- Threads in Java (Hasta 'Ending Threads')
- Threads vs Processes
Este ejercicio contiene una introducción a la programación con hilos en Java, además de la aplicación a un caso concreto.
Parte I - Introducción a Hilos en Java
- De acuerdo con lo revisado en las lecturas, complete las clases CountThread, para que las mismas definan el ciclo de vida de un hilo que imprima por pantalla los números entre A y B.
- Complete el método main de la clase CountMainThreads para que:
- Cree 3 hilos de tipo CountThread, asignándole al primero el intervalo [0..99], al segundo [99..199], y al tercero [200..299].
- Inicie los tres hilos con 'start()'.
- Ejecute y revise la salida por pantalla.
- Cambie el incio con 'start()' por 'run()'. Cómo cambia la salida?, por qué?.
Se pudo evidenciar que el metodo start() , crea nuevos hilos en paralelo y los ejecuta, donde se evidencia que la salida de los intervalos de cada hilo salen en desorden:
.png)
Se pudo evidenciar que el metodo run(), crea los hilos desde el metodo , lo que hace que salida de los intervalos de los hilos sea ordenada ya que cada llamada la hace secuencialmente al llamado del metodo y no en paralelo:
.png)
Parte II - Ejercicio Black List Search
Para un software de vigilancia automática de seguridad informática se está desarrollando un componente encargado de validar las direcciones IP en varios miles de listas negras (de host maliciosos) conocidas, y reportar aquellas que existan en al menos cinco de dichas listas.
Dicho componente está diseñado de acuerdo con el siguiente diagrama, donde:
-
HostBlackListsDataSourceFacade es una clase que ofrece una 'fachada' para realizar consultas en cualquiera de las N listas negras registradas (método 'isInBlacklistServer'), y que permite también hacer un reporte a una base de datos local de cuando una dirección IP se considera peligrosa. Esta clase NO ES MODIFICABLE, pero se sabe que es 'Thread-Safe'.
-
HostBlackListsValidator es una clase que ofrece el método 'checkHost', el cual, a través de la clase 'HostBlackListDataSourceFacade', valida en cada una de las listas negras un host determinado. En dicho método está considerada la política de que al encontrarse un HOST en al menos cinco listas negras, el mismo será registrado como 'no confiable', o como 'confiable' en caso contrario. Adicionalmente, retornará la lista de los números de las 'listas negras' en donde se encontró registrado el HOST.

Al usarse el módulo, la evidencia de que se hizo el registro como 'confiable' o 'no confiable' se dá por lo mensajes de LOGs:
INFO: HOST 205.24.34.55 Reported as trustworthy
INFO: HOST 205.24.34.55 Reported as NOT trustworthy
Al programa de prueba provisto (Main), le toma sólo algunos segundos análizar y reportar la dirección provista (200.24.34.55), ya que la misma está registrada más de cinco veces en los primeros servidores, por lo que no requiere recorrerlos todos. Sin embargo, hacer la búsqueda en casos donde NO hay reportes, o donde los mismos están dispersos en las miles de listas negras, toma bastante tiempo.
Éste, como cualquier método de búsqueda, puede verse como un problema vergonzosamente paralelo, ya que no existen dependencias entre una partición del problema y otra.
Para 'refactorizar' este código, y hacer que explote la capacidad multi-núcleo de la CPU del equipo, realice lo siguiente:
- Cree una clase de tipo Thread que represente el ciclo de vida de un hilo que haga la búsqueda de un segmento del conjunto de servidores disponibles. Agregue a dicha clase un método que permita 'preguntarle' a las instancias del mismo (los hilos) cuantas ocurrencias de servidores maliciosos ha encontrado o encontró.
📂 Desarrollo de la práctica:

- Agregue al método 'checkHost' un parámetro entero N, correspondiente al número de hilos entre los que se va a realizar la búsqueda (recuerde tener en cuenta si N es par o impar!). Modifique el código de este método para que divida el espacio de búsqueda entre las N partes indicadas, y paralelice la búsqueda a través de N hilos. Haga que dicha función espere hasta que los N hilos terminen de resolver su respectivo sub-problema, agregue las ocurrencias encontradas por cada hilo a la lista que retorna el método, y entonces calcule (sumando el total de ocurrencuas encontradas por cada hilo) si el número de ocurrencias es mayor o igual a BLACK_LIST_ALARM_COUNT. Si se da este caso, al final se DEBE reportar el host como confiable o no confiable, y mostrar el listado con los números de las listas negras respectivas. Para lograr este comportamiento de 'espera' revise el método join del API de concurrencia de Java. Tenga también en cuenta:
📂 Desarrollo de la práctica:

* Dentro del método checkHost Se debe mantener el LOG que informa, antes de retornar el resultado, el número de listas negras revisadas VS. el número de listas negras total (línea 60). Se debe garantizar que dicha información sea verídica bajo el nuevo esquema de procesamiento en paralelo planteado.
* Se sabe que el HOST 202.24.34.55 está reportado en listas negras de una forma más dispersa, y que el host 212.24.24.55 NO está en ninguna lista negra.
Parte II.I Para discutir la próxima clase (NO para implementar aún)
La estrategia de paralelismo antes implementada es ineficiente en ciertos casos, pues la búsqueda se sigue realizando aún cuando los N hilos (en su conjunto) ya hayan encontrado el número mínimo de ocurrencias requeridas para reportar al servidor como malicioso. Cómo se podría modificar la implementación para minimizar el número de consultas en estos casos?, qué elemento nuevo traería esto al problema?
✏️ Para minimizar el numero de consultas es posible crear una variable global que incremente cada vez que se realiza una consulta. Dicha solución cuando se implementa impide llevar un conteo limpio de estos casos ya que las variables pueden sufrir modificación antes o despues de que otra variable sea conusulte, impidiendo que esta se modifique con el valor correcto.
Parte III - Evaluación de Desempeño
A partir de lo anterior, implemente la siguiente secuencia de experimentos para realizar las validación de direcciones IP dispersas (por ejemplo 202.24.34.55), tomando los tiempos de ejecución de los mismos (asegúrese de hacerlos en la misma máquina):
1. Un solo hilo.
✏️ Tiempo de ejecución = 133 s

✏️ 2. Tantos hilos como núcleos de procesamiento (haga que el programa determine esto haciendo uso del API Runtime).
✏️Tiempo de ejecución = 17 s


✏️3. Tantos hilos como el doble de núcleos de procesamiento.
Tiempo de ejecución = 9 s


✏️4. 50 hilos.
Tiempo de ejecución = 3 s

✏️5. 100 hilos.
✏️Tiempo de ejecución = --- No fue posible identificar el tiempo de ejecución ya que al momento de ejecutar el proyecto este no reportaba ningun valor en VisualMV.
Al iniciar el programa ejecute el monitor jVisualVM, y a medida que corran las pruebas, revise y anote el consumo de CPU y de memoria en cada caso. 
Con lo anterior, y con los tiempos de ejecución dados, haga una gráfica de tiempo de solución vs. número de hilos. Analice y plantee hipótesis con su compañero para las siguientes preguntas (puede tener en cuenta lo reportado por jVisualVM):
-
Según la ley de Amdahls:
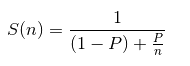 , donde S(n) es el mejoramiento teórico del desempeño, P la fracción paralelizable del algoritmo, y n el número de hilos, a mayor n, mayor debería ser dicha mejora. Por qué el mejor desempeño no se logra con los 500 hilos?, cómo se compara este desempeño cuando se usan 200?.
, donde S(n) es el mejoramiento teórico del desempeño, P la fracción paralelizable del algoritmo, y n el número de hilos, a mayor n, mayor debería ser dicha mejora. Por qué el mejor desempeño no se logra con los 500 hilos?, cómo se compara este desempeño cuando se usan 200?.


✏️Cuando se utilizan un número muy alto numero de hilos es mas costoso la construción y ejecución de los mismos que el beneficio que este pueda dar. Por esta razón aveces cuando se tiene mayor número de hilos no brinda un mayor desempeño.
- Cómo se comporta la solución usando tantos hilos de procesamiento como núcleos comparado con el resultado de usar el doble de éste?.
✏️si se aumenta el número de hilos sobre el número de núcleos se optiene un mayor rendimiento. Esto se debe a que los hilos no aprovechan todo el potencial sobre el número de núcleos disponibles, por lo tanto quedan recursos libres que pueden ser aprovechados por un mayor número de hilos.
- De acuerdo con lo anterior, si para este problema en lugar de 100 hilos en una sola CPU se pudiera usar 1 hilo en cada una de 100 máquinas hipotéticas, la ley de Amdahls se aplicaría mejor?. Si en lugar de esto se usaran c hilos en 100/c máquinas distribuidas (siendo c es el número de núcleos de dichas máquinas), se mejoraría?. Explique su respuesta.
✏️Si utilizamos la definición teórica de la ley de Amdahls, podemos concluir que tanto en el caso de usar 1 hilo en cada una de 100 máquinas hipotéticas, como en el de usar c hilos en 100/c máquinas distribuidas, no se presentaría una mejora de rendimiento del problema, ya que en cada uno de los 3 casos (incluyendo 100 hilos en una sola CPU), habría la misma fracción paralelizable del algoritmo P, y el mismo número de hilos n. Por tanto, el mejoramiento teórico del desempeño sería exactamente el mismo, asumiendo que no se presenta un cuello de botella por parte del CPU.