Play around with f2py and other ways to use compiled code (fortran, c) with python
mcpi.f90- routines for estimating the value of pi using the Monte Carlo methodpurecython.pyx- pure cython implementation with a corresponding setup file
A very basic Makefile is provided that will compile the fortran and cython modules and run the comparison after
running the make command.
Here, we use the Monte Carlo method of drawing random numbers to estimate pi. N random (x, y)
pairs are drawn with values between 0 and 1. We take the number of points inside the square as a
proxy for the area of the square. We also compute the number of points inside a circle of radius one, with
sqrt(x ^ 2 + y ^ 2) <= 1 as a proxy for the area of the circle. Since we are only looking at values of
x and y that are positive, we are estimating a quarter of the area.
The value of pi can be estimated by taking a ratio of the areas:
A_circle / A_square = pi * R^2 / (4 * 1) = pi / 4 ~ N_inside / N
pi ~ 4 * N_inside / N
The figure below presents a plot of 1000 random points drawn inside this unit square. The yellow points are inside the disk, while the purple points are outside the disk.
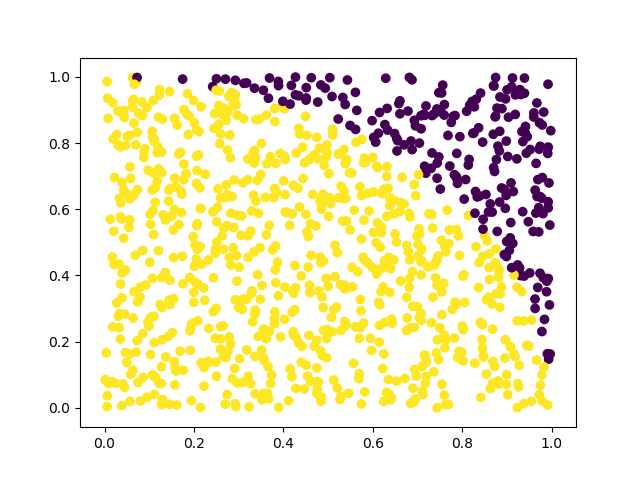
By increasing the number of points drawn, the area of the circle is better approximated, and thus the guess improves.
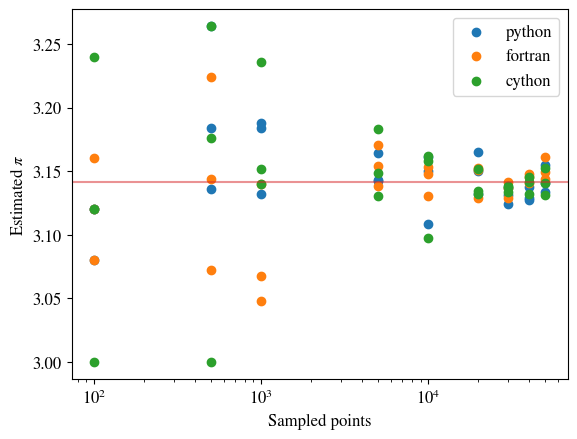
The two plots above were generated using the compare.py
python script. This script relies upon the fortran subroutine
pi_with_coords.
The estimates are computed using implementations in
That's a fair question. We can see from the above picture that the methods both appear to be decently accurate and converge at about the same rate. So why is this hybrid approach necessary?
Python is slow.
...er than compiled code
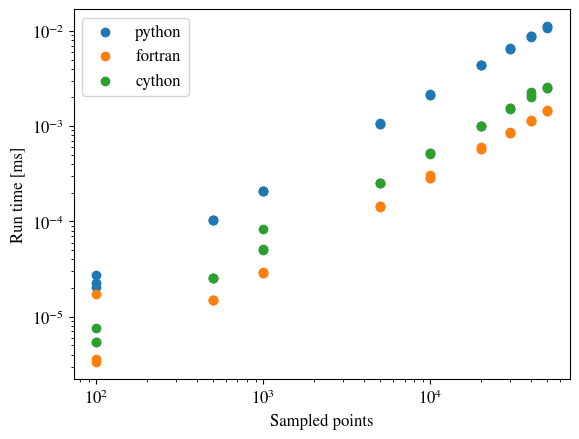
Even for this simple exercise, the compiled fortran is about 10-times faster when many many points are used. This is largely due to the benefits received from a compiled, statically-typed language rather than an interpreted, dynamically-typed program. Rather than rehash what many people on the internet have said, links are provided.