nautilus-ocr is a Nautilus script
that scans pdfs and adds OCR information to them. This is useful if you scanned documents
and want to make them searcheable or copy-paste content from them.
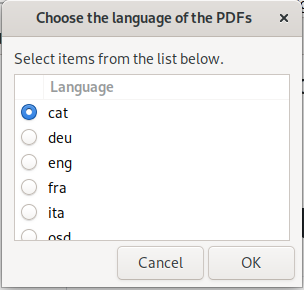
It allows selecting the language in the PDF for a better recognition of the text.
- Zenity: UI dialogs
- OCRMyPDF: OCR
- Tesseract: OCR (low-level)
For Tesseract you need also the OSD data.
You can install all the dependencies in Fedora as follows:
$ dnf install tesseract tesseract-osd ocrmypdf zenityIn Ubuntu you would instead do:
$ sudo apt install tesseract-ocr tesseract-ocr-osd ocrmypdf zenitySimilar packages might exist for your distribution of choice.
You might also want to add training data for other languages. In Fedora you can install, for example, French language as follows:
$ dnf install tesseract-langpack-fraIn Ubuntu, it would be:
$ sudo apt install tesseract-ocr-fra(Click on image to see screencast)
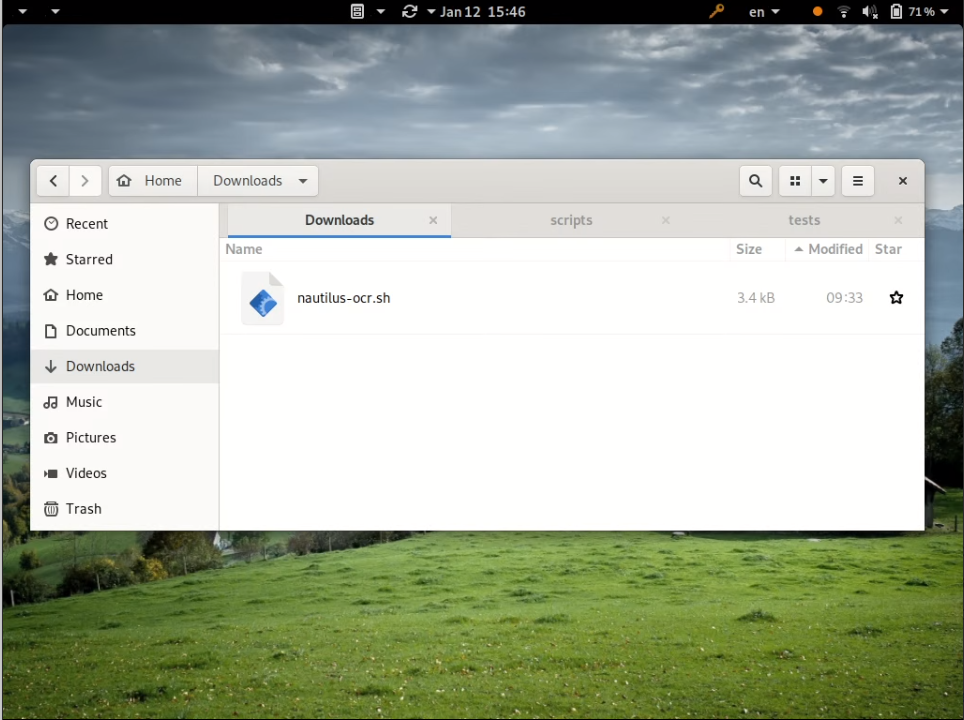
Download nautilus-ocr.sh and move it to the Nautilus Scripts
folder. Remember to add the execution permission. If you downloaded
the script to ~/Downloads folder:
$ chmod +x ~/Downloads/nautilus-ocr.sh
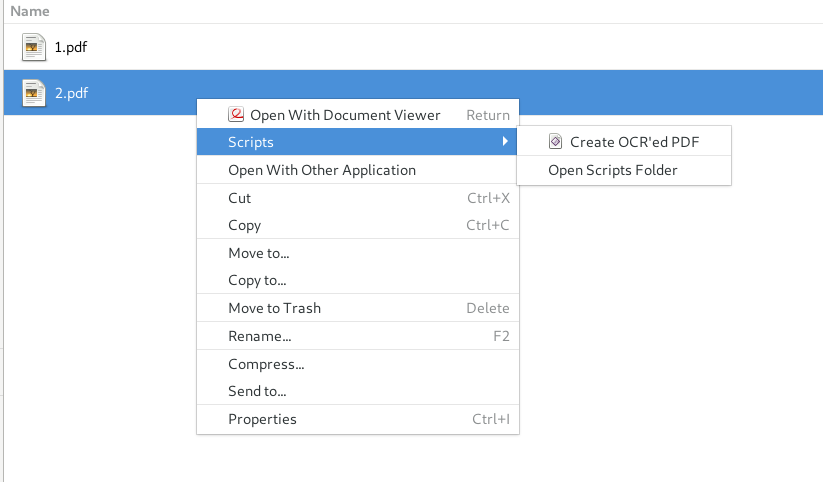
$ mv ~/Downloads/nautilus-ocr.sh "~/.local/share/nautilus/scripts/Create OCR'ed PDF"Once the script is in place, you can righ-click on any file in Nautilus.
It will create a pdf file with the _ocr suffix. That file will contain OCR information. If you
can select text in that file, it means the OCR worked.
By default a dialog will ask you which language to use for the OCR. If you
want to use always the same language, edit nautilus-ocr.sh and set
the language at the top of the file.
A dialog will be showed after OCR'ing the files, stating that the process
has finished. If you want to close the dialog automatically, just uncomment the option --auto-close.
- @errotu: Ubuntu support