas, podemos aproveitar a infraestrutura de gerenciamento do Google e obtê-la instalado e funcionando muito mais rapidamente e com muito mais rapidez, porque Logging, Storage, Pub / Sub, Dataflow e BigQuery porque Logging, Storage, Pub / Sub, Dataflow e BigQuery são serviços sem servidores. são todos serviços sem servidor. Estou vendo esse tipo de arquitetura se tornando. Estou vendo esse tipo de arquitetura sendo usado com muito mais frequência do que a mais antiga, usado com muito mais frequência do que as mais antigas, arquiteturas baseadas em máquina virtual, arquiteturas baseadas em máquina virtual ou mesmo o bruto Arquiteturas Kubernetes ou mesmo as arquiteturas Kubernetes brutas simplesmente porque é um tempo mais rápido para valorizar, um tempo mais rápido para o mercado.