Repository detailing the deployment of an Enterprise Azure OpenAI reference architecture.
Link: Azure Architecture Center - Monitor OpenAI Models
- Comprehensive logging of Azure OpenAI model execution tracked to Source IP address. Log information includes what text users are submitting to the model as well as text being received back from the model. This ensures models are being used responsibly within the corporate environment and within the approved use cases of the service.
- Advanced Usage and Throttling controls allow fine-grained access controls for different user groups without allowing access to underlying service keys.
- High availability of the model APIs to ensure user requests are met even if the traffic exceeds the limits of a single Azure OpenAI service.
- Secure use of the service by ensuring role-based access managed via Azure Active Directory follows principle of least privilege.
EnterpriseLogging_0.mp4

| 1. Client applications can access Azure OpenAI endpoints to perform text generation (completions) and model training (fine-tuning) endpoints to leverage the power of large language models. 2. Next-Gen Firewall Appliance (Optional) - Provides deep packet level inspection for network traffic to the OpenAI Models. |
3. API Management Gateway enables security controls, auditing, and monitoring of the Azure OpenAI models. Security access is granted via AAD Groups with subscription based access permissions in APIM. Auditing is enabled via Azure Monitor request logging for all interactions with the models. Monitoring enables detailed AOAI model usage KPIs/Metrics. | 4. API Management Gateway connects to all Azure resources via Private Link to ensure all traffic is secured by private endpoints and contained to private network. 5. Multiple Azure OpenAI instances enable scale out of API usage to ensure high-availability and disaster recovery for the service. |
This project framework provides the following features:
- Enterprise logging of OpenAI usage metrics:
- Token Usage
- Model Usage
- Prompt Input
- User statistics
- Prompt Response
- High Availability of OpenAI service with region failover.
- Integration with latest OpenAI libraries-
Provisioning artifacts, begin by provisioning the solution artifacts listed below:
(Optional)
- Next-Gen Firewall Appliance
- Azure Application Gateway
- Azure Virtual Network
-
To begin, provision a resource for Azure OpenAI in your preferred region. Please note the current primary region is East US, new models and capacity will be provisioned in this location before others: Provision resource
-
Once the resource is provisioned, create a deployment with model of choice: Deploy Model
-
After the model has been deployed, go to the OpenAI studio to test your newly created model with the studio playground: oai.azure.com/portal
-
API Management can be provisioned through Azure Portal :Provision resource
-
Once the API Management service has been provisioned you can import your OpenAI API layer using the OpenAPI specification for the service.
- Import instructions
- Open the APIM - API blade and Select the Import option for an existing API.

- Select the Update option to update the API to the current OpenAI specifications.
- (Optional) For Semantic Kernel compatibility "Append" the following Authoring API endpoints:
-
For All API Operations:
- In Settings set the Subscription - header name to "api-key" to match OpenAI library specifications.
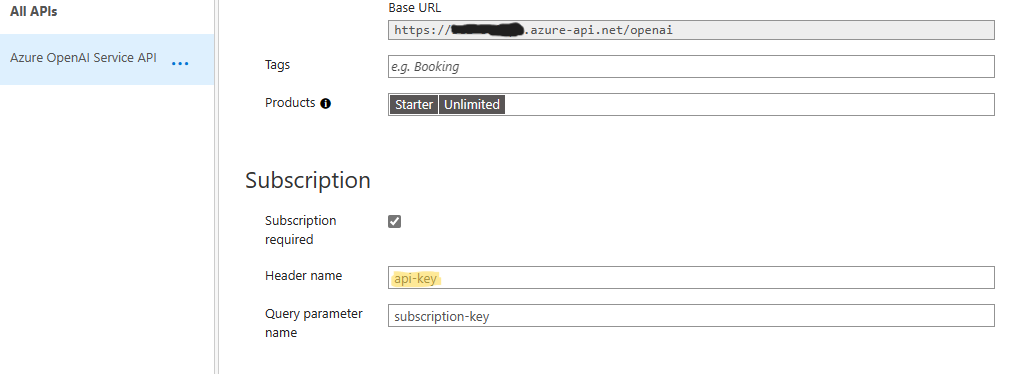
- Configure the inbound rule of "set-headers" to add/override the "api-key" header parameter with a value of the API secret key from the OpenAI service. Instructions for locating your OpenAI keys are here: Retrieve keys

- Configure the backend service to the endpoint of your deployed OpenAI service with /openai as the path, be sure to override the existing endpoint:
- Example: https://< yourservicename >.openai.azure.com/openai
- Retrieve endpoint

- Configure the Diagnostic Logs settings:
- Set the sampling rate to 100%
- Set the "Number of payload bytes to log" as the maximum.

- In Settings set the Subscription - header name to "api-key" to match OpenAI library specifications.
-
Test API
- Test the endpoint by providing the "deployment-id", "api-version" and a sample prompt:

- Test the endpoint by providing the "deployment-id", "api-version" and a sample prompt:


API Management allows API providers to protect their APIs from abuse and create value for different API product tiers. Use of API Management layer to throttle incoming requests is a key role of Azure API Management. Either by controlling the rate of requests or the total requests/data transferred.
Details for configuring APIM Layer : https://learn.microsoft.com/en-us/azure/api-management/api-management-sample-flexible-throttling
- Once the API Management layer has been configured, you can configure existing OpenAI python code to use the API layer by adding the subscription key parameter to the completion request: Example:
import openai
openai.api_type = "azure"
openai.api_base = "https://xxxxxxxxx.azure-api.net/" # APIM Endpoint
openai.api_version = "2023-05-15"
openai.api_key = "APIM SUBSCRIPTION KEY" #DO NOT USE ACTUAL AZURE OPENAI SERVICE KEY
response = openai.Completion.create(engine="modelname",
prompt="prompt text", temperature=1,
max_tokens=200, top_p=0.5,
frequency_penalty=0,
presence_penalty=0,
stop=None) - Once OpenAI requests begin to log to the Azure Monitor service, you can begin to analyze the service usage using Log Analytics queries.
- The table should be named "ApiManagementGatewayLogs"
- The BackendResponseBody field contains the json response from the OpenAI service which includes the text completion as well as the token and model information.
- Example query to identify token usage by ip and model:
ApiManagementGatewayLogs
| where tolower(OperationId) in ('completions_create','chatcompletions_create')
| where ResponseCode == '200'
| extend modelkey = substring(parse_json(BackendResponseBody)['model'], 0, indexof(parse_json(BackendResponseBody)['model'], '-', 0, -1, 2))
| extend model = tostring(parse_json(BackendResponseBody)['model'])
| extend prompttokens = parse_json(parse_json(BackendResponseBody)['usage'])['prompt_tokens']
| extend completiontokens = parse_json(parse_json(BackendResponseBody)['usage'])['completion_tokens']
| extend totaltokens = parse_json(parse_json(BackendResponseBody)['usage'])['total_tokens']
| extend ip = CallerIpAddress
| where model != ''
| summarize
sum(todecimal(prompttokens)),
sum(todecimal(completiontokens)),
sum(todecimal(totaltokens)),
avg(todecimal(totaltokens))
by ip, model
- Example query to monitor prompt completions:
ApiManagementGatewayLogs
| where tolower(OperationId) in ('completions_create','chatcompletions_create')
| where ResponseCode == '200'
| extend model = tostring(parse_json(BackendResponseBody)['model'])
| extend prompttokens = parse_json(parse_json(BackendResponseBody)['usage'])['prompt_tokens']
| extend prompttext = substring(parse_json(parse_json(BackendResponseBody)['choices'])[0], 0, 100)
- Azure API Management Policies for Azure OpenAI: https://github.com/mattfeltonma/azure-openai-apim