ディープ・ニューラル・ネットワークによる手書きの漢字、かなを含む日本語OCRを学習させます。
- データセットはETL8Gを使用
- 教育漢字881文字、ひらがな75文字(昭和23年内閣告示第1号「当用漢字別表」による)
ETL8GのRAW形式のバイナリデータからpng画像として抽出。 このとき学習に適した画像にするため、白黒反転させ、輝度を高くしています。
これをNumpy.ndarray形式にしてpickleで保存するというやり方もありますが、 学習時にメモリを使いすぎて動かなくなるので、画像データの前処理はひとまずここまでにしておきます。
基本は畳み込みニューラル・ネットワーク(CNN)ですが、転移学習とテストのために VGG-16の学習済みモデルを利用して学習させていきます。
本来VGG16は多様な画像認識のためのモデルなので、このようなOCRには不向きかと思うのですが、 念の為どうなるのかテストしてみたいと思います。
当初はNumpy配列にデータを突っ込んでからKerasのfit()メソッドで学習させようと思ったのですが、 メモリを使いすぎてしまい動かなくなりました。
転移学習ではfit()メソッドはあまり使わていないように見受けられます。 素直にfit_generate()メソッドを使用し、学習させたいと思います。
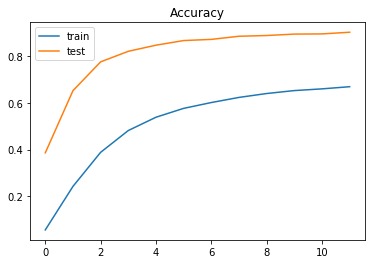
正解率 = 0.9039047710738796
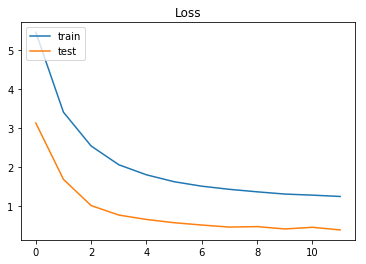
損失誤差= 0.38764024693433413
他クラス分類問題なので精度に不安がありますが、ひとまずこんなものではないのでしょうか。