A graph question answering (GQA) dataset inspired by CLEVR. You could call it CLEGR. We aim to follow a similar methodology and usefulness.
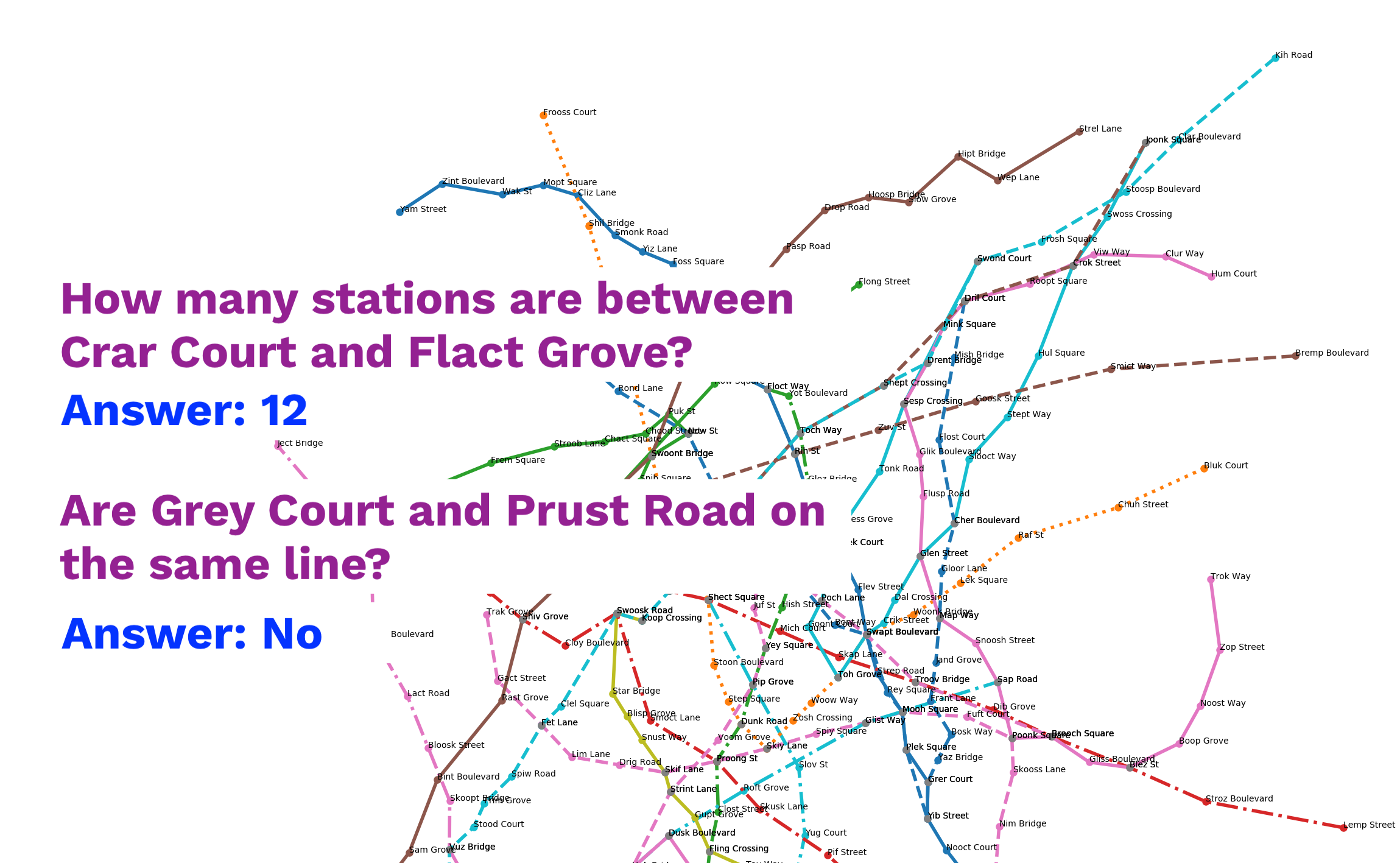
The graph data is modelled on transit networks (e.g. the London tube and train network). Questions are modelled on questions typically asked around mass transit (e.g. How many stops between? Where do I change?). Our aim is that a successful solution to this dataset has real world applications.
This dataset contains a set of graph, question, answer tuples where
- graph is a generated transit graph (vaguely modelled on the London underground)
- question is posed in English, a functional program and Cypher
- answer is a number, boolean, list or categorical answer
python -m gqa.list_questions lists the currently supported questions:
- How many stations are between {Station} and {Station}?
- Which lines is {Station} on?
- How many lines is {Station} on?
- How clean is {Station}?
- Are {Station} and {Station} on the same line?
- Which stations does {Line} pass through?
- How many architecture styles does {Line} pass through?
- How many {Architecture} stations are on the {Line} line?
- Which line has the most {Architecture} stations?
- What's the nearest station to {Station} with disabled access?
- Which {Architecture} station is beside the {Cleanliness} station with {Music} music?
Pull requests adding new questions are very welcome!
See a full list of the question definitions in the source code.
The entire dataset is stored in files /data/gqa-xxxxxx.yaml. This is a series of documents (i.e. YAML objects seperated by '---') to enable parallel parsing. Each document has the following structure:
answer: 7
graph: {...}
question: {...}
The structure of graph and question are explained below.
Graphs are a list of nodes and a list of edges. Each node represents a station. Each edge represents a line going between stations. A list of the different lines is also included for convenience.
Here is an example graph object:
graph:
id: 058af99c-bddc-48d3-a43b-a07cdc6a27ff
nodes:
- {architecture: glass, cleanliness: clean, disabled_access: true, has_rail: false,
id: 5ef607f3-7c54-484d-abc7-ae22030bf513, music: country, name: Stub Grove, size: small,
x: -2.9759803148208315, y: -0.5997361666284166}
edges:
- {line_color: gray, line_id: 3299ecda-ab86-483b-a0dd-d88ff0f03b0b,
line_name: Gray Vuss, line_stroke: dotted, station1: 5ef607f3-7c54-484d-abc7-ae22030bf513,
station2: 26fd3fc5-b447-4ade-929f-2b947abb8be0}
lines:
- {built: 90s, color: green, has_aircon: false,
id: 37ed4b53-b696-4547-9b33-132cce0f2fa4, name: Green Gloot, stroke: dotted}Questions contain an english question, a functional representation of that question, a cypher query and the type of question.
Functional programs are represented as a syntax tree. For example the algebraic expression subtract(count(shortest_path(Station(King's Cross), Station(Paddington))),2) would be stored as:
question:
english: How many stations are between King's Cross and Paddington?
functional:
Subtract:
- Count:
- ShortestPath:
- Station:
- { name: King's Cross, ... }
- Station:
- { name: Paddington, ... }
- 2
tpe: StationShortestCount
cypher: MATCH (var1) MATCH (var2) MATCH tmp1 = shortestPath((var1)-[*]-(var2)) WHERE
var1.id="c2b8c082-7c5b-4f70-9b7e-2c45872a6de8" AND var2.id="40761fab-abd2-4acf-93ae-e8bd06f1e524" WITH
nodes(tmp1) AS var3 RETURN length(var3) - 2| Number of (Graph,Question,Answer) triples | 10,000 |
| Average number of lines per graph | 20 |
| Average number of stations per graph | 440 |
| Average number of edges per graph | 420 |
| Number of question types | 11 |
You can randomly generate your own unique CLEVR graph dataset:
pipenv install
pipenv shell
python -m gqa.generate --count 200We've included questions in three forms - English, a functional program and a Cypher query. We hope these can help with intermediary solutions, e.g. translating English into Cypher then executing the query, or translating the English into a functional program and then using Neural modules to compute it.
The gql directory contains code to:
- Translate functional programs into Cypher queries
- Upload the graphs to a Neo4j database
- Verify that the Cypher query against the database gives the correct answer
Start a neo4j instance with expected ports and credentials
docker run -it -p 7474:7474 -p 7687:7687 --env NEO4J_AUTH=neo4j/clegr-secrets neo4j:3.4
To load the first graph from qga.yaml into your Neo4j database (n.b. this will pre-emptively wipe your neo4j database, use with care):
python -m gql.load
We're an open-source organisation and are enthusiastic to collaborate with other researchers. Extending this dataset to a wider range of networks, questions or formats is very welcome.
- All the contributors to CLEVR and their supporters
- Nicola Greco, Tubemaps for the London tube map
- Thanks to Andrew Jefferson and Ashwath Salimath for their help with this project
- D. Mack, A. Jefferson. CLEVR graph: A dataset for graph question answering, 2018