Make your PDF files text-searchable (A GUI for OCRmyPDF)
It started with the idea to provide users that are not used to command line tools access to OCRmyPDF's basic features.
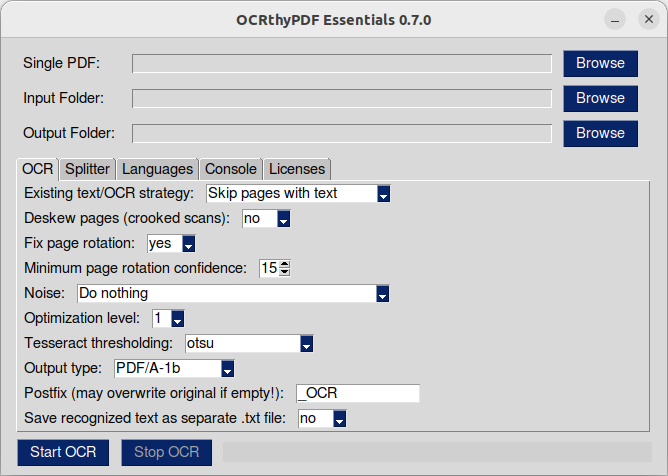
It supports more than 100 languages "out-of-the-box" (all languages that are installed with tesseract).
The splitter function extends the text recognition provided by OCRmyPDF. It allows scanned documents to be separated at separator pages - defined by a QR code - before text recognition. A QR code can mark a separator-only page that is discarded. Alternatively, in sticker mode, the QR code defines the first page of a new document and is retained.
If you like the results created with OCRthyPDF but need more flexibility I suggest you give OCRmyPDF a try on the command line. :)
If you are using Ubuntu or any other Distro that comes with snap pre-installed you can install it directly from the Snap Store

or you can type
sudo snap install ocrthypdf
in your terminal.
If your Distro does not have snap pre-installed you can find instructions for installing snap here.
Snaps run in a restricted environment and need permissions to access files on your computer (Similar to apps on your smartphone). So first check if you have set the correct permissions in the snap store user interface.
You can start OCRthyPDF from the terminal with
ocrthypdf --log INFO
or
ocrthypdf --log DEBUG
in order to get more info in case the application does not work as expected.
Info about subprocesses like OCRmyPDF, Splitter, Ghostscript, etc. is displayed in the console tab. Set 'Loglevel' to DEBUG and 'Limit console ...' to 'no' for detailed information.
📌 Still no clue what went wrong? Report an issue here.
First you need to select a single PDF or a folder containing PDF files that should be processed by OCRmyPDF's character recognition. Then you specify a folder where the new PDFs will be saved. If no output folder is selected, the input folder ist set as output folder as well.
The switches in the "Options" tab correspond to the values described in the OCRmyPDF cookbook and work exactly the same way. Not all combinations are useful or allowed. OCRthyPDF does not prevent you from setting such combinations. In most cases, OCR will simply refuse to start or abort with an error message. See the Console tab for detailed information about what went wrong.
📌 Caution: If you leave the postfix field blank and the output is written to the input folder, you will overwrite your source file! 🤦
Start the OCR with the "Start OCR" button. You can press the "Stop OCR" button to stop all running OCR jobs.
The activity indicator bar flashes while OCR is running.
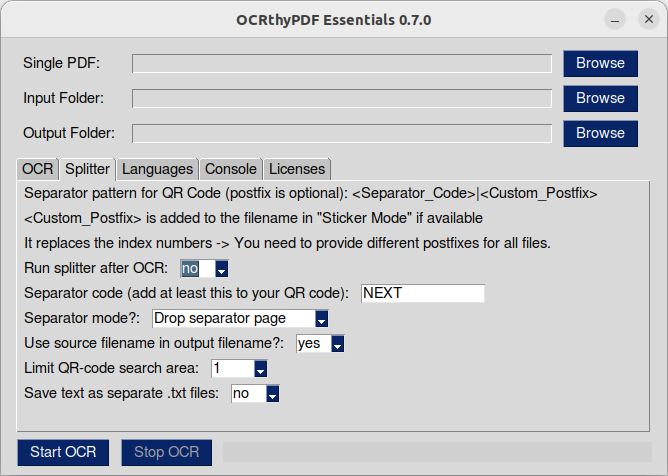
The splitter enables you to split a PDF-file into separate files based on a separator barcode / QR-Code. This is very handy if you have to scan a lot of (multi-page) documents and don't want to scan each document separately. Just put a separator page between each document and scan them at once!
In order to avctivate the splitter set "Run splitter after OCR" to "yes".
In the next field you have to specify a separator text. The splitter tries to find a QR code on each page and compares it's content with this text.
The next switch selects the separator mode. By default, the separation page is omitted and not included in the output files. In Sticker Mode a QR-Code starts a new segment and the page will be added to the output. Each segment/document will be saved with a segment number as postfix. You can download standard QR-Codes with text "NEXT" here.
You can use the pattern <SEPARATOR_TEXT>|<CUSTOM_POSTFIX> in your QR-Code to add a custom postfix to the filename by using Sticker Mode. Use individual postfixes in each code since no segment numbers are added in this mode if a custom postfix is found.
📌 Examples for useful QR-Codes in Sticker Mode:
- NEXT|CoverLetter - NEXT|Attachments
- NEXT|CoverLetter_Miller - NEXT|CoverLetter_Smith
📌 If you select the option not to use the source filename in the output filename you are able to set the filenames by using the custom postfixes (if you leave the postfix field in the options tab blank).
Before Splitter starts analyzing the pages of a PDF file, the source PDF file is rewritten with Ghostscript to work around some common problems with PDF files created by scanners/MFPs. Splitter looks for QR codes in the rewritten file, but assembles the split files directly from the source file.
You can limit the QR-code search area to speed up splitting. 1 -> Search whole page, 0.5 -> search upper left quadrant of page, 0.25 -> search upper left quadrant of upper left quadrant.
If you need the raw text of the final PDF-files set "Save text as separate .txt files" to "yes".
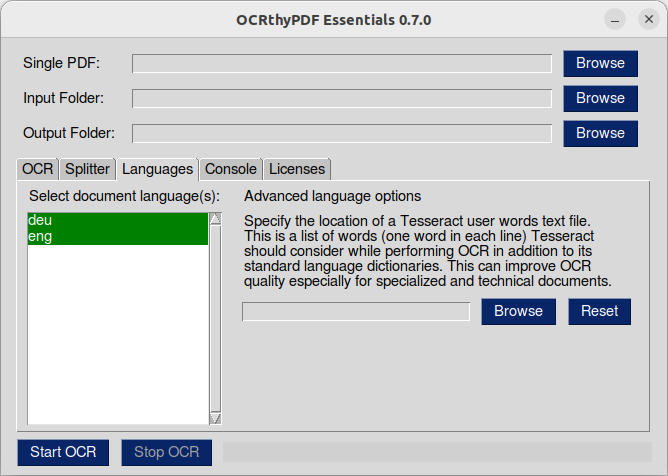
The Language tab lets you select the languages present in your documents. The default selection is English and the language of your desktop environment. Since the result of OCR strongly depends on this selection, you should select all languages you need and deselect all languages you don't!
Language options with the "best-" prefix should give better results than the default options, but OCR may take longer.
You can specify a location of a user words text file. This is a list of words (one word in each line) Tesseract should consider while performing OCR in addition to its standard language dictionaries. This can improve OCR quality especially for specialized and technical documents.
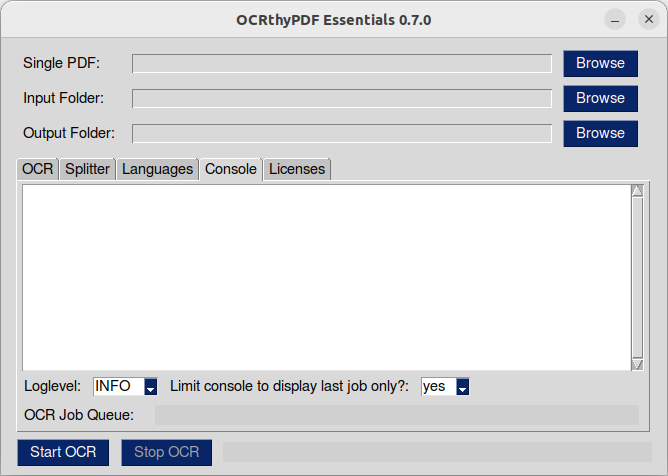
In the console you can see the output of the processes working "under the hood". This is helpful in case the results are different than expected or the OCR terminates with an error code. You can select the log levels "INFO" (status messages when everything works as expected) and "DEBUG" (a lot of detailed information). By default, the console shows the output of the last subprocess and is cleaned up when a new subprocess is started. You can set the console to show the information of all subprocesses without cleanup.
The bars at the bottom indicates the status of the OCR job queue. "Queue" refers to documents waiting to be processed.
A German version of this text can be found here.