Contact Points:
- Luca Cagliero: luca.cagliero@polito.it
- Moreno La Quatra: moreno.laquatra@polito.it
This repository contains the information used for the development a master thesis in the NLP domain at PoliTO.
The latex template to write the master thesis is avaiable in Overleaf
The first step is to create a GitHub Educational account and create an ad-hoc repository containing all relevant code and information for the master thesis.
The research work expected during the development of the master thesis will cover the following steps.
Collect, read and analyze the most recent and relevant publications in the proposed application field. Related works could be summarized and presented by using the Markdown Template available here. Publication could be searched by using the following services:
The majority of the thesis requires a step of data collection or data search. During the exploration of the state of the art the student is asked to collect and organize the data used by each publication. Dataset must be presented in an organized way by expoiting the Markdown template available here If a new data collection is created/parsed please create a specific Markdown file (template available here) explaining both the data collection procedure and the statistics of the data collection.
A video tutorial explaining how to create a Python package is available here: YouTube .
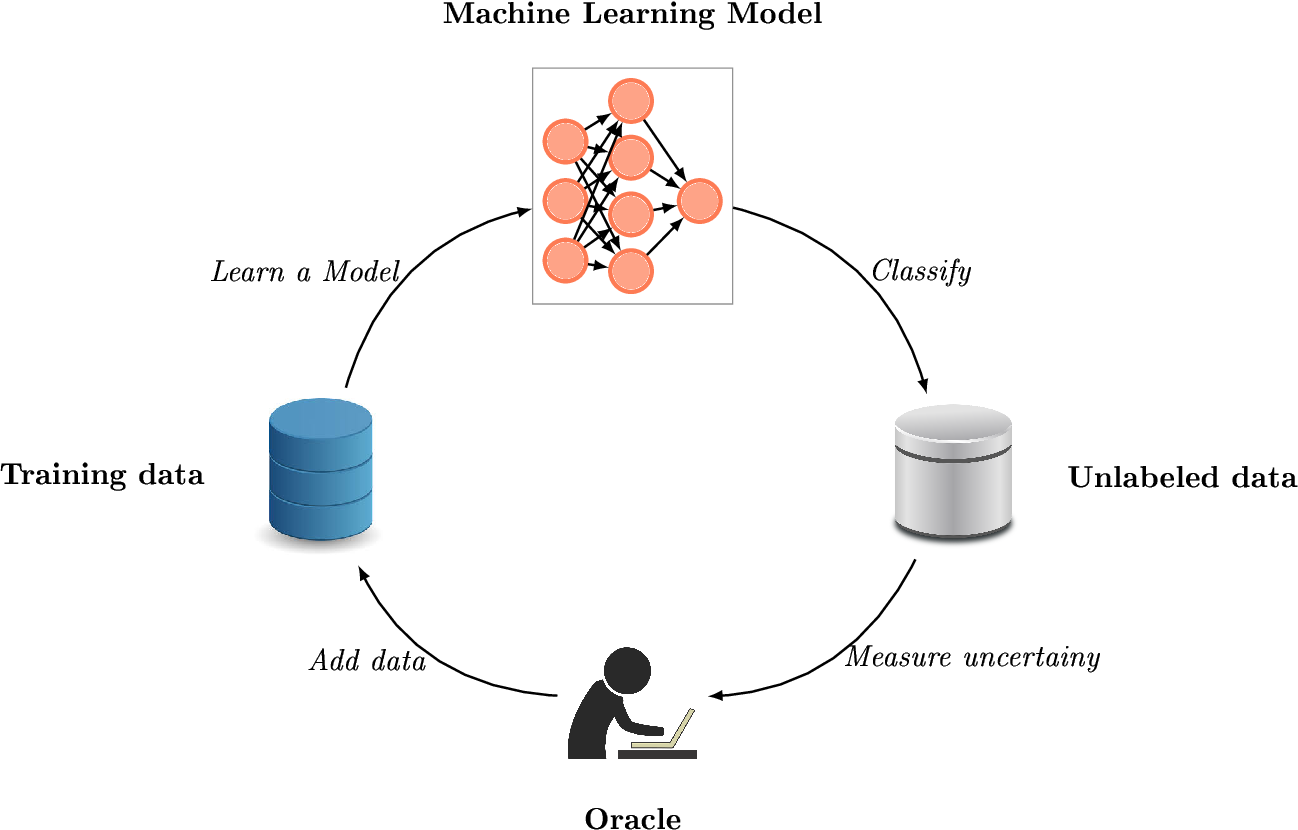
Active Learning is a subfield of machine learning that aims at reducing the number of supervised samples needed to train a machine learning model. It include an human-in-the-loop procedure aimed at selecting the most relevant examples for model's learning.
The main objectives of this thesis are:
- Explore the state of the art in Active Learning
- Define and propose an Active Learning approach for the fine-tuning of deep neural language models.
- Simulate the process on existing benchmark dataset
References 📚:
Citovsky, G., DeSalvo, G., Gentile, C., Karydas, L., Rajagopalan, A., Rostamizadeh, A., & Kumar, S. (2021). Batch Active Learning at Scale. arXiv preprint arXiv:2107.14263. article
Peshterliev, S., Kearney, J., Jagannatha, A., Kiss, I., & Matsoukas, S. (2019, June). Active Learning for New Domains in Natural Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Industry Papers) (pp. 90-96). article
Schröder, C., & Niekler, A. (2020). A Survey of Active Learning for Text Classification using Deep Neural Networks. arXiv preprint arXiv:2008.07267. article
Interesting projects 💻:
Additional Material:
Active Learning: Algorithmically Selecting Training Data to Improve Alexa’s Natural-Language Understanding post
Active Learning for Natural Language Processing. post
 image by: https://quillbot.com/
image by: https://quillbot.com/
Text paraphrasing aims at reformulating natural language by conveying the same meaning with different words. For example:
- I would like to know if tomorrow will be sunny in Turin.
- Will it be sunny tomorrow in Turin?
- Will be a sunny day in Turin tomorrow?
All those sentences bring the same meaning using slightly different formulations. The syntactic element are different, however the semantic behind the is the same.
The main objectives of this thesis are:
- Analyze the state-of-the-art in text paraphrasing models.
- Exploit latest advancement in deep learning techniques to create a text paraphrasing tool based on Transformers.
- Evaluate the proposed pipeline on benchmark datasets (Quora, ParaSCI, etc.).
References 📚:
Dong, Q., Wan, X., & Cao, Y. ParaSCI: A Large Scientific Paraphrase Dataset for Longer Paraphrase Generation. article
Hosking, T., & Lapata, M. (2021). Factorising Meaning and Form for Intent-Preserving Paraphrasing. arXiv preprint arXiv:2105.15053. article
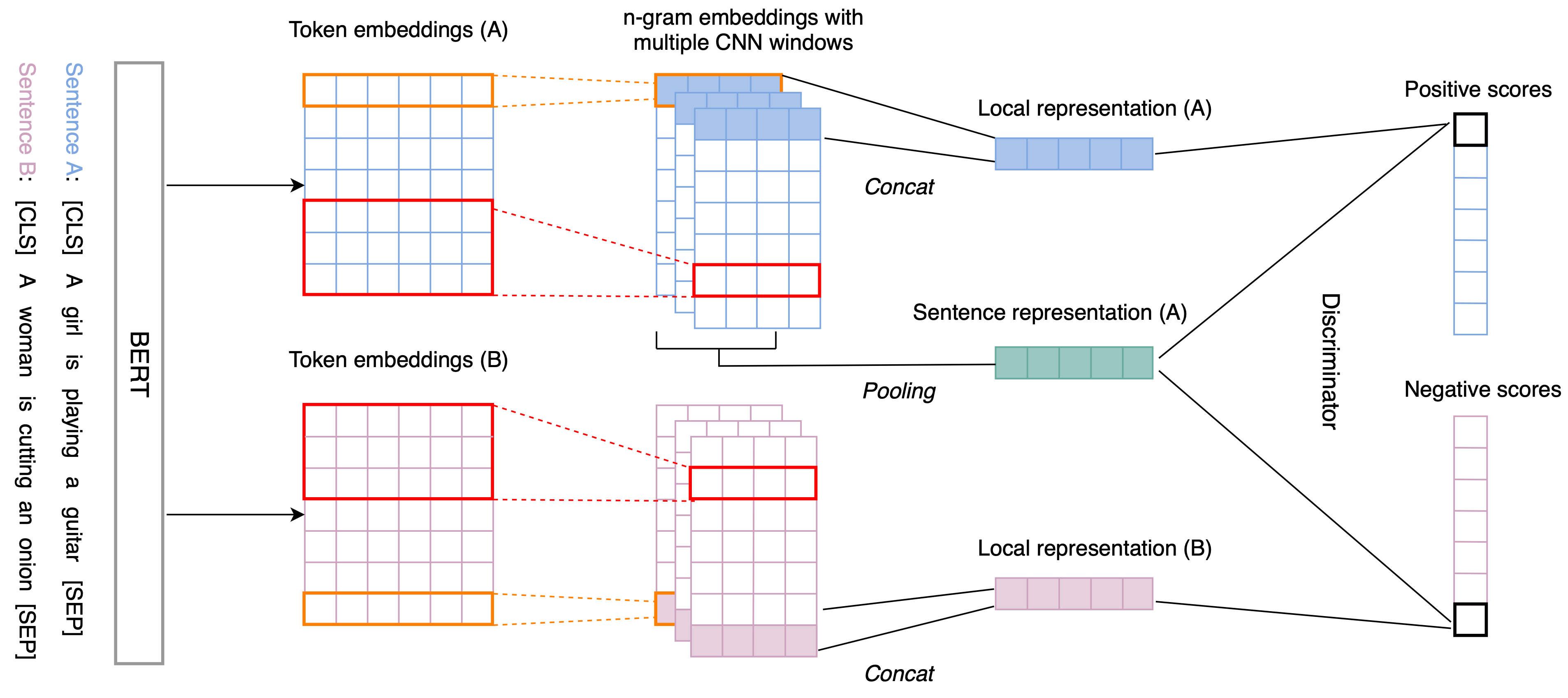 image by: https://arxiv.org/abs/2009.12061
image by: https://arxiv.org/abs/2009.12061
Learning effective representations of the input data is one of the main challenges of deep learning algorithms. While it is framed as an independent task, effective representations are beneficial in a variety of contexts and domains. Contrastive Learning is one of the hot-topics in current research. It allows exploiting un-annotated data to let the model learns by contrastive examples. It all started in the Computer Vision domain with some groundbreaking publications (e.g., SimCLR), however, at the time of writing, almost 400 papers have been published both for CV and NLP.
The main objectives of this thesis are:
- Analyze the state-of-the-art in contrastive learning and data augmentation techniques (mainly in NLP).
- Find interesting spots where Contrastive Learning can be effectively exploited (e.g., structured data representation)
- Define a novel contrastive learning algorithm and demonstrate its effectiveness in real-world scenarios. The model should be trained and evaluated on benchmark dataset (the Master Thesis could involve also data collection).
References 📚:
Radford, Alec, et al. "Learning transferable visual models from natural language supervision." arXiv preprint arXiv:2103.00020 (2021). article
Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020. article
Hosking, T., & Lapata, M. (2021). Factorising Meaning and Form for Intent-Preserving Paraphrasing. arXiv preprint arXiv:2105.15053. article
Zhang, Yan, et al. "An unsupervised sentence embedding method by mutual information maximization." arXiv preprint arXiv:2009.12061 (2020). article
Lilian Weng - Contrastive Representation Learning
Interesting projects 💻:

image by: https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
What if you can speak with someone else voice? Voice imitation is usually challenging from an human perspective. It requires both specific training and great voice flexibility. This thesis aims at exploring the intersection of audio and natural language processing domain for the task of voice cloning.
The main objectives of this thesis are:
- Analyze the state-of-the-art voice cloning.
- Leverage state-of-the-art NLP models.
- Define a novel approach and demonstrate its effectiveness both using benchmark datasets and real-world data (Master Thesis could involve also data collection).
References 📚:
Voice Cloning: a Multi-Speaker Text-to-Speech Synthesis Approach based on Transfer Learning article
Neural Voice Cloning with a Few Samples article
Interesting projects 💻:

image by: https://grammarly.com
The task of reviewing the literature for a scientific project is one of the most crucial steps for its success. This thesis is intented to apply several NLP architecture and tools for generating a platform aimed at helping researchers during the academic literature review.
The main objectives of this thesis are:
- Define the scope and the tools for platform develpment.
- Leverage state-of-the-art NLP models for classification, summarization, automated scoring, user-item similarity, etc.
- Implement, train and make efficient relevant DL architectures that can be used in the platform.
- Platform deployment.
References 📚:
ArXiv Sanity platform
Semantic Scholar platform
A Web-based Knowledge Hub for Exploration of MultipleResearch Article Collections paper
Interesting projects 💻:
- Simone Manni (2021) @simonemanni
- Sofia Perosin (2021) @sofiaperosin