This package implements a C++/Cuda OP for evaluating this ℓ function(called x*log(x) for reasons of simplicity in the rest of the README file):
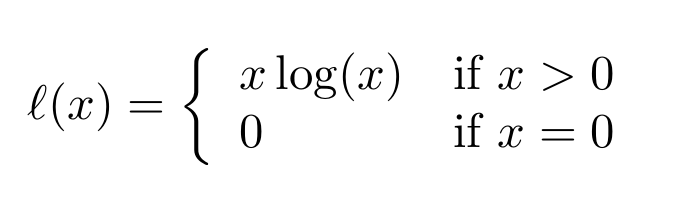
This extends the usual x*log(x) by defining it for x=0, the inserted value of 0 is the limit of said function for x -> 0:
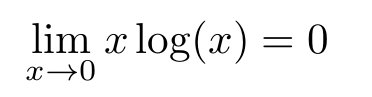
Just clone this repo and run
python3 setup.py install
TensorFlow already has to be installed and should be up to date.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow_xlogx import xlogx as tf_xlogx
xs = np.linspace(0,3,100)
sess = tf.Session()
ys = sess.run(tf_xlogx(xs))
plt.plot(xs,ys)
plt.show()By changing the content of src/settings.h and reinstalling you can configure this package.
This is a simple on/off switch if you set it to 1, the xlogx function will not return NaN for negtive inputs any more, but instead throw an error, this behaviour is only implemented on the GPU right now.
Default: 0
The limit of log(x) + 1(the deriavtive of x*log(x)) for x->0 is not a real number, but -∞(an extended real number), therefore we have to choose some value for it, this option allows you to extend this and make the derivative of x*log(x) return a fixed value for all 0 ≤ x ≤ ϵ. This allows you to make the derivative a continuous function.
Default: 0
The ϵ mentioned in FIX_DERIVATIVE_FROM_0_TO_EPSILON.
Default: 1e-3
The value for the derivative of x*log(x) for x=0 or 0 ≤ x ≤ ϵ(see FIX_DERIVATIVE_FROM_0_TO_EPSILON).
Default: -1.0
Implementing the ℓ function in tensorflow is to my knowledge only possible with some kind of switch, if raw performance is paramount this is very inefficent, by implementing ℓ in pure C++ and CUDA C this package is a way around the need for symbolic switches in your TensorFlow graph.