In this project, you will build a web application for Kindle book reviews, one that is similar to Goodreads. You will start with some public datasets from Amazon, and will design and implement your application around them. The requirements below are intended to be broad and give you freedom to explore alternative design choices.
If I can see your effort, your understanding and putting the key technologies together, you'll get an A.
You will be using two dataset.
-
Amazon Kindle's reviews, available from Kaggle website.

This dataset has 982,619 entries (about 700MB).
-
Amazon Kindle metadata, available from UCSD website
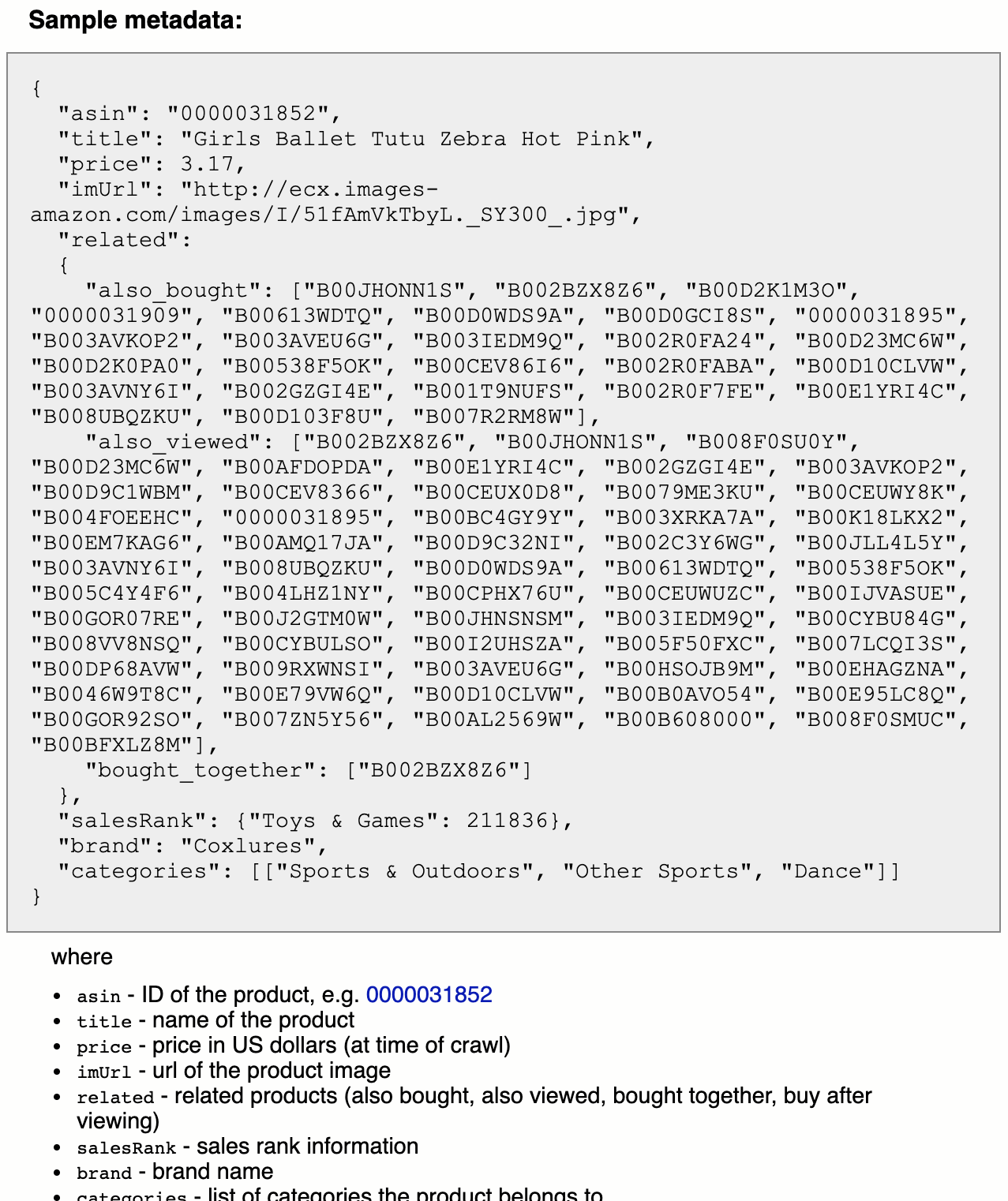
This dataset has 434,702 products (about 450MB)


WARNING There are some weird characters in these datasets that cause troubles to the loading tools in
MySQL and MongoDB. I have manually removed them, and uploaded the clean datasets to Dropbox. You can download
them using the provide script: ./scripts/get_data.sh.
This consists of a web page that let an user perform at least the following:
- See some reviews
- Add new review
- Add a new book
You are free to use any Web framework you want, and free to decide your own structure and layout. As long as I can enter input and get my output. Pretty website will earn you more points, to a certain limit.
And feel free to add more functionalities as the project progresses.
The backend will be the meat of your application, and it accounts for most of the grade. The are two types of backend: a production backend, and a analytics backend.
-
Production backend: consists of the web server, and transaction databases that serve requests from the Internet.
-
Analytics backend: consists of clusters of machines that crunch numbers on the regularly dumped data. In practice, the production system will regularly backup its data and move it to the analytics backend, both for archival storage and for analytics. Another benefit of this practice is that the production system can remove the old data, thus saving resources and making it lightweight.
You will build a web server and several databases like below.

- The web server receives requests and computes the responses by interacting with the databases.
- The reviews are stored in a relational databases (SQL is recommended).
- The metadata (book descriptions) is in a document store (MongoDB is recommended).
- The web server logs are recorded in a document store. Each log record must have at least the following
information:
- Timestamp
- What type of request is being served
- What is the response
For CP1, you will implement the production backend on your local machine. That is, the web server and databases run on the same machine.
Automate as much as you can
For CP2, you will move your backend to Amazon EC2. The server, relational database, and document store, will each run in a separate machine. You will need 3 machines on EC2 for your application to work.
Again, automate as much as you can
You will build a analytics pipeline and system that looks like the figure below.

[Task 1] You will first write a script that saves data from the production system, and then loads the data to a distributed file system (HDFS) in the analytics systems.
[Task 2] Write the following applications in Spark.
-
Correlation: compute the Pearson correlation between price and average review length. You are to implement in a map-reduce fashion, and are not allowed to use
mllib.stat.Satistics. -
TF-IDF: compute the term frequency inverse document frequency metric on the review text. Treat one review as a document.
[Task 3] Demonstrate Task 2 running on 2,4,8-node clusters.
You will build the analytics backend as specified above. You will integrate with the production backend to make your application complete.
You will not (be able to) do this without automation scripts.
The requirements for the scripts are as follows:
-
No managed service such as EMR and RDS.
-
Your scripts are expected to:
-
Take my AWS credentials as input. (For the analytic tasks, your scripts also take the number of nodes).
-
Spin up new instances from a base Ubuntu image. Only most basic OS packages are installed in the base image.
-
Configure and start your systems (both production and analytics). Your scripts tell me how/where to access the front end.
-
Have options to start the analytic tasks.
-
You can save the results of the analytic tasks to file, and tell me how/where to access the file.