LLM-Lora-PEFT_accumulate
Welcome to the LLM-Lora-PEFT_accumulate repository!
This repository contains implementations and experiments related to Large Language Models (LLMs) using PEFT (Parameter Efficient Fine Tuning), LORA (Low-Rank Adaptation of Large Language Models), and QLORA (Quantized LLMs with Low-Rank Adapters).
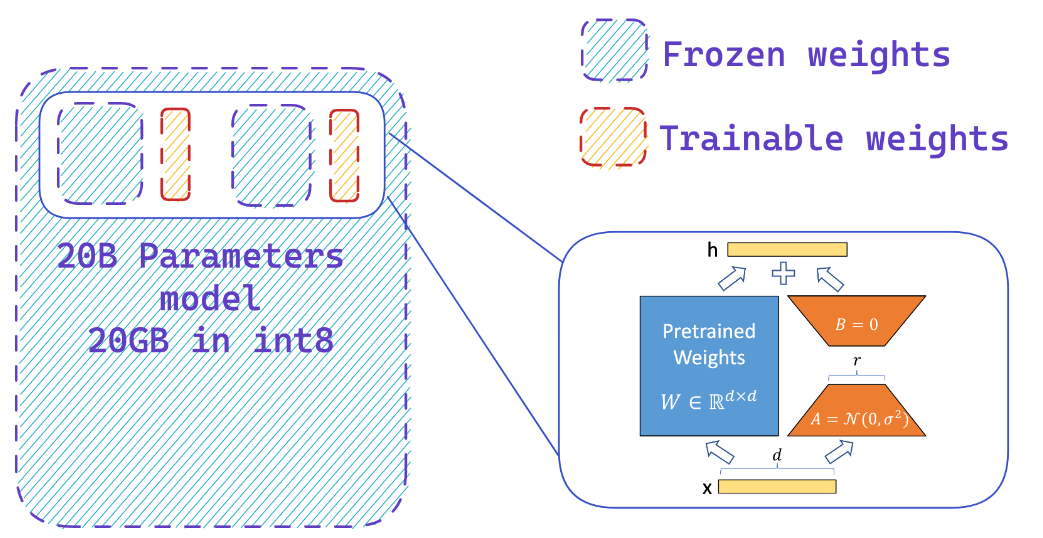
Loading a model in 8-bit precision can save up to 4x memory compared to full precision model

What does PEFT do?
You easily add adapters on a frozen 8-bit model thus reducing the memory requirements of the optimizer states, by training a small fraction of parameters
Resources
🌐 Websites
- HF-BitsandBytes-Integration
🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware- LLM.int8() and Emergent Features
- Tensorfloat-32-precision-format
- RLHF-LLM
- Finetuning Falcon LLMs More Efficiently With LoRA and Adapters by Sebastian Raschka
📺 YouTube Videos
- Boost Fine-Tuning Performance of LLM: Optimal Architecture w/ PEFT LoRA Adapter-Tuning on Your GPU
- How to finetune your own Alpaca 7B
📄 Papers
- PEFT: Parameter Efficient Fine Tuning
- LORA: Low-Rank Adaptation of Large Language Models
- QLORA: Quantized LLMs with Low-Rank Adapters
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
- SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
🐙 GitHub Repositories
🐍 Python Notebooks
SWOT of LLMs
Go to LLM Analysis with SWOT for more clarification.