The textSpan package is deprecated as the function has been rolled into the doc_centrality() function in the R package text2map.
install.packages("text2map")
library(text2map)
help(doc_centrality)
# example
spanning_scores <- doc_centrality(dtm, method = "span")

Dustin S. Stoltz and Marshall A. Taylor
textSpan is an R package to measure textual spanning
NOTE: We fixed a coding error with the textSpan function (July 2020)

This is an R package used to measure textual spanning on a document by document similarity matrix. The textSpan function takes this document by document similarity matrix and outputs a document specific measure which increases when a document is similar to documents which are not also similar to each other. This is defined by the following equations:
We define proportional similarities as:
Finally, to make the measure more interpretable, we standardize the output by taking the z-score of each and inverting it such that positive values indicate more textual spanning, while negative values indicate less textual spanning:
See the Step by Step Guide for a detailed breakdown of the steps involved in the function. For more elaborate discussion of the theoretical intuition motivating the measure see Stoltz and Taylor (2019) "Textual Spanning: Finding Discursive Holes in Text Networks" in Socius. The package includes the four simulated similarity matrices used in the paper, but further explanation of the code and data necessary to reproduce the measures, graphs, and plots in the paper can be found here: https://github.com/dustinstoltz/textual_spanning_socius. Note that we issued a correction when we discovered the function was not directly implementing the measure as defined by the equations in the paper. The corrected function, as a result, will precisely replicate the paper revised paper, but not the original.
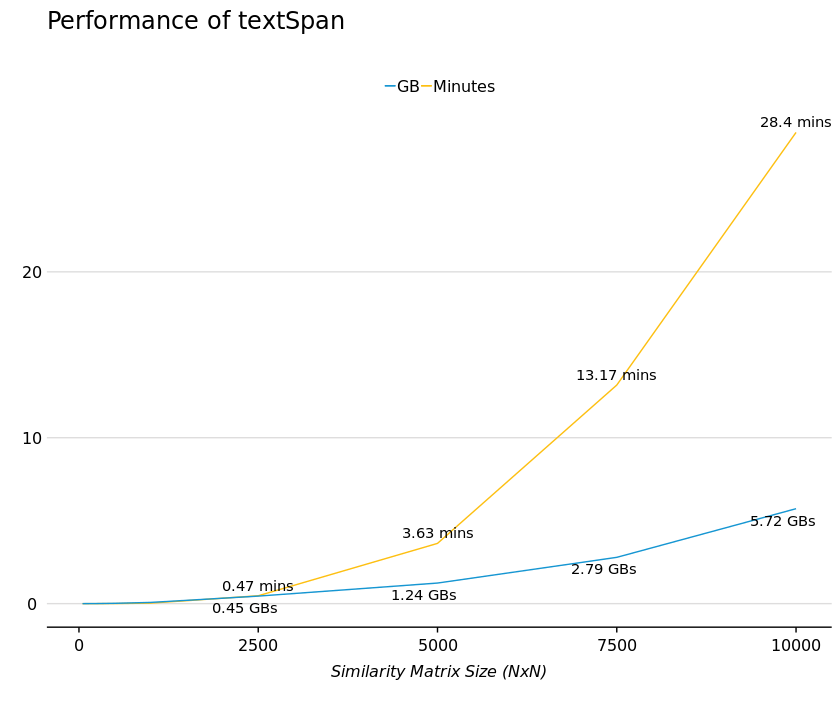
To get a sense of how much time and resources textSpan uses up (as written in Base R above), we simulated a handful of similarities matrices between 50x50 and 10000x10000. The machine we used has a dual-core 2.40GHz processor with 16 GB of RAM running Ubuntu, and this chart shows the total minutes and total RAM used on each matrix.