Databricks offers a notebook-style development interface. However, to take advantage of the full-suite of Python tooling, it is necessary to move code into a Python package. This is a sample python package that can serve as a starting point for PySpark development on Databricks. It makes use of VSCode Devcontainers for easy setup.
- Docker
- VSCode
- Databricks CLI -- comes installed in the devcontainer as well, but used to retrieve cluster ids
- Databricks workspace
-
Open solution in VSCode.
-
Create an
.envfile. Optionally, set the following environment variables.- If you will be uploading the package to a Databricks workspace as part of the Development cycle, you can optionally set these:
- DATABRICKS_HOST - Databricks workspace url (ei. https://australiaeast.azuredatabricks.net/)
- DATABRICKS_TOKEN - PAT token to databricks workspace
- DATABRICKS_DBFS_PACKAGE_UPLOAD_PATH
- Path in the DBFS where the python package whl file will be uploaded when calling
make uploaddatabricks. (ei. 'dbfs:/mypackages')
- Path in the DBFS where the python package whl file will be uploaded when calling
- DATABRICKS_CLUSTER_ID
- Cluster Id of Databricks cluster where package will be installed when calling
make installdatabricks. (ei. '1234-123456-abc123') - To retrieve cluster ids, use
databricks clusters list.
- Cluster Id of Databricks cluster where package will be installed when calling
- If you will be uploading the package to a Databricks workspace as part of the Development cycle, you can optionally set these:
-
In VSCode command pallete (
ctrl+shift+p), selectRemote-Containers: Reopen in container. First time building the Devcontainer may take a while. -
Run
maketo see options.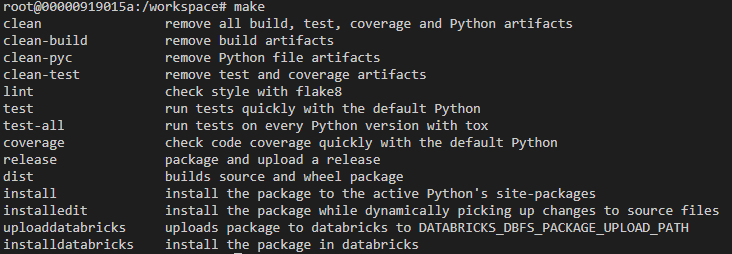

- Localy, write Data Transformation code (
mysparkpackage/core/) and Unit Tests (mysparkpackage/tests/) against test data (/data). - Test and validate locally. ei.
make test,make lint,make install - Upload to databricks and install on a cluster:
make installdatabricks.- Note: that targeted cluster needs to be in a running state.
- Test in notebook.
- Rinse and repeat.
from mysparkpackage.core.transformer import transform
df = spark.read.csv("dbfs:/real-data/")
transformed_df = transform(df)The Devcontainer should have ms-python extension installed and .vscode all the necessary settings. All you need to do is run Python: Discover tests, from the vscode command pallete. Now, all tests (currently located under the mysparkpackage/tests folder) should have Run test | Debug test annotation:
